
- 1React入门:基本环境搭建
- 2基于python的携程旅游数据采集作业,通过selenium爬取指定经典用户评论信息,将用户评论信息保存在本地数据库和excel文件。_python 爬取携程中某一酒店的用户评价并存储下来
- 3浅谈安数云智能安全运营管理平台:DCS-SOAR
- 4图神经网络实战(16)——经典图生成算法_图神经网络生成图
- 5自动创建XFRM虚拟接口的net2net形式的IPSEC_strongswan xfrm
- 6建筑设备【3】_用户终端是指共用天线电视的接线器,又称为?
- 7快速排序基于分治法的思想
- 8阿里云天池大赛赛题解析——机器学习篇 | 留言赠书
- 9【免费赠送源码】基于Hadoop平台的个性化图书推荐系统的研究
- 10Gitee码云 remote: Incorrect username or password ( access token )_gitee incorrect username or password (access token
【消息中间件】Rabbitmq消息可靠性、持久化机制、各种消费_rabbitmq 批量消费
赞
踩
原文作者:我辈李想
版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。
前言
一、常见用法
1.消息可靠性
RabbitMQ 提供了多种机制来确保消息的可靠性,以防止消息丢失或被意外删除。以下是几种提高消息可靠性的方法:
-
持久化消息(Durable Message):在发布消息时,将消息的
deliveryMode设置为2,即可将消息设置为持久化消息。持久化消息会将消息写入磁盘,即使 RabbitMQ 服务器重启,消息也不会丢失。 -
持久化队列(Durable Queue):创建队列时,将队列的
durable参数设置为true,即可创建一个持久化队列。持久化队列会将队列的元数据和消息都存储在磁盘上,即使消息队列服务器重启,队列的元数据和消息仍然可以恢复。 -
确认模式(Publisher Confirms):使用确认模式可以确保消息被成功发送到 RabbitMQ 服务器,并得到确认。通过在信道上使用
channel.confirmSelect()启用确认模式,然后通过channel.waitForConfirms()方法来等待服务器的确认。 -
事务模式(Transactions):使用事务模式可以保证消息的原子性,要么全部发送成功,要么全部失败。通过在信道上使用
channel.txSelect()开启事务模式,在发送消息后使用channel.txCommit()提交事务,或使用channel.txRollback()进行回滚。 -
消费者应答(Consumer Acknowledgement):在消费者接收和处理消息后,必须发送确认应答给 RabbitMQ 服务器。通过使用
channel.basicAck()方法发送确认应答,以告知服务器消息已经成功处理。
通过使用上述机制,可以在 RabbitMQ 中实现消息的可靠性传输和处理,以防止消息的丢失和重复传递。
这里有篇博客,大家可以看看。
2.持久化机制
在RabbitMQ中,消息持久化是一种机制,可以确保消息在服务器宕机或重启之后不丢失。默认情况下,RabbitMQ的消息是存储在内存中的,如果服务器宕机,则会导致消息的丢失。要实现消息的持久化,可以采取以下步骤:
-
创建一个持久化的交换机(Exchange):
在定义交换机时,将其durable参数设置为true,例如:channel.exchangeDeclare("exchange_name", "direct", true);- 1
-
创建一个持久化的队列(Queue):
在定义队列时,将其durable参数设置为true,例如:
channel.queue_declare(queue=self._queue_oname, durable=True)
3. 将持久化的队列与交换机进行绑定:
使用队列和交换机的bind方法进行绑定,例如:
- 1
- 2
- 3
channel.queue_bind(queue=self._queue_oname, exchange=self.exchange, routing_key=self.routing_key)
4. 发布持久化的消息:
在发布消息时,将消息的deliveryMode属性设置为2,表示消息是持久化的,例如:
- 1
- 2
- 3
String message = “Hello RabbitMQ!”;
channel.basicPublish(“exchange_name”, “routing_key”, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());
通过以上步骤,就可以实现消息的持久化。当RabbitMQ服务器宕机或重启后,消息会被保存在磁盘中,并在服务器恢复后重新投递给消费者。需要注意的是,虽然消息被持久化了,但是在发送到队列之前,仍然有可能发生丢失,所以在实际的应用中,还需要考虑一些因素,比如网络故障、消费者的可靠性等。 ## 3.消息积压 ### 批量消费:增加 prefetch 的数量,提高单次连接的消息数 为了提高消费性能,可以将多个消息批量进行消费,减少消费者和消息队列的交互次数。通过设置合适的批量消费大小,可以在一次网络往返中消费多个消息,从而提高消费性能。 要实现RabbitMQ的批量消费,可以使用RabbitMQ的channel.basicQos方法来设置每次消费的消息数量。以下是一个示例代码,演示如何实现批量消费: ```python import pika def callback(ch, method, properties, body): print("Received message: %s" % body) # 处理消息的逻辑 # 发送确认给RabbitMQ ch.basic_ack(delivery_tag=method.delivery_tag) def consume_messages(): connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 设置每个消费者一次性获取的消息数量 channel.basic_qos(prefetch_count=10) # 注册消费者并开始消费消息 channel.basic_consume(queue='my_queue', on_message_callback=callback) # 进入一个循环,一直等待消息的到来 channel.start_consuming() consume_messages()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
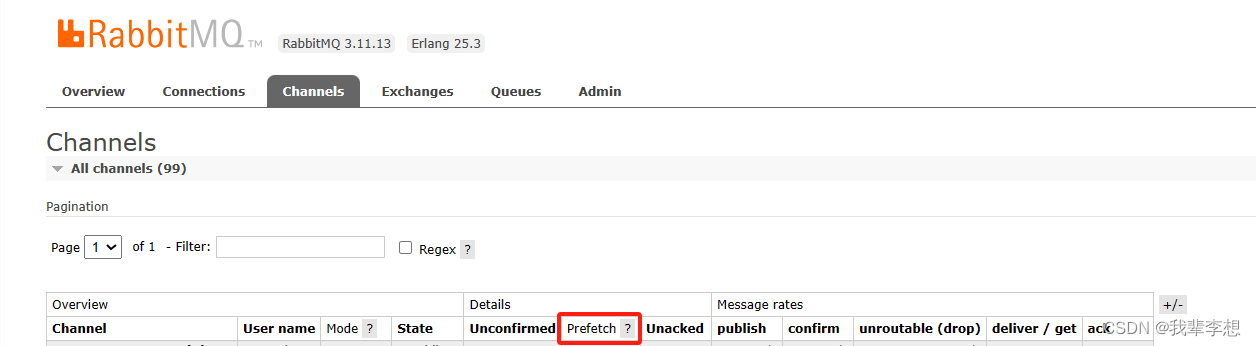
在上面的代码中,我们通过channel.basic_qos(prefetch_count=10)设置每次处理的消息数量为10。这样,在消费者处理完10条消息之前,RabbitMQ将不会再向其发送更多消息。
这样,就实现了RabbitMQ的批量消费。你可以根据需求,在basic_qos方法中设置适合你的消息数量。
并发消费:多部署几台消费者实例
可以采用多线程或多进程的方式进行消息的并发消费,将多个消费者并行处理消息。通过增加并发消费者的数量,可以提高消息的处理速度,提高消费的性能。
使用进程池来消费RabbitMQ的消息可以更好地管理并发性能。通过使用进程池,可以在一个固定的池子中创建多个进程,并且复用它们来消费消息,从而减少进程创建和销毁的开销。
以下是一个使用进程池消费RabbitMQ消息的示例:
import multiprocessing import os import time import pika def consumer(queue_name): connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.queue_declare(queue=queue_name) def callback(ch, method, properties, body): print(f'Process {os.getpid()} received message: {body}') time.sleep(1) channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True) channel.start_consuming() def main(): # 创建进程池 pool = multiprocessing.Pool(processes=5) # 在进程池中提交任务 for _ in range(5): pool.apply_async(consumer, ('my_queue',)) pool.close() pool.join() if __name__ == '__main__': main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
在上述示例中,我们使用multiprocessing.Pool来创建一个包含5个进程的进程池。然后,我们使用apply_async方法向进程池中提交任务,每个任务都是调用consumer函数来消费"my_queue"队列中的消息。进程池会自动分配任务给闲置的进程来处理。通过close和join方法,我们可以确保所有任务都被完成。
4.重复消费
-
消息确认:在消费者处理完一条消息后,通过调用
basic_ack方法手动确认消息已经成功消费。这样,RabbitMQ就会将该消息标记为已经处理,不会再次发送给其他消费者。同时,还可以设置auto_ack参数为False,禁用自动消息确认机制,以确保消息被正确确认。 -
消息持久化:可以通过设置消息的
delivery_mode属性为2来将消息标记为持久化消息。这样,即使消费者在处理消息时发生故障,消息也会被保存在磁盘上,待消费者恢复正常后会重新投递。 -
唯一消费者:可以通过设置队列的
exclusive参数为True,创建一个排他队列。这样,只有一个消费者可以连接到该队列,并独占地消费其中的消息,避免重复消费。 -
消息去重:在消费者端可以维护一个已消费消息的记录,例如在数据库或缓存中记录已消费的消息的ID或唯一标识。每次消费消息时,先检查记录中是否已经存在该消息,如果存在则跳过,避免重复处理。
-
幂等操作:在消费者的处理逻辑中,要确保操作是幂等的,即多次执行同一个操作的效果和执行一次的效果是一样的。这样,即使消息被重复消费,也不会产生副作用。
二、其他
1.队列存在大量unacked数据
通过rabbitmq的后台管理,进入相应的队列,滑到最下边,找到purge。purge将清空这个队列的消息。

2.断线重连

方式一
这里可以使用retry在消费者函数consume加装饰器。
import pika
from retry import retry
@retry(pika.exceptions.AMQPConnectionError, delay=5, jitter=(1, 3))
def consume(self, callback):
"""Start consuming AMQP messages in the current process"""
try:
self.start_consuming_message()
# 不恢复被rabbitmq服务器关闭的连接
except pika.exceptions.ConnectionClosedByBroker:
"""捕获ConnectionClosedByBroker异常,相当于跳过,retry将不执行"""
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
不用retry的可以手动获取异常,添加重连方法
from mq.rabbitmq_base import Rabbitmq class MqCastComparisonAlgorithm(Rabbitmq): @func_timer def on_message(self, ch, method, properties, body): eventsDelivery = set() eventsDelivery.add(config.Arim_Plan_Send) eventsDelivery.add(config.Arim_SlabMatching_Start) eventsDelivery.add(config.Arim_RollPlan_Rescheduled_Redis) try: print('算法事件:', method.routing_key) pass except Exception as e: print("算法出现异常: {}".format(e)) finally: ch.basic_ack(delivery_tag=method.delivery_tag) def CastComparisonAlgorithm_consume_task(queue_oname, exchange, route_key): mq = MqCastComparisonAlgorithm(queue_oname, exchange, route_key, is_use_rabbitpy=1) try: mq.start_consuming_message() except ConnectionClosed as e: print('异常断开时,重新建立消费者') mq.reconnect(queue_oname, exchange, route_key, is_use_rabbitpy=1) mq.start_consuming_message() except ChannelClosed as e: print('异常断开时,重新建立消费者') mq.reconnect(queue_oname, exchange, route_key, is_use_rabbitpy=1) mq.start_consuming_message()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
方式二
这个需要开启链接断开的重试,属于ConnectionParameters的retry_delay和connection_attempts参数。消费ack确认前连接异常断开时。
connectionParameters = pika.ConnectionParameters(
host='localhost',
virtual_host=5672,
credentials=credentials,
socket_timeout=10,
heartbeat=0,
retry_delay=10, # 连接尝试重连间隔
connection_attempts=10, # 连接尝试次数
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.rabbitmq心跳间隔
心跳的全称是心跳间隔,RabbitMQ 心跳间隔是一种保持连接活跃的机制。当 RabbitMQ 与客户端建立连接后,它会定期发送心跳包来确认连接仍然有效。如果在一段时间内没有收到心跳回复,RabbitMQ 将会关闭连接。心跳属于ConnectionParameters参数heartbeat。
对于单个消费者,我们不希望消费者断开连接,设置heartbeat=0,并且使用retry捕获异常重新建立连接;对于多消费者,设置一个合理的心跳heartbeat值,可以减少异常连接,减少rabbitmq服务端进程维持心跳的开销。
parameters = pika.ConnectionParameters(host, int(port), '/', credentials=userx, heartbeat=int(heartbeat))
- 1
如果消费者使用心跳,还可以参考这个博客
4.消费时间和心跳间隔时间
import threading import pika def callback(channel, method, properties, body): # 处理接收到的消息 print(body) # 发送回执确认消息 channel.basic_ack(delivery_tag=method.delivery_tag) def on_message(channel, method, properties, body): # 将回调函数添加到队列中 channel.add_callback_threadsafe(callback, channel, method, properties, body) def consume_messages(): connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() # 定义一个队列 channel.queue_declare(queue='my_queue') # 消费消息 channel.basic_consume(queue='my_queue', on_message_callback=on_message) # 开始消费消息 channel.start_consuming() # 在新的线程中执行消费消息的函数 consume_thread = threading.Thread(target=consume_messages) consume_thread.start() # 主线程做其他的事情 # ... consume_thread.join()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
5.消费时间过长引发的consumer_timeout异常
具体异常如下:pika.exceptions.ChannelClosedByBroker: (406, ‘PRECONDITION_FAILED - delivery acknowledgement on channel 1 timed out. Timeout value used: 1800000 ms. This timeout value can be configured, see consumers doc guide to learn more’)
主要原因是ack超过30分钟未确认,所以引发了rabbitmq的参数consumer_timeout,这个参数就是消费者超时参数,默认是1800000即30分钟。如果使用channel.basic_qos(prefetch_count=10)来批量消费,就看10条信息的总时间是否超过30分钟。
可以通过retry捕获异常重建消费者,这样的话平时正常消费不会触发,任务大量堆积导致unacked较大时,会触发consumer_timeout,即30分钟重连一次rabbitmq。(看自己情况吧)
@retry((pika.exceptions.AMQPConnectionError,
pika.exceptions.ChannelClosedByBroker), delay=5, jitter=(1, 3))
def cusermer():
print('重试一次')
rabbitmq = RabbitMQ(my_host, rabbitmq_port, my_username, my_password)
if rabbitmq.connect():
# rabbitmq.send_message(my_exchange, my_routing_key, message="{"reason":"11"}")
rabbitmq.consume_messages("queues_test", callback)
else:
print("Failed to connect to RabbitMChannelClosedByBrokerQ.")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
连接被重置ConnectionResetError
具体报错内容Stream connection lost: ConnectionResetError(104, ‘Connection reset by peer’),这个报错无法使用retry处理,产生的原因是未开启心跳,并且长时间无数据需要处理。
消费消息后发送一条新消息到另一个事件
可以使用Pika库连接RabbitMQ,并编写代码以消费消息并发送一条新消息。以下是一个示例代码:
import pika # 连接RabbitMQ connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明队列和交换机 channel.queue_declare(queue='my_queue') channel.exchange_declare(exchange='my_exchange', exchange_type='direct') channel.queue_bind(queue='my_queue', exchange='my_exchange', routing_key='my_key') # 定义消费消息的回调函数 def callback(ch, method, properties, body): # 接收到消息后,发送一条新消息到另一个队列 channel.basic_publish(exchange='', routing_key='another_queue', body='Hello World') # 消费消息 channel.basic_consume(queue='my_queue', on_message_callback=callback, auto_ack=True) # 开始消费 channel.start_consuming()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在以上代码中,我们首先连接到RabbitMQ,并在my_queue队列和my_exchange交换机之间建立绑定关系。
然后,我们定义了一个回调函数callback,用于接收消费到的消息。在这个回调函数中,我们通过channel.basic_publish()方法发送了一条新消息到名为another_queue的队列。
最后,我们使用channel.basic_consume()方法开始消费消息,并传入回调函数。接下来,channel.start_consuming()方法启动了消费者,使其开始接收和处理消息。
请注意,以上代码仅是一个简单示例,具体的实现方式可能会因实际需求而有所不同。可以使用Pika库连接RabbitMQ,并编写代码以消费消息并发送一条新消息。以下是一个示例代码:
import pika # 连接RabbitMQ connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明队列和交换机 channel.queue_declare(queue='my_queue') channel.exchange_declare(exchange='my_exchange', exchange_type='direct') channel.queue_bind(queue='my_queue', exchange='my_exchange', routing_key='my_key') # 定义消费消息的回调函数 def callback(ch, method, properties, body): # 接收到消息后,发送一条新消息到另一个队列 channel.basic_publish(exchange='', routing_key='another_queue', body='Hello World') # 消费消息 channel.basic_consume(queue='my_queue', on_message_callback=callback, auto_ack=True) # 开始消费 channel.start_consuming()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在以上代码中,我们首先连接到RabbitMQ,并在my_queue队列和my_exchange交换机之间建立绑定关系。
然后,我们定义了一个回调函数callback,用于接收消费到的消息。在这个回调函数中,我们通过channel.basic_publish()方法发送了一条新消息到名为another_queue的队列。
最后,我们使用channel.basic_consume()方法开始消费消息,并传入回调函数。接下来,channel.start_consuming()方法启动了消费者,使其开始接收和处理消息。
请注意,以上代码仅是一个简单示例,具体的实现方式可能会因实际需求而有所不同。

