
- 1发现区块链世界的新大门——AppBag.io DApp导航网站全面解析
- 2国内的数据安全与隐私保护现状如何?_我国数据隐私保护方面的现状
- 322.扩展.论信息系统项目的安全管理(学习)
- 4idea如何下载github项目_idea导入github项目
- 5LangChain+ChatGLM大模型应用落地实践(一)
- 6飞机飞行原理之空气流动基本规律_气流流动的基本规律
- 7PS超强插件——StartAI(重磅来袭)_startai邀请码
- 8langgraph之智能体工作流
- 9ERROR: Could not build wheels for pypesg, which is required to install pyproject.toml-based projects_could not build wheels for echarts-china-cities-py
- 10【智能楼宇秘籍】一网关多协议无缝对接BACnet+OPC+MQTT_opc和bacnet对接方案
Elasticsearch 开放 inference API 增加了对 Azure OpenAI 嵌入的支持_cohere免费使用
赞
踩
我们很高兴地宣布,Elasticsearch 现在在我们的开放 inference API 中支持 Azure OpenAI 嵌入,使开发人员能够将生成的嵌入存储到我们高度可扩展和高性能的向量数据库中。
这一新功能进一步巩固了我们不仅致力于与 Microsoft 和 Azure 平台合作的承诺,而且还进一步巩固了我们为客户提供更灵活的 AI 解决方案的承诺。
Elastic 对人工智能的持续投资
这是 Elasticsearch 的 AI 支持的一系列附加功能和集成中的最新功能,如下:
- Elasticsearch 开放 inference API 增加了 Azure AI Studio 支持
- Elasticsearch 开放 inference API 添加了对 Azure OpenAI chat completions 的支持
- Elasticsearch 开放 inference API 添加了对 OpenAI chat completions 成的支持
- Elasticsearch 开放 inference API 增加了对 Cohere Embeddings 的支持
- 将 Elasticsearch 向量数据库引入到数据上的 Azure OpenAI 服务(预览)
Azure OpenAI 的新 inference 嵌入服务提供商已在 Elastic Cloud 上的 stateless 产品中提供,并将很快在即将发布的 Elastic 版本中向所有人提供。
将 Azure OpenAI 嵌入与 Elasticsearch Inference API 结合使用
部署 Azure OpenAI 嵌入模型
首先,你需要 Microsoft Azure 订阅以及 Azure OpenAI 服务的访问权限。 注册并有权访问后,你需要在 Azure 门户中创建资源,然后将嵌入模型部署到 Azure OpenAI Studio。 为此,如果你的 Azure 门户中还没有 Azure OpenAI 资源,请从 Azure 市场中找到的 “Azure OpenAI” 类型创建一个新资源,并记下你需要的资源名称 这个稍后再说。 创建资源时,你选择的区域可能会影响你可以访问的模型。 有关更多详细信息,请参阅 Azure OpenAI 部署模型可用性表。

获得资源后,你还需要一个 API 密钥,可以在 Azure 门户左侧导航的 “Keys and Endpoint” 信息中找到该密钥:
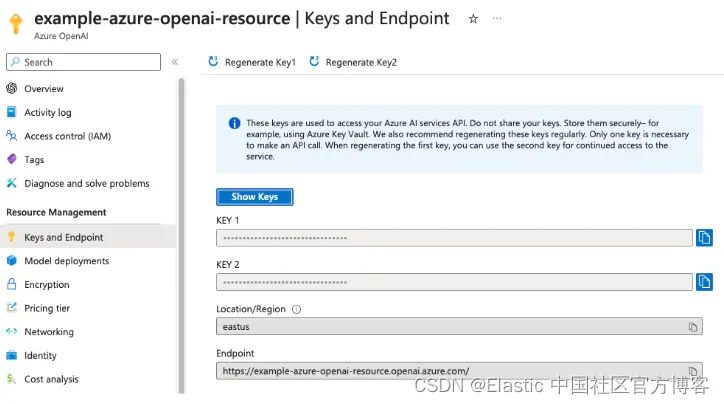
现在,要部署 Azure OpenAI Embedding 模型,请进入 Azure OpenAI Studio 控制台并使用 OpenAI Embeddings 模型(例如 text-embedding-ada-002)创建部署。 创建部署后,你应该会看到部署概述。 另请记下部署名称,在下面的示例中,它是 “example-embeddings-model”。

将部署的 Azure OpenAI 嵌入模型与 Elasticsearch Inference API 结合使用
部署 Azure OpenAI 嵌入模型后,我们现在可以配置 Elasticsearch 部署的 _inference API 并创建一个管道来索引文档中的嵌入向量。 请参阅 Elastic Search Labs GitHub 存储库以获取更深入的指南和交互式笔记本。
要执行这些任务,你可以使用 Kibana 开发控制台或你选择的任何 REST 控制台。
首先,使用创建推理模型端点配置推理端点 - 我们将其称为 “example_model”:
- PUT _inference/text_embedding/example_model
- {
- "service": "azureopenai",
- "service_settings": {
- "api_key": "<api-key>",
- "resource_name": "<resource-name>",
- "deployment_id": "<deployment-id>",
- "api_version": "2024-02-01"
- },
- "task_settings": {
- "user": "<optional-username>"
- }
- }
对于 inference 端点,你将需要 API 密钥、资源名称以及上面创建的部署 ID。 对于 “api_version”,你需要使用 Azure OpenAI 嵌入文档中的可用 API 版本 - 我们建议始终使用最新版本,即撰写本文时的 “2024-02-01”。 你还可以选择在任务设置的 “user” 字段中添加用户名,该用户名应该是代表最终用户的唯一标识符,以帮助 Azure OpenAI 监控和检测滥用行为。 如果你不想这样做,请省略整个 “task_settings” 对象。
运行此命令后,你应该收到 200 OK 状态,表明模型已正确设置。
使用执行 inference 端点,我们可以看到推理端点的工作示例:
- POST _inference/text_embedding/example_model
- {
- "input": "What is Elastic?"
- }
上述命令的输出应提供输入文本的嵌入向量:
- {
- "text_embedding": [
- {
- "embedding": [
- -0.0038039694,
- 0.0054465225,
- -0.0018359756,
- -0.02274399,
- -0.01969836,
- ...
- ]
- }
- ]
- }
现在我们知道推理端点可以工作,我们可以创建一个使用它的管道:
- PUT _ingest/pipeline/azureopenai_embeddings
- {
- "processors": [
- {
- "inference": {
- "model_id": "example_model",
- "input_output": {
- "input_field": "name",
- "output_field": "name_embedding"
- }
- }
- }
- ]
- }
这将创建一个名为 “azureopenai_embeddings” 的摄取管道,它将在摄取时读取 “name” 字段的内容,并将模型中的嵌入推断应用到 “name_embedding” 输出字段。 然后,你可以在摄取文档时(例如通过 _bulk 摄取端点)或对已填充的索引重新建立索引时使用此摄取管道。
目前可通过我们在 Elastic Cloud 上的 stateless 产品中的开放推理 API 获得此功能。 它还将很快在即将推出的 Elasticsearch 版本中向所有人开放,并具有额外的语义文本功能,使此步骤更容易集成到你现有的工作流程中。
对于其他用例,你可以浏览带有推理的语义搜索教程,了解如何使用 Azure OpenAI 和其他服务(例如重新排名或 chat completions)大规模执行摄取和语义搜索。
还有更多即将到来
这种新的可扩展性只是我们从 Elastic 引入 AI 表的众多新功能之一。 立即为 Elastic Search Labs 添加书签以了解最新动态! 准备好将 RAG 构建到您的应用程序中了吗? 想要尝试使用矢量数据库的不同 LLMs? 在 Github 上查看我们的 LangChain、Cohere 等示例笔记本,并参加即将开始的 Elasticsearch 工程师培训!
准备好自己尝试一下了吗? 开始免费试用。
Elasticsearch 集成了 LangChain、Cohere 等工具。 加入我们的高级语义搜索网络研讨会,构建您的下一个 GenAI 应用程序!
原文:Elasticsearch open inference API adds support for Azure OpenAI embeddings — Elastic Search Labs

