
- 1基于STM32的最小系统电路设计(STM32F103C8T6为例)_stm32微控制器和最小系统电路
- 2推荐3个开源好用的堡垒机_免费堡垒机
- 3安装samba服务器_samba安装
- 4AIGC:重塑创意产业的新纪元
- 5高德地图2.0内网部署 离线瓦片 性能优化_高德地图瓦片服务
- 6计算机工程与科学期刊小木虫,《[小木虫emuch.net]北大中文核心期刊目录(2016版)--2016年4月12日更新》.pdf...
- 7springboot小区物业服务平台 计算机专业毕业设计源码35514_老旧小区改造智能管理系统的编码实现过程
- 8【C++】STL之空间配置器
- 9如何做好springboot监控集成
- 10numpy的下载与安装教程——(解决No module named numpy问题)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(二)_cnn+残差
赞
踩
系列文章目录
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(一)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(二)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(三)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(四)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(五)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(六)

前言
本项目以卷积神经网络(CNN)模型为基础,对收集到的猫咪图像数据进行训练。通过采用数据增强技术和结合残差网络的方法,旨在提高模型的性能,以实现对不同猫的种类进行准确识别。
首先,项目利用CNN模型,这是一种专门用于图像识别任务的深度学习模型。该模型通过多个卷积和池化层,能够有效地捕捉图像中的特征,为猫的种类识别提供强大的学习能力。
其次,通过对收集到的数据进行训练,本项目致力于建立一个能够准确辨识猫的种类的模型。包括各种猫的图像,以确保模型能够泛化到不同的种类和场景。
为了进一步提高模型性能,采用了数据增强技术。数据增强通过对训练集中的图像进行旋转、翻转、缩放等操作,生成更多的变体,有助于模型更好地适应不同的视角和条件。
同时,引入残差网络的思想,有助于解决深层网络训练中的梯度消失问题,提高模型的训练效果。这种结合方法使得模型更具鲁棒性和准确性。
最终,通过本项目,实现了对猫的种类进行精准识别的目标。这对于宠物领域、动物学研究等方面都具有实际应用的潜力,为相关领域提供了一种高效而可靠的工具。
总体设计
本部分包括系统整体结构图和系统流程图。
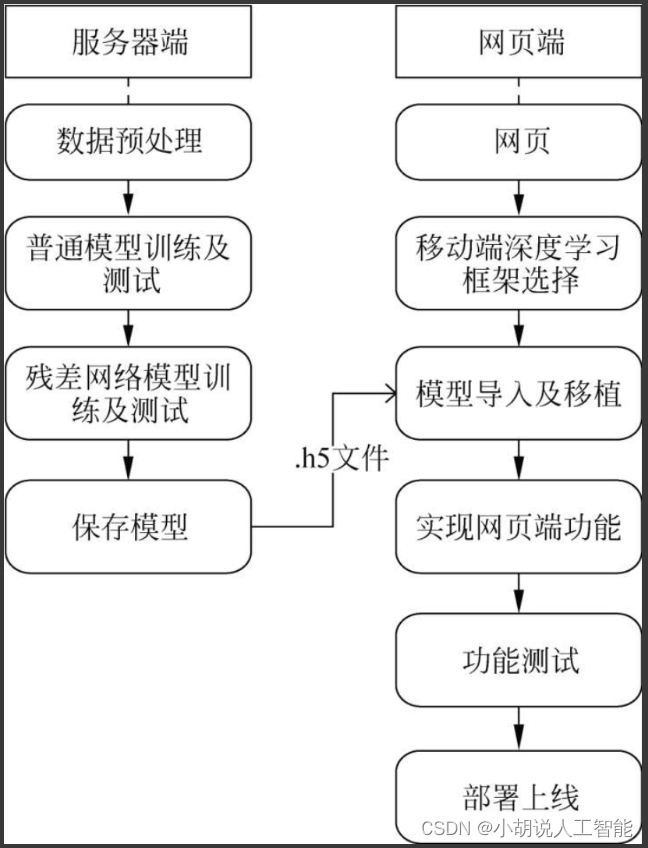
系统整体结构图
系统整体结构如图所示。
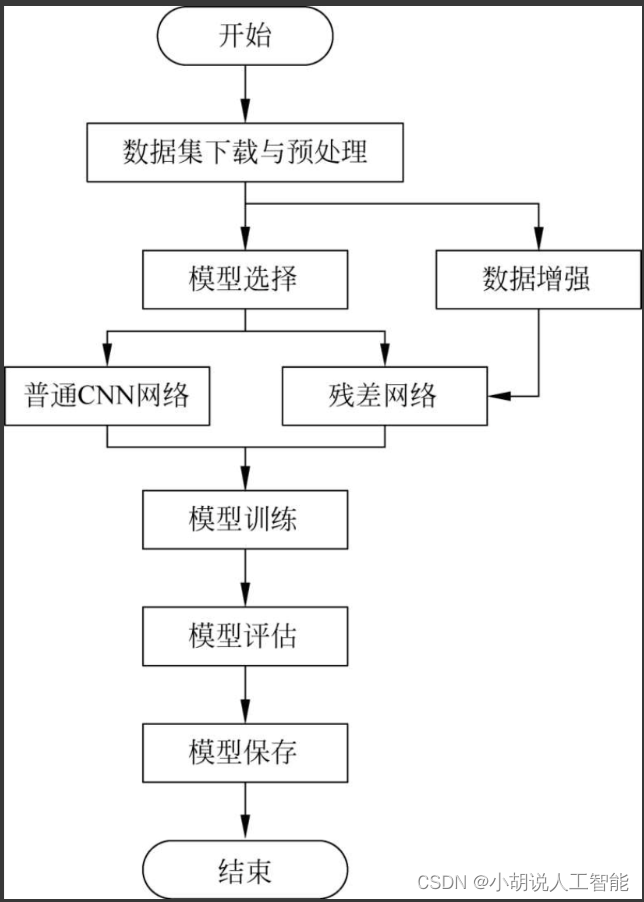
系统流程图
系统流程如图所示。
运行环境
本部分包括计算型云服务器、Python环境、TensorFlow环境和MySQL环境。
详见博客。
模块实现
本项目包括5个模块:数据预处理、数据增强、普通CNN模型、残差网络模型、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
打开浏览器,分别搜索布偶猫、孟买猫、暹罗猫和英国短毛猫的图片。用批量下载器下载图片,筛选出特征明显的图片作为数据集。使用的图片包含101张布偶猫、97张孟买猫、101张逼罗猫以及85张英国短毛猫,共计384张图片。(其中在工程代码中/cat_kind_model/cat_data_100与/cat_kind_model/cat_data_224也可下载)
对数据集进行预处理,包括修改图片名、调整格式及大小,将图片按比例划分为训练集和测试集。
import os #导入各种模块 from PIL import Image import argparse from tqdm import tqdm class PrepareData: #准备数据类 def __init__(self, options): #初始化 self.moudle_name = "prepare data" self.options = options self.src_images_dir = self.options.src_images_dir self.save_img_with = self.options.out_img_size[0] self.save_img_height = self.options.out_img_size[1] self.save_dir = self.options.save_dir #统一图片类型 def renameJPG(self, filePath, kind): #图片重命名 #filePath:图片文件的路径,kind: 图片的种类标签 images = os.listdir(filePath) for name in images: if (name.split('_')[0] in ['0', '1', '2', '3']): continue else: os.rename(filePath + name, filePath + kind + '_' + str(name).split('.')[0] + '.jpg') #调用图片处理 def handle_rename_covert(self): #重命名处理 save_dir = self.save_dir #调用统一图片类型 list_name = list(os.listdir(self.src_images_dir)) print(list_name) train_dir = os.path.join(save_dir, "train") test_dir = os.path.join(save_dir, "test") #1.如果已经有存储文件夹,执行则退出 if not os.path.exists(save_dir): os.mkdir(save_dir) os.mkdir(train_dir) os.mkdir(test_dir) list_source = [x for x in os.listdir(self.src_images_dir)] #2.获取所有图片总数 count_imgs = 0 for i in range(len(list_name)): count_imgs += len(os.listdir(os.path.join(self.src_images_dir, list_name[i]))) #3.开始遍历文件夹,并处理每张图片 for i in range(len(list_name)): count = 1 count_of_each_kind = len(os.listdir(os.path.join(self.src_images_dir, list_name[i]))) handle_name = os.path.join(self.src_images_dir, list_name[i] + '/') self.renameJPG(handle_name, str(i)) #调用统一图片格式 img_src_dir = os.path.join(self.src_images_dir, list_source[i]) for jpgfile in tqdm(os.listdir(handle_name)): img = Image.open(os.path.join(img_src_dir, jpgfile)) try: new_img = img.resize((self.save_img_with, self.save_img_height), Image.BILINEAR) if (count > int(count_of_each_kind * self.options.split_rate)): new_img.save(os.path.join(test_dir, os.path.basename(jpgfile))) else: new_img.save(os.path.join(train_dir, os.path.basename(jpgfile))) count += 1 except Exception as e: print(e) #参数设置 def main_args(): parser = argparse.ArgumentParser() parser.add_argument('--src_images_dir', type=str, default='../dataOrig/',help="训练集和测试集的源图片路径") parser.add_argument("--split_rate", type=int, default=0.9, help='将训练集二和测试集划分的比例,0.9表示训练集占90%') parser.add_argument('--out_img_size', type=tuple, default=(100, 100),help='保存图片的大小,如果使用简单网络结构参数大小为(100,100),如果使用resnet大小参数为(224,224)') parser.add_argument("--save_dir", type=str, default='../cat_data_100', help='训练数据的保存位置') options = parser.parse_args() return options if __name__ == "__main__": #获取参数对象 options = main_args() #获取类对象 pd_obj = PrepareData(options) pd_obj.handle_rename_covert()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
2. 数据增强
所谓数据增强,是通过翻转、旋转、比例缩放、随机裁剪、移位、添加噪声等操作对现有数据集进行拓展。本项目中数据量较小,无法提取图片的深层特征,使用深层的残差网络时易造成模型过拟合。
from keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img import argparse, os from PIL import Image from tqdm import tqdm #进度条模块 datagen = ImageDataGenerator( rotation_range=40, #整数,数据提升时图片随机转动的角度 width_shift_range=0.2,#浮点数,图片宽度的某个比例,数据提升时图片水平偏移的幅度 height_shift_range=0.2,#浮点数,图片高度的某个比例,数据提升时图片竖直偏移的幅度 rescale=1. / 255, #重放缩因子,默认为None shear_range=0.2, #浮点数,剪切强度(逆时针方向的剪切变换角度) zoom_range=0.2, #浮点数或形如[lower,upper]的列表,随机缩放的幅度 #若为浮点数,则相当于[lower,upper] = [1 - zoom_range, 1+zoom_range] horizontal_flip=True, #布尔值,进行随机水平翻转 vertical_flip=False, #布尔值,进行随机竖直翻转 fill_mode='nearest', #‘constant’,‘nearest’,‘reflect’或‘wrap’之一, #进行变换时超出边界的点将根据本参数给定的方法进行处理 cval=0, #浮点数或整数,当fill_mode=constant时,指定要向超出边界的点填充值 channel_shift_range=0, #随机通道转换的范围 ) def data_aug(img_path, save_to_dir, agu_num): img = load_img(img_path) #获取被扩充图片的文件名部分,作为扩充结果图片的前缀 save_prefix = os.path.basename(img_path).split('.')[0] x = img_to_array(img) x = x.reshape((1,) + x.shape) i = 0 for batch in datagen.flow(x, batch_size=1, save_to_dir=save_to_dir, save_prefix=save_prefix, save_format='jpg'): i += 1 #保存agu_num张数据增强图片 if i >= agu_num: break #读取文件夹下的图片,并进行数据增强,将结果保存到dataAug文件夹下 def handle_muti_aug(options): src_images_dir = options.src_images_dir save_dir = options.save_dir list_name = list(os.listdir(src_images_dir)) for name in list_name: if not os.path.exists(os.path.join(save_dir, name)): os.mkdir(os.path.join(save_dir, name)) for i in range(len(list_name)): handle_name = os.path.join(src_images_dir, list_name[i] + '/') #tqdm()为数据增强添加进度条 for jpgfile in tqdm(os.listdir(handle_name)): #将被扩充的图片保存到增强的文件夹下 Image.open(handle_name+jpgfile).save(save_dir+'/'+list_name[i]+'/'+jpgfile) #调用数据增强过程函数 data_aug(handle_name+jpgfile, os.path.join(options.save_dir, list_name[i]), options.agu_num) def main_args(): parser = argparse.ArgumentParser() parser.add_argument('--src_images_dir', type=str, default='../source_images/', help="需要被增强训练集的源图片路径") parser.add_argument("--agu_num", type=int, default=19, help='每张训练图片需要被增强的数量,这里设置为19,加上本身的1张,每张图片共计变成20张') parser.add_argument("--save_dir", type=str, default='../dataAug', help='增强数据的保存位置') options = parser.parse_args() return options if __name__ == "__main__": options = main_args() handle_muti_aug(options)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
数据增强进度如图所示。

数据集拓展为原来的20倍,如图所示。

其他相关博客
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(一)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(三)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(四)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(五)
基于CNN+数据增强+残差网络Resnet50的少样本高准确度猫咪种类识别—深度学习算法应用(含全部工程源码)+数据集+模型(六)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。

