
- 1关于cannot import name ‘nms_rotated_ext‘ from partially initialized module ‘utils.nms_rotated‘问题解决
- 2【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 卢小姐的生日礼物(200分) - 三语言AC题解(Python/Java/Cpp)
- 3Java的并发编程与虚拟线程Java 17中的Record类Java 16中的Switch表达式Java 11中的局部变量类型推断 [包含示咧]
- 4计算机网络联考复习题_如果源节点知道目的地的ip和 mac 地址的话,信号是直接送往目的地
- 5sourcetree安装过程中的注意事项:_sourcetree安装报错
- 6Java二十三种设计模式-抽象工厂模式(3/23)_java设计原则
- 7Git | git的简单使用教程_downgit
- 8VPN和NAT服务搭建_搭建nat服务器
- 9ComfyUI 基础教程(十四):ComfyUI中4种实现局部重绘方法_comfyui局部重绘工作流
- 10语义分割的几种网络模型_语义分割最新模型
H100利用率飙升至75%!英伟达亲自下场FlashAttention三代升级,比标准注意力快16倍...
赞
踩
明敏 克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
大模型训练推理神作,又更新了!
主流大模型都在用的FlashAttention,刚刚升级第三代。
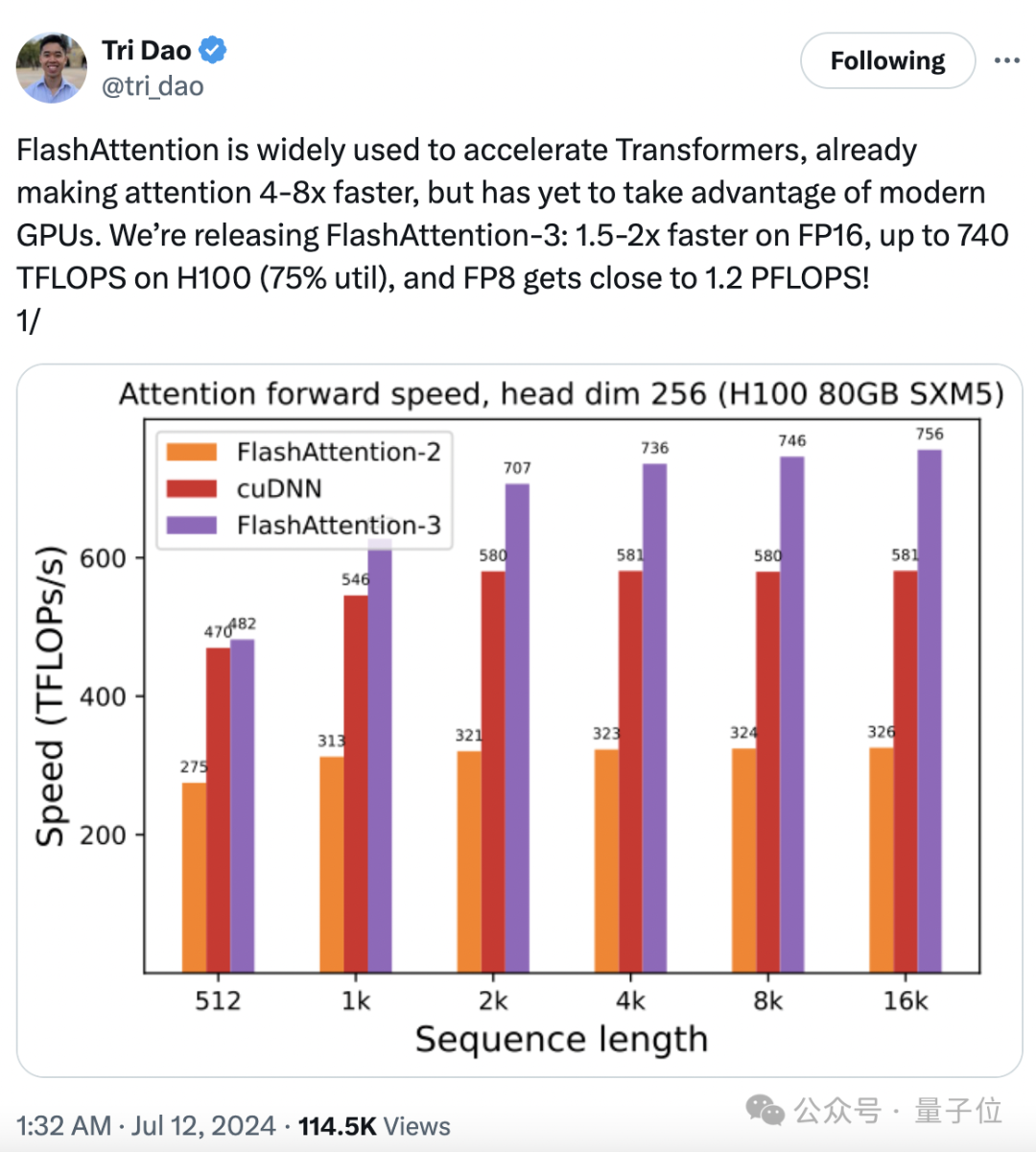
时隔一年,FlashAttention-3已经全方位升级。
训练速度提升1.5-2倍,FP16下计算吞吐量高达740TFLOPs/s,达理论最大吞吐量75%,更充分利用计算资源,此前只能做到35%。
FP8下速度接近1.2PFLOPs/s!
同时误差也进一步减小,FP8下的误差比标准Attention减少2.6倍。
而且这一次,不再是一作Tri Dao单打独斗,FlashAttention-3直接和英伟达、Meta、谷歌等合作,针对最强芯片H100专门做优化。
英伟达CUTLASS团队和cuDNN团队,都直接为该研究提供支持。

同时和前作一样,FlashAttention-3也将开源,PyTorch和Hugging Face中都集成。
作者之一Vijay Thakkar激动表示:
曾经在FA2发布时,我就说过这句话。今天,我想再说一次:
看到CUTLASS和CuTe被用来开让Tensor Core大显身手的新算法,真的泰裤辣。
前Stable Diffusion老板Emad也非常关注这一进展,他推测使用FlashAttention-3,能将4090的FP8计算吞吐量推升到700+TFLOPs。

充分利用Hopper架构特点
自初代发布以来,FlashAttention已经使大模型速度提高了4-8倍,但还有一个遗憾:尚未充分利用现代 GPU。
针对英伟达H100倍后的Hopper架构新特性,三代进行了专门优化。
整个系列的核心思路,是IO感知优化和分块处理。
作者认为,传统的注意力机制效率低的原因,在处理长序列时,会出现内存访问操作频繁,以及算法复杂度指数级暴增这两大问题。
FlashAttention通过IO感知优化将数据从较大但缓慢的高带宽内存(HBM)加载到较小但更快的片上内存(SRAM),在SRAM中执行计算,减少了内存读写操作的次数。
分块处理则是将输入序列分成若干小块,每次只处理一个小块的数据。这种方法使得每次处理的数据量减少,从而降低了内存使用和计算复杂度。
这样一来,两个关键问题就得到了解决,这两大核心思想也在本次的FlashAttention-3中得到了继承。
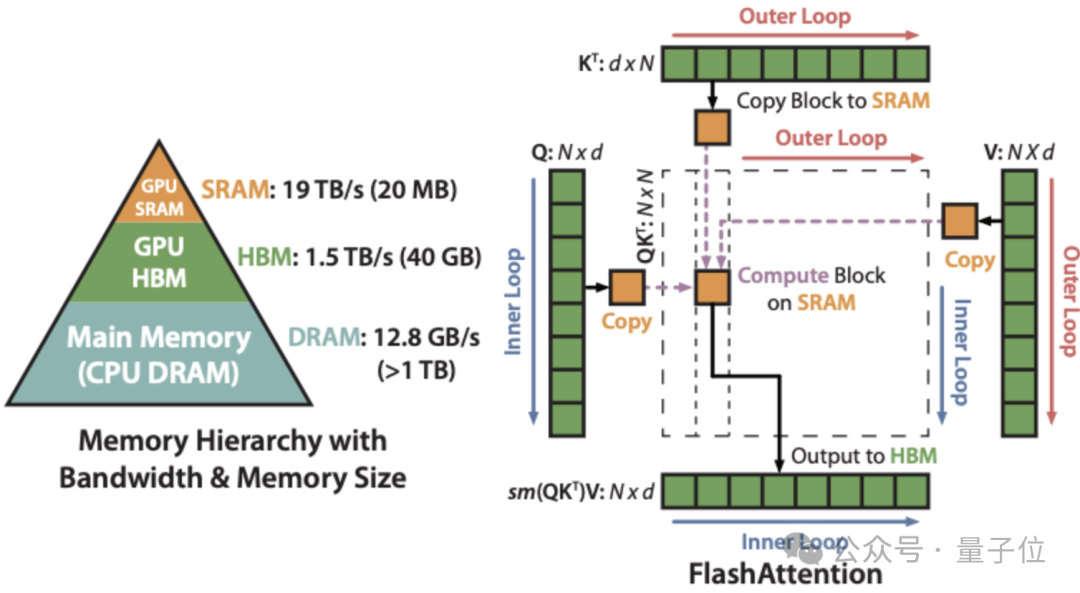
△第一代FlashAttention原理图
但是,第一代的FlashAttention也遗留下了并行性不够强、工作分区划分不合理,以及非矩阵乘法较多(GPU计算单元处理矩阵乘法比非矩阵速度更快)的问题。
针对这一问题,第二代FlashAttention通过重写softmax,减少了重新缩放操作、边界检查和因果屏蔽操作的次数,使得大部分计算集中在矩阵乘法上。
另外,FlashAttention-2引入了序列长度维度上的并行化,并针对工作在线程块之间的分配进行了优化,GPU利用效率更高了。
可以说前两代当中,作者一直坚持着充分利用硬件特点这一思路,但站在今天的视角来看,对硬件的挖掘仍然不够充分。

到了这次的FlashAttention-3,由于是直接和英伟达官方合作,对英伟达Hopper架构特点的理解更加透彻,软硬件之间的协同进一步增强了。
FlashAttention-3的技术报告显示,为了充分匹配Hopper架构,团队主要做了三方面的技术升级。
首先,Hopper架构的一个重要特点是Tensor Core的异步性,FlashAttention-3针对性地提出了一种异步方式。
具体来说,FlashAttention-3引入了一种“生产者(Producer)-消费者(Consumer)”的编程模型,将注意力的计算划分为两个角色。
“生产者”负责将数据从HBM异步加载到片上共享内存(SMEM)。这个过程主要利用了Hopper GPU的张量内存加速器(TMA),可以在不阻塞CUDA核心的情况下进行数据传输。
消费者直接从共享内存读取数据,并使用Tensor Core执行矩阵乘法等计算密集型任务。由于共享内存的访问延迟远低于全局内存,消费者可以快速获取所需数据,提升计算效率。
△Hopper中的张量内存加速器
为了实现角色的划分,作者引入了warp专门化技术,用不同的warp分别匹配生产者和消费者,让两者可以并行执行。
这其中利用了Hopper架构的动态warp寄存器分配特性,通过setmaxnreg指令优化了寄存器资源的利用。
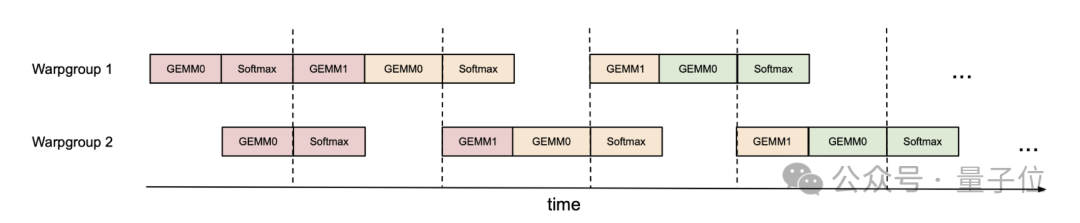
为了进一步提高GPU的利用率,作者又提出了一种“乒乓调度”策略,让一个warp组执行矩阵乘法时,另一个warp组执行softmax,从而实现计算的重叠。
具体讲,FlashAttention-3使用CUDA的同步原语控制不同warp组之间的执行顺序,让不同warp组分别执行两种运算,然后像乒乓球一样交替运行。
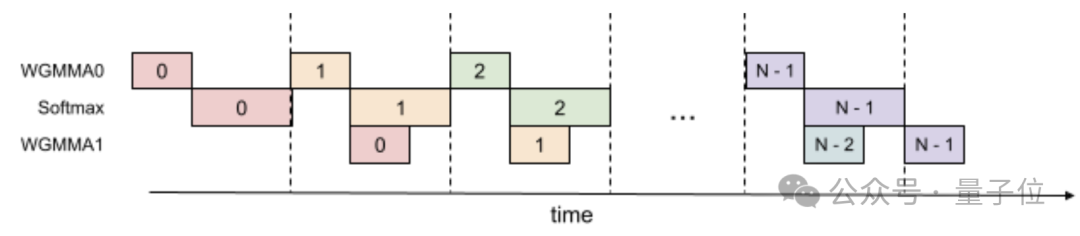
第二大技术特点,是warp组内部GEMMs和softmax的重叠,核心奥义是重新安排计算的执行顺序以提高GPU利用率。
与乒乓调度不同,这里的计算重排处理的是warp组内部的重叠,而乒乓调度更关注组间协调。
实现方式上,FlashAttention-3提出了一种两阶段GEMM-softmax流水线方案,以打破不同操作之间的数据依赖。
第一阶段,当前迭代(iteration)的softmax操作与下一个迭代的Q·K^T矩阵乘法重叠执行。
第二阶段,当前迭代的P·V矩阵乘法与下一个迭代的softmax操作重叠执行。
通过引入额外的寄存器和共享内存缓冲区,FlashAttention-3实现了跨迭代的数据传递和重用。
在每个迭代中,Q·K^T的结果首先存储在名为S_cur的缓冲区中,用于当前迭代的softmax计算,同时异步执行下一个迭代的Q·K^T矩阵乘法,结果存储在名为S_next的缓冲区中。
在执行当前迭代的P·V矩阵乘法时,异步执行下一个迭代的softmax操作,并更新S_cur和S_next缓冲区。
第三项更新,是用更低的FP8精度替代FP16。
实际上,降低数值精度是一种常见的优化策略,可以显著提高GPU的计算吞吐量和能效,Hopper GPU也引入了FP8精度的Tensor Core支持。
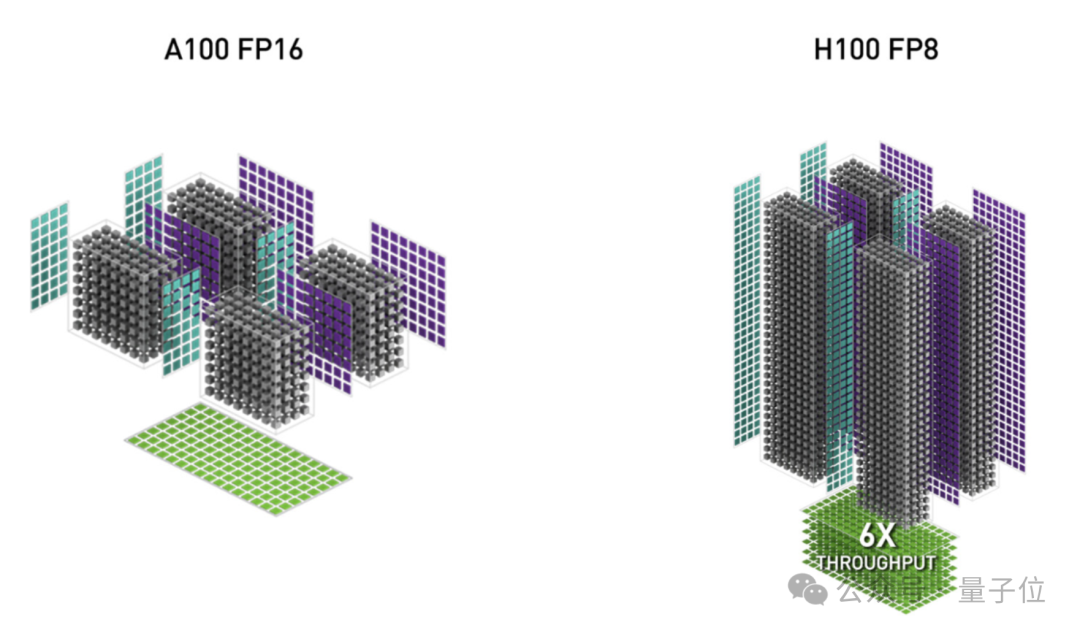
但是,直接将注意力计算从FP16转换为FP8可能会引入较大的精度损失。
另外,FP8 Tensor Core对输入数据的布局也有特定的要求(K维度连续),不幸的是,注意力计算中的输入数据存储格式(头维度连续)并不符合这样的要求。
所以FlashAttention-3首先引入了一系列内存布局转换技术,动态转置V矩阵的块,改变其连续方式,从而适配FP8 Tensor Core的布局要求。
在此基础之上,为了获得更高的计算精度,FlashAttention-3又采用了分块量化和非相干处理技术。
传统的量化方法通常对整个矩阵使用一个统一的缩放因子(per-tensor quantization),无法很好地适应不同区域的数值范围。
FlashAttention-3则采用了分块量化(block-wise quantization)的策略,为每个块单独设置缩放因子,更好地捕捉局部的数值分布。
非相干处理(incoherent processing)技术则是通过随机正交矩阵对输入数据进行旋转,破坏不同块之间的相干性,减少量化误差的传播。
这两项技术的结合使得FlashAttention-3在FP8精度下取得了更高的计算精度,显著优于传统的量化方法。
结果,与基于传统量化方法的FP8实现相比,FlashAttention-3的使得精度提高了2.6倍。

比标准Attention快16倍
以上就是FlashAttention-3在充分研究Hopper架构特点后做出的三大更新,针对更新后的表现,作者主要进行了3方面测试。
注意力基准测试
消融实验
FP8注意力准确性测试
首先来看注意力基准测试。
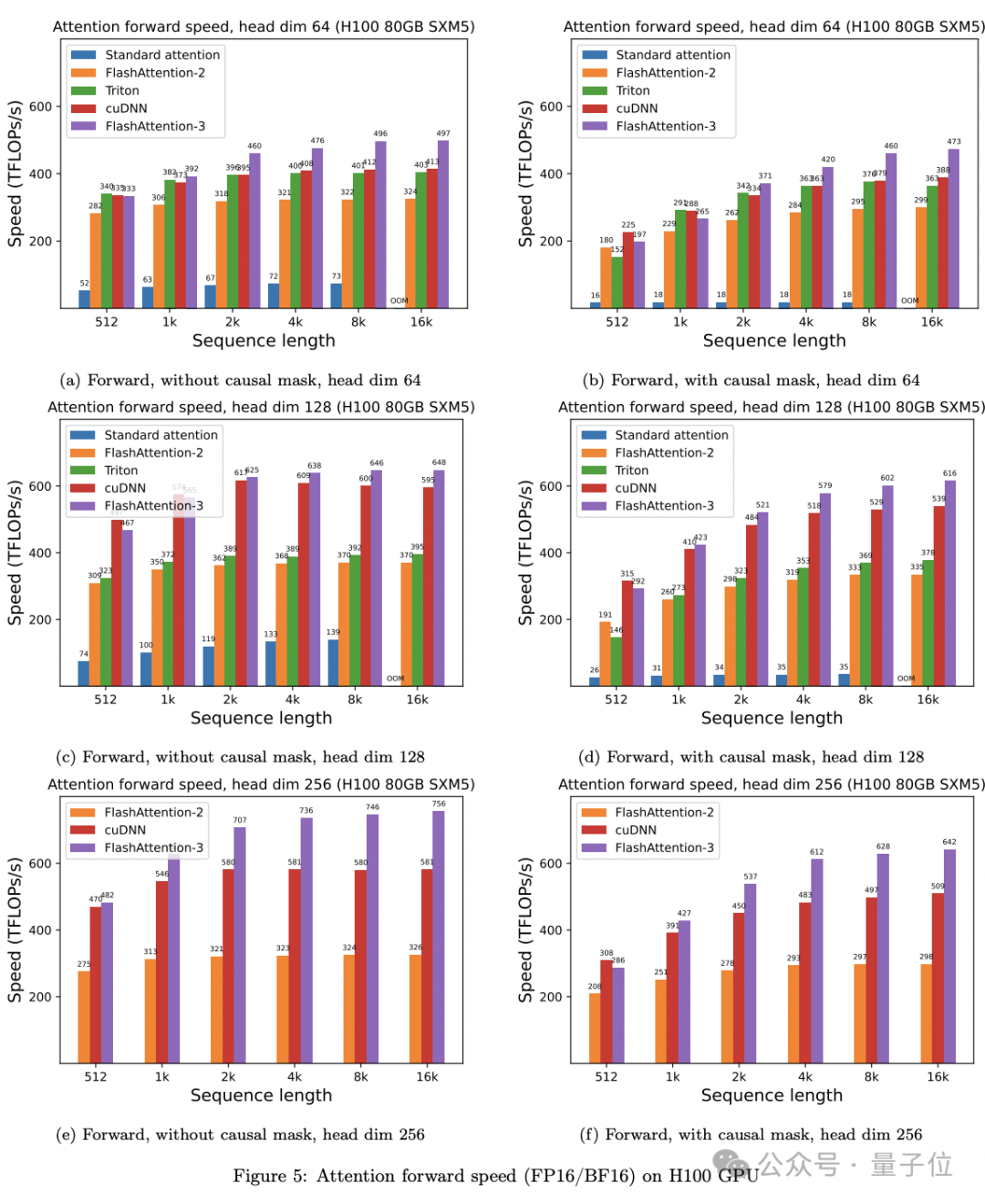
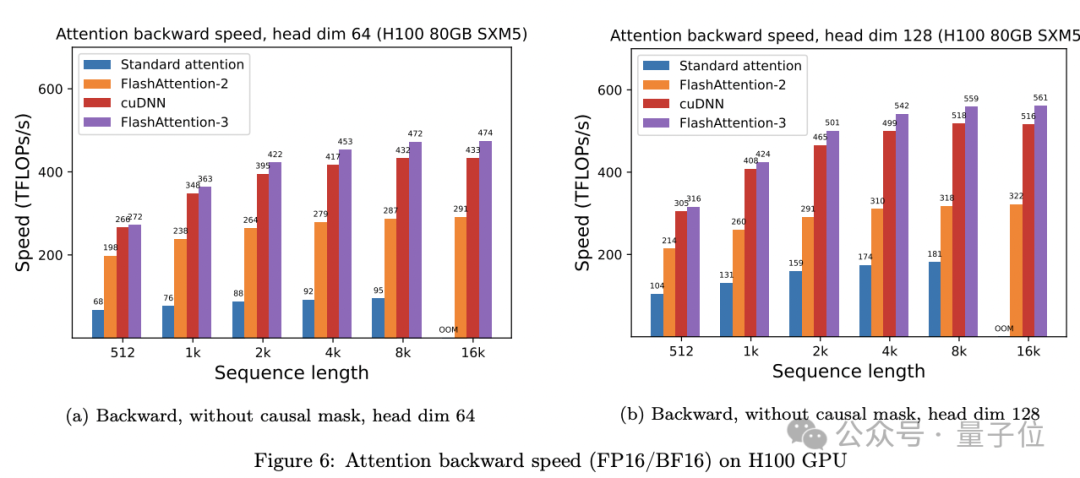
通过改变序列长度(512、1k、……16k),并设置批大小以确保总token数为16k。研究人员将隐藏维度设置为2048,头维度设置为64、128或258,计算前向传播、后向传播。
对比标准Attention、FlashAttention-2、Triton、cuDNN和FlashAttention-3,在H100 80GB SXM5上FP16的运行时间。
FlashAttention-3的前向传播比FlashAttention-2快1.5-2倍,后向传播快1.5-1.75倍。
与标准Attention相比,FlashAttention-3的速度快了3-16倍。
对于中长序列(1k以上),FlashAttention-3甚至超过了专门为H100优化的cuDNN。
在消融实验中,通过对非因果FP16 FlashAttention-3进行了2阶段WGMMA-softmax流水线和warp特殊化的消融研究,参数固定为{batch, seqlen, nheads, hdim} = {4, 8448, 16, 128}。
结果证实,FlashAttention-3改进带来了显著加速,从570提升到661。

另外,因为对FlashAttention的数值误差感兴趣,研究团队还将FlashAttention-2、FlashAttention-3和标准Attention进行了比较。
为了模拟LLMs中的异常特征和激活,研究团队生成了Q、K、V的条目,分布为:N(0,1)+N(0,100)⋅Bernoulli(0.001)
也就是说,每个条目都服从均值为0、标准差为1的正态分布,但对于0.1%的条目,增加了一个独立的项,其标准差为10。然后测量均方根误差(RMSE)。
结果显示,在FP16中,由于中间结果(softmax)保留在FP32中,FlashAttention-2和FlashAttention-3的RMSE比标准Attention减少1.7倍。
FP8的标准Attention使用每个张量的缩放,matmul累加器在FP32中,中间softmax结果保留在FP16中。由于块量化和非相干处理,FP8中的FlashAttention-3比这个基线更准确2.6倍。

最后,论文还表示目前工作专注于Hopper架构,后续将推广到其他硬件。
除了英伟达为研究提供了技术支持外,Meta、Together AI和普林斯顿大学为研究提供了计算支持。
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

