
- 1System.InvalidCastException:“无法将类型为“Microsoft.Office.Interop.Excel.ApplicationClass”的 COM 对象强制转换为接口类
- 2HTC vive pro & unity开发者软件/SDK版本注意事项_htc vive unity配置
- 3php毕业设计 基于php+mysql的在线购物商城毕业设计开题报告功能参考_php mysql navicat hbuilder购买系统开题报告
- 4UE蓝图 函数调用(CallFunction)节点和源码
- 5【毕业设计】基于微信小程序体育场地预约系统(源码+LW+部署+讲解)_基于微信小程序体育馆预约系统
- 6mysql 安装问题:由于找不到MSVCP120.dll,无法继续执行代码.重新安装程序可能会解决此问题。_mysql找不到msvcp120
- 7sdkmanager工具安装
- 8redis持久化失败问题(MISCONF Redis is configured to save RDB snapshots, but ......)问题解决
- 9计算机系统:EEPROM详解
- 10虚拟机Ubuntu18.04为Jetson AGX Xavier使用jetpack4.4刷机_agx orin装jetpack4。4
AlexNet详细解读_alexnet中图饱和是什么意思
赞
踩
目前在自学计算机视觉与深度学习方向的论文,今天给大家带来的是很经典的一篇文章 :《ImageNet Classification with Deep Convolutional Neural Networks》。纯粹是自学之后,自己的一点知识总结,如果有什么不对的地方欢迎大家指正。AlexNet的篇文章当中,我们可以主要从五个大方面去讲:ReLU,LPN,Overlapping Pooling,总体架构,减少过度拟合。重点介绍总体结构和减少过度拟合。
1. ReLU Nonlinearity
一般神经元的激活函数会选择sigmoid函数或者tanh函数,然而Alex发现在训练时间的梯度衰减方面,这些非线性饱和函数要比非线性非饱和函数慢很多。在AlexNet中用的非线性非饱和函数是f=max(0,x),即ReLU。实验结果表明,要将深度网络训练至training error rate达到25%的话,ReLU只需5个epochs的迭代,但tanh单元需要35个epochs的迭代,用ReLU比tanh快6倍。
2. 双GPU并行运行
为提高运行速度和提高网络运行规模,作者采用双GPU的设计模式。并且规定GPU只能在特定的层进行通信交流。其实就是每一个GPU负责一半的运算处理。作者的实验数据表示,two-GPU方案会比只用one-GPU跑半个上面大小网络的方案,在准确度上提高了1.7%的top-1和1.2%的top-5。值得注意的是,虽然one-GPU网络规模只有two-GPU的一半,但其实这两个网络其实并非等价的。
3. LRN局部响应归一化
ReLU本来是不需要对输入进行标准化,但本文发现进行局部标准化能提高性能。
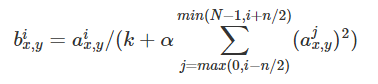
其中a代表在feature map中第i个卷积核(x,y)坐标经过了ReLU激活函数的输出,n表示相邻的几个卷积核。N表示这一层总的卷积核数量。k, n, α和β是hyper-parameters,他们的值是在验证集上实验得到的,其中k = 2,n = 5,α = 0.0001,β = 0.75。
这种归一化操作实现了某种形式的横向抑制,这也是受真实神经元的某种行为启发。
卷积核矩阵的排序是随机任意,并且在训练之前就已经决定好顺序。这种LPN形成了一种横向抑制机制。
4. Overlapping Pooling
池层是相同卷积核领域周围神经元的输出。池层被认为是由空间距离s个像素的池单元网格的组成。也可以理解成以大小为步长对前面卷积层的结果进行分块,对块大小为的卷积映射结果做总结,这时有。然而,Alex说还有的情况,也就是带交叠的Pooling,顾名思义这指Pooling单元在总结提取特征的时候,其输入会受到相邻pooling单元的输入影响,也就是提取出来的结果可能是有重复的(对max pooling而言)。而且,实验表示使用 带交叠的Pooling的效果比的传统要好,在top-1和top-5上分别提高了0.4%和0.3%,在训练阶段有避免过拟合的作用。
5. 总体结构
如果说前面的ReLU、LRN、Overlapping Pooling是铺垫的话,那么它们一定是为这部分服务的。
因为这才是全文的重点!!!理解这里才是把握住这篇的论文的精华!

首先总体概述下:
- AlexNet为8层结构,其中前5层为卷积层,后面3层为全连接层;学习参数有6千万个,神经元有650,000个
- AlexNet在两个GPU上运行;
- AlexNet在第2,4,5层均是前一层自己GPU内连接,第3层是与前面两层全连接,全连接是2个GPU全连接;
- RPN层第1,2个卷积层后;
- Max pooling层在RPN层以及第5个卷积层后。
- ReLU在每个卷积层以及全连接层后。
- 卷积核大小数量:
conv1:96 11*11*3(个数/长/宽/深度)
conv2:256 5*5*48
conv3:384 3*3*256
conv4: 384 3*3*192
conv5: 256 3*3*192
ReLU、双GPU运算:提高训练速度。(应用于所有卷积层和全连接层)
重叠pool池化层:提高精度,不容易产生过度拟合。(应用在第一层,第二层,第五层后面)
局部响应归一化层(LRN):提高精度。(应用在第一层和第二层后面)
Dropout:减少过度拟合。(应用在前两个全连接层)
第1层分析:
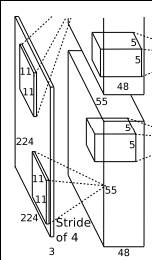
第一层输入数据为原始图像的227*227*3的图像(最开始是224*224*3,为后续处理方便必须进行调整),这个图像被11*11*3(3代表深度,例如RGB的3通道)的卷积核进行卷积运算,卷积核对原始图像的每次卷积都会生成一个新的像素。卷积核的步长为4个像素,朝着横向和纵向这两个方向进行卷积。由此,会生成新的像素;(227-11)/4+1=55个像素(227个像素减去11,正好是54,即生成54个像素,再加上被减去的11也对应生成一个像素),由于第一层有96个卷积核,所以就会形成55*55*96个像素层,系统是采用双GPU处理,因此分为2组数据:55*55*48的像素层数据。
重叠pool池化层:这些像素层还需要经过pool运算(池化运算)的处理,池化运算的尺度由预先设定为3*3,运算的步长为2,则池化后的图像的尺寸为:(55-3)/2+1=27。即经过池化处理过的规模为27*27*96.
局部响应归一化层(LRN):最后经过局部响应归一化处理,归一化运算的尺度为5*5;第一层卷积层结束后形成的图像层的规模为27*27*96.分别由96个卷积核对应生成,这96层数据氛围2组,每组48个像素层,每组在独立的GPU下运算。
第2层分析:
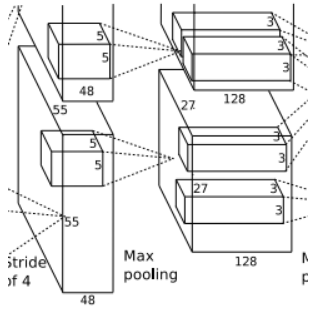
第二层输入数据为第一层输出的27*27*96的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被5*5*48的卷积核进行卷积运算,同理按照第一层的方式进行:(27-5+2*2)/1+1=27个像素,一共有256个卷积核,这样也就有了27*27*128两组像素层。
重叠pool池化层:同样经过池化运算,池化后的图像尺寸为(27-3)/2+1=13,即池化后像素的规模为2组13*13*128的像素层。
局部响应归一化层(LRN):最后经过归一化处理,分别对应2组128个卷积核所运算形成。每组在一个GPU上进行运算。即共256个卷积核,共2个GPU进行运算。
第3层分析
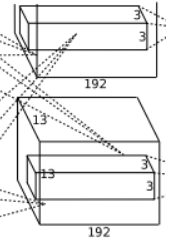
第三层输入数据为第二层输出的两组13*13*128的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*128的卷积核(两组,一共也就有3*3*256)进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有384个卷积核,这样也就有了13*13*192两组像素层。
第4层分析:
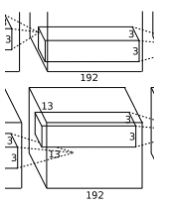
第5层分析:
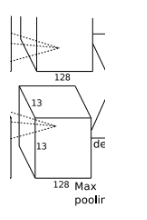
第五层输入数据为第四层输出的两组13*13*192的像素层(为方便后续处理,这对每幅像素层进行像素填充),分为2组像素数据,两组像素数据分别在两个不同的GPU中进行运算。每组像素数据被3*3*192的卷积核进行卷积运算,同理按照第一层的方式进行:(13-3+1*2)/1+1=13个像素,一共有256个卷积核,这样也就有了13*13*128两组像素层。
重叠pool池化层:进过池化运算,池化后像素的尺寸为(13-3)/2+1=6,即池化后像素的规模变成了两组6*6*128的像素层,共6*6*256规模的像素层。
第6层分析:
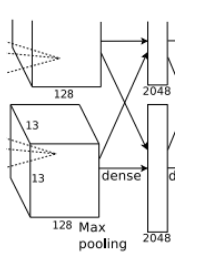
第6层输入数据的尺寸是6*6*256,采用6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算;每个6*6*256尺寸的滤波器对第六层的输入数据进行卷积运算生成一个运算结果,通过一个神经元输出这个运算结果;共有4096个6*6*256尺寸的滤波器对输入数据进行卷积,通过4096个神经元的输出运算结果;然后通过ReLU激活函数以及dropout运算输出4096个本层的输出结果值。
很明显在第6层中,采用的滤波器的尺寸(6*6*256)和待处理的feature map的尺寸(6*6*256)相同,即滤波器中的每个系数只与feature map中的一个像素值相乘;而采用的滤波器的尺寸和待处理的feature map的尺寸不相同,每个滤波器的系数都会与多个feature map中像素相乘。因此第6层被称为全连接层。
第7层分析:
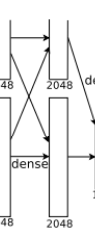
第6层输出的4096个数据与第7层的4096个神经元进行全连接,然后经由ReLU和Dropout进行处理后生成4096个数据。
第8层分析:

第7层输入的4096个数据与第8层的1000个神经元进行全连接,经过训练后输出被训练的数值。
6. 减少过度拟合
6.1 数据增益
增强图片数据集最简单和最常用的方法是在不改变图片核心元素(即不改变图片的分类)的前提下对图片进行一定的变换,比如在垂直和水平方向进行一定的唯一,翻转等。
AlexNet用到的第一种数据增益的方法:是原图片大小为256*256中随机的提取224*224的图片,以及他们水平方向的映像。
第二种数据增益的方法就是在图像中每个像素的R、G、B值上分别加上一个数,用到 方法为PCA。对于图像每个像素,增加以下量 :
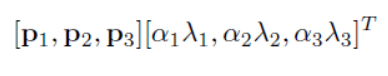
p是主成分,lamda是特征值,alpha是N(0,0.1)高斯分布中采样得到的随机值。此方案名义上得到自然图像的重要特性,也就是说,目标是不随着光照强度和颜色而改变的。此方法降低top-1错误率1%。
6.2 Dropout
结合多个模型的预测值是减少错误的有效方法,但是对于训练时间用好几天的大型神经网络太耗费时间。Dropout是有效的模型集成学习方法,具有0.5的概率讲隐藏神经元设置输出为0。运用了这种机制的神经元不会干扰前向传递也不影响后续操作。因此当有输入的时候,神经网络采样不用的结构,但是这些结构都共享一个权重。这就减少了神经元适应的复杂性。测试时,用0.5的概率随机失活神经元。dropout减少了过拟合,也使收敛迭代次数增加一倍。
7. 学习细节
AlexNet训练采用的是随机梯度下降 (stochastic gradient descent),每批图像大小为128,动力为0.9,权重衰减为0.005,(Alexnet认为权重衰减非常重要,但是没有讲为什么)
对于权重值的更新规则如下:

其中i是迭代指数,v是动力变量,ε是学习率,是目标关于w、对求值的导数在第i批样例上的平均值。我们用一个均值为0、标准差为0.01的高斯分布初始化了每一层的权重。我们用常数1初始化了第二、第四和第五个卷积层以及全连接隐层的神经元偏差。该初始化通过提供带正输入的ReLU来加速学习的初级阶段。我们在其余层用常数0初始化神经元偏差。
对于所有层都使用了相等的学习率,这是在整个训练过程中手动调整的。我们遵循的启发式是,当验证误差率在当前学习率下不再提高时,就将学习率除以10。学习率初始化为0.01,在终止前降低三次。作者训练该网络时大致将这120万张图像的训练集循环了90次,在两个NVIDIA GTX 580 3GB GPU上花了五到六天。
8. 实验结果
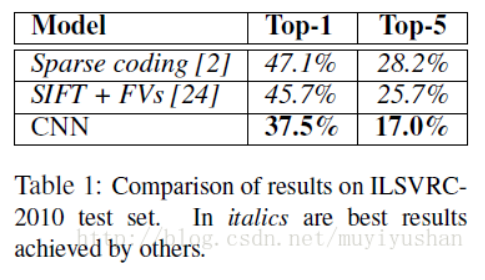
ILSVRC2010比赛冠军方法是Sparse coding,这之后(AlexNet前)报道最好方法是SIFT+FVs。CNN方法横空出世,远超传统方法。
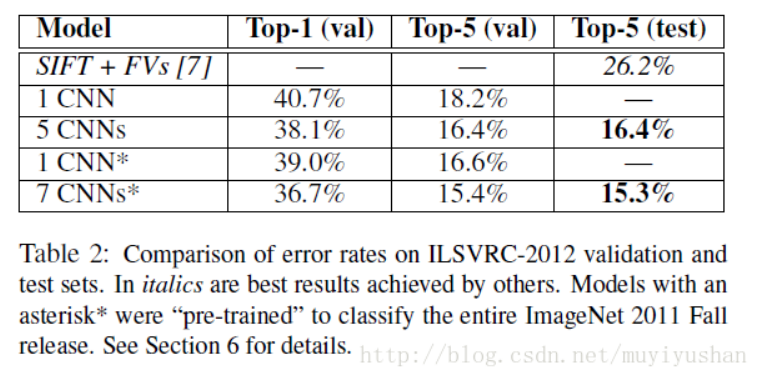
ILSVRC-2012,Alex参加比赛,获得冠军,远超第二名SIFT+FVs。
定量分析:

图3显示了卷积层学到的有频率和方向选择性的卷积核,和颜色斑点(color blob)。GPU 1 (color-agnostic)和GPU 2(color-specific)学习到的卷积核并不一样。不一样的原因是3.5中的受限连接(restricted connectivity)。

图4显示,即使目标偏离中心,也可以被识别出来,比如mite。top-5预测结果是reasonable的,比如leopard的预测的可能结果是其他类型的猫科动物。但是也存在对intended focus的模糊问题,就是网络不知道我们到底想识别图片中的什么物体,比如cherry,分类结果是dalmatian,网络显然关注的是dog。
网络最后4096-d隐藏层产生的是feature activations是另一个重要指标。如果两张图像产生欧氏距离相近的feature activation vectors,那么网络的higher levels就认为他们是相似的。使用此度量,可以实现较好的图像检索。
通过欧氏距离计算两个4096维度效率太低,可以使用自动编码压缩向量成二进制码。这比直接在原始像素上使用自动编码效果更好。因为在raw pixels上使用quto-encoder,没用到标签数据,只是检索有相似边缘模式(similar patterns of edges)的图像,却不管他们语义(semantically)上是否相似。9.探讨
深度很重要,去掉任一层,性能都会降低。
为了简化实验,没有使用非监督预训练。但是当有足够计算能力扩大网络结构,而没增加相应数据时,非监督预训练可能会有所帮助。
虽然通过增大网络结构和增加训练时长可以改善网络,但是我们与达到人类视觉系统的时空推理能力(infero-temporal pathway of the human visual system)还相距甚远。所以,最终希望能将CNN用到视频序列分析中,视频相对静态图像有很多有用的时间结构信息。
AlexNet的论文下载地址:点击打开链接

