
- 1STM32 HAL库PID控制电机 第三章 PID控制双电机_双电机pid控制
- 2应急响应--小结
- 3word2vec层次化softmax理解
- 4九、Linux二进制安装ElasticSearch集群
- 5Python基础4--异常处理(try&except&finally)_try,except,finally
- 6构建实时银行应用程序:英国金融机构 Nationwide 为何选择 MongoDB Atlas_nationwide building society
- 7The First项目报告:创新型金融生态Lista DAO
- 8“云”筹帷幄 “数”治天下 天翼云的“智”与“志”
- 9又一篇Android Recovery的文章_uboot firmware update
- 10Hadoop 功能组件入门_hadoop组件运维基本概念
MiniGPT4模型训练与部署_minigpt4训练
赞
踩
第二式:MiniGPT4模型训练与部署
1.环境搭建
1.1 下载MiniGPT-4代码
$ git clone https://github.com/Vision-CAIR/MiniGPT-4.git
- 1
1.2 创建虚拟环境
$ cd MiniGPT-4
$ conda env create -f environment.yml
$ conda activate minigpt4
- 1
- 2
- 3
说明:也可以用其他的方式创建虚拟环境,创建虚拟环境的主要目的是安装environment.yml中的依赖库。
2.Vicuna模型准备
2.1 下载vicuna delta weights
下载7b delta weights:
$ git lfs install
$ git clone https://huggingface.co/lmsys/vicuna-7b-delta-v1.1
- 1
- 2
下载13b delta weights:
$ git lfs install
$ git clone https://huggingface.co/lmsys/vicuna-13b-delta-v1.1
- 1
- 2
请注意:这不是直接的 working weight ,而是LLAMA-13B的 working weight 与 original weight 的差值。(由于LLAMA的规则,我们无法提供LLAMA的 weight )
2.2 下载原始llama weights
您需要按照HuggingFace提供的 原始权重 或 从互联网上获取 HuggingFace格式的原始LLAMA-7B或LLAMA-13B 权重。
注:这里直接从HuggingFace下载已转化为HuggingFace格式的原始LLAMA-7B或LLAMA-13B 权重
下载7b 原始 llama weights:
$ git lfs install
$ git clone https://huggingface.co/decapoda-research/llama-7b-hf
- 1
- 2
下载13b 原始 llama weights:
$ git lfs install
$ git clone https://huggingface.co/decapoda-research/llama-13b-hf
- 1
- 2
2.3 合成真正的working weights
当这delta weights 和llama原始weights都准备好后,我们可以使用Vicuna团队的工具来创建真正的 working weight 。
执行如下命令创建最终 working weight
$ python -m fastchat.model.apply_delta --base /home/llama/llama-13b-hf --target /home/vicuna/vicuna-13b-delta-v1.1-llama-merged --delta /home/vicuna/vicuna-13b-delta-v1.1
- 1
注:低CPU内存需在上述命令中加入–low-cpu-mem,可以把大的权重文件分割成多个小份,并使用磁盘作为临时存储。可以使峰值内存保持在16GB以下。不然无法载入vicuna增量文件,CPU内存占满,程序直接被kill。
2.4 配置Vicuna模型路径
需要对minigpt4/configs/models/minigpt4.yaml的第16行进行修改,修改为本地Vicuna working weights的路径。
model: arch: mini_gpt4 vit encoder image_size: 224 drop_path_rate: 0 use_grad_checkpoint: False vit_precision: "fp16" freeze_vit: True freeze_qformer: True Q-Former num_query_token: 32 Vicuna llama_model: "chat/vicuna/weight" # 将 "/path/to/vicuna/weights/" 修改为本地 weight 地址 ...

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3. MiniGPT-4 checkpoint准备
3.1 下载MiniGPT-4 checkpoint
方法一:从 google drive 下载
- Checkpoint Aligned with Vicuna 13B:https://drive.google.com/file/d/1a4zLvaiDBr-36pasffmgpvH5P7CKmpze/view?usp=share_link
- Checkpoint Aligned with Vicuna 7B:https://drive.google.com/file/d/1RY9jV0dyqLX-o38LrumkKRh6Jtaop58R/view?usp=sharing
方法二:huggingface 平台下载
- prerained_minigpt4_7b.pth:https://www.huggingface.co/wangrongsheng/MiniGPT4-7B/tree/main
- pretrained_minigpt4.pth:https://www.huggingface.co/wangrongsheng/MiniGPT4/tree/main
$ git lfs install
$ git clone https://www.huggingface.co/wangrongsheng/MiniGPT4-7B
- 1
- 2
3.2 修改MiniGPT-4 checkpoint路径
在eval_configs/minigpt4_eval.yaml的 第11行 设置 MiniGPT-4 checkpoint 路径
model:
arch: mini_gpt4
model_type: pretrain_vicuna
freeze_vit: True
freeze_qformer: True
max_txt_len: 160
end_sym: "###"
low_resource: True
prompt_path: "prompts/alignment.txt"
prompt_template: '###Human: {} ###Assistant: '
ckpt: '/path/to/pretrained/ckpt/' # 修改为 MiniGPT-4 checkpoint 路径
...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
4. Bert模型准备
1、从huggingface平台下载bert-base-uncased模型:https://huggingface.co/bert-base-uncased
2、修改/MiniGPT-4/minigpt4/models/blip2.py中第31行、47行中
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
encoder_config = BertConfig.from_pretrained("bert-base-uncased")
- 1
- 2
"bert-base-uncased"为下载到本地的bert-base-uncased模型路径。
5. 本地启动MiniGPT-4 demo
本地通过以下命令demo.py运行 MiniGPT-4 demo
$ python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
- 1
注:为了节省GPU内存,Vicuna默认加载为8位,波束搜索宽度为1。这种配置对于Vicuna 13B需要大约23G GPU内存,对于Vicuna7B需要大约11.5G GPU内存。对于更强大的GPU,您可以通过在配置文件minigpt4_eval.yaml中将low_resource设置为False以16位运行模型,并使用更大的波束搜索宽度。
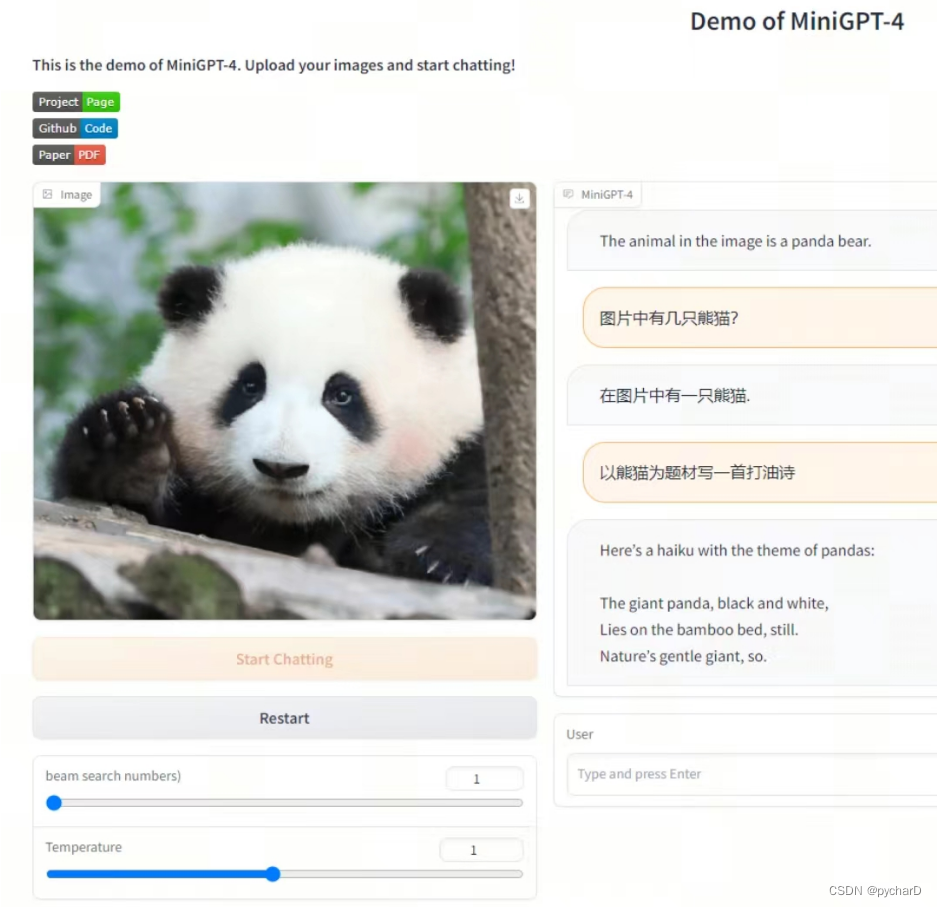
6. 训练MiniGPT-4
6.1 MiniGPT-4 训练介绍
MiniGPT-4的训练包含两个 alignment stages.
6.2 MiniGPT-4 —— First pretraining stage
在第一个预训练阶段,使用 Laion和CC数据集的图像-文本对 来 训练模型,以对齐视觉和语言模型。要下载和准备数据集,请查看我们的第一阶段数据集准备说明。在第一阶段之后,视觉特征被映射,并且可以被语言模型理解。要启动第一阶段培训,请运行以下命令。在我们的实验中,我们使用了4个A100。您可以在配置文件 train_configs/minigpt4_stage1_pretrain.yaml 中更改保存路径
$ torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage1_pretrain.yaml
- 1
注:只有第一阶段训练的MiniGPT-4 checkpoint 可以在这里下载。与第二阶段之后的模型相比,该 checkpoint 频繁地生成不完整和重复的句子。
6.3 MiniGPT-4 — Second finetuning stage
在第二阶段,我们使用自己创建的小型高质量图像-文本对数据集,并将其转换为对话格式,以进一步对齐MiniGPT-4。要下载和准备我们的 第二阶段数据集,请查看我们的 second stage dataset preparation instruction。
要启动第二阶段对齐,首先在 train_configs/minigpt4_stage1_pretrain.yaml 中指定阶段1中训练的 checkpoint 文件的路径。您也可以在那里指定输出路径。然后,运行以下命令。在我们的实验中,我们使用1 A100。
$ torchrun --nproc-per-node NUM_GPU train.py --cfg-path train_configs/minigpt4_stage2_finetune.yaml
- 1
7. Reference
感谢:https://github.com/km1994/LLMsNineStoryDemonTower/tree/main/mingpt4

