
- 1天池NLP新闻文本分类学习赛心得-Task2_新闻文本分类项目难吗
- 2如何在后台执行 SwiftData 操作_swiftdata modelactor
- 3is not in the sudoers file_is not in the sudoers file
- 4CNN RNN 与transformer简介_transformer cnn
- 5八个新手入门的有趣python海龟画图(附代码)_海龟绘图python代码
- 6hive-4(分区、分桶、视图)
- 7只需3步,即刻体验Oracle Database 23c
- 8uniapp搭建vue2+微信小程序项目(兼容H5)初始化注意事项(unocss、vant3等)_uniapph5 vue2
- 9技术成长之路:九阴真经式学习策略与职场智慧_网络工程师讲师 九阴真经
- 10jasypt——对Springboot项目数据源连接加解密_jasypt解密数据库密码+druid数据库连接池+springboot
pandas详细教程(涵盖全部,看这一篇就够了)
赞
踩
pandas认识
Pandas(Panel Data的缩写)是一个开源的Python数据处理库,它提供了高性能、易用的数据结构和数据分析工具,用于处理和分析结构化数据。
Pandas的核心数据结构是DataFrame和Series,它们使数据的清理、转换、分析和可视化变得非常便捷。
Pandas的主要特点和功能:
-
DataFrame和Series:DataFrame是二维表格数据结构,类似于电子表格或SQL表,它由行和列组成,每列可以包含不同数据类型。Series是一维标签化数组,用于存储单列数据。
-
数据清理和预处理:Pandas提供了一系列功能,用于处理丢失数据(缺失值)、重复数据、异常值、数据类型转换等,以使数据变得更加干净和可用于分析。
-
数据选择和过滤:Pandas允许使用标签和位置进行数据选择和过滤,包括布尔索引、条件过滤、列选择等。
-
数据分组和聚合:Pandas支持数据分组操作,可以对数据进行分组并执行聚合操作,如求和、均值、计数等。
-
合并和连接:Pandas提供了多种方法来合并和连接不同的数据集,包括数据库风格的连接、拼接和合并操作。
-
时间序列处理:Pandas内置了强大的时间序列功能,支持时间索引和时间相关的操作,适用于处理时间序列数据。
-
数据可视化:Pandas可以与Matplotlib等数据可视化库集成,帮助用户快速绘制图表和图形,以更好地理解数据。
-
读取和存储数据:Pandas支持多种数据格式,包括CSV、Excel、SQL数据库、JSON等,可以方便地读取和存储数据。
-
高性能计算:Pandas基于NumPy构建,因此具有高性能的数据处理能力,尤其在处理大规模数据集时非常有效。
-
广泛应用领域:Pandas广泛应用于数据分析、数据科学、机器学习、金融建模、时间序列分析、数据清理和数据预处理等领域。


pandas的导入:
我前几天写了numpy的,写的很详细,这里就不写了,不会的小伙伴可以去看看我numpy的安装 包的安装
Pandas数组
pandas库中总共有两个数据结构,一个是Series,另一个是DataFrame。 我们先来讲Series
Series
认识:
Series是Pandas库中的一个主要数据结构,是一种类似一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的标签组成。这些标签通常是索引,用于对数据进行分类和定位。而Pandas库是基于NumPy构建的,专门用于处理表格和混杂数据,与NumPy不同,它更适合处理带有复杂标签的数据。类似于字典
我们对比numpy数组来进行分析
- import numpy as np
- import pandas
- from pandas import Series
- data1=np.random.randint(1,10,size=5)
- print("ndarray数组是:")
- print(data1)
- data2=Series(data1)
- print("Series数组是:")
- print(data2)
运行效果:

先不用弄明白我如何创建Series数组的,下面会有详细讲解,我们观察运行图,可以发现Series数组是默认自带索引的,可能有些小伙伴会有疑问,numpy数组也有索引,然而,这两者在索引的使用和性质上存在一些关键的区别
在numpy中,一维数组的索引主要是基于位置的,从0开始并且与数据的位置有关。这种索引主要用来访问数组中的元素,但它并不提供额外的元数据或分类功能。换句话说,numpy数组的索引主要是为了定位元素,而不是为了数据的分类或标签。
相比之下,pandas的Series数组具有更复杂的索引结构。除了基于位置的索引外,Series还可以附加额外的索引,这些索引通常是字符串或其他对象类型,用于分类或标记数据。这些额外的索引使得Series数组能够更好地处理复杂的数据集,其中的数据可能需要根据多个维度或标准进行分类或查询。听不懂的小伙伴也没有关系,我这就写几个例子
- import numpy as np
-
- arr = np.array([1, 2, 3, 4, 5])
- print(arr[0]) # 输出:1
- print(arr[2]) # 输出:3
- import pandas as pd
-
- data = [1, 2, 3, 4, 5]
- index = ['a', 'b', 'c', 'd', 'e']
- series = pd.Series(data, index=index)
- print(series['a']) # 输出:1
- print(series['c']) # 输出:3
创建出来的Series对象默认会有一个索引。如果你不想使用默认的索引(隐式索引),可以在创建Series对象时通过index参数指定自定义的索引(显示索引),用于分类或标记数据,numpy数组索引主要用来访问数组中的元素,但它并不提供额外的元数据或分类功能
至于如何创建,怎么去自己加索引这些先不用管,下面会详细讲到
创建:
使用列表或数组创建:
使用列表和数组创建的Series数组则是副本,改变其中一个不会影响另一个。这里有个印象就可以了
- import pandas as pd
- data = [1, 2, 3, 4, 5]
- series = pd.Series(data)
使用numpy数组创建:
使用numpy创建出来的Series数组不是副本。这意味着当你改变原来的numpy数组时,Series也会跟着改变
- import pandas as pd
- import numpy as np
- data = np.array([1, 2, 3, 4, 5])
- series = pd.Series(data)
这两种都是采用数组的默认索引,要是想用自定义索引 可以加一个index属性
- import pandas as pd
- from pandas import Series
- series = pd.Series(data=[1, 2, 3, 4, 5], index= ['a', 'b', 'c', 'd', 'e'])
- print(series)
运行效果:

使用字典创建:
使用字典创建的Series对象也不是副本,而是与字典共享数据。因此,如果你修改了原始字典中的数据,那么对应的Series对象也会跟着改变。
字典的键作为索引,值作为数据
- import numpy as np
- import pandas
- from pandas import Series
- list={
- "name":"张三",
- "age:":18,
- "sex":"男"
- }
- series=Series(list)
- print(series)
运行效果:

当然,用字典创建Series时,也可以加index属性,但是一般不会这样用,感兴趣的小伙伴可以自己去尝试一下
读取DataFrame的一列
这个看后面的DataFrame就知道了
访问:
完全兼容numpy的访问,不会的小伙伴去我另外一篇补充笔记哦numpy笔记
直接访问:
一般不推荐:官方推荐第三种,方便后面要学的DateFrame数组的访问
- import numpy as np
- import pandas
- from pandas import Series
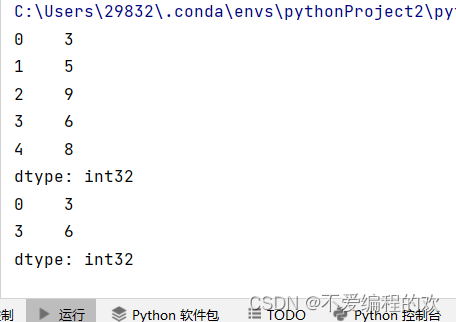
- s1=Series(np.random.randint(1,10,size=5))#用arrary创建一个Series数组
- print(s1)
- print(s1[[0,3]])
运行效果:
使用显式索引:
一般不推荐:官方推荐第四种
- import numpy as np
- import pandas
- from pandas import Series
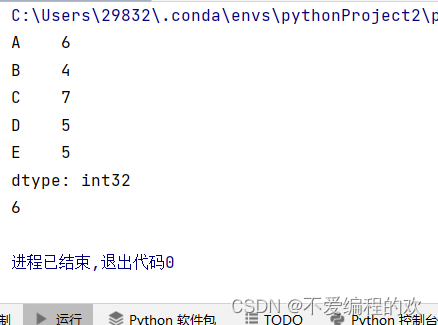
- s1=Series(np.random.randint(1,10,size=5,),index=["A","B","C","D","E"])#用arrary创建一个Series数组
- print(s1)
- print(s1["A"])
运行效果:
使用iloc访问机制:
配合隐式的索引,官方推荐的访问机制 ,运行结果和第一种一样
- import numpy as np
- import pandas
- from pandas import Series
- s1=Series(np.random.randint(1,10,size=5,),index=["A","B","C","D","E"])#用arrary创建一个Series数组
- print(s1)
- print(s1.iloc[[0,1]])
使用loc访问机制 :
配合显式的索引,官方推荐的访问机制,运行结果和第二种一样
- import numpy as np
- import pandas
- from pandas import Series
- s1=Series(np.random.randint(1,10,size=5,),index=["A","B","C","D","E"])#用arrary创建一个Series数组
- print(s1)
- print(s1.loc["A"])
切片
这里直接用iloc(隐式索引)和loc(显示索引)进行切片
iloc切片
注意这里的切片是左闭右开
- import numpy as np
- import pandas as pd
- from pandas import Series
- data1=Series(np.random.randint(1,10,size=3),index=["A","B","C"])
- data1=data1.iloc[0:2]#切片
- print(data1)
运行效果:

loc切片
- import numpy as np
- import pandas as pd
- from pandas import Series
- data1=Series(np.random.randint(1,10,size=3),index=["A","B","C"])
- data1=data1.loc["A":"B"]#切片
- print(data1)
-
运行效果:

运算:
Series运算是Pandas库中的一种数据结构,类似于一维数组。它提供了许多方便的函数和方法来进行各种操作,如求和、平均值、最大值、最小值等。与Numpy类似,还是那句话,不用刻意的去记,不会的方法直接向ai取取经就好了 多写几次,再多练几次,这种东西留个印象即可,所以我这里也不讲了
总结:
Series是一种类似于一维数组的数据结构,可以保存任何数据类型,由索引和列组成。
DateFrame
认识:
DataFrame是一个类似于二维数组或表格(如Excel表格)的对象 ,它的每列数据可以是不同的数据类型,与Series的结构相似,DataFrame也是由索引和数据组成的,不同的是,DataFrame的索引不仅有行索引,还有列索引

