
热门标签
热门文章
- 1反向传播与梯度_用梯度计算写出反向传播公式,即写出w1
- 2【STM32】USART串口和I2C通信_stm32 i2c
- 3数字孪生-3D模型管理系统(Three.js加载三维模型)_开发一个备品备件管理的三维模型系统
- 4AIGC引领未来:搜索引擎、广告系统与推荐系统的重塑与革新
- 5一款支持几分钟视频生成,免费无限制AI视频生成网站_brmgo
- 6Python的包管理工具pip的安装与使用_python pip
- 7[矩阵分析] 一、线性空间与线性变换_线性变换所有的特征向量构成值域吗
- 8npm_yarn_pnpm最新阿里镜像源配置_npm阿里源
- 9早晨看到的七彩云,据说是祥瑞
- 10git push 时出现 Updates were rejected because... 错误_push的时候提示未update
当前位置: article > 正文
SQL SERVER系列(三):SQL Server 2008中的数据压缩_sql2008压缩数据库
作者:我家小花儿 | 2024-08-09 16:50:20
赞
踩
sql2008压缩数据库
在本系列的
上一篇文章中,我列举了目前三大数据库(Oracle、DB2、SQL Server)在最新版本中使用的压缩技术的相关链接,关于SQL Server 2008的相关信息是最少的,因为直到目前为止,我们还不能拿到具有数据压缩功能的SQL Server 2008版本。一个好消息是,在SQL Server 2008的下一个社区预览版(CTP6)中,我们终于能够看到“数据压缩”功能的庐山真面目了(注:11月刚刚发布的SQL Server 2008社区预览版为CTP5)。这个好消息来源于SQL Server存储引擎开发组的博客
Data Compression will be available in CTP-6,在这篇博客(博客作者Sunil Agarwal为SQL Server Storage Engine组的一名程序经理)中同时提到,数据压缩功能将是企业版独有的。
在 Types of data compression in SQL Server 2008这篇博客中, Sunil Agarwal提到了在SQL Server 2008中采用的两种压缩策略:
(1)以变长格式存储所有的定长数据类型。在本系列的 上一篇文章中,我提到过在SQL Server 2005 SP2中提供的使用vardecimal类型来存储decimal/numeric数据类型以节省存储空间的问题,有兴趣的朋友可以参考上一篇文章最后列出的相关链接以获取更多信息。在SQL Server 2008中,微软将这一思想扩展到了所有的定长数据类型,例如integer,char,float类型。需要注意的是,虽然SQL Server 2008以变长格式存储所有的定长数据类型,但这只是一种存储的具体实现机制,并不会改变任何语义上的东西,任何客户的程序都不需要修改,因为它根本不关心也不必知道数据库内部具体的数据存储方式。
例子一:假设一个表中有一个32位整数列(integer),但是该列的值均在(0~255或-128~127)的范围内,那么SQL Server 2008就可以只用一个字节来存储该列的值,这与之前版本的SQL Server总是使用4个字节来存储该列相比,就节省了75%的空间。
例子二:假设一个表中有一个定长字符串列CHAR(100),在以前的SQL Server版本中,该列总是使用100个字节来存储(即使实际的字符串没有100个字节,也会在其后填充空格以达到长度正好为100)。但是在SQL Server 2008中,该列将根据实际字符串的长度来进行存储,例如"Hello"将只耗费5个字节存储空间,而"This is a longer string"将只需23个字节存储,分别带来95%和77%的存储空间的节省。
当然,在上述例子一中如果实际的数值变化范围超过了一个字节能够表示的范围,那么相应的压缩比就会降低;对于例子二也类似,如果实际的字符串长度接近100,那么压缩效果也会大大降低。这意味着压缩的效果将依赖于实际的数据值的分布,同时也依赖于表的架构定义,这可能不那么明显,但是想象一下上述的例子二,如果将列的定义改为CHAR(150),显然压缩的效果就更为显著。另外请注意,NULL值是不需要占用任何存储空间的(参见下面的行格式)。
在 SQL Server 2008 Data Compression这篇博客中,博客作者Shailan Chudasama用一副图形象的说明了上述例子一描述的场景:

图1 SQL Server 2008以变长格式存储整数类型列
在上面的图1中,我们注意到在SQL Server 2008中,存储一个字节能够表示的整数实际需要1.5个字节来存储,而不是我们上面例子一中所描述的一个字节,为什么会是这样呢?我们知道,在SQL Server中存储一个变长列时,需要额外的存储空间来存储该列在一个数据行中的位置,以便能够在需要的时候快速访问到该列,以下这幅图说明了在SQL Server 2000/2005中一个数据行是如何存储的:
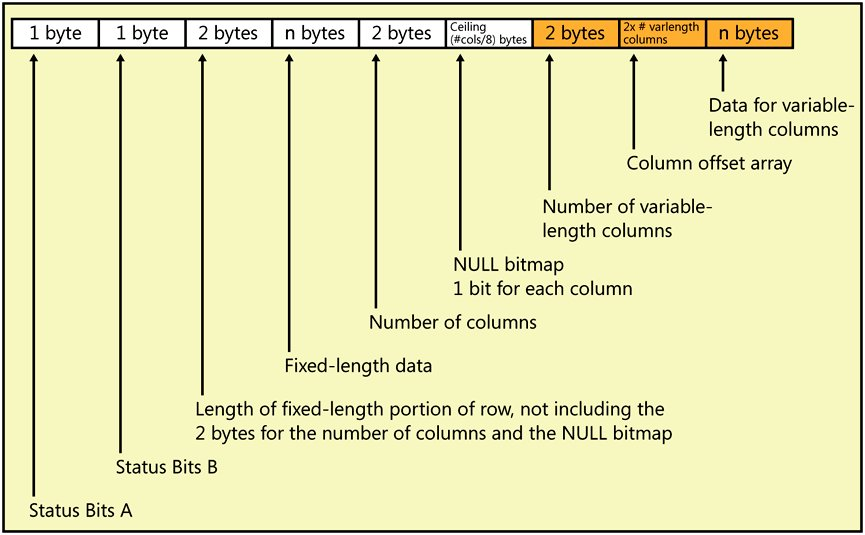
图2 SQL Server 2000/2005中的数据行存储格式
从上面这副图2中,我们可以清楚的看到,一个定长列除了存储该列数据本身以外,是不需要额外的存储空间的。而对于一个变长列,除了该列数据本身所占的空间外,每个变长列还需要2个额外的字节来存储该列在数据行中的位置,这就是上图中的“Column Offset Array”。从这个意义上来将,将smallint甚至我们例子一中提到的integer数据类型以变长方式存储的压缩效果就几乎毫无意义了。因此在SQL Server 2008中针对这种情况进行了特殊的优化,那就是如果该列的长度不超过8字节,那么每列只需要4bit来存储上述的列偏移,这就清楚的解释了图1中的4Bits从何而来了。需要提醒大家的上,图2中的数据行存储格式在SQL Server 2008中依然有效,而且是默认的存储格式(我猜测应该是不启用数据压缩时所使用存储格式)。
在SQL Server 2008中,这种压缩策略是通过在DDL(数据操纵语言)中的“ROW COMPRESSION"而暴露出来的,这也就是我们通常所说的行级压缩(Row level compression)。
(2) 与上面所说的行级压缩相对应,在SQL Server 2008中所采用的另外一种压缩策略是”页级压缩(Page level compression)",它是在一个数据页内部减少一个或多个数据行的列之间的数据冗余。它的设计思想是:在一个数据页(对于SQL Server为8KB)内部,对于冗余数据只存储一次,然后在用到的地方进行多次引用而非多次重复存储,以此来减少存储空间的占用。例如如下的表:
对于这样一个表,如果插入很多数据行,那么很可能很多行的status列都是使用默认的"full time“值。这种情况下,SQL Server 2008可以通过在数据页内只存储"full time"一次,然后在其他需要的地方进行引用,这样存储空间自然减少了。很显然,这种压缩策略的效果取决于冗余数据的数量。
在 SQL Server 2008 Data Compression这篇博客中,博客作者Shailan Chudasama用以下两幅图说明了页级压缩的实现原理,与行级压缩一样,页级压缩也是通过DDL暴露给用户的。

图3 通过引用减少冗余数据的存储

图4 冗余数据字典
从上面两幅图,我们可以猜想在SQL Server 2008中的页级压缩中,采用了类似LZ78/LZ77这样的字典压缩算法的思想,到底是否这样,我们暂且拭目以待。
在Sunil Agarwal的另外一篇博客 Estimating the space savings with data compression中,他使用如下的表进行了压缩效果的测试:
以下是目前能够找到的关于SQL Server 2008的数据压缩的相关信息:
(1) SQL Server 2008 Data Compression
(2) Data Compression: Why Do we need it?
(3) Data compression techniques and trade offs
(4) Katmai (Sql 2008) - Data Compression (including Backup Compression)
(5) Why not use compressed disk files or disk volumes?
(6) Estimating the space savings with data compression
(7) Types of data compression in SQL Server 2008
(8) Data Compression will be available in CTP-6
最后说些题外话,在接下来的SQL Server系列文章中,我除了将会继续关注SQL Server 2008的新特性之外,还将会尝试解开SQL Server中的查询优化的秘密。提到SQL Server的查询优化,就不能不提到Goetz Graefe这个牛人,此君浸淫查询优化多年,于上世纪九十年代中期加入微软,应该是SQL Server的查询优化机制的主要设计者吧(我猜测的)。不过据悉此君已于今年初离开微软加盟HP实验室,这对微软来说应该是一个损失吧。
在 Types of data compression in SQL Server 2008这篇博客中, Sunil Agarwal提到了在SQL Server 2008中采用的两种压缩策略:
(1)以变长格式存储所有的定长数据类型。在本系列的 上一篇文章中,我提到过在SQL Server 2005 SP2中提供的使用vardecimal类型来存储decimal/numeric数据类型以节省存储空间的问题,有兴趣的朋友可以参考上一篇文章最后列出的相关链接以获取更多信息。在SQL Server 2008中,微软将这一思想扩展到了所有的定长数据类型,例如integer,char,float类型。需要注意的是,虽然SQL Server 2008以变长格式存储所有的定长数据类型,但这只是一种存储的具体实现机制,并不会改变任何语义上的东西,任何客户的程序都不需要修改,因为它根本不关心也不必知道数据库内部具体的数据存储方式。
例子一:假设一个表中有一个32位整数列(integer),但是该列的值均在(0~255或-128~127)的范围内,那么SQL Server 2008就可以只用一个字节来存储该列的值,这与之前版本的SQL Server总是使用4个字节来存储该列相比,就节省了75%的空间。
例子二:假设一个表中有一个定长字符串列CHAR(100),在以前的SQL Server版本中,该列总是使用100个字节来存储(即使实际的字符串没有100个字节,也会在其后填充空格以达到长度正好为100)。但是在SQL Server 2008中,该列将根据实际字符串的长度来进行存储,例如"Hello"将只耗费5个字节存储空间,而"This is a longer string"将只需23个字节存储,分别带来95%和77%的存储空间的节省。
当然,在上述例子一中如果实际的数值变化范围超过了一个字节能够表示的范围,那么相应的压缩比就会降低;对于例子二也类似,如果实际的字符串长度接近100,那么压缩效果也会大大降低。这意味着压缩的效果将依赖于实际的数据值的分布,同时也依赖于表的架构定义,这可能不那么明显,但是想象一下上述的例子二,如果将列的定义改为CHAR(150),显然压缩的效果就更为显著。另外请注意,NULL值是不需要占用任何存储空间的(参见下面的行格式)。
在 SQL Server 2008 Data Compression这篇博客中,博客作者Shailan Chudasama用一副图形象的说明了上述例子一描述的场景:
图1 SQL Server 2008以变长格式存储整数类型列
在上面的图1中,我们注意到在SQL Server 2008中,存储一个字节能够表示的整数实际需要1.5个字节来存储,而不是我们上面例子一中所描述的一个字节,为什么会是这样呢?我们知道,在SQL Server中存储一个变长列时,需要额外的存储空间来存储该列在一个数据行中的位置,以便能够在需要的时候快速访问到该列,以下这幅图说明了在SQL Server 2000/2005中一个数据行是如何存储的:
图2 SQL Server 2000/2005中的数据行存储格式
从上面这副图2中,我们可以清楚的看到,一个定长列除了存储该列数据本身以外,是不需要额外的存储空间的。而对于一个变长列,除了该列数据本身所占的空间外,每个变长列还需要2个额外的字节来存储该列在数据行中的位置,这就是上图中的“Column Offset Array”。从这个意义上来将,将smallint甚至我们例子一中提到的integer数据类型以变长方式存储的压缩效果就几乎毫无意义了。因此在SQL Server 2008中针对这种情况进行了特殊的优化,那就是如果该列的长度不超过8字节,那么每列只需要4bit来存储上述的列偏移,这就清楚的解释了图1中的4Bits从何而来了。需要提醒大家的上,图2中的数据行存储格式在SQL Server 2008中依然有效,而且是默认的存储格式(我猜测应该是不启用数据压缩时所使用存储格式)。
在SQL Server 2008中,这种压缩策略是通过在DDL(数据操纵语言)中的“ROW COMPRESSION"而暴露出来的,这也就是我们通常所说的行级压缩(Row level compression)。
(2) 与上面所说的行级压缩相对应,在SQL Server 2008中所采用的另外一种压缩策略是”页级压缩(Page level compression)",它是在一个数据页内部减少一个或多个数据行的列之间的数据冗余。它的设计思想是:在一个数据页(对于SQL Server为8KB)内部,对于冗余数据只存储一次,然后在用到的地方进行多次引用而非多次重复存储,以此来减少存储空间的占用。例如如下的表:
Table
employee( name
varchar
(
100
),
status varchar ( 10 ) default ‘ full time’)
status varchar ( 10 ) default ‘ full time’)
在 SQL Server 2008 Data Compression这篇博客中,博客作者Shailan Chudasama用以下两幅图说明了页级压缩的实现原理,与行级压缩一样,页级压缩也是通过DDL暴露给用户的。
图3 通过引用减少冗余数据的存储
图4 冗余数据字典
从上面两幅图,我们可以猜想在SQL Server 2008中的页级压缩中,采用了类似LZ78/LZ77这样的字典压缩算法的思想,到底是否这样,我们暂且拭目以待。
在Sunil Agarwal的另外一篇博客 Estimating the space savings with data compression中,他使用如下的表进行了压缩效果的测试:
create
table
t1_big (c1
int
, c2
int
, c3
char
(
8000
))
go
declare @i int
select @i = 0
while ( @i < 6000 )
begin
insert into t1_big values ( @i , @i + 6000 , replicate (‘a’, 60 ))
set @i = @i + 1
end
-- find the current size of the uncompressed table
EXEC sp_spaceused N ' t1_big '
-- 输出结果如下:
Name Rows Reserved Data Index_size unused
t1_big 6000 48008 KB 48000 KB 8 KB 0 KB
-- 估计行压缩的效果
exec sp_estimate_data_compression_savings
' dbo ' , ' t1_big ' , NULL , NULL , ' ROW '
object_name schema_name index_id partition_number
-- --------- ----------- ------- -----------------
t1_big dbo 0 1
size_with_current_compression_setting(KB)
-- ---------------------------------------
48008
size_with_requested_compression_setting(KB)
-- -----------------------------------------
472
sample_size_with_current_compression_setting(KB)
-- ---------------------------------------------
39648
sample_size_with_requested_compression_setting(KB)
-- ------------------------------------------------
392
-- 估计页级压缩的效果
-- estimate the PAGE compression
exec sp_estimate_data_compression_savings
' dbo ' , ' t1_big ' , NULL , NULL , ' PAGE '
object_name schema_name index_id partition_number
-- --------- ---------------- ---------- -----------------
t1_big dbo 0 1
size_with_current_compression_setting(KB)
-- ---------------------------------------
48008
size_with_requested_compression_setting(KB)
-- -----------------------------------------
80
sample_size_with_current_compression_setting(KB)
-- ---------------------------------------------
39960
sample_size_with_requested_compression_setting(KB)
-- ------------------------------------------------
72
go
declare @i int
select @i = 0
while ( @i < 6000 )
begin
insert into t1_big values ( @i , @i + 6000 , replicate (‘a’, 60 ))
set @i = @i + 1
end
-- find the current size of the uncompressed table
EXEC sp_spaceused N ' t1_big '
-- 输出结果如下:
Name Rows Reserved Data Index_size unused
t1_big 6000 48008 KB 48000 KB 8 KB 0 KB
-- 估计行压缩的效果
exec sp_estimate_data_compression_savings
' dbo ' , ' t1_big ' , NULL , NULL , ' ROW '
object_name schema_name index_id partition_number
-- --------- ----------- ------- -----------------
t1_big dbo 0 1
size_with_current_compression_setting(KB)
-- ---------------------------------------
48008
size_with_requested_compression_setting(KB)
-- -----------------------------------------
472
sample_size_with_current_compression_setting(KB)
-- ---------------------------------------------
39648
sample_size_with_requested_compression_setting(KB)
-- ------------------------------------------------
392
-- 估计页级压缩的效果
-- estimate the PAGE compression
exec sp_estimate_data_compression_savings
' dbo ' , ' t1_big ' , NULL , NULL , ' PAGE '
object_name schema_name index_id partition_number
-- --------- ---------------- ---------- -----------------
t1_big dbo 0 1
size_with_current_compression_setting(KB)
-- ---------------------------------------
48008
size_with_requested_compression_setting(KB)
-- -----------------------------------------
80
sample_size_with_current_compression_setting(KB)
-- ---------------------------------------------
39960
sample_size_with_requested_compression_setting(KB)
-- ------------------------------------------------
72
以下是目前能够找到的关于SQL Server 2008的数据压缩的相关信息:
(1) SQL Server 2008 Data Compression
(2) Data Compression: Why Do we need it?
(3) Data compression techniques and trade offs
(4) Katmai (Sql 2008) - Data Compression (including Backup Compression)
(5) Why not use compressed disk files or disk volumes?
(6) Estimating the space savings with data compression
(7) Types of data compression in SQL Server 2008
(8) Data Compression will be available in CTP-6
最后说些题外话,在接下来的SQL Server系列文章中,我除了将会继续关注SQL Server 2008的新特性之外,还将会尝试解开SQL Server中的查询优化的秘密。提到SQL Server的查询优化,就不能不提到Goetz Graefe这个牛人,此君浸淫查询优化多年,于上世纪九十年代中期加入微软,应该是SQL Server的查询优化机制的主要设计者吧(我猜测的)。不过据悉此君已于今年初离开微软加盟HP实验室,这对微软来说应该是一个损失吧。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/954255
推荐阅读
相关标签

