
- 1python爬取b站403_使用Python爬取B站全站视频信息
- 2构筑安全堡垒:详解OpenSSL与OpenSSH在等保三级升级中的关键作用_openssh和openssl
- 3Python零基础入门教程
- 4程序员福利:好用的api接口_好用的ai接口 csdn
- 5day14(7/25)——Git 分布式版本控制系统
- 6一文吃透VSCode中git的相关配置与使用
- 7Primavera P6 EPPM R17.12.X Patch/Update(补丁/更新)_oracle primavera p6 r17.12
- 8植物大战僵尸杂交版2.2最新潜艇伟伟迷版本重磅发布更新下载_潜艇伟伟迷植物大战僵尸下载2.2
- 9solara,一个超级厉害的 Python 库!_python solara
- 10蓝桥杯 --- 日期问题模板_蓝桥杯日期问题测试用例
Mamba 模型_mamba模型
赞
踩
建议观看讲解视频:AI大讲堂:革了Transformer的小命?专业拆解【Mamba模型】_哔哩哔哩_bilibili
1. 论文基本信息

2. 创新点
选择性 SSM,和扩展 Mamba 架构,是具有关键属性的完全循环模型,这使得它们适合作为在序列上运行的一般基础模型的主干。
(i) 高质量:选择性在语言和基因组学等密集模式上带来了强大的性能。
(ii) 快速训练和推理:计算和内存在训练期间以序列长度线性缩放,并且在推理过程中自回归展开模型在每一步只需要恒定的时间,因为它不需要先前元素的缓存。
(iii) 长上下文:质量和效率共同产生了高达序列长度 1M 的真实数据的性能改进。
3. 背景
基础模型 (FM) 或在大量数据上预训练的大型模型,然后适应下游任务,已成为现代机器学习的有效范式。这些 FM 的主干通常是序列模型,对来自语言、图像、语音、音频、时间序列和基因组学等多个领域的任意输入序列进行操作。虽然这个概念与模型架构的特定选择无关,但现代 FM 主要基于一种类型的序列模型:Transformer 及其核心注意力层自注意力的功效归因于它能够在上下文窗口中密集地路由信息,使其能够对复杂的数据进行建模。然而,此属性带来了根本的缺点:无法对有限窗口之外的任何信息进行建模,以及相对于窗口长度的二次缩放。大量研究似乎在更有效的注意力变体上来克服这些缺点,但通常以牺牲使其有效的非常属性为代价。然而,这些变体都没有被证明在跨领域的规模上在经验上是有效的。
最近,结构化状态空间模型 (SSM) 已成为序列建模的一种有前途的架构。这些模型可以解释为循环神经网络 (RNN) 和卷积神经网络 (CNN) 的组合,灵感来自经典状态空间模型 (Kalman 1960)。此类模型可以非常有效地计算为递归或卷积,序列长度具有线性或接近线性缩放。此外,论文提出了一类新的选择性状态空间模型,它在几个轴上改进了先前的工作,以实现 Transformer 的建模能力,同时在序列长度上线性缩放。
之前的网络训练测试时间对比如下:
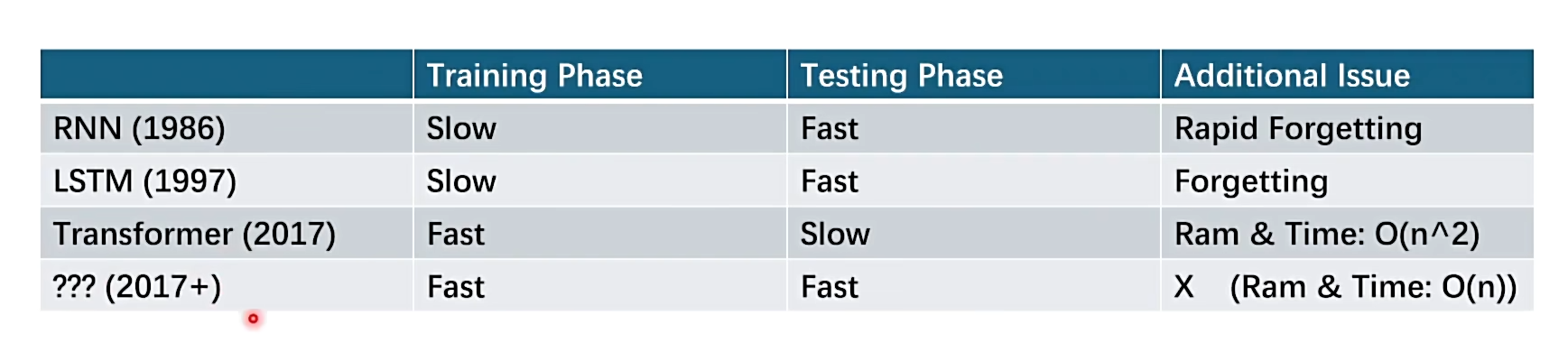
- 自注意力机制的缺陷:计算范围仅限于窗口内,缺乏全局观,但是窗口一旦扩大,计算复杂度(O n^2),每个位置都需要计算,计算复杂度扩大。
4. Pipeline
Parallel Computing:显卡中例如计算累加和,可使用下面的蝶形运算达到并行计算效果

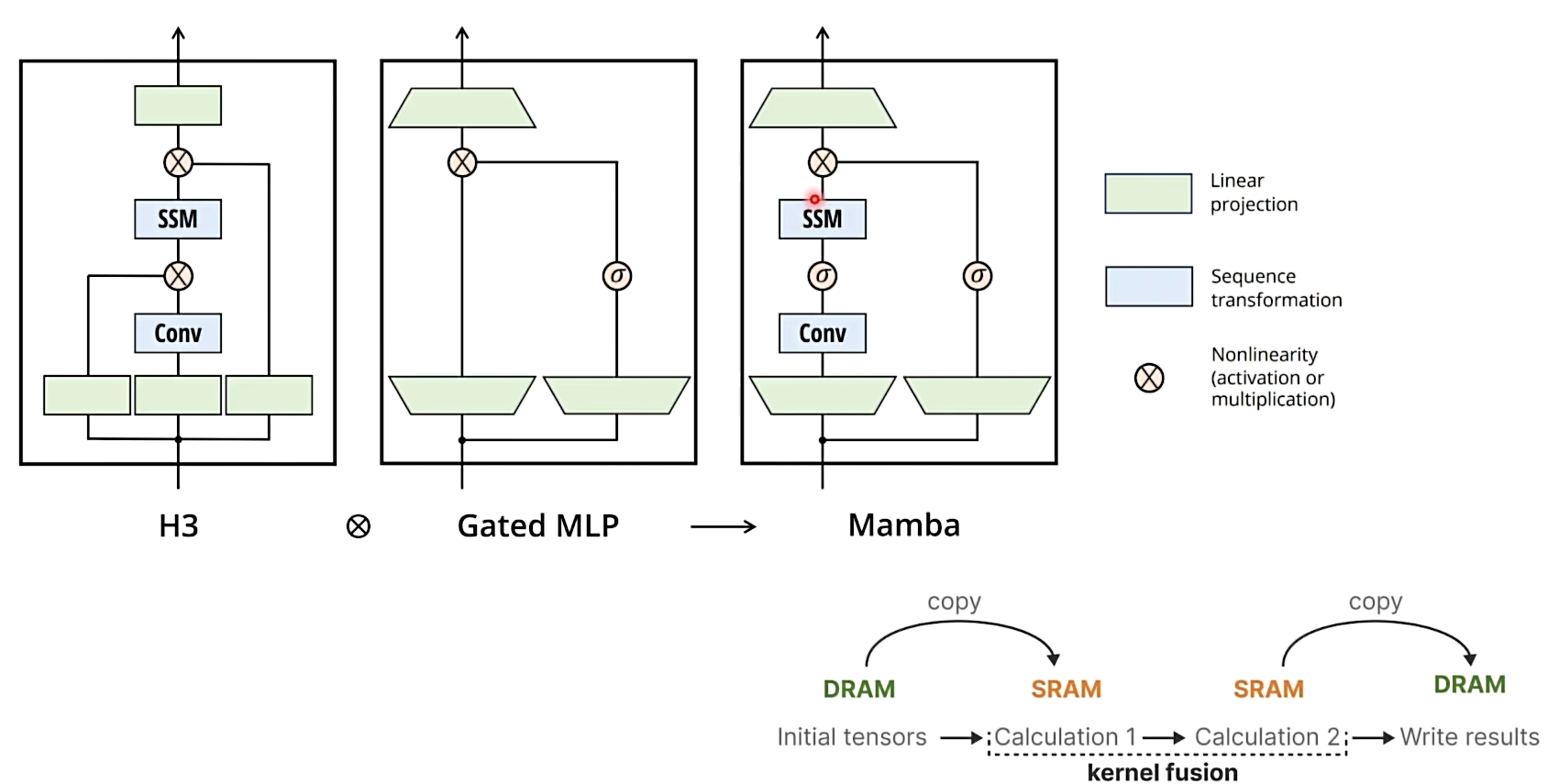
在 Transformer 中由于要存储 attention map 导致需要存储的内容过多,导致显卡中需要来回在 DRAM 和 SRAM 中做数据 copy ,导致降低了计算效率:

Mamba 的模型框架,硬件感知算法(某些值可能过大 在 SRAM 中无法存储,Manba 的思想是将其重算):
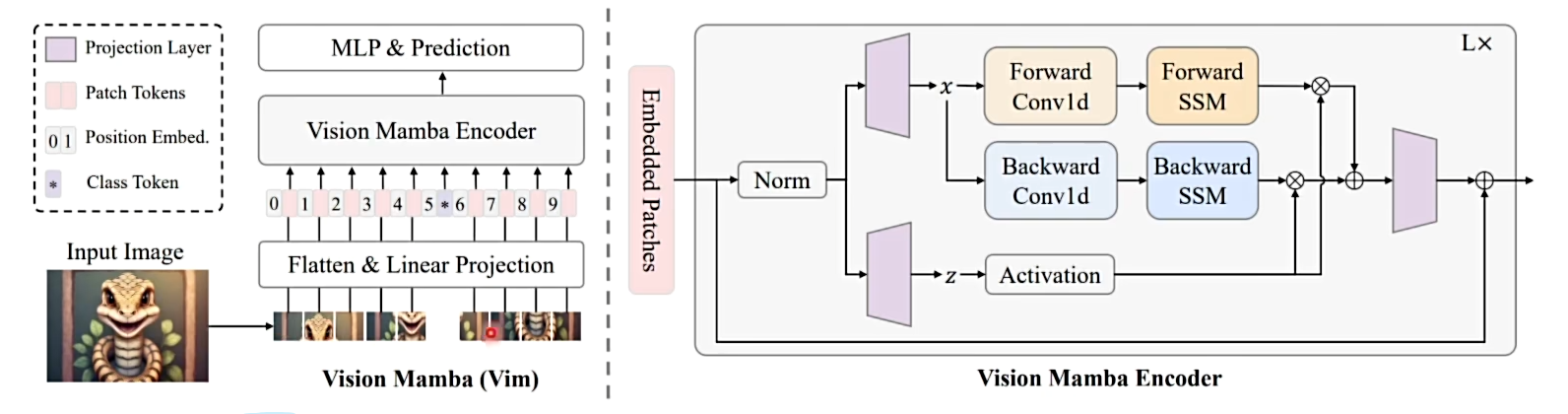
Vision Mamba:
4.1. 时序状态空间模型 SSM

NeurIPS 2021
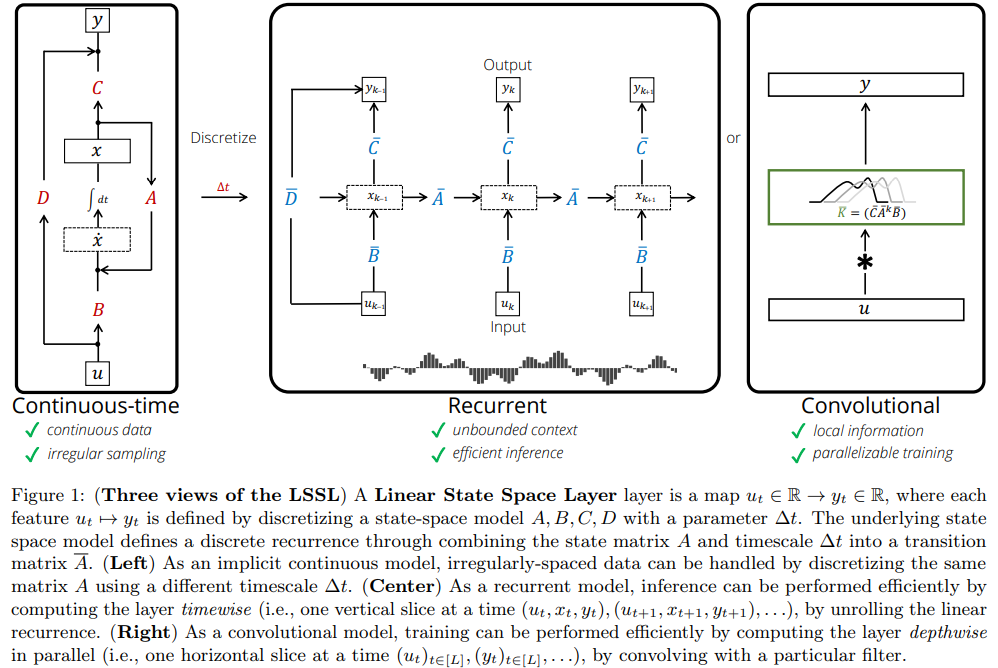
SSM 本质上是一个 CNN 化的 RNN,采用并行处理结构代替了原本的递归 RNN 。例如在生活中读一本书,时许嵌套的 RNN 每次只能读一行, 然后把记忆传递到下一行,这种方式只适合处理短故事,故事一长,容易忘记之前的情节。而 SSM 并行处理,相当于同时打开所有页看到每行内容,这样就能够快速找到和理解整本数。
4.2. 选择性 SSM
attention的核心思想其实就是在大量样本中能够找到重点,于是 Manba 在降低模型的存储复杂度的前提下,同样关注注意力机制的核心。
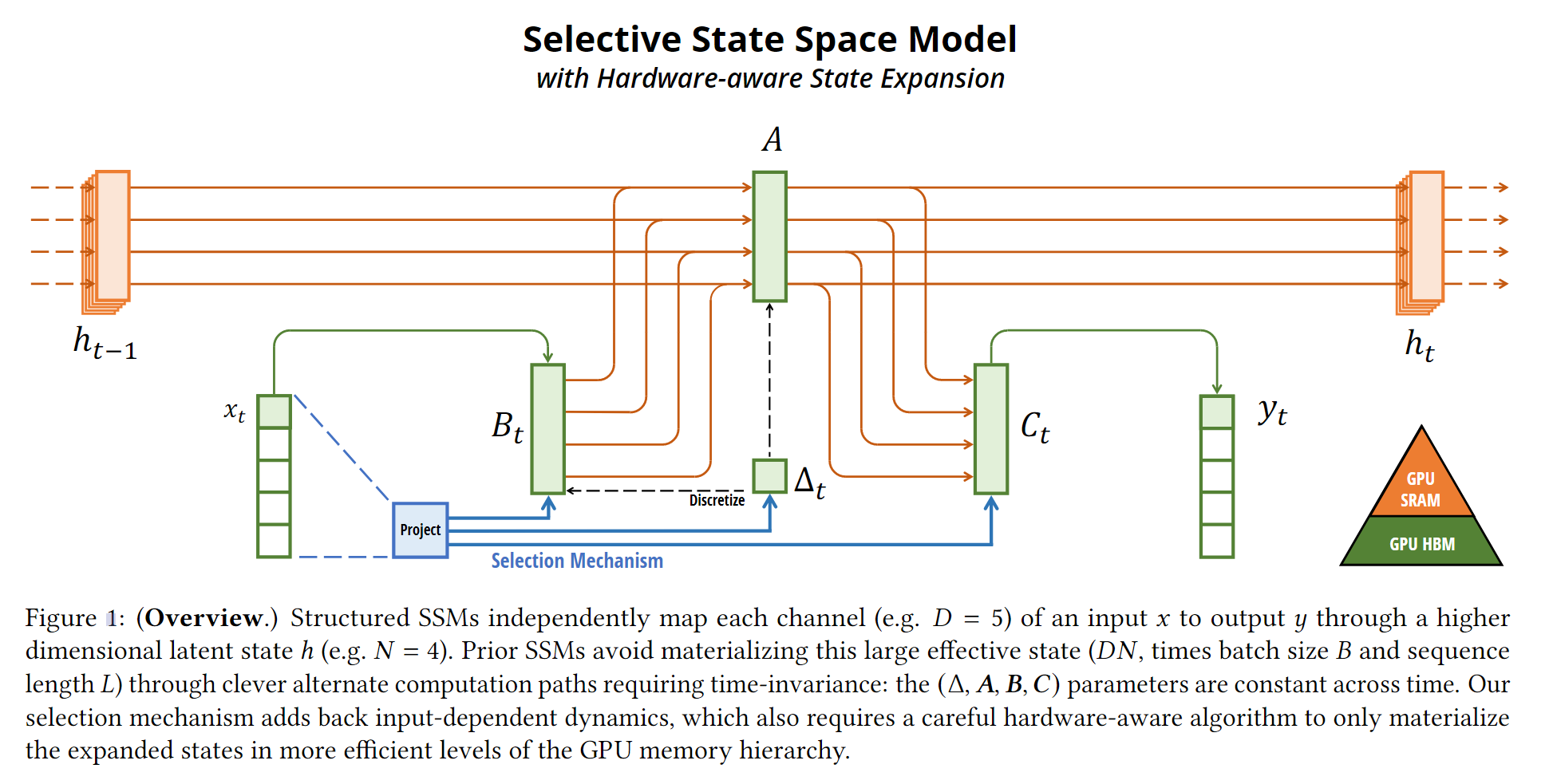
在框架图中,derta T 是通过 \tau(一种非线性激活函数),因此delta T 是非线性的,所以 ABC 都是非线性时变的,系统的条件就放开了。

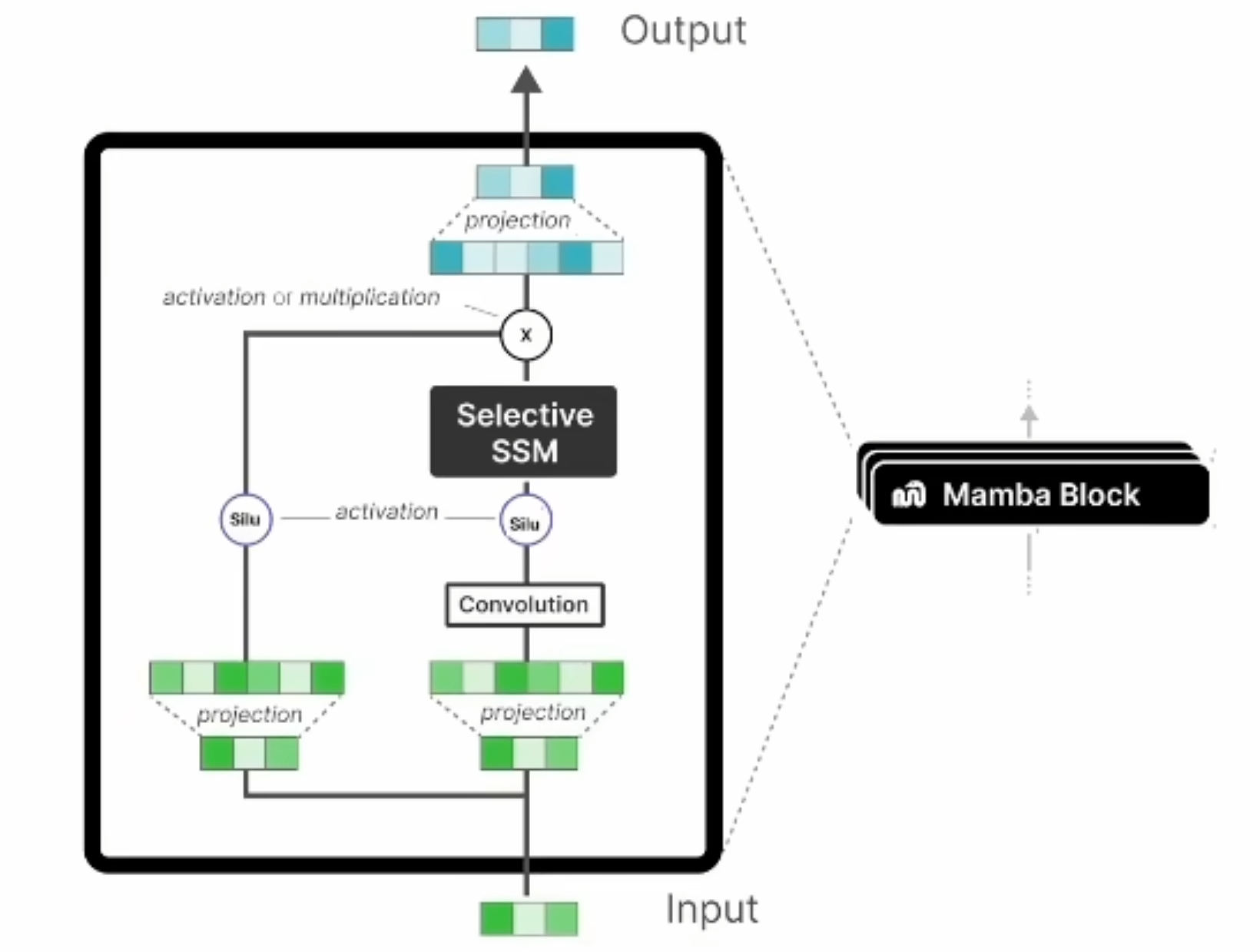
Mamba Block ,左边的线主要保证残差连接,避免梯度消失。右边先升维,在卷积提取时序特征,silu是非线性激活函数。
5. 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/960961
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

