
- 1uniapp微信小程序自定义刘海屏头部兼容问题_unipp 刘海屏幕 兼容写法
- 2MyBatisPlus与MyBatis的对比与联系_mymatisplus 和mymatis 对比图
- 3Mac安装多个Java环境_mac air m2 安装多个java
- 4linux逻辑卷/dev/mapper/centos-root扩容增加空间
- 5云服务器迁移 (全网最省钱最详细攻略)_服务器迁移难吗
- 6黑客学习手册(自学网络安全)_黑客学习资料
- 7css实现两行或多行显示省略号_css双行省略号怎么写
- 8linux ssh连接问题总结与解决方案_ssh无法连接linux服务器
- 9【Unity组件知识】如何在Unity2020以后版本中打包图集_unity 打包图集
- 102023年最新Java八股文面试题,面试应该是够用了(吊打面试官)_java面试八股文2023
Pointnet语义分割任务S3DIS数据集_s3dis数据集大小
赞
踩
1.前言
Pointnet的网络结构和源码解释,已在之前写了次总结,本次主要针对论文中的数据集以.h5为TensorFlow的输入格式进行解释,记录如何制作H5文件,以提供给TensorFlow,PyTorch框架中进行训练。
首先,Pointnet一文中针对3个不同的任务使用到了三个数据集,分别为:
-
点云分类(3D Object Classification)——
ModelNet40,下载命令在provider.py中,运行python train.py后便会自动下载(416MB)到**data/**文件夹下,每个点云包含从形状表面均匀采样的2048个点。每个云均值为零,并归一到单位球面。data/modelnet40_ply_hdf5_2048在h5文件中还指定文本ID的文本文件。 -
点云部分分割(3D Object Part Segmentation)——
ShapeNetPart,下载命令在part_seg/download_data.sh中
浏览器点击下载:
ShapeNet原始点云数据(约1.08GB)
ShapeNet-制作好的hdf5文件(约346MB)
或者直接在终端手动下载数据集:cd part_seg sh download_data.sh- 1
- 2
执行脚本后将下载上面对应的两个数据集,脚本会自动解压到项目目录下。接下来直接运行train.py和test.py进行训练和测试即可。
-
语义分割(Semantic Segmentation in Scenes)—— Stanford Large-Scale 3D Indoor Spaces Dataset
对S3DIS数据集进行简单说明:在6个区域的271个房间,使用Matterport相机(结合3个不同间距的结构光传感器),扫描后生成重建3D纹理网格,RGB-D图像等数据,并通过对网格进行采样来制作点云。对点云中的每个点都加上了1个语义标签(例如椅子,桌子,地板,墙等共计13个对象)。
用于训练的数据会按照房间来划分点集,将房间的点云数据划分为1 m × 1 m 1m×1m1m×1m的块,然后再对每个块预测其中每个点的语义标签。每个点由一个9-dim向量表示,分别为:
X, Y, Z, R, G, B, X,Y,Z——标准化后的每个点相对于所在房间的位置坐标( 值为0 - 1)。在训练时,从每个块中随机采样4096个点,使用K折交叉验证(github中是6折,论文中是3折) -
k-fold交叉验证:6-fold:训练集5个区域,测试集1个区域,3-fold:训练集4个区域,测试集2个区域,防止过拟合的常用手段。
注意: 这里有一个有意思的问题,对于分割网格进行训练,如果采用这种切分块式样的预处理方式作为输入,会影响到最后的结果,比如一张桌面出现两种不同的错误分割,这一点在RandLA-Net(2019)一文中进行了说明。因此那篇文章说道在做大场景点云分割的时候不能直接使用pointnnet这种方式,因为网络难以有效地学习到一个物体的整体几何结构,也是大场景点云分割的改进点。
2.数据集准备
-
1.如果没有最后的可视化要求,即只评价模型的分割准确度,不进行更多测试,那可以下载制作好的hdf5格式文件,不会在训练后生成.obj文件:
点击下载作者准备好的S3DIS-hdf5文件(大约1.6G)
或者在终端运行:cd sem_seg sh download_data.sh- 1
- 2
脚本会自动解压得到一个indoor3d_sem_seg_hdf5_data 文件夹,其中包含ply_data_all_0.h5~ply_data_all_23.h5 共24个.h5结尾的数据文件,每个文件都包含data和 label数据。除最后一个为585行数据以外,这24个文件共有23×1000+585=23585行,每行对应一个切分为1m ×1m×1m的Block,表示4096个点,每个点对应9个维度。
all_files.txt 中保存24个数据文件名,room_filelist.txt中数据为23585 行,对应每行的Block所对应的采集area和room。 -
2.如果想要进行测试和可视化,需要下载3D室内解析数据集(S3DIS Dataset数据集介绍)进行模型的测试和可视化工作。作者实验用的是Stanford3dDataset_v1.2_Aligned_Version数据集,填写信息进行下载下载链接。第一个是谷歌云平台存储的地址,第二个是一个共享文件形式,如果可以用谷歌云的话可能会方便很多。
在.txt文件中的保存的点云数据(XYZ,RGB),解压后文件夹大小为16.8GB
注意: 在执行 collect_indoor3d_data.py应该会出现类似于下面的错误:
D:\pointnet\data\Stanford3dDataset_v1.2_Aligned_Version\Area_5/hallway_6/Annotations
D:\pointnet\data\Stanford3dDataset_v1.2_Aligned_Version\Area_5/hallway_6/Annotations
- 1
- 2
作者提示Area_5/hallway_6中多了一个额外的字符,不符合编码规范,需要手动删除。经查找具体位置为:Stanford3dDataset_v1.2_Aligned_Version\Area_5\hallway_6\Annotations\ceiling_1.txt中的第180389行数字185后。windows下建议使用EmEditor打开文件,会自动跳转到该行,数字185后面有一个类似空格的字符,实际上不是空格,删掉然后重新打一个空格就可以了。linux下直接使用gedit或vim跳转到该行修改即可。保存后再次使用编辑器尝试打开该文件,不提示出现问题说明已经修改完成。
对应修改位置如下:

如果要将数据转换为模型所需的hdf5格式,首先需要在Python中安装h5py,如果是Anaconda环境应该已默认安装,通过import h5py测试检查是否安装,没有安装的话可以使用下面命令进行快速安装:
sudo apt-get install libhdf5-dev # 安装h5py开发库,必要!
sudo pip install h5py
- 1
- 2
接下来准备自己的HDF5数据,下载好数据集后,分别运行该sem_seg/下的两个python脚本来生成hdf5数据文件。
- python collect_indoor3d_data.py用于数据的重组,转换为.npy格式文件,比如Area_1_hallway_1.npy(.npy为Numpy专用的二进制格式)。
- python gen_indoor3d_h5.py 将.npy文件批量转为HDF5文件。
3.训练:
使用准备好的HDF5数据文件(处理好的或自己转换的数据),即可开始模型训练,模型默认使用Vanilla PointNet进行训练,指定区域1用作测试集,作者给出的是区域6作测试集:
python train.py --log_dir log1 --test_area 1
- 1
得到在log1文件夹下关于训练模型和日志model.ckpt文件。
4.测试:
训练结束后,可以进行测试,需要对于测试集数据进行简单处理:
batch_inference.py 对测试集中的房间进行细分。
作者实验中使用6折交叉训练来训练获得6个模型。比如:对于model1,将区域2-6用作训练集,区域1用作测试集;对于模型2,区域1,3-6被用作训练集,区域2被用作测试集以此类推,请注意,论文使用了不同的3折交叉训练。
加入我们想使用model1进行测试,并获得一个obj文件用于可视化,那么测试集为区域1,可以运行如下代码,作者README中给出的是model6作为测试,即以区域6位测试集测试工作和可视化:
python batch_inference.py --model_path log1/model.ckpt --dump_dir log1/dump --output_filelist log1/output_filelist.txt --room_data_filelist meta/area1_data_label.txt --visu
- 1
测试执行完毕后。将会在log1/dump下创建一些.OBJ .TXT文件,可以使用CloudCompare,MeshLab等软件来进行区域1—会议室1的预测结果的可视化。

5.分割效果评价
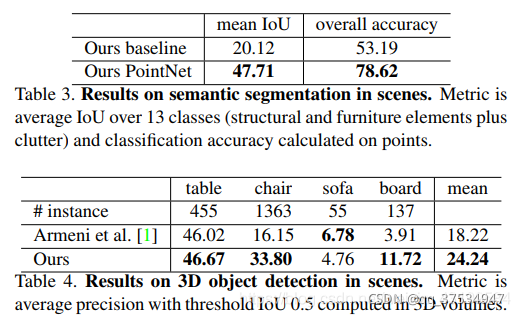
最后是评估整体分割的准确性,作者依次评估了6个模型,并用于eval_iou_accuracy.py产生点的分类准确性和IoU,结果最终除以13,得到一个分割的平均交并比mIOU。
参考论文中作者的结果:
原文链接:https://blog.csdn.net/weixin_43199584/article/details/105378083
6.机器学习算法评估指标——3D语义分割
3D语义分割是在三维点云中对每个点进行分类,属于同一类的点都要被归为一类。 例如如下场景,属于建筑的点都要分成一类,属于植物的点也要分成一类。下面重点介绍3D语义分割算法的评估指标。
-
PA(Point Accuracy)
定义:总体的分类准确度,分类正确的点数和点云总点数的比值
范围:0~100%
用途:这是最简单的度量分割准确性的方式 -
MPA(Mean Point Accuracy)
定义:平均分类准确度,计算每一类分类正确的点数和该类的所有点数的比值然后求平均
范围:0~100% -
MIoU(Mean Intersection over Union)
定义:计算每一类的IoU然后求平均。一类的IoU计算方式如下:1:假设P11表示本属于1类且被预测为1类的点数,X1表示本属于1类的点数, Y1表示被预测为1类的点数, 2:则1类的 IoU = P11 / (X1 + Y1 - P11)- 1
- 2
- 3
范围:0~100%
用途:这是分割任务的标准度量方法,同时考虑了“漏标”和“误标”的情况。MIoU指标由于其代表性和简洁性,成为了评价分割准确性的最常用的指标。 -
FWIoU(Frequency Weighted Intersection over Union)
定义:根据每一类出现的频率对各个类的IoU进行加权求和
范围:0~100%
用途:它是对MIoU的改进,每个类的重要性取决于它们出现的频率。

