
- 1NPM私服搭建(verdaccio)
- 2f1-score_统计学中的分数是什么意思
- 3FileReader上传文件
- 4车载诊断协议——基于Vector诊断工具实现诊断测试_vector 车载
- 5Unity/Animation -- 创建Animation Clip_unity animationclip
- 6SpringBoot实现AOP和IOC的原理_springboot ioc aop
- 7成绩排序_给出班里某门课程的成绩单,请你按成绩从高到低对成绩单排序输出,如果有相同分数则
- 8聚类——标签传播算法以及Python实现_标签传播聚类
- 9java输出少女のトゲ在线观看
- 10ElasticSearch在Windows上的下载与安装_elasticsearch下载
(11-3-02)检测以太坊区块链中的非法账户: 数据分析(1)
赞
踩
11.3.3 数据分析
(1)检查目标列(FLAG)的分布,其中0表示非欺诈交易,1表示欺诈交易。计算并显示了每个类别的数量,以帮助了解数据中欺诈和非欺诈交易的分布情况。具体实现代码如下所示。
dataset['FLAG'].value_counts()执行后会输出:
- 0 7662
- 1 2179
- Name: FLAG, dtype: int64
(2)创建一个饼图,显示了欺诈和非欺诈交易的分布情况。饼图中的百分比表示每个类别的相对比例。具体实现代码如下所示。
- round(100*dataset['FLAG'].value_counts(normalize=True),2).plot(kind='pie',explode=[0.02]*2, figsize=(6, 6), autopct='%1.2f%%')
- plt.title("Fraudulent and Non-Fraudulent Distribution")
- plt.legend(["Non-Fraud", "Fraud"])
- plt.show()
执行后会绘制欺诈和非欺诈交易的分布情况饼形图,如图11-1所示,
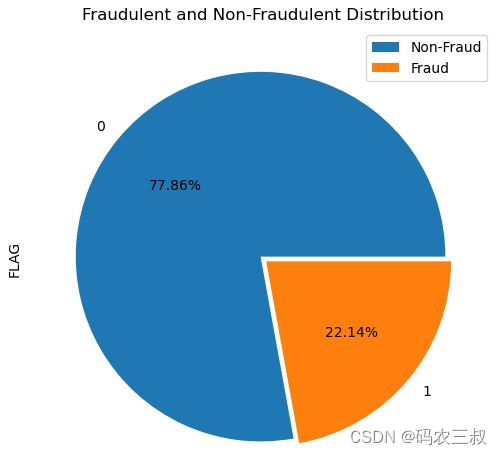
图11-1 时间序列预测结果的图
(3)计算数据集中每列中的非空值(不缺失值)的数量。结果将显示每列中非空值的计数,以便了解哪些列具有缺失数据。具体实现代码如下所示。
- # 检查每列中的非空值数量
- dataset.isnull().sum()
执行后会输出:
- Index 0
- Address 0
- FLAG 0
- Avg min between sent tnx 0
- Avg min between received tnx 0
- Time Diff between first and last (Mins) 0
- Sent tnx 0
- Received Tnx 0
- Number of Created Contracts 0
- #####省略部分输出结果
- ERC20 uniq rec token name 829
- ERC20 most sent token type 841
- ERC20_most_rec_token_type 851
- dtype: int64
(4)实现数据的预处理,首先使用中位数替换数值变量中的缺失值。然后清理分类特征中的0值,将它们更改为null值,因为0在分类特征中通常没有实际意义。最后计算每列中缺失值的百分比,以帮助了解数据集中缺失数据的情况。具体实现代码如下所示。
- # 使用中位数替换数值变量中的缺失值
- dataset.fillna(dataset.median(), inplace=True)
-
- # 清理分类特征 - 将0值更改为null,因为在分类特征中0值没有意义
- dataset[' ERC20_most_rec_token_type'].replace({'0': np.NaN}, inplace=True)
- dataset[' ERC20 most sent token type'].replace({'0': np.NaN}, inplace=True)
-
- # 计算每列中缺失值的百分比
- round((dataset.isnull().sum() / len(dataset.index)) * 100, 2)
执行后会输出:
- Index 0.00
- Address 0.00
- FLAG 0.00
- Avg min between sent tnx 0.00
- Avg min between received tnx 0.00
- Time Diff between first and last (Mins) 0.00
- Sent tnx 0.00
- ####省略部分输出结果
- ERC20 uniq rec token name 0.00
- ERC20 most sent token type 53.25
- ERC20_most_rec_token_type 53.35
- dtype: float64
(5)识别数据集中具有对象类型(通常是文本或字符串)值的列,并将这些列的名称存储在变量 object_columns 中。具体实现代码如下所示。
- # 获取具有对象类型值的列
- object_columns = (dataset.select_dtypes(include=['object'])).columns
- object_columns
执行后会输出:
Index(['Address', ' ERC20 most sent token type', ' ERC20_most_rec_token_type'], dtype='object')(6)计算名为 ' ERC20_most_rec_token_type' 的列中各个值的数量,这对于了解这一列中不同代币类型的分布情况非常有用。具体实现代码如下所示。
- # 计算' ERC20_most_rec_token_type' 列中各个值的数量
- dataset[' ERC20_most_rec_token_type'].value_counts()
执行后会输出:
- OmiseGO 873
- Blockwell say NOTSAFU 779
- DATAcoin 358
- Livepeer Token 207
- EOS 161
- ...
- BCDN 1
- Egretia 1
- UG Coin 1
- Yun Planet 1
- INS Promo1 1
- Name: ERC20_most_rec_token_type, Length: 466, dtype: int64
(7)计算名为 ' ERC20 most sent token type' 的列中各个值的数量,具体实现代码如下所示。
- None 1856
- 1191
- EOS 138
- OmiseGO 137
- Golem 130
- ...
- BlockchainPoland 1
- Covalent Token 1
- Nebula AI Token 1
- Blocktix 1
- eosDAC Community Owned EOS Block Producer ERC20 Tokens 1
- Name: ERC20 most sent token type, Length: 304, dtype: int64
(8)实现数据清理工作并计算相关性矩阵,首先删除具有大量null、0或None值的列,这些列是 'Index'、' ERC20_most_rec_token_type' 和 ' ERC20 most sent token type'。然后,删除没有实际值的列。最后,计算数据集的相关性矩阵,以分析不同列之间的相关性。具体实现代码如下所示。
- # 删除具有许多null、0或None值的列
- dataset.drop(['Index', ' ERC20_most_rec_token_type', ' ERC20 most sent token type'], axis=1, inplace=True)
- # 删除没有值的列
- dataset.drop([' ERC20 avg time between sent tnx', ' ERC20 avg time between rec tnx', ' ERC20 avg time between rec 2 tnx', ' ERC20 avg time between contract tnx', ' ERC20 min val sent contract', ' ERC20 max val sent contract', ' ERC20 avg val sent contract'], axis=1, inplace=True)
- # 计算相关性矩阵
- corr = dataset.corr()
- corr
执行后会输出:
- FLAG Avg min between sent tnx Avg min between received tnx Time Diff between first and last (Mins) Sent tnx Received Tnx Number of Created Contracts Unique Received From Addresses Unique Sent To Addresses min value received ... ERC20 uniq sent addr.1 ERC20 uniq rec contract addr ERC20 min val rec ERC20 max val rec ERC20 avg val rec ERC20 min val sent ERC20 max val sent ERC20 avg val sent ERC20 uniq sent token name ERC20 uniq rec token name
- FLAG 1.000000 -0.029754 -0.118533 -0.269354 -0.078006 -0.079316 -0.013711 -0.031941 -0.045584 -0.021641 ... -0.011148 -0.052473 0.004434 -0.005510 0.003132 0.019023 0.018770 0.018835 -0.026290 -0.052603
- Avg min between sent tnx -0.029754 1.000000 0.060979 0.214722 -0.032289 -0.035735 -0.006186 -0.015912 -0.017688 -0.014886 ... -0.011862 0.047946 0.004998 -0.002260 -0.002829 -0.001511 -0.001841 -0.001792 0.003310 0.049548
- Avg min between received tnx -0.118533 0.060979 1.000000 0.303897 -0.040419 -0.053478 -0.008378 -0.029571 -0.025747 -0.045753 ... -0.013750 -0.011693 -0.007794 -0.003326 -0.005241 -0.003545 -0.003568 -0.003521 -0.016831 -0.011684
- ###########省略部分输出结果
- ERC20 uniq sent token name -0.026290 0.003310 -0.016831 0.269025 0.082239 0.045475 0.006475 0.042108 0.086414 -0.026315 ... -0.005837 0.787943 -0.002288 0.017746 0.013764 -0.000440 0.001276 -0.000332 1.000000 0.789220
- ERC20 uniq rec token name -0.052603 0.049548 -0.011684 0.329237 0.222945 0.205219 0.030527 0.150158 0.238798 -0.000335 ... 0.032573 0.999643 -0.006013 0.028497 0.022273 -0.002144 -0.000625 -0.001906 0.789220 1.000000
(9)提取相关性矩阵的上三角部分,这部分包含了相关性系数的唯一值,而下三角部分包含了对称的冗余信息。具体实现代码如下所示。
- # 计算相关性矩阵的上三角部分
- upper = corr.where(np.triu(np.ones(corr.shape), k=1).astype(np.bool))
- upper.head()
上述提取操作通常用于减少冗余信息并更清晰地可视化相关性,执行后会输出:
- FLAG Avg min between sent tnx Avg min between received tnx Time Diff between first and last (Mins) Sent tnx Received Tnx Number of Created Contracts Unique Received From Addresses Unique Sent To Addresses min value received ... ERC20 uniq sent addr.1 ERC20 uniq rec contract addr ERC20 min val rec ERC20 max val rec ERC20 avg val rec ERC20 min val sent ERC20 max val sent ERC20 avg val sent ERC20 uniq sent token name ERC20 uniq rec token name
- FLAG NaN -0.029754 -0.118533 -0.269354 -0.078006 -0.079316 -0.013711 -0.031941 -0.045584 -0.021641 ... -0.011148 -0.052473 0.004434 -0.005510 0.003132 0.019023 0.018770 0.018835 -0.026290 -0.052603
- Avg min between sent tnx NaN NaN 0.060979 0.214722 -0.032289 -0.035735 -0.006186 -0.015912 -0.017688 -0.014886 ... -0.011862 0.047946 0.004998 -0.002260 -0.002829 -0.001511 -0.001841 -0.001792 0.003310 0.049548
- Avg min between received tnx NaN NaN NaN 0.303897 -0.040419 -0.053478 -0.008378 -0.029571 -0.025747 -0.045753 ... -0.013750 -0.011693 -0.007794 -0.003326 -0.005241 -0.003545 -0.003568 -0.003521 -0.016831 -0.011684
- Time Diff between first and last (Mins) NaN NaN NaN NaN 0.154480 0.148376 -0.003881 0.037043 0.071140 -0.084996 ... 0.022216 0.324088 -0.008921 0.046278 0.049160 -0.006174 -0.005606 -0.006148 0.269025 0.329237
- Sent tnx NaN NaN NaN NaN NaN 0.198455 0.320603 0.130064 0.670014 0.024015 ... -0.007671 0.221971 -0.003480 0.004445 0.009104 -0.001407 -0.000870 -0.001271 0.082239 0.222945
(10)绘制多个散点图,用不同颜色的点表示不同类别(欺诈和非欺诈),以比较不同属性之间的关系。每个散点图比较了数据集中的两个属性,并根据目标标志列 'FLAG' 进行着色,以帮助可视化数据的分布和关联性。具体实现代码如下所示。
- # 创建散点图,比较不同属性之间的关系
- plt.subplots(figsize=(8, 6))
- sns.set(style='darkgrid')
- sns.scatterplot(data=dataset, x='Unique Received From Addresses', y='Received Tnx', hue='FLAG')
- plt.show()
-
- plt.subplots(figsize=(8, 6))
- sns.set(style='whitegrid')
- sns.scatterplot(data=dataset, x='Unique Sent To Addresses', y='Sent tnx', hue='FLAG')
- plt.show()
-
- plt.subplots(figsize=(8, 6))
- sns.scatterplot(data=dataset, x=' ERC20 uniq sent addr', y=' Total ERC20 tnxs', hue='FLAG')
- plt.show()
-
- plt.subplots(figsize=(8, 6))
- sns.scatterplot(data=dataset, x='Unique Received From Addresses', y='Received Tnx', hue='FLAG')
- plt.show()
-
- plt.subplots(figsize=(8, 6))
- sns.scatterplot(data=dataset, x='Sent tnx', y='Unique Sent To Addresses', hue='FLAG')
- plt.show()
-
- plt.subplots(figsize=(8, 6))
- sns.scatterplot(data=dataset, x=' ERC20 uniq rec addr', y=' Total ERC20 tnxs', hue='FLAG')
- plt.show()
-
- plt.subplots(figsize=(8, 6))
- sns.scatterplot(data=dataset, x='total transactions (including tnx to create contract', y='Received Tnx', hue='FLAG')
- plt.show()
上述代码绘制了如下所示的7个散点图:
- 第一个图:比较 'Unique Received From Addresses' 和 'Received Tnx' 的关系。
- 第二个图:比较 'Unique Sent To Addresses' 和 'Sent tnx' 的关系。
- 第三个图:比较 ' ERC20 uniq sent addr' 和 ' Total ERC20 tnxs' 的关系。
- 第四个图:再次比较 'Unique Received From Addresses' 和 'Received Tnx' 的关系(与第一个图相同)。
- 第五个图:比较 'Sent tnx' 和 'Unique Sent To Addresses' 的关系。
- 第六个图:比较 ' ERC20 uniq rec addr' 和 ' Total ERC20 tnxs' 的关系。
- 第七个图:比较 'total transactions (including tnx to create contract' 和 'Received Tnx' 的关系。
这7个图用不同颜色的点表示不同类别(欺诈和非欺诈),以帮助可视化数据之间的关联性,例如第一个图“”Unique Received From Addresses和 Received Tnx关系”的散点效果如图11-2所示。
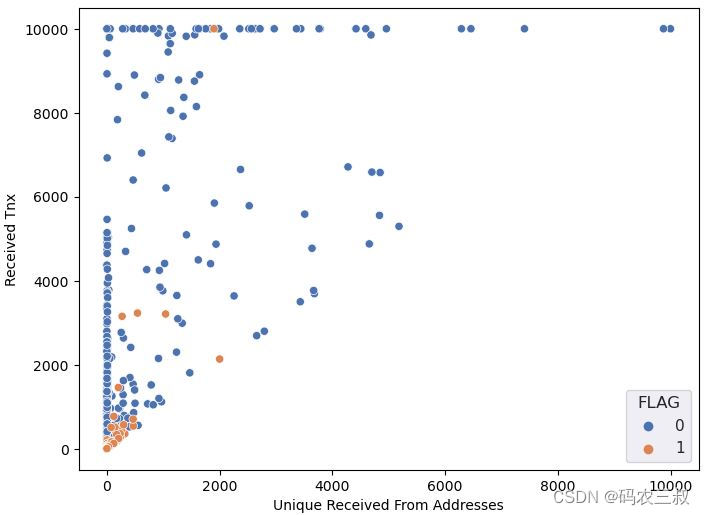
图11-2 Unique Received From Addresses和 Received Tnx的关系图


