
- 1springboot获取resources下的文件失败解决记录_springboot java.io.filenotfoundexception: class pa
- 2关键节点与邻居搜索:K-Core算法对比K-Hop算法的效能较量_。 关节点检索算法
- 3FlowUs息流打造AI赋能下的知识库,信息深度挖掘与智能创作!FlowUs让你的数据资产更有价值
- 4javascript开发技巧训练_学好这些小技巧,帮你写出更好地JavaScript
- 5docker mysql8使用SSL及使用openssl生成自定义证书_mysql 8 cert生成
- 6mac系统 SSH配置_mac ssh配置
- 7自然语言处理 (NLP) 入门教程_nlp入门教程
- 835.MySQL导出数据的几种方式_mysql 导出表数据
- 9vs+qt5.0 使用poppler-qt5 操作库获取pdf所有文本输出到txt操作
- 10超级详细的GitLab安装 与使用 【Gitlab添加组、创建用户和项目、权限管理】_gitlab群组_gitlab创建账号,分配权限
[图形学渲染]大白话推导三维重建-摄像机内参(Intrinsic)、外参(extrinsic)、世界坐标相机坐标转换、3D物体投影归一化、单双目摄像头、视差(Disparity)_摄像头内参
赞
踩
前言
参考资料:
1.B站MIT逆向图形学中的机器学习6.S980
一、背景知识学习
在日常生活中,光线与物体界面的交互,构成了我们眼里的图像。
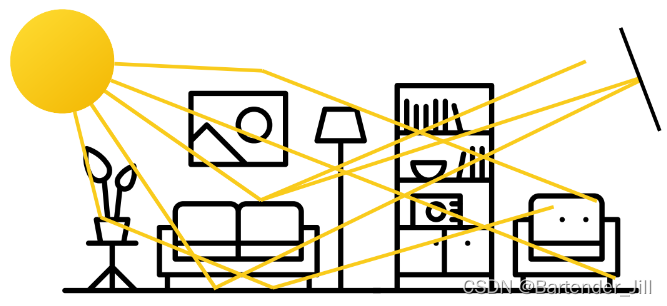
但是为什么只有眼睛有成像,而像墙壁/桌子等这些平面上不会成像呢?
比如我举着一张纸在半空中,周围环境的物体上的光线也会照到这张纸上,但为什么纸还是一片空白没有图像呢?
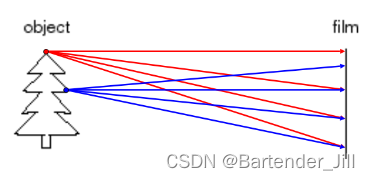
原因是因为纸上接收到的光线过于繁杂,纸上的一个点会接收到无数物体反射来的光线,从而什么都显示不出:
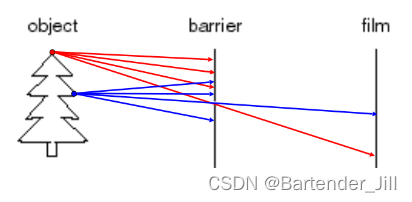
于是,针孔摄像机就出现了。假设我们在纸和众多光线之间加一个隔板,隔板中开一个小孔。当中间的的孔足够小时,孔中只能透过一根光线,即纸上一个点就对应一条光线,这样我们就能在纸上看到一颗清晰的倒着的树的成像(之所以是倒着的,是因为光线要到孔的另一边的话,基本只能是斜着进入,除了正对着孔中心的那跟光线才可能正对着孔平行射入):

1.1 3D场景 to 2D图像
而我们的3D场景摄像机也是运用了类似的原理,假设现在有只可爱的小牛牛和一个摄像机,那么成像过程如下所示:
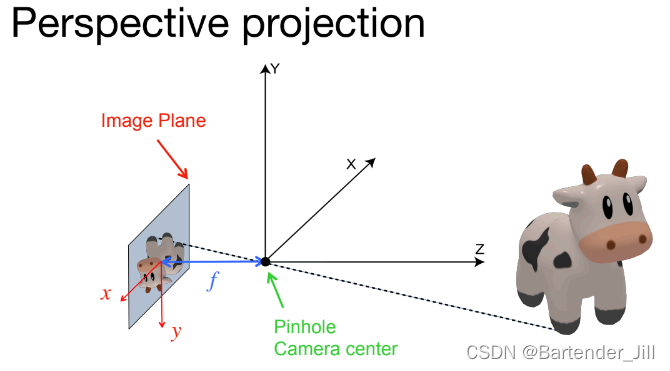
由上图可以看到,Image Plane有着自己的Image坐标系。
这样镜像翻转看终究有点别扭,我们不妨调整一下:
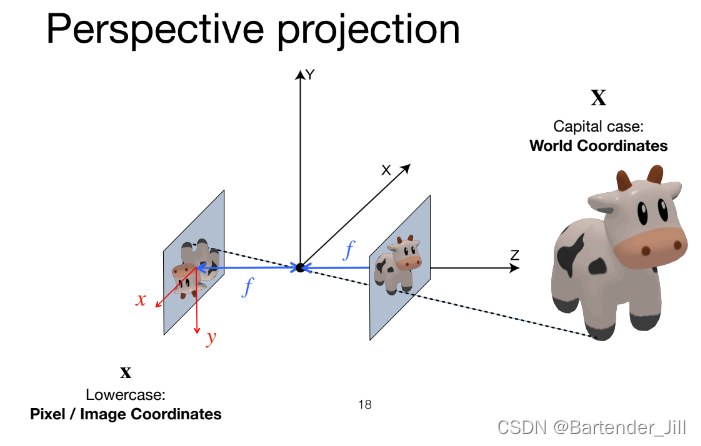
如果只看前面部分的投影牛牛:
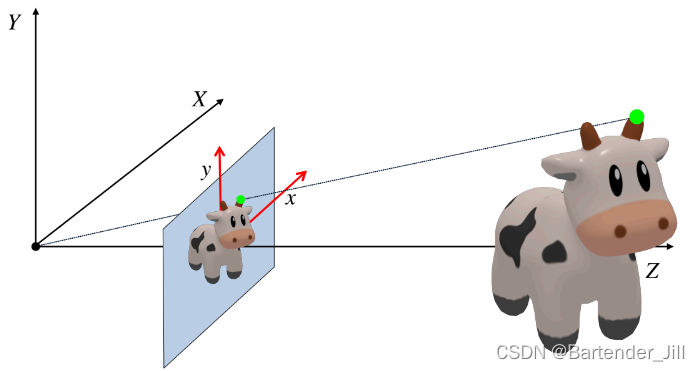
这时投影的2维牛牛上每一个点都能对应着3D牛牛的唯一一个点。
为了方便后续公式推导,我们把牛牛去掉,只看正面的坐标系:
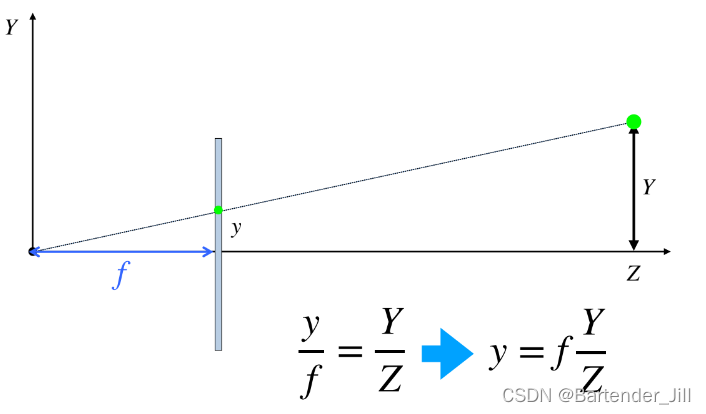
已知3D牛牛在3D世界某个点距离摄像机的深度Z和高度Y,以及摄像机的焦距f(focal length),那我们利用相似三角形公式,能很快推出2D牛牛的对应点具体坐标(x,y)。
注:深度并不是点到摄像机center那根斜线,而是底部的Z长度
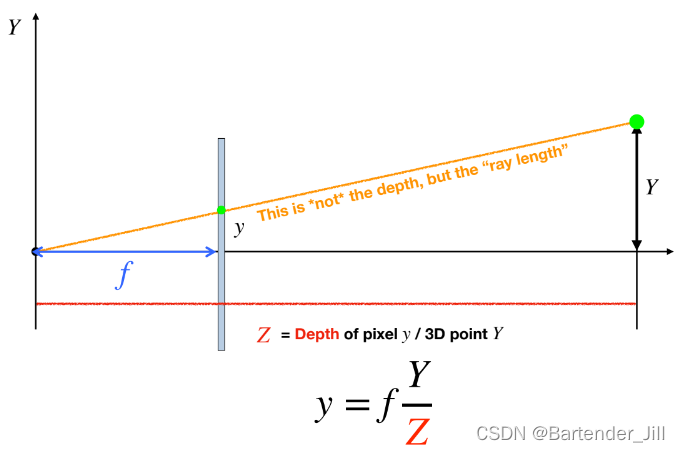
至此,我们就得到了3D牛牛世界坐标与图像平面坐标的换算关系:
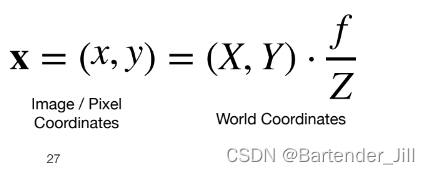
且我们还能用这个换算关系推断出有意思的东西。
2D场景能保留3D场景的直线和相交信息,比如3D场景有根直线,那你在2D图像看也是直线。3D场景有两根线重合,那你在2D图像看那两根线也会重合。
但是2D场景难以保留3D场景的角度和长度信息。比如3D场景中有个铁路,并不相交,你却会觉得两根铁轨在无穷远处相交于一点:
我们可以用公式来进行类似的证明,假设现在3D场景有一根无限长的直线,那么在2D图像的投影是这样的:
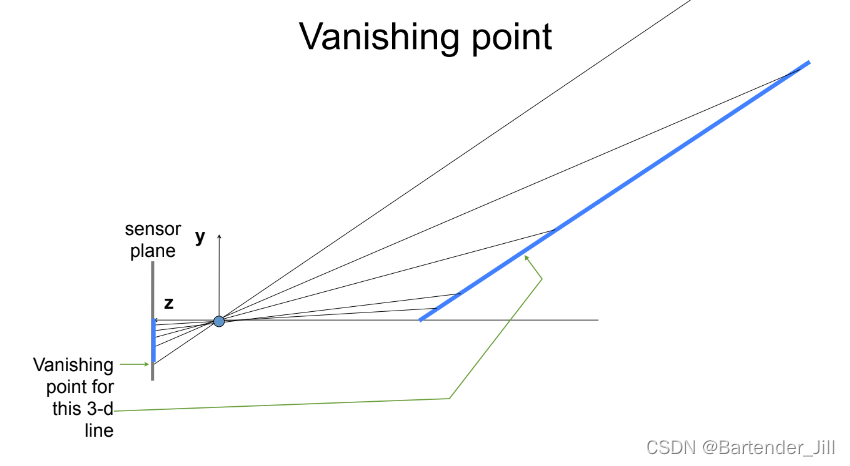
我们可以看到距离无限远时,左边2D平面接收到的最下面的光线线很难再往下移动了,它们汇聚在一个叫Vanishing point的点上。
可以用取极限的方式进行推理,十分简单:

可以看到最后点聚集在(fa/c,fb/c)坐标上。
且在现实中,我们很难判断2D图像中的物体实际上在3D环境中的位置:

两个人其实差不多高,只是房间构造和人物距离的设定使得成像后有视觉误差,具体可以看GAMES101课程的内容。(鸽子为什么会这么大?)
1.2 矩阵运算表达
由于矩阵运算在多维场景下更方便,我们不妨将上述公式以矩阵形式表达:
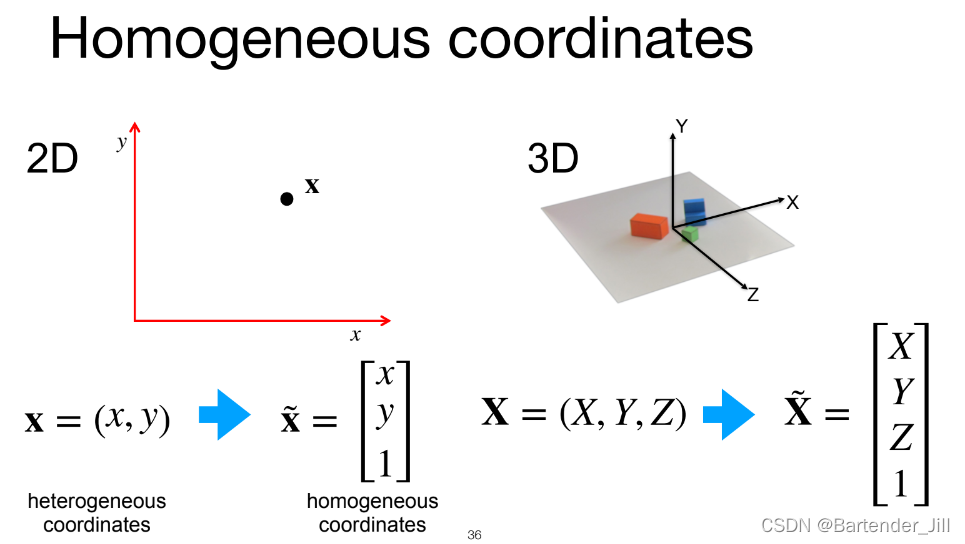
我们将原先的2维坐标和3维坐标都以齐次坐标形式进行表示,故两者的换算关系现在变成下面这样:
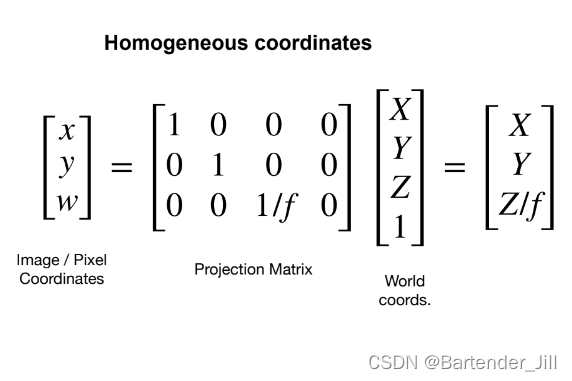
进一步:
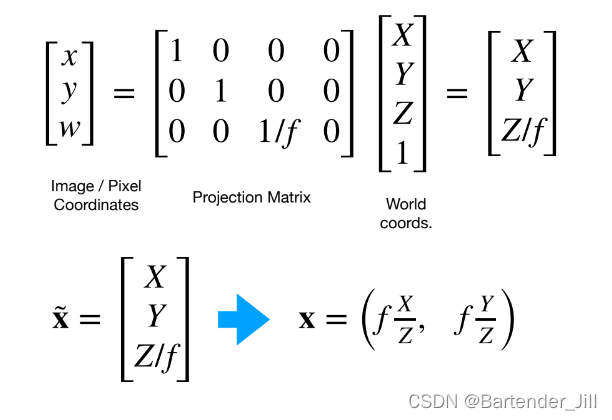
到这里,我们就知道了3D牛牛的一个坐标[X,Y,Z]在已知相机焦距f的情况下,是如何转换到2D牛牛的,即乘上一个叫做Projection矩阵的玩意,太简单辣!
当然,这时候你可能会奇怪,这个[x,y,w]中的w是怎么来的?其实[x,y,1]坐标在同时乘或除上一个系数时,该坐标保持不变,比如[xw,yw,w]、[x/w,y/w,1/w]和[x,y,1]都是表示一个点:
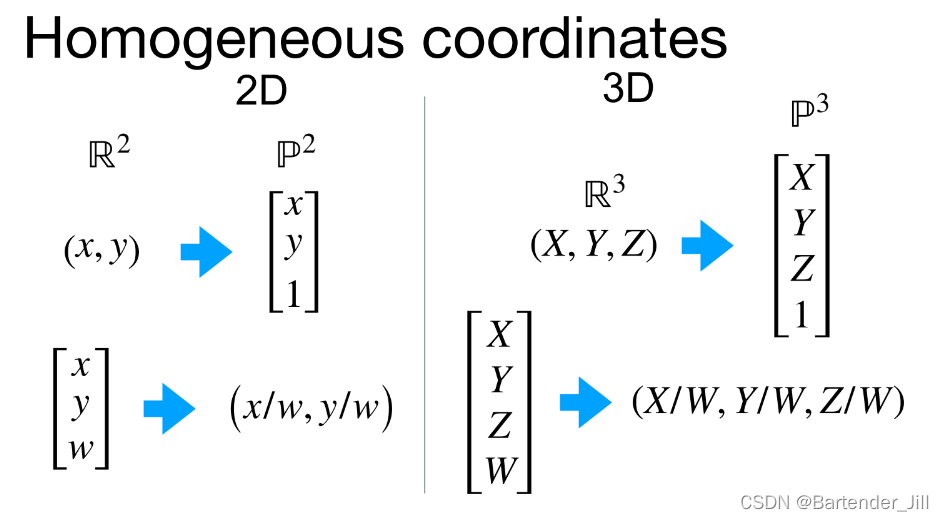
所以为了通用性和后续处理,就写成[x,y,w]。
1.3 摄像机坐标系原点设置
上述我们说到,3D物体到2D成像,需要用到世界坐标到图像坐标的转换公式,中间会乘一个叫透视矩阵的玩意,该玩意其实也有多种表达形式,看你怎么方便怎么来:
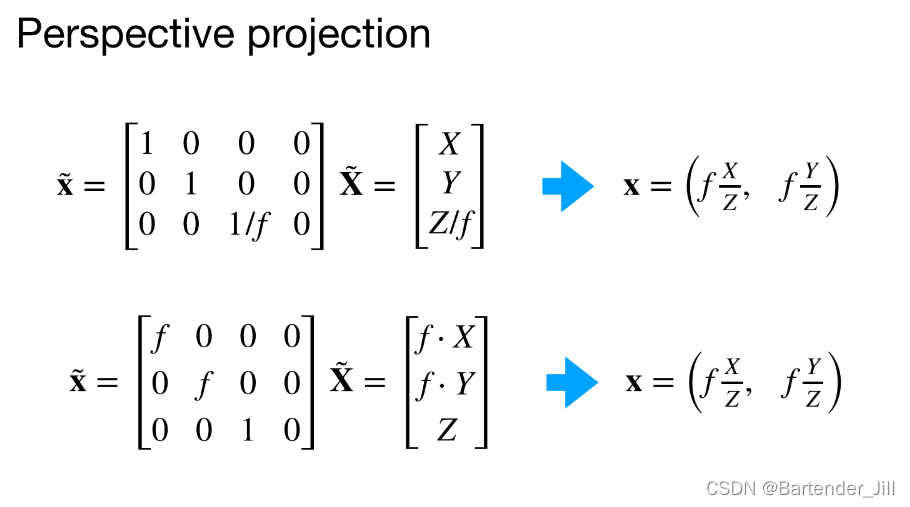
但现在问题来了,我们推一个公式要尽量符合通用性,比如我们上面就将[x,y,1]换成了[x,y,w]。
但是我们的公式仍然有不足之处,比如该公式只能满足相机平面在中心的情况:
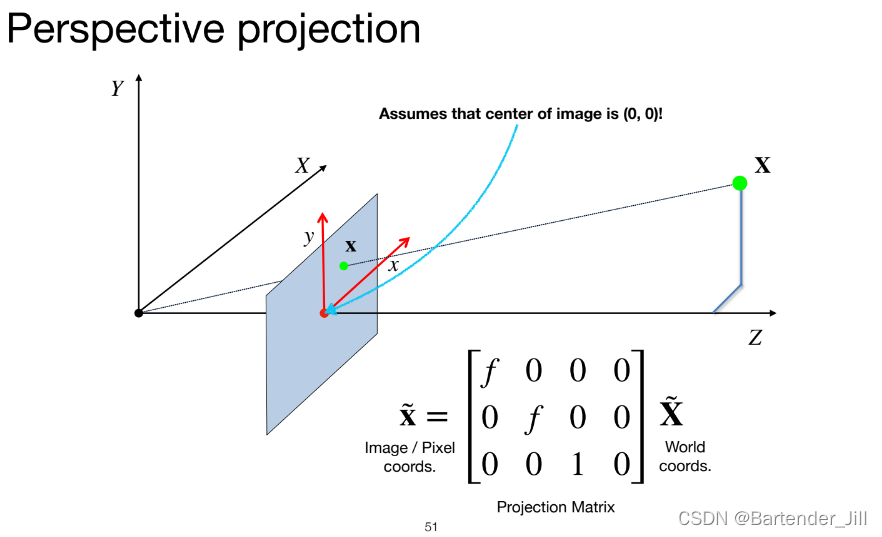
但是了解过图像实际存储格式的人应该清楚,比如像numpy等定义的矩阵,其坐标原点是在左上/下角而不是在中心的,上述所说的公式用不了。
故我们再进一步推导:
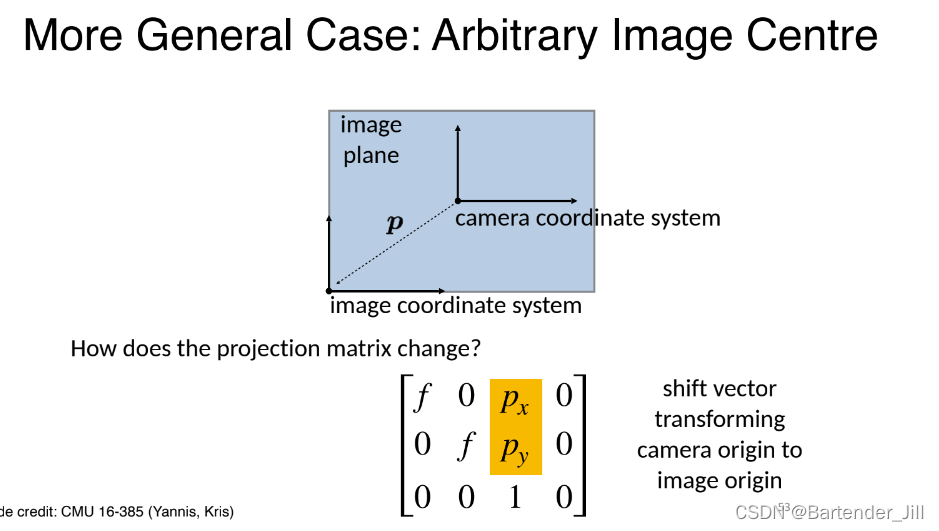
假设我们的图像中心是在图像某个角落,距离图像中心为p,那我们只要在Projection矩阵里加上一个中心到该角落的位移值(px,py)即可。(详细部分可以看网上的物体矩阵旋转、位移换算资料)。
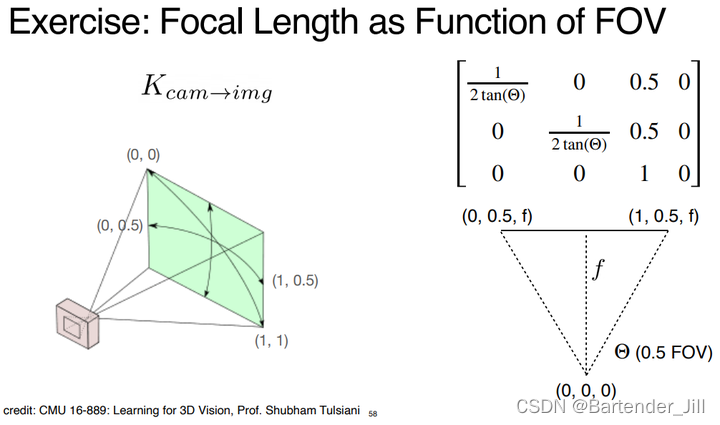
1.4 FOV 与 摄像机焦距 换算
当然有的时候并不会直接给出摄像机焦距,而是给出FOV,这时候就要用到以下公式自己进行换算:
二、内参矩阵
2.1 内参矩阵定义
上面我们讲述了如何将3D环境中的物体投影到任意坐标系的图像平面,接下来我们再进一步讲述一些常用的概念。
我们可以将我们推导出来的Projection矩阵拆成以下两个部分:
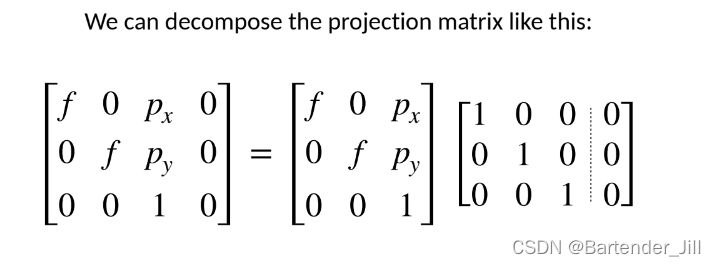
为什么要拆呢?因为原先的矩阵第四列全是0,属于没用的信息,我们要只关注有用的信息。
我们不妨把这个有用的信息矩阵称为K:
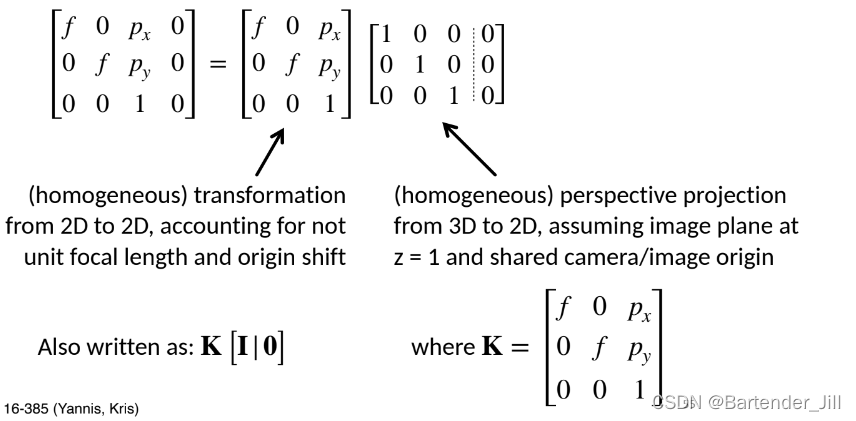
这个K就是我们经常在各个摄像机规格书或数据集看到的相机内参矩阵(Intrinsic Matrix),其是一个3x3的矩阵,对角线有该相机焦距信息,并在最后一列有着像素偏移量。
2.2 内参矩阵和归一化空间的作用
我们已经将3D物体转换成2D投影平面了,那接下来怎么把该平面上的内容转换成图像像素呢?
有人可能会问,这个2D投影平面不就已经是图像了吗?其实图像的定义比较模糊,我们这里要讨论的此图像非彼图像。2D的投影平面是相机捕捉到的图像,但并非是实际呈现在相机传感单元上的图像。
相机捕捉到的图像尺寸并不固定,是一种虚拟的概念。而相机传感单元却是有限制的,比如256x256。那么我们要怎么将2D投影平面的图像转换成实际摄像机传感单元上的图像呢?
你可能会想:“这还不简单,直接按照长宽等比例映射,中间再用一些插值技术balabala不就行了。”
实际上,道理是这么个道理,但并不能很好的符合开发需求。你的2D投影平面尺寸大小随时都可能按照用户设定进行改变,而相机传感单元分辨率也会随着相机不同而随之改变。
故OpenCV为了提供一个统一化的接口,即在相机图像到用户屏幕图像中还加了一个归一化(Normalized)的过程。
而我们的内参矩阵K作为有用信息,在这里进一步细分,分成图像->相机,相机->像素的变换矩阵:
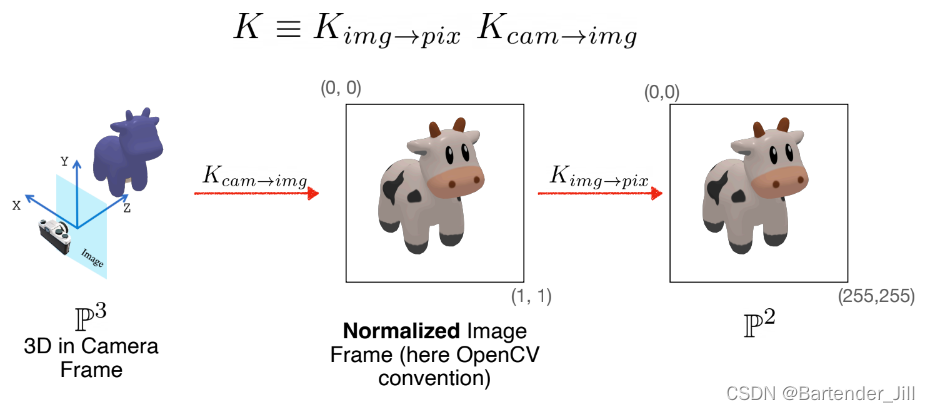
这样一来,图像映射关系维护起来就简单了很多。
对于摄像机而言,其不用管实际传感单元分辨率为多少,只要将捕获到的2D图像通通转为一个归一化的空间即可。
对于摄像机实际传感分辨率而言,其不用管原先捕获到的图像尺寸是怎么样的,只要负责从固定的归一化空间里的图像映射到自己的传感单元分辨率上即可,从而实现一个相对固定的映射计算方式。而不用考虑捕获的图像尺寸是否变化。
三、摄像机外参
3.0 三维重建背景知识
假设现在你有一个RGBD相机,你用该相机拍摄了一个场景,从而有了该场景的RGB信息和深度信息(Depth),那你要如何从2D的图像里恢复出3D场景的点云呢?

我们上面提到了我们可以将3D物体坐标转换到2D图像坐标,那我们很容易想到一个思路:求逆
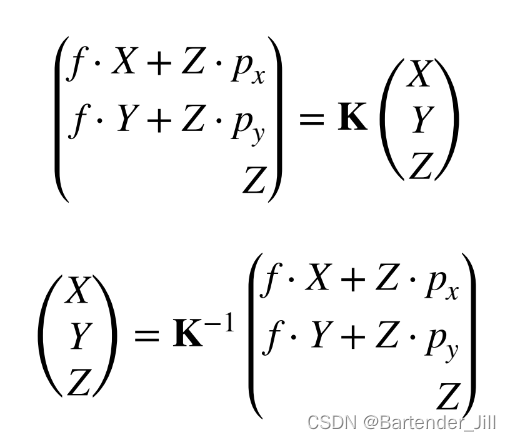
由上图我们可以看到,给定3维坐标(X,Y,Z),以及相机内参矩阵K,我们可以得到相机平面下的(x,y)坐标,至于深度信息Z并没有用到。(为了方便起见,我们这次先不用齐次方式来描述坐标)
但当给定一个2维图像的坐标(x,y),我们缺乏了深度信息Z,并不能恢复成3维坐标,我们只能恢复3维环境下的一条已知X,Y的直线(X, Y, ?),相当于对3维的一根直线进行了参数化,表明经过该X,Y的有可能的点所构成的直线。(如果你在做可微渲染器,那你可能会利用这条线,因为你需要知道该点所有深度上的颜色)
为了三维重建,我们接下来要引入相机外参(extrinsic)这个概念。
3.1 World to Camera
上面在讲内参的时候,我们的相机是摆放在一个3D场景中某个固定位置的(比如原点)。
但我们往往会希望用一组相机,摆放在不同位置,观看一个3D场景,从不同角度推断出来该场景是怎么样的。
现在假设我们有一个相机,相机中心距离世界坐标原点 t ( 3x1的向量 ):
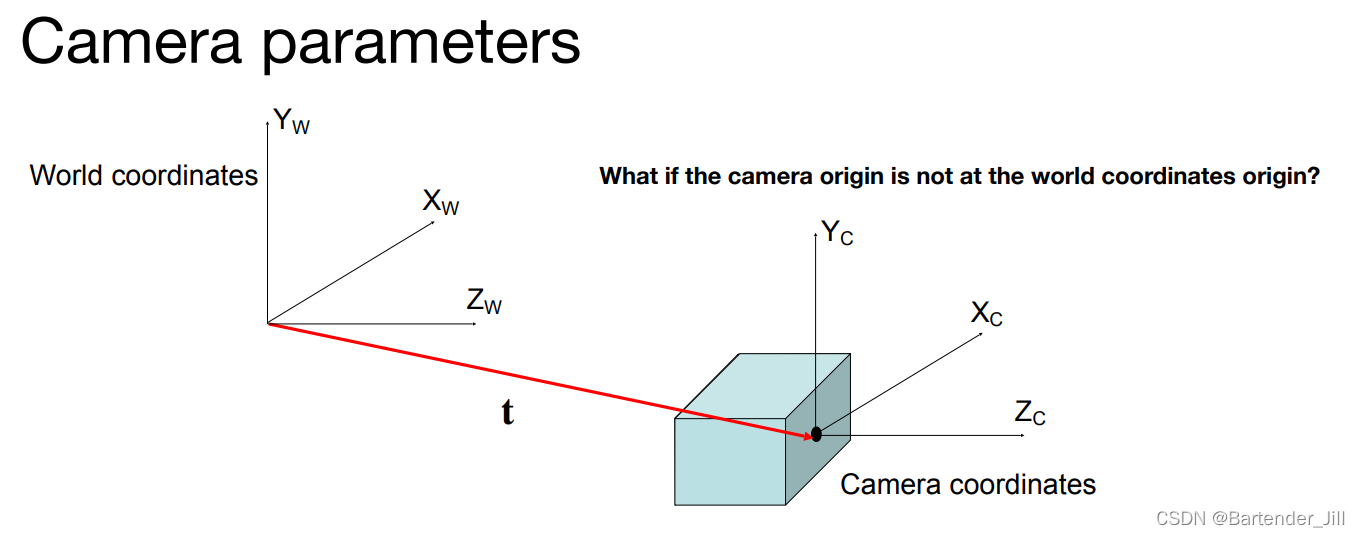
那么在这种情况下,3D里的一个点在世界坐标以及在相机坐标的关系可以用高中学到的三角向量公式推导得到:
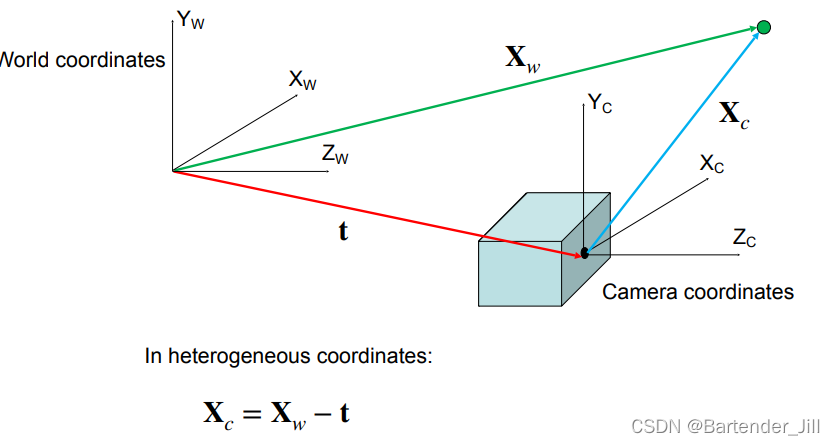
要注意的是,这里绿色的点在相机坐标系中的位置是3D的,与我们前面讲的内参2D平面坐标不一样,切记别搞混!
除此之外,相机除了位移,还可能发生旋转,那么公式就进一步变成:
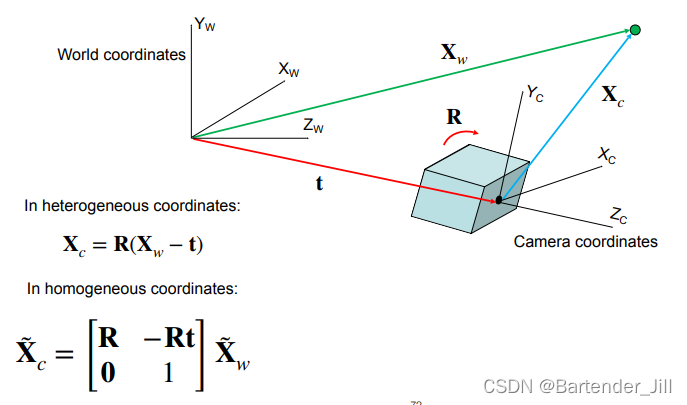
你可以以非齐次的形式在原先公式基础上左乘上一个旋转矩阵R(3x3的矩阵),也可以齐次的形式将该坐标变换关系写成矩阵运算形式,两者是等价的。无非就是Xw由(X,Y,Z)变成了(X,Y,Z,1)。
该矩阵即为World to Camera矩阵(W2C),别看它维度是2x2,实际上是4x4,R是一个三维旋转矩阵,Rt是一个1x3矩阵。
W2C矩阵也在许多数据集里被称之为Camera Poles:
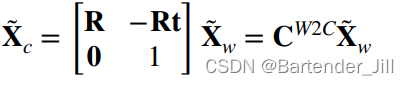
该矩阵,即为外参矩阵
3.2 补充知识: Camera to World
这个W2C矩阵说白了就是将世界坐标转换为相机坐标的一个矩阵,而它的逆矩阵自然就是Camera to World矩阵(C2W):
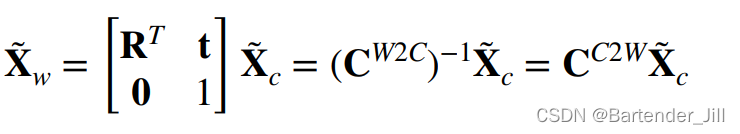
四、内参和外参总结
Q:为什么称之为内参和外参?
A:因为内参是摄像机本身固有的参数,只与相机本身有关;外参与相机在世界坐标摆放关系有关,与相机本身无关。
至此,我们终于打通了整个3D空间点到相机像素成像的Pipeline:
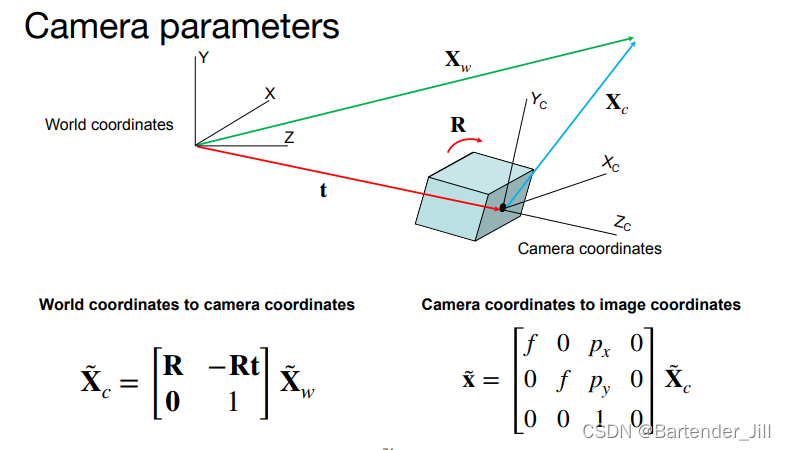
- 先用左边公式将世界坐标系里的一个点转换成任意摄像机坐标系里进行表示。
- 再用右边公式将相机坐标系下的3D坐标点转换成相机上的像素。
结合起来即为如下公式:

有了这个公式,你可以用来写一个简单的渲染器。
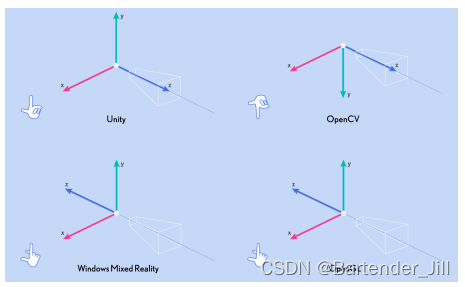
而关于px和py具体要取什么值,取决于你的应用场景,这里给出几个常用的坐标系场景:
五、三维重建
5.1 不同摄像机的特点

如果我们竖起一根笔放在两眼前,然后遮住右边的眼睛,可以看到笔位置朝左偏了。遮住左眼的话则会看到笔位置朝右偏了,这就是单目视觉带来的视差问题。
而我们在用两只眼睛的时候可以让我们更好的感知立体信息,避免了这种视差效果。
你可能会说,人在用一只眼睛的时候也能正常生活,没什么问题,避障捡东西都可以,这是为什么?
其实人眼获取的是RGB信息,并不能直观地获取到深度信息,不清楚场景中的某个物体具体离我们多少米,我们能避障是依赖于我们学习到的经验,通过参考物体脑海中自动有了大小远近的概念从而进行避障。
而只要跟人学习经验有关的事情,放在计算机里往往就是要用深度学习的方式进行解决。这就是为什么双目RGB摄像头可以依赖自己的信息获取深度信息,而单目RGB往往要配合神经网络才能出好的效果。
5.2 三维重建基本原理
我们上文提到,要从2D像素恢复到3D空间中的点,需要深度信息Z,有了这个 Z ,恢复起来就简简又单单。
单目RGB摄像头只能通过估计(Estimation)的方式进行恢复,而双目摄像头则可以通过计算的方式进准确得到 Z 的值,从而进行恢复。
假设现在有两台摄像机 X1 和 X2 (类似于人的双眼),3D空间中有一个绿色的物体,且相机都已经标定准确(绿色点对它们来说是同一个空间中的点),成像点是 Xl 和 Xr ,如下图所示:
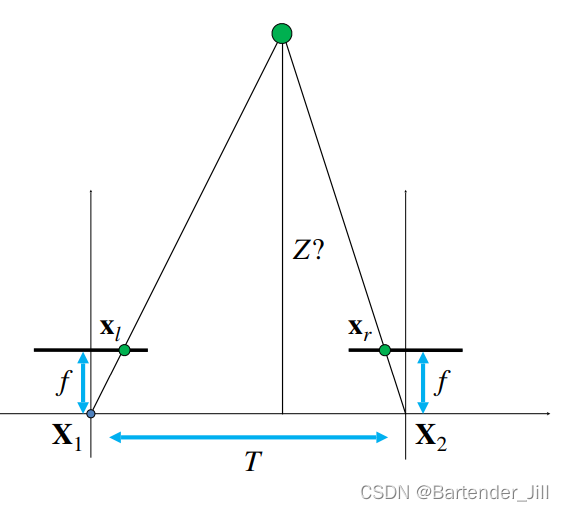
要求解这个Z的值(注:前面已说过,深度是指到摄像机所在平面直线而非斜边),需先构造相似三角形:
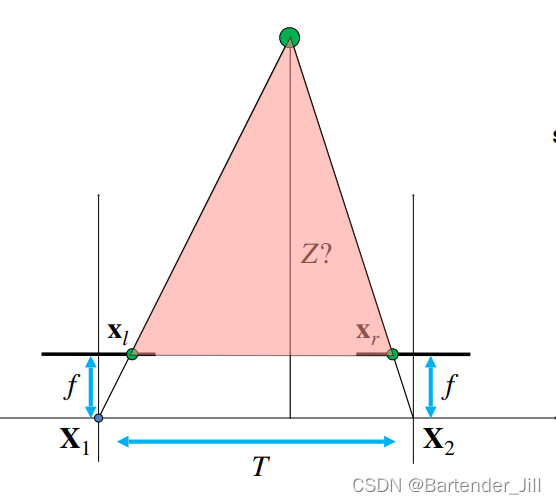
再由相似三角形得到以下公式(两相似三角形底边与高之比相同):
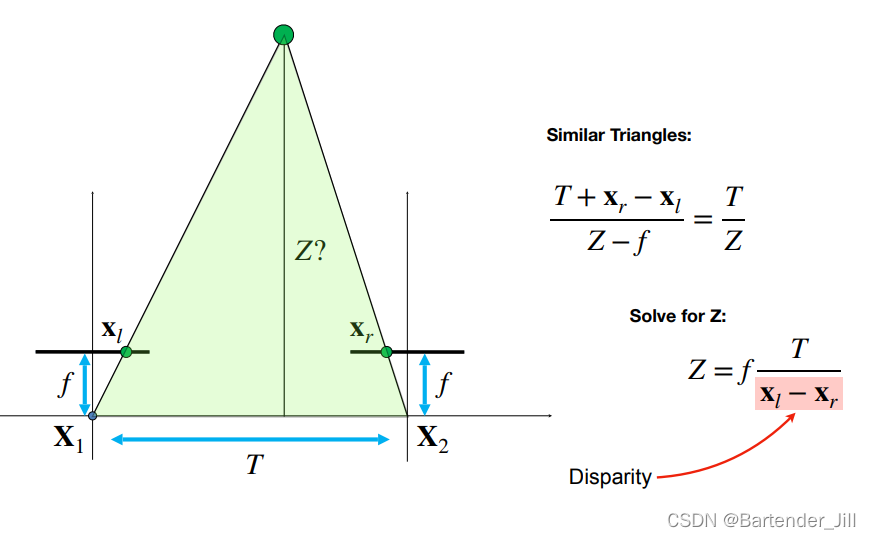
注:这里的 Xl 和 Xr 是摄像机自己的局部坐标系下的值,这意味着Xl是正的,Xr是负的。
Xl-Xr也被称之为视差(Disparity)。
那么问题来了,两个不同坐标系下的值,如何进行相减运算?如何获取这个视差?
5.3 视差(Disparity)
我们用左右摄像头同时拍一张图片,可以看到相同位置却成像不同,这就是视差:
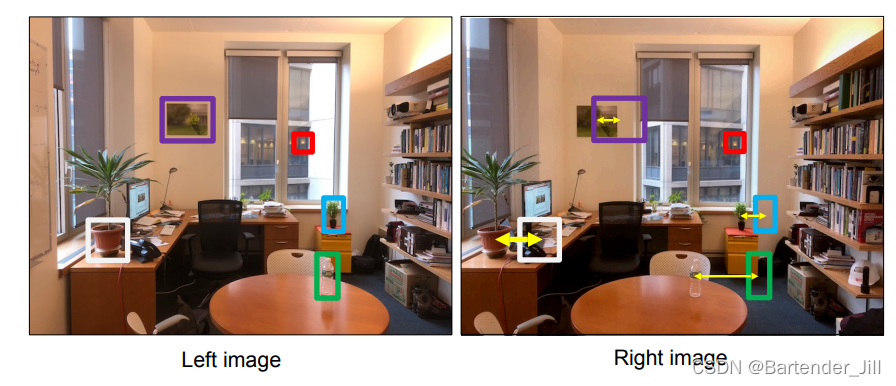
越近的物体改变越明显,越远的物体视差越小。
最直观的思路就是,如果我们在左右图构建像素之间的映射关系,然后作差,即可得到我们所需的视差数据D(x,y):

这个深度数据是我们用双目摄像机计算出来的,也正是深度摄像机所能测量的结果。
那么问题来了,这个D(x,y)函数如何构建?我们如何清楚两张图像中像素移动了多少?
你可能会想到,直接编写一个暴力判断两张图片RGB值一样的像素然后直接计算距离不就行了吗?
但事实上,暴力循环判断两个像素值是一件十分困难的事情,比如上图中第一张图片的桌子里有反光,第二张桌子里的反光却很不明显,这就会导致很多误判。
故我们不能只凭借像素的RGB值来判断像素是否相同,而是要找某些特征点进行匹配,比如对极几何、Harris角点等。这便涉及到图像匹配的相关知识,由于篇幅所限,这里不过多展开,个人打算在后续教程篇章再进行更新。
总结
以上就是三维重建的基本原理推导过程,本人也是初学者,如有问题,欢迎指出。

