- 1智谱AI发布新一代国产文本生成模型:GLM-4,“宣称”性能逼近GPT-4 (怎么又是GPT )_智谱 文本表示模型
- 22019-iswc-Google基于学习的问答摘要模型_question and answer pairs
- 3消息队列应用场景
- 4探索知识的边界:Apache Answer,你的团队智慧引擎
- 5【翻译】Elasticsearch Java API Client 8.13.2 (第三章-API约定)_elasticsearch client
- 6ZooKeeper系统模型之Leader选举算法分析。
- 7怎样规划学习Linux,就业方向有哪些?_学linux的就业方向
- 8linux用户组的常见操作
- 9Lua table(表)
- 10Python之Numpy使用详解_numpy在python中的用法
美团外卖搜索基于Elasticsearch的优化实践--图文解析_elasticsearch 美团
赞
踩
美团外卖搜索基于Elasticsearch的优化实践–图文解析
前言
美团在外卖搜索业务场景中大规模地使用了 Elasticsearch 作为底层检索引擎,随着业务量越来越大,检索速度变慢了,CPU快累趴了,所以要进行优化。经过检测,发现最耗资源(性能热点)的地方是倒排链的检索与合并,**Run-length Encoding(RLE)**技术设计实现了一套高效的倒排索引,使倒排链合并时间降低了 96%。将这一索引能力开发成了一款通用插件集成到 Elasticsearch 中,使得 Elasticsearch 的检索链路时延降低了 84%。
离线数仓:
离线数仓之所以被称为“离线”,是因为它处理的数据不是实时的,而是在一定时间周期内进行计算和存储。这与实时数据仓库(例如实时流数据)不同,后者可以立即处理和分析数据。所以,离线数仓更像是一个历史数据的“存储室”,用于长期分析和决策。
知名:Snowflake,Amazon Redshift,Google BigQuery等
近线检索:
近线检索是一种根据数据的相似性,在数据库中寻找与目标数据最相似的项目的技术。这个技术认为,特征数据的值约相近,之间的相似性就越高。
B端检索与C端检索:面向商家,企业,团队的检索。举例:商城app首页的搜索框是面向普通用户的C端检索,用来检索商品。而商城后台的运维等人员,商家检索该平台或同类别网店的历史数据进行决策分析等操作,属于B端检索。
倒排索引:
文中多次提到的 Posting List就是指的倒排链
通过一个单词,找到含有单词有关系的文章,是倒排索引
下图中包括程序员,产品经理,运维以及对应的docId的表就是倒排所以,其中每一个分词(或叫做词条,文中的Term)所以应的DocId就是该Term的倒排链:

为了增加查询效率,节省磁盘与内存资源,增加了字典树 term index概念:
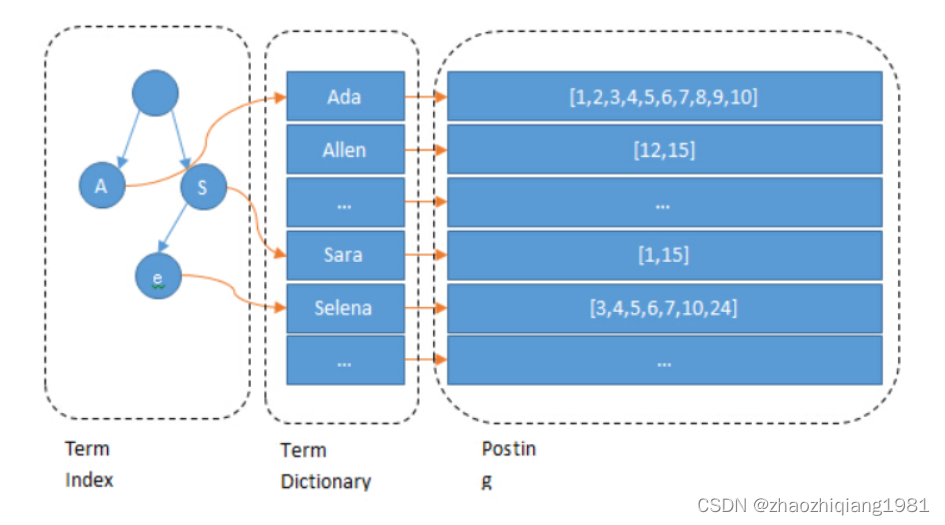
倒排链的合并:
如果用户的查询包含多个关键词,搜索引擎会合并这些关键词的倒排列表,找到同时包含这些关键词的文档。

背景
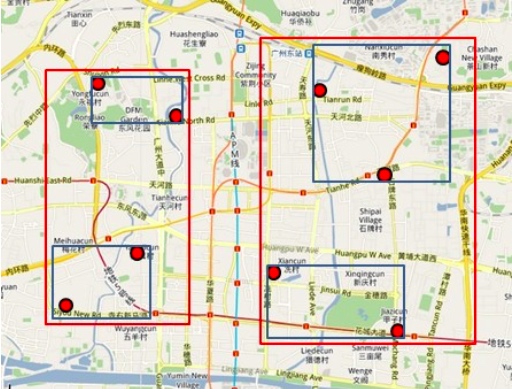
当前,外卖搜索主要为 Elasticsearch,具有较强的 Location Based Service(LBS) 依赖(其实就是地理位置有限制,太远了送不了),即用户所能点餐的商家,是由商家配送范围决定的。对于每一个商家的配送范围,大多采用多组电子围栏进行配送距离的圈定,一个商家存在多组电子围栏,并且随着业务的变化会动态选择不同的配送范围,电子围栏示意图如下:
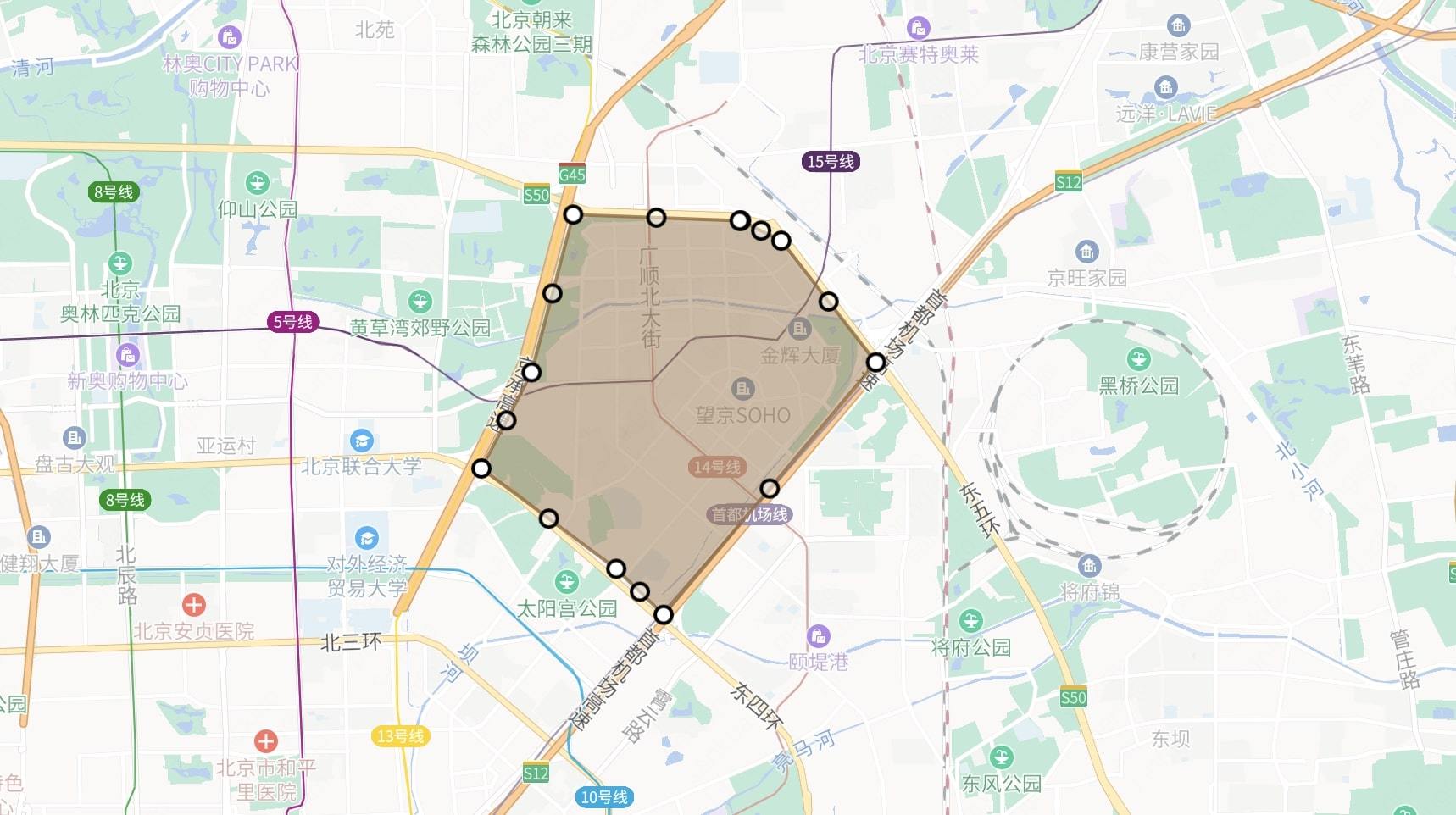
- 电子围栏:
- 定义:电子围栏是一种虚拟的地理边界,可以通过定位系统或其他位置服务技术来创建。
- 作用:商家可以使用电子围栏来限定配送范围,确保配送员在指定区域内进行配送。以及用来限制用户在自己的可配送范围内,搜索到可配送范围内的商家对应的商品。
- 多组电子围栏动态选择不同的配送范围:
- 定义:商家可能需要不止一个电子围栏来定义不同的配送区域,用来应对可能会随着时间和情况变化的业务需求。
- 例子:商家在城南开了一家烤串店,如果城北的用户点餐外卖,则会触发更大范围的电子围栏,提高配送费用等。
原文:
考虑到商家配送区域动态变更带来的问题,通过上游一组 R-tree 服务判定可配送的商家列表来进行外卖搜索。因此,LBS 场景下的一次商品检索,可以转化为如下的一次 Elasticsearch 搜索请求:
POST food/_search { "query": { "bool": { "must":{ "term": { "spu_name": { "value": "烤鸭"} } //... }, "filter":{ "terms": { "wm_poi_id": [1,3,18,27,28,29,...,37465542] // 上万 } } } } //... }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
R-tree
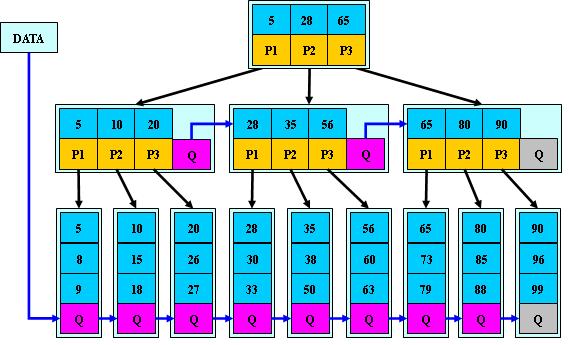
B树向多维空间发展的另一种形式
先说B树:
图片来自百度百科
比如我要查找id是38的数据,范围在28-65之间,选中28的p2,发现了范围在35-65之间,选择35的p2最后快速找到了38,而且是比SSD还要快的多的顺序查找。
R树和B树有点像:
图片来自百度百科
A和B是两个大的区域,里面包含了若干小区域,在R树中可以通过下图呈现(注意我们发现A和B其实里面有重叠的部分):
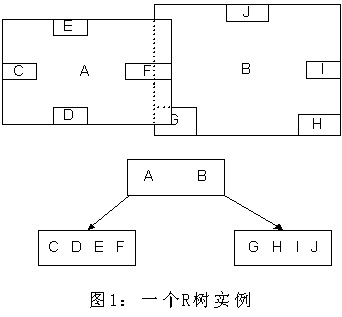
用地图的例子来解释,就是所有的数据都是餐厅所对应的地点,先把相邻的餐厅划分到同一块区域,划分好所有餐厅之后,再把邻近的区域划分到更大的区域,划分完毕后再次进行更高层次的划分,直到划分到只剩下两个最大的区域为止。要查找的时候就方便了。
下图以及进一步详细解释的内容来自:
https://blog.csdn.net/wzf1993/article/details/79547037
最后在解释一下如果发现重合区域怎么办:
-
S1:[查找子树] 如果T是非叶子结点,如果T所对应的矩形与S有重合,那么检查所有T中存储的条目,对于所有这些条目,使用Search操作作用在每一个条目所指向的子树的根结点上(即T结点的孩子结点)。
简单说就是两个同级别非叶子节点有重合区域了,检测已存储对应的子节点,检查指向到底是哪一个。
-
S2:[查找叶子结点] 如果T是叶子结点,如果T所对应的矩形与S有重合,那么直接检查S所指向的所有记录条目。返回符合条件的记录。
简单说就是父子节点有重合,检查父节点的条目看看有没有这个子节点
这里要注意的是Elasticsearch本身并不提供R-Tree功能,原文中也说了是上游提供的功能,需要先在程序中找到用户所在区域的叶子节点,再找到里面的所有商家,之后进行搜索。
POST food/_search { "query": { "bool": { "must":{ "term": { "spu_name": { "value": "烤鸭"} } //... }, "filter":{ "terms": { "wm_poi_id": [1,3,18,27,28,29,...,37465542] // 上万 } } } } //... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
代码中的wm_poi_id可能是使用到了Elasticsearch中的父子关系映射,用来模拟R-Tree,为了更好理解,下面例子中是一家店与这家店菜品的模拟
PUT /food/restaurants/1
{
"name": "烤鸭之家",
"address": "北京市朝阳区XXX路123号",
"phone": "123-456-7890",
"wm_poi_id": 1
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
POST /food/dishes
{
"wm_poi_id": 1, // 父文档的 wm_poi_id
"spu_name": "北京烤鸭",
"price": 88.0,
"description": "传统的烤鸭,外酥里嫩,美味可口。"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
POST /food/dishes
{
"wm_poi_id": 1,
"spu_name": "葱爆牛肉",
"price": 58.0,
"description": "香辣的葱爆牛肉,下饭绝佳。"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
原文:对于一个通用的检索引擎而言,Terms 检索非常高效,平均到每个 Term 查询耗时不到0.001 ms。因此在早期时,这一套架构和检索 DSL(ES的领域专用语言) 可以很好地支持美团的搜索业务——耗时和资源开销尚在接受范围内。然而随着数据和供给的增长,一些供给丰富区域的附近可配送门店可以达到 20000~30000 家,这导致性能与资源问题逐渐凸显。这种万级别的 Terms 检索的性能与耗时已然无法忽略,仅仅这一句检索就需要 5~10 ms。
挑战及问题
倒排链查询流程
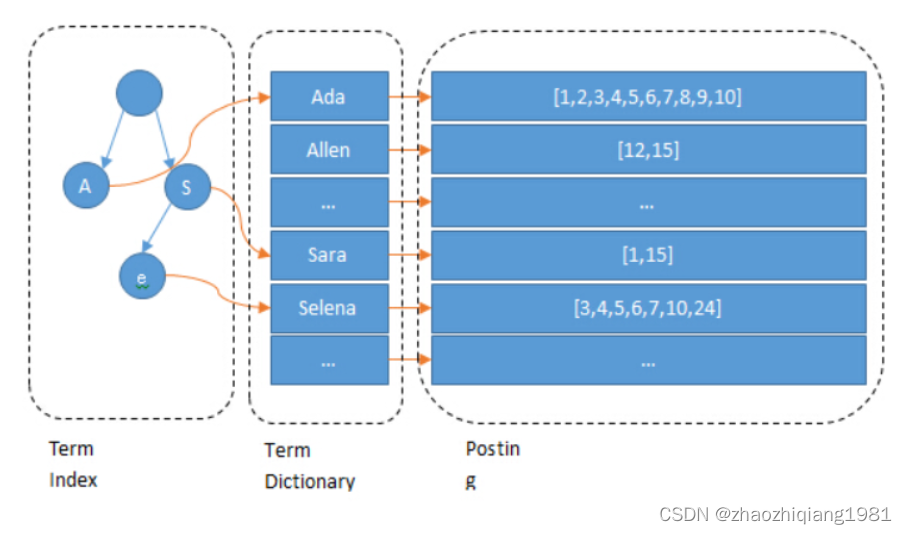
1,从内存中的 Term Index 中获取该 Term 所在的 Block 在磁盘上的位置。
“Block” 指的是磁盘上存储相关词条信息的数据块。这个概念与数据库中的"块"或"页"(通常是数据存储的基本单位)有些相似。在 Elasticsearch 中,倒排索引由多个这样的 Block 组成,每个 Block 包含了一组词条的信息,以及这些词条在文档中出现的位置。为了提高性能,同时又节约内存空间,所以不会在内存中直接存储词条对应的信息,而是存储一个block的位置,通过这个位置到硬盘上去查找具体的位置以及数据信息。
2,从磁盘中将该 Block 的 TermDictionary 读取进内存。
Block存储的所有词条信息被统称为TermDictionary,Elasticsearch 在处理查询时,通过加载整个 Block 来提高效率,因为通常情况下,相关的词条会被存储在相同或相近的位置。在TermDictionary中,存放的基本都是该词条以及和该词条相关的词条内容。
3,对倒排链存储格式的进行 Decode,生成可用于合并的倒排链。
倒排链的存储格式通常是压缩的,为了使用这些数据,需要先对它们进行解码也就是Decode。解码后就可以得到一个可用于查询合并的倒排链,包含了所有包含该词条的文档ID的列表。
原文:
可以看到,这一查询流程非常复杂且耗时,且各个阶段的复杂度都不容忽视。所有的 Term 在索引中有序存储,通过二分查找找到目标 Term。这个有序的 Term 列表就是 TermDictionary ,二分查找 Term 的时间复杂度为 O(logN) ,其中 N 是 Term 的总数量 。Lucene 采用 Finite State Transducer(FST)对 TermDictionary 进行编码构建 Term Index。FST 可对 Term 的公共前缀、公共后缀进行拆分保存,大大压缩了 TermDictionary 的体积,提高了内存效率,FST 的检索速度是 O(len(term)),其对于 M 个 Term 的检索复杂度为 O(M * len(term))。
公共前缀:如果多个词条有相同的开始部分,比如 “search”, “seek”, 和 “seem” 都以 “se” 开头,FST 会将 “se” 存储一次,然后链接到不同的后续字符。
公共后缀:同样地,如果多个词条在结尾处相同,FST 也会对这些后缀进行合并存储。
通过这种方式,FST 可以大大减少存储每个独立词条所需的空间,因为它只存储每个唯一的前缀和后缀一次。
O(len(term)):因为前缀与后缀的原因,查找速度与词条的长度有关。
前缀类似于这张图。
倒排链合并流程
在经过上述的查询,检索出所有目标 Term 的 Posting List 后,需要对这些 Posting List 求并集(OR 操作)。在 Lucene 的开源实现中,其采用 Bitset 作为倒排链合并的容器,然后遍历所有倒排链中的每一个文档,将其加入 DocIdSet 中。
伪代码如下:
Input: termsEnum: 倒排表;termIterator:候选的term
Output: docIdSet : final docs set
for term in termIterator: //遍历倒排表中的每一个词条
if termsEnum.seekExact(term) != null: //如果存在,不为空
docs = read_disk() // 磁盘读取
docs = decode(docs) // 倒排链的decode流程,解压缩,找到这个词条的倒排链
for doc in docs:
docIdSet.or(doc) //代码实现为DocIdSetBuilder.add。 //将倒排链中存放的doc信息存入docIdSet
end for
docIdSet.build()//合并,排序,最终生成DocIdSetBuilder,对应火焰图最后一段。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
原生es倒排链合并问题:
假设我们有 M 个 Term,每个 Term 对应倒排链的平均长度为 K,那么合并这 M 个倒排链的时间复杂度为:O(K * M + log(K * M))。 可以看出倒排链合并的时间复杂度与 Terms 的数量 M 呈线性相关。在我们的场景下,假设一个商家平均有一千个商品,一次搜索请求需要对一万个商家进行检索,那么最终需要合并一千万个商品,即循环执行一千万次,导致这一问题被放大至无法被忽略的程度。
下图说明了查找,读取,合并的火焰图确实存在高耗时。
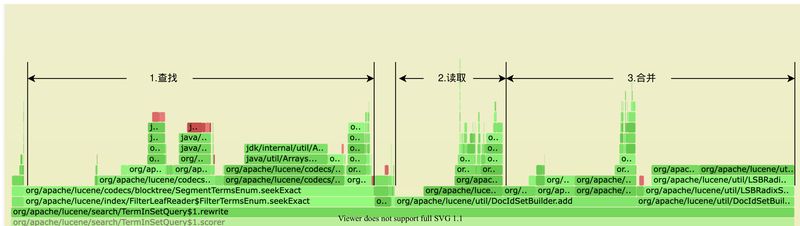
PS火焰图

技术探索与实践
倒排链查询优化
默认使用FST本身也是不错的选择,但在原文提到的背景中有些不适用,原因如下:
考虑到在外卖搜索场景有以下几个特性:
- Term 的数据类型为 long 类型。(可以巧妙利用long类型特有的压缩算法)
- 无范围检索,均为完全匹配。
- 无前缀匹配、模糊查找的需求,不需要使用前缀树相关的特性。(用不着FTS的特性)
- 候选数量可控,每个商家的商品数量较多,即 Term 规模可预期,内存可以承载这个数量级的数据。(我家内存够大)
最终方案:时间换空间,选择了查询复杂度O(1)的哈希表LongObjectHashMap,和传统的HashMap相比,LongObjectHashMap 可以存储更多的数据,对Long类型友好。

倒排链合并
原生实现
RoaringBitmap
原文:
当前 Elasticsearch 选择 RoaringBitMap 做为 Query Cache 的底层数据结构缓存倒排链,加快查询速率。
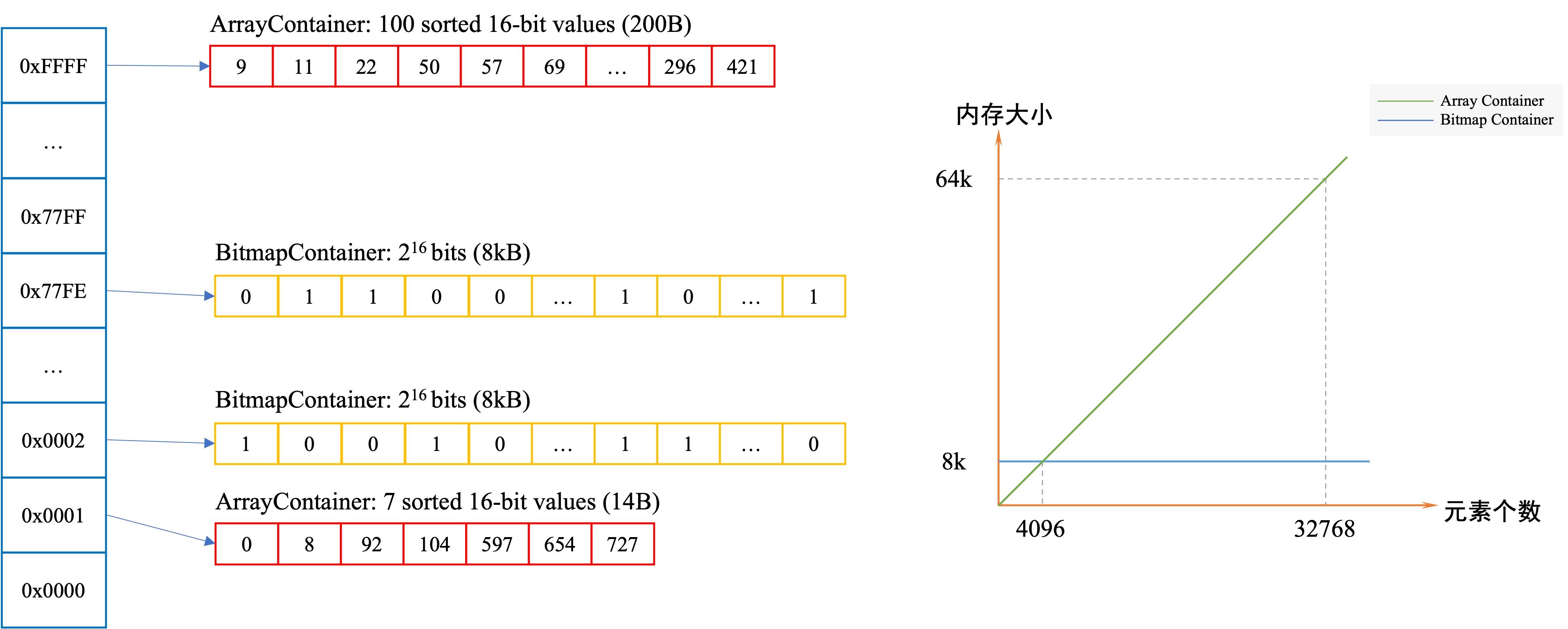
RoaringBitmap 是一种压缩的位图,相较于常规的压缩位图能提供更好的压缩,在稀疏数据的场景下空间更有优势。以存放 Integer 为例,Roaring Bitmap 会对存入的数据进行分桶,每个桶都有自己对应的 Container。在存入一个32位的整数时,它会把整数划分为高 16 位和低 16 位,其中高 16 位决定该数据需要被分至哪个桶,我们只需要存储这个数据剩余的低 16 位,将低 16 位存储到 Container 中,若当前桶不存在数据,直接存储 null 节省空间。 RoaringBitmap有不同的实现方式,下面以 Lucene 实现(RoaringDocIdSet)进行详细讲解:
如原理图中所示,RoaringBitmap 中存在两种不同的 Container:Bitmap Container 和 Array Container。
图3 Elasticsearch中Roaringbitmap的示意图
这两种 Container 分别对应不同的数据场景——若一个 Container 中的数据量小于 4096 个时,使用 Array Container 来存储。当 Array Container 中存放的数据量大于 4096 时,Roaring Bitmap 会将 Array Container 转为 Bitmap Container。即 Array Container 用于存放稀疏数据,而 Bitmap Container 用于存放稠密数据,这样做是为了充分利用空间。下图给出了随着容量增长 Array Container 和 Bitmap Container 的空间占用对比图,当元素个数达到 4096 后(每个元素占用 16 bit ),Array Container 的空间要大于 Bitmap Container。
针对上面原文的解析:
要了解RoaringBitmap,首先要简单了解下Bitmap:
假设要缓存这样一些数字到Bitmap中: 2,5,7,9

首先,创建一个数组,长度为要缓存数字的最大值+1,例子中最大数字是9,则创建的数组长度为9+1=10
数组中只存放0或1,为1表示存放的数字存在,0表示不存在
因为数组下标是从0开始的,实际的值就是数组值为1的下标值+1
Bitmap有一个很严重的缺陷就是:如果数据稀疏,比如1,2,3,999999999999,一共四个数字,但要创建一个特别特别大的数组来存放,中间有一大段数组值为0,数据稀疏问题需要通过RoaringBitmap来解决。
RoaringBitmap优化Bitmap
1.将存储容器分为Bitmap Container(位图容器) 和 Array Container(数组容器),数据量小于4096使用数组容器
数据量大于4096使用位图容器
其中的位图容器和传统bitmap特性相似,用来存储应对数据稠密场景,而稀疏数据通过数组存储。在储存时,RoaringBitmap算法会安排数组容器适当的占用位图容器中的稀疏空间,从而更小有效的利用内存。
原文中的分桶,高16位,低16位又是什么意思呢:
假设我们有一些整数:65537, 65538, 131073。在 RoaringBitmap 中,这些数会被分为高16位和低16位:
对于 65537(二进制为 00000001 00000000 00000001),高16位是 00000001 00000000(即1),低16位是 00000001(即1)。
对于 65538(二进制为 00000001 00000000 00000010),高16位是 00000001 00000000(即1),低16位是 00000010(即2)。
对于 131073(二进制为 00000010 00000000 00000001),高16位是 00000010 00000000(即2),低16位是 00000001(即1)。
在这个例子中,65537 和 65538 会被放入编号为1的"桶"中,而 131073 会被放入编号为2的"桶"中。这样,当我们需要查找一个数是否存在时,我们先看它的高16位,确定去哪个"桶"查找,然后在那个"桶"里用低16位找到具体的数。这种方法使得存储更加紧凑,检索也更快速。
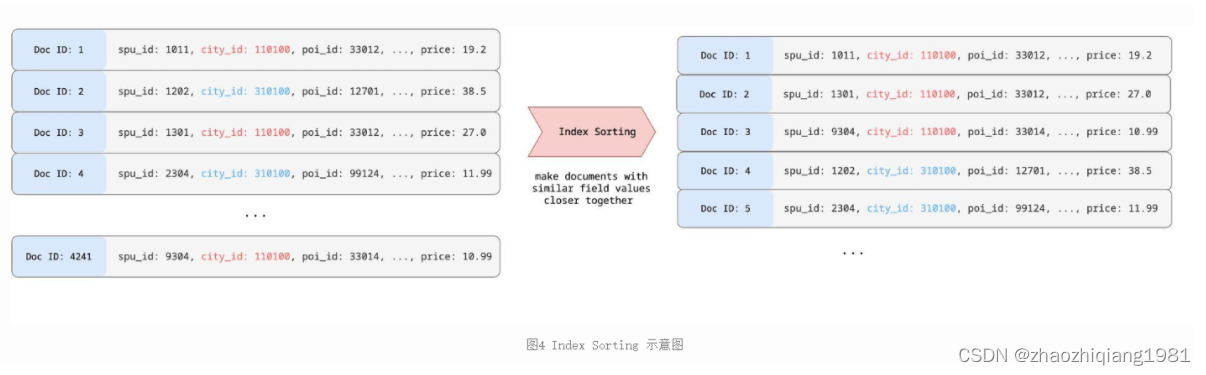
Index Sorting
这个比较好理解,就是说Elasticsearch 从 6.0 版本开始在索引阶段可以配置多个字段进行排序了。
基于 RLE 的倒排格式设计
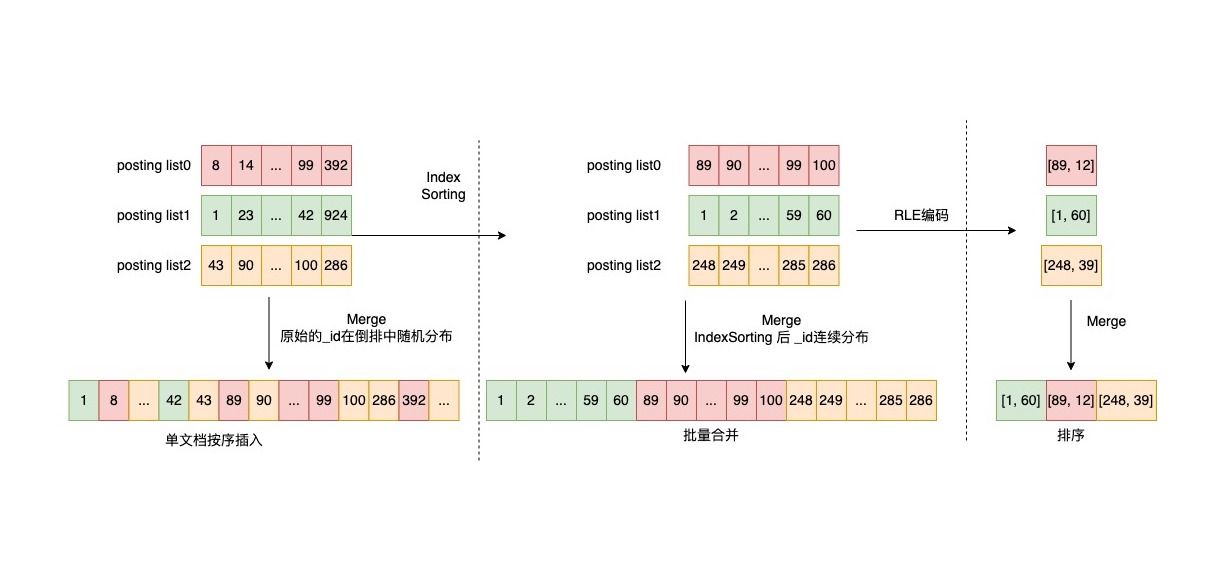
Run-Length Encoding
原理:对于完全连续数字{1,2,3,4,5,6,7,8,9,10} —>经过RLE压缩为—>{1,10} 也就是{start,length}
RoaringBitmap对于美团外卖场景仍然需要进一步优化,通过使用Index Sorting对多个字段进行排序后得到一个突破性进展,即通过一些字段进行排序后,商家的商品ID完全连续了。
在 bitmap 这一场景之下,主要通过压缩连续区间的稠密数据,节省内存开销。以数组 [1, 2, 3, …, 59, 60, 89, 90, 91, …, 99, 100] 为例(如下图上半部分):使用 RLE 编码之后就变为 [1, 60, 89, 12]——形如 [start1, length1, start2, length2, …] 的形式,其中第一位为连续数字的起始值,第二位为其长度。
同时还对倒排链的合并做了修改,由原来的单文档按序插入优化为批量合并,最终通过Index Sorting排序后,通过RLE编码对完全连续的数字进行了压缩:
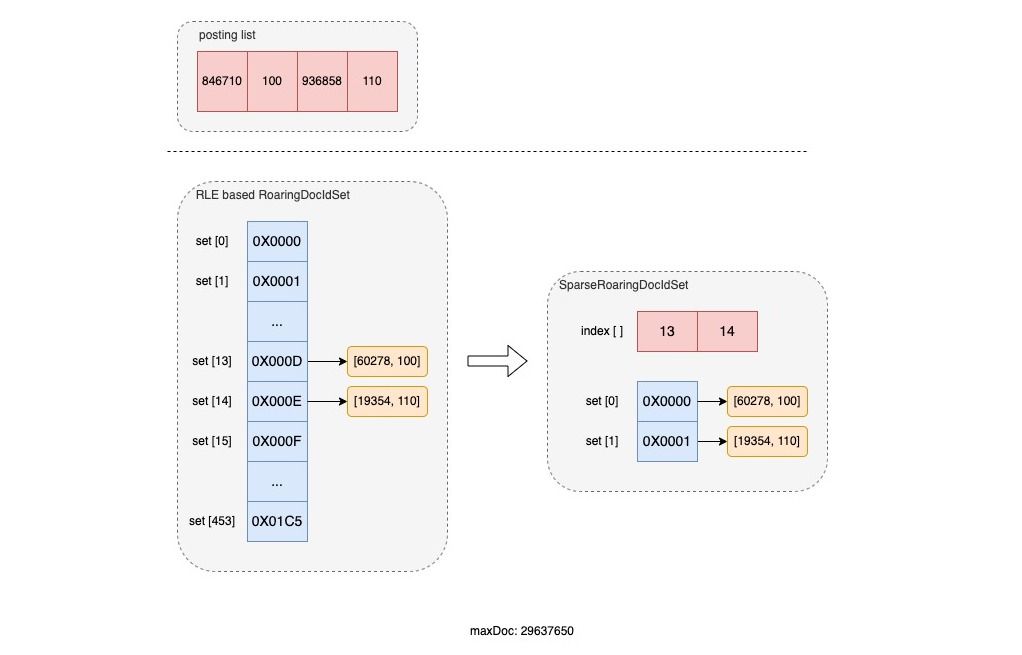
SparseRoaringDocIdSet
RoaringBitmap中存在分桶操作,如下图,可能存在有些桶是空的,美团技术团队通过实现SparseRoaringDocIdSet,额外使用一组索引记录所有有值的 桶的 位置。
原文也介绍了ES也通过算法优化节约开销了:在 Elasticsearch 场景上,RoaringDocIdSet 在申请 bucket 容器的数组时,会根据当前 Segment 中的最大 Doc ID 来申请**,**这种方式可以避免每次均按照 Integer.MAX-1 来创建容器带来的无谓开销。
经过上述修改,倒排链合并耗时节约了96%
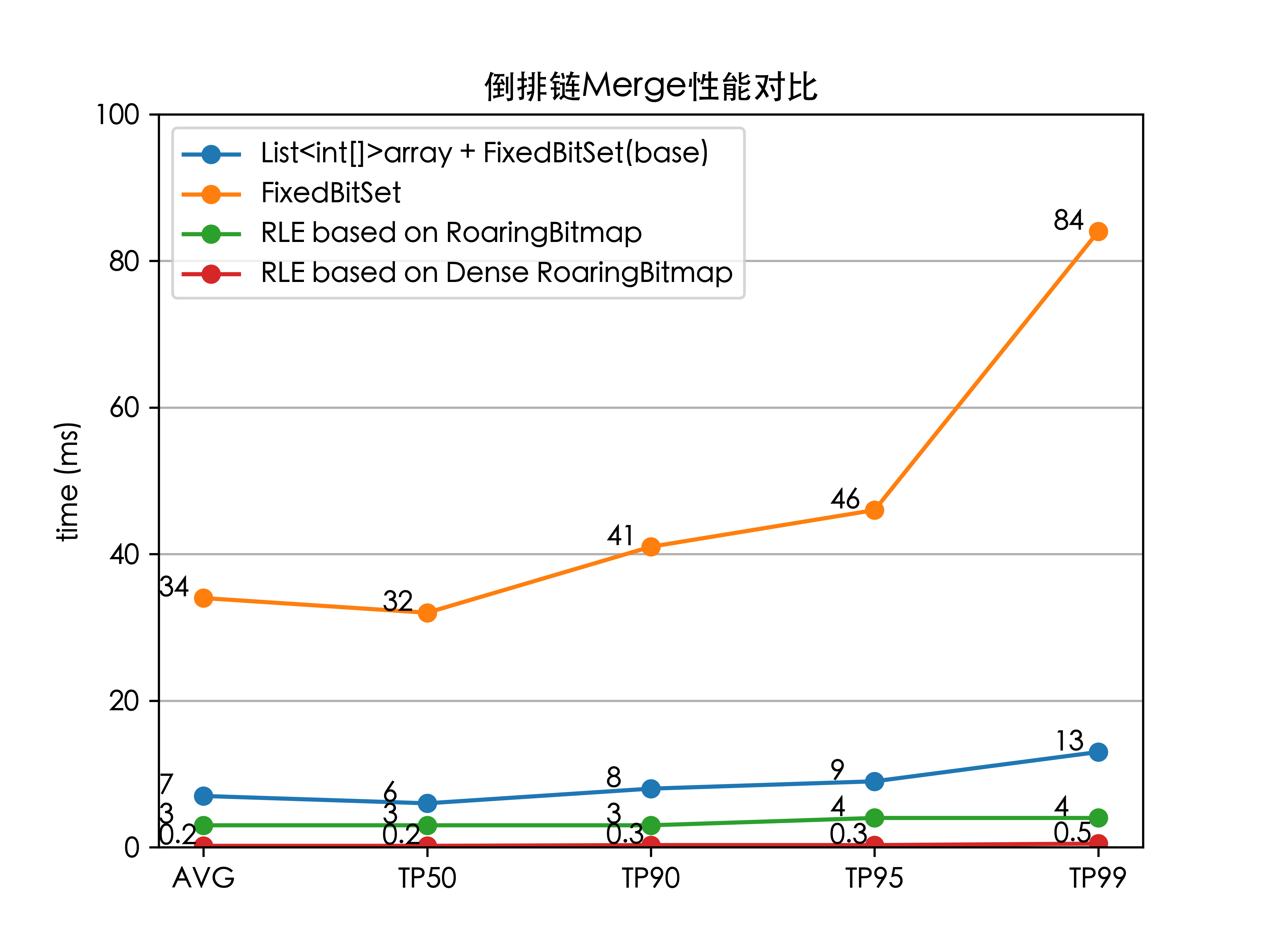
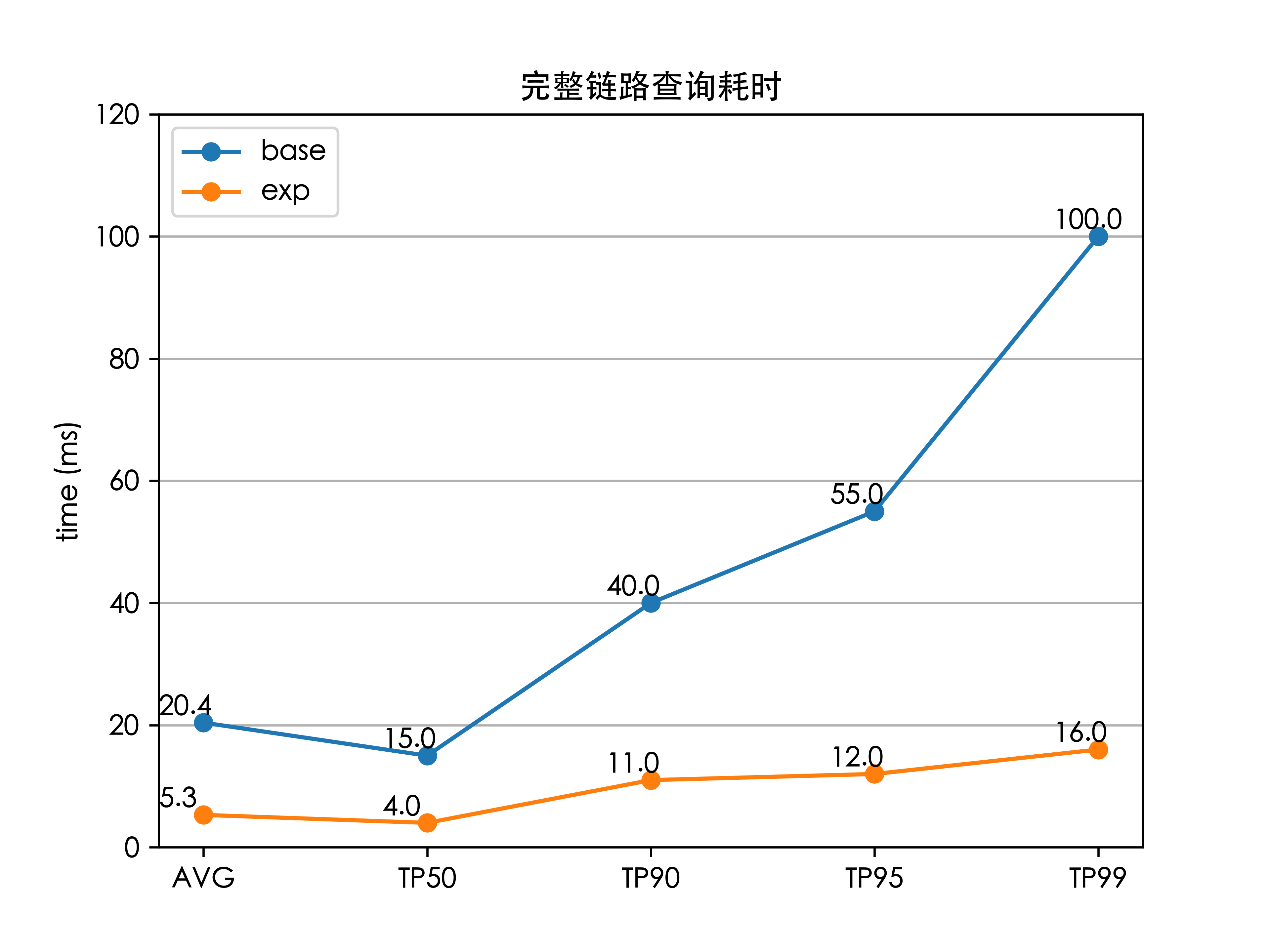
最终将上述优化集成到ES中,以及做了若干调整上线测试后,全链路的检索时延(TP99)降低了 84%(100 ms 下降至 16 ms),解决了外卖搜索的检索耗时问题,并且线上服务的 CPU 也大大降低。
位置。
原文也介绍了ES也通过算法优化节约开销了:在 Elasticsearch 场景上,RoaringDocIdSet 在申请 bucket 容器的数组时,会根据当前 Segment 中的最大 Doc ID 来申请**,**这种方式可以避免每次均按照 Integer.MAX-1 来创建容器带来的无谓开销。
[外链图片转存中…(img-TzaAhAdI-1719651983203)]
经过上述修改,倒排链合并耗时节约了96%
[外链图片转存中…(img-JsIhX5W7-1719651983204)]
最终将上述优化集成到ES中,以及做了若干调整上线测试后,全链路的检索时延(TP99)降低了 84%(100 ms 下降至 16 ms),解决了外卖搜索的检索耗时问题,并且线上服务的 CPU 也大大降低。