
- 1Android Gradle Plugin与Gradle 版本对应关系
- 2docker安装
- 3华为通用软件开发工程师24校招三轮面试详细记录_有两个城市a与b,相距50 km,我们有100根胡萝卜希望由a地运送到b地;有1头小毛驴,每
- 4夏至时节,繁花盛开_夏至繁华盛开
- 5判断大模型微调是否产生灾难性遗忘的实战方案_lora 灾难性遗忘
- 6使用Packer在Hyper-V上自动部署Windows Server 2016中文版_sw dvd9 win svr std core and datactr core 2016 64b
- 7资源推荐 | 五十种最好用的开源爬虫软件
- 8HEIC图片转JPG和其他格式_python 转为heif格式
- 9简述企业落地RAG技术时遇到的困境_rag落地人才能力要求、
- 10总结新老的Python程序员常犯的一些错误(满满的干货)_代码只有第一次使用有效
语义匹配应用介绍_统一语义匹配
赞
踩
语义匹配
工业界的很多应用都有在语义上衡量本文相似度的需求,我们将这类需求统称为“语义匹配”。根据文本长度的不同,语义匹配可以细分为三类:短文本-短文本语义匹配,短文本-长文本语义匹配和长文本-长文本语义匹配。基于主题模型的语义匹配通常作为经典文本匹配技术的补充,而不是取代传统的文本匹配技术。
短文本-短文本语义匹配
短文本-短文本的语义匹配在工业界的应用场景非常广泛。例如,在网页搜索中,我们需要度量用户查询 (query) 和网页标题 (web page title) 的语义相关性;在query推荐中,我们需要度量query和其他query之间的相似度。这些场景都会用到短文本-短文本的语义匹配。 由于主题模型在短文本上的效果不太理想,在短文本-短文本匹配任务中词向量的应用比主题模型更为普遍。简单的任务可以使用Word2Vec这种浅层的神经网络模型训练出来的词向量。
比如,query推荐任务中,我们经常要计算两个query的相似度,例如=“推荐好看的电影”与
=“2016年好看的电影”。 通过词向量按位累加的方式,得到这两个query的向量表示之后,可以利用Cosine Similarity来计算两者的相似度。对于较难的短文本-短文本语义匹配任务,则可以考虑引入有监督信号并利用 Deep Structured Semantic Model(DSSM)[5] 或 Convolutional Latent Semantic Model(CLSM)[9] 这些更复杂的神经网络模型进行语义相关性的计算。
短文本-长文本语义匹配
短文本-长文本语义匹配的应用场景在工业界非常普遍。例如,在搜索引擎中,我们需要计算一个用户查询(query)和一个网页正文(content)的语义相关度。由于query通常较短,而网页content较长,因此query与content的匹配与上文提到的短文本-短文本不同,通常需要使用短文本-长文本语义匹配,以得到更好的匹配效果。在计算相似度的时候,我们规避对短文本直接进行主题映射,而是根据长文本的主题分布,计算该分布生成短文本的概率,作为它们之间的相似度:

其中表示query,
表示content,
表示
中的词,
表示第k个主题。
案例1:用户查询-广告页面相似度
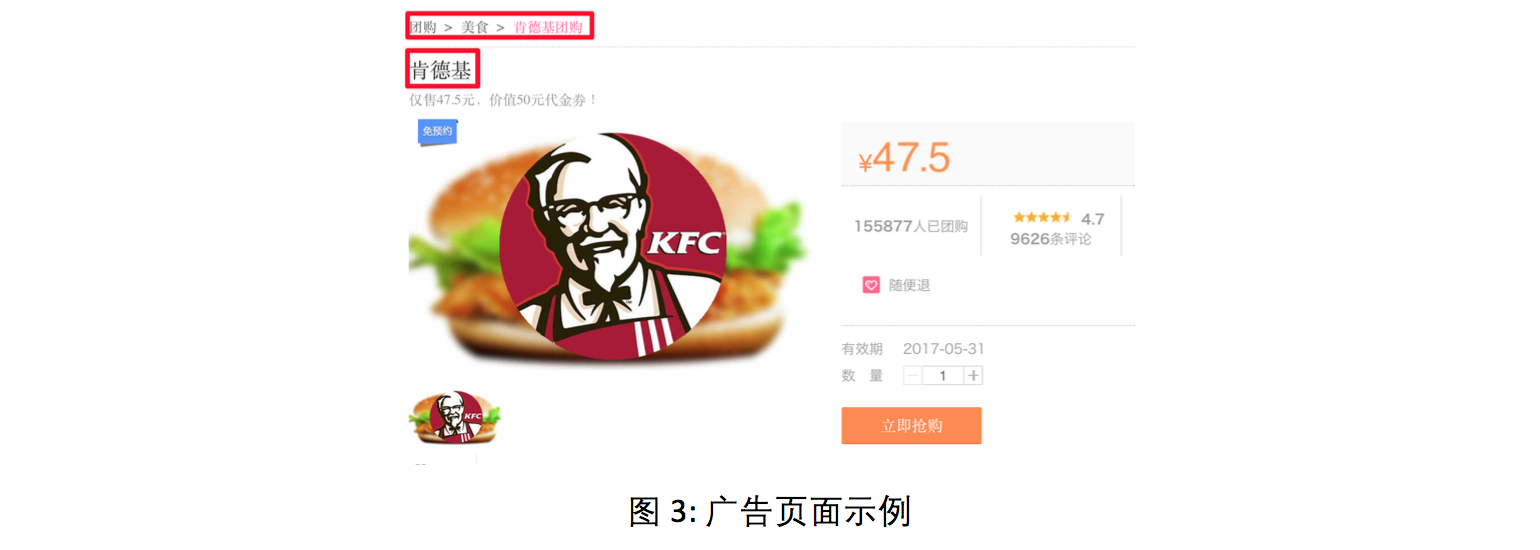
在线广告场景中,我们需要计算用户查询和广告页面的语义相似度。这时可应用SentenceLDA,将广告页面中各个域的文本视为句子,如图3所示(红框内容为句子)。我们首先通过主题模型学习得到广告的主题分布,再使用公式 (1) 计算用户查询和广告页面的语义相似度。该相似度可以作为一维特征,应用在更复杂的排序模型中。在图4中,对于query=“婚庆拍摄”,我们对比了不同特征组合的结果。其中左图为Baseline,右图则是引入SentenceLDA相似度(基于SentenceLDA计算query与广告页面的相似度)后得到的结果。可以看出,相比于Baseline,引入新特征后召回的结果更加符合query语义,能更好的满足用户需求。

案例2: 文档关键词抽取
在分析文档时,我们往往会抽取一些文档的关键词做标签(tag),这些tag在用户画像和推荐任务中扮演着重要角色。从文档中抽取关键词,常用的方法是利用词的TF和IDF信息,此外,还可利用主题模型,估计一个文档产生单词的概率作为该单词的重要度指标:
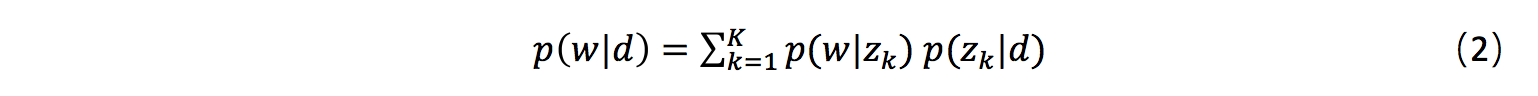
其中,表示文档内容,
表示词,
表示第主题。 但由于
常被高频词主导,导致一些语义上重要的低频词难以被选为关键词。 为了解决上述问题,我们利用TWE训练得到主题和单词的向量表示,再使用公式(3)计算每个词与文档主题的相似度作为衡量语义重要度的指标。

其中,表示?对应的词向量,
表示主题
对应的主题向量,并且词向量和主题向量在处于同一个向量空间中。下面一段文字是我们随机从网上取的一个新闻片段,对其进行分词处理以及应用主题模型 LDA 或 TWE 后,然后分别选取公式(2)或公式(3)计算每个词的重要度。在表5中,我们列出了 LDA 和 TWE 模型计算得到的Top-10关键词集合 (已去除停用词)。从表中可以看出,采用 TWE 得到的 Top-10 关键词 能更好地体现出新闻的重要信息。
台湾《自由时报》4 月 13 日综合外媒报道称,全美发起拒搭联航运动,并在社群网站上 发酵。居住在美国纽约的网友许柏祥表示,本身是联合航空会员,在得知联航将乘客拖下飞 机后,就向航空公司取消下个月的预订班机,并称“我不想被人打!”许柏祥说,他完全不能 接受航空公司的处理方式,而且是对待一名 69 岁的老人。报道称,联航会员“剪卡”风潮也 席卷社群网路,许多网友将自己的联航会员卡剪掉抵制。网友萨赫哈(Aninda Sadhukhan)表 示,身为联航多年的乘客,在看到影片后,让他决定不再搭联航,并将会员卡放入碎卡机内。 另一名会员布朗(Phyllis Brown)表示,呼吁民众剪掉联航会员卡,并改搭其他航空公司班机,以此抗议联航暴力对待乘客。

长文本-长文本语义匹配
通过使用主题模型,我们可以得到两个长文本的主题分布,再通过计算两个多项分布的距离来衡量它们之间的相似度。衡量多项分布的距离可以利用Hellinger Distance和Jensen-Shannon Divergence (JSD)。
案例3: 新闻个性化推荐
长文本-长文本的语义匹配可用于个性化推荐的任务中。在互联网应用中,当我们积累了用户大量的行为信息后,这些行为信息对应的文本内容可以组合成一篇抽象的“文档”,对该“文档”进行主题映射后获得的主题分布可以作为用户画像。例如,在新闻个性化推荐中,我们可以将用户近期阅读的新闻(或新闻标题)合并成一篇长“文档”,并将该“文档” 的主题分布作为表达用户阅读兴趣的用户画像。如图5所示,通过计算每篇实时新闻的主题分布与用户画像之间的Hellinger Distance,可作为向用户推送新闻的选择依据,达到新闻个性化推荐的效果。

案例4: 小说个性化推荐
小说推荐任务是根据用户的偏好进行小说推荐,具体场景如图6(a)所示。最常见的推荐算法技术为协同过滤,其中矩阵分解是协同过滤算法中常用的技术之一,主要的思想是从评分矩阵(用户对物品的评价等)中分解出用户-特性矩阵,特性-物品矩阵,从而得到用户的偏好和物品的特性,用以预测用户对未接触过的物品的打分情况。 基于特征的矩阵分解(SVDFeature)[3],是一个灵活的推荐框架,允许向模型中增加一些全局特征、用户特征以及物品特征,使得模型在推荐上可以取得更好的效果。考虑到每个用户有一些收藏或者下载的小说,我们可以将这些小说对应的主题分布进行聚合,从而得到用户的主题表示,作为描述用户阅读兴趣的用户画像。通过计算每篇小说的主题分布与用户画像之间的JSD距离,可以用来衡量用户对该小说的感兴趣程度。我们将JSD评分作为全局特征加入到SVDFeature中参与训练,对小说进行排序后推荐给用户。对比传统的SVDFeature打分与结合了主题模型策略的SVDFeature打分,后者在线下指标上均超过前者,如图6(b)所示。

案例5:垂类新闻CTR预估
新闻推荐服务涉及多个垂类新闻方向,如体育、汽车、娱乐等。在这些方向上,我们往往需要做更精细的个性化推荐。为了实现这个目的,我们需要在垂类新闻数据的基础上,训练针对该垂类的主题模型。对于某个用户而言,我们把该用户历史上点击的新闻拼接成一篇文档,基于垂类主题模型做主题推断,获得文档的主题分布作为该用户的画像。垂类新闻的CTR预估模型利用的特征可以分为三类:新闻-用户相似度特征(语义匹配范式),新闻主题特征(语义表示范式)和其他常规的统计特征。新闻-用户相似度特征指的是利用长文本-长文本语义匹配的方式计算的新闻和用户画像的相似度。新闻主题特征是该新闻的主题分布。常规的统计特征包括时间,新闻源,点击率等等。在工业界应用中,用户模型数据空间较大,会存在垂类主题分布的压缩需求,可以考虑根据CTR预估模型的权重进行删减和重训。上述方案在垂类新闻推荐上取得了很好的效果提升。
https://github.com/baidu/Familia/wiki/%E8%AF%AD%E4%B9%89%E5%8C%B9%E9%85%8D%E5%BA%94%E7%94%A8%E4%BB%8B%E7%BB%8D

