
热门标签
热门文章
- 1Unity2D教程:单例模式、SceneManager.LoadSceneAsync场景切换、Loading界面进度条
- 2mysql undo表空间_MySQL UNDO表空间独立和截断
- 3Chatgpt这么智能,以后会不会取代掉人类?_chatgpt是否会代替人类的大脑
- 4计算机设计大赛 深度学习人体语义分割在弹幕防遮挡上的实现 - python
- 5windows7装python哪个版本好,win7安装哪个版本的python_pycharm win7适配版本
- 6UE4蓝图基础入门(一)变量与蓝图_ue setmenbersin
- 7ChatGPT-4和ChatGPT-3.5知识库截止日期竟然一样?_gpt4数据库截止日期
- 8Unity——InputSystem入门及部分问题讲解_unity inputsystem
- 9python库turtle的双画笔并发绘制兔兔 表白神器_pythonturtle画小白兔
- 10Rabbitmq学习之路3-cluster_rabbitmqctl join_cluster --ram
当前位置: article > 正文
点云分割(point cloud segmentation)任务笔记
作者:我家自动化 | 2024-02-19 17:07:51
赞
踩
点云分割(point cloud segmentation)任务笔记
1.PointNet++分割任务
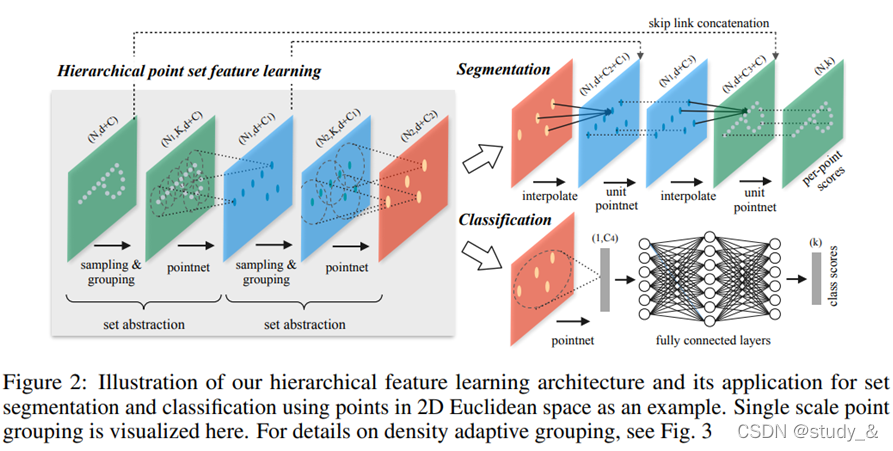
分割任务
分为Set Abstraction layers特征提取 , Feature Propagation layers特征传递 , FC layers全链接 三个模块。一个类似unet的结构,整个分割网络的代码如下:
# Set Abstraction layers
l1_xyz, l1_points, l1_indices = pointnet_sa_module(l0_xyz, l0_points, npoint=512, radius=0.2, nsample=64, mlp=[64,64,128], mlp2=None, group_all=False, is_training=is_training, bn_decay=bn_decay, scope='layer1')
l2_xyz, l2_points, l2_indices = pointnet_sa_module(l1_xyz, l1_points, npoint=128, radius=0.4, nsample=64, mlp=[128,128,256], mlp2=None, group_all=False, is_training=is_training, bn_decay=bn_decay, scope='layer2')
l3_xyz, l3_points, l3_indices = pointnet_sa_module(l2_xyz, l2_points, npoint=None, radius=None, nsample=None, mlp=[256,512,1024], mlp2=None, group_all=True, is_training=is_training, bn_decay=bn_decay, scope='layer3')
# Feature Propagation layers
l2_points = pointnet_fp_module(l2_xyz, l3_xyz, l2_points, l3_points, [256,256], is_training, bn_decay, scope='fa_layer1')
l1_points = pointnet_fp_module(l1_xyz, l2_xyz, l1_points, l2_points, [256,128], is_training, bn_decay, scope='fa_layer2')
l0_points = pointnet_fp_module(l0_xyz, l1_xyz, tf.concat([l0_xyz,l0_points],axis=-1), l1_points, [128,128,128], is_training, bn_decay, scope='fa_layer3')
# FC layers
net = tf_util.conv1d(l0_points, 128, 1, padding='VALID', bn=True, is_training=is_training, scope='fc1', bn_decay=bn_decay)
end_points['feats'] = net
net = tf_util.dropout(net, keep_prob=0.5, is_training=is_training, scope='dp1')
net = tf_util.conv1d(net, 50, 1, padding='VALID', activation_fn=None, scope='fc2')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- SA module 特征提取模块:下采样。输入是(N,D)表示N个D维特征的points,输出是(N’,D’)表示N’个下采样之后的点,每个点采用最远点采样寻找N’个中心点,通过pointnet计算得到N’维度的特征。前面的分类网络说过不再赘述。
- FP module 特征传递模块:用来上采样。
采用反距离加权插值(把距离的倒数作为weight)。这种插值输入(N, D),输出(N’, D),保证输入的特征维度不变。
白色代表输入,绿色代表输出。
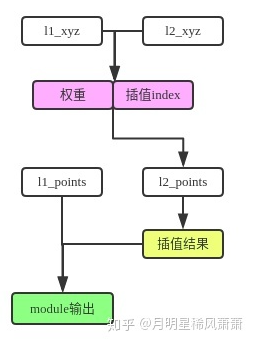
代码如下:
def pointnet_fp_module(xyz1, xyz2, points1, points2, mlp, is_training, bn_decay, scope, bn=True): ''' PointNet Feature Propogation (FP) Module Input: xyz1: (batch_size, ndataset1, 3) TF tensor xyz2: (batch_size, ndataset2, 3) TF tensor, sparser than xyz1 points1: (batch_size, ndataset1, nchannel1) TF tensor points2: (batch_size, ndataset2, nchannel2) TF tensor mlp: list of int32 -- output size for MLP on each point Return: new_points: (batch_size, ndataset1, mlp[-1]) TF tensor ''' with tf.variable_scope(scope) as sc: dist, idx = three_nn(xyz1, xyz2) dist = tf.maximum(dist, 1e-10) norm = tf.reduce_sum((1.0/dist),axis=2,keep_dims=True) norm = tf.tile(norm,[1,1,3]) weight = (1.0/dist) / norm #weight is the inverse of distance # interpolate interpolated_points = three_interpolate(points2, idx, weight) if points1 is not None: new_points1 = tf.concat(axis=2, values=[interpolated_points, points1]) # B,ndataset1,nchannel1+nchannel2 else: new_points1 = interpolated_points new_points1 = tf.expand_dims(new_points1, 2) for i, num_out_channel in enumerate(mlp): new_points1 = tf_util.conv2d(new_points1, num_out_channel, [1,1], padding='VALID', stride=[1,1], bn=bn, is_training=is_training, scope='conv_%d'%(i), bn_decay=bn_decay) new_points1 = tf.squeeze(new_points1, [2]) # B,ndataset1,mlp[-1] return new_points1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2.PointMLP segmentation关键代码段
segmentation部分示意图
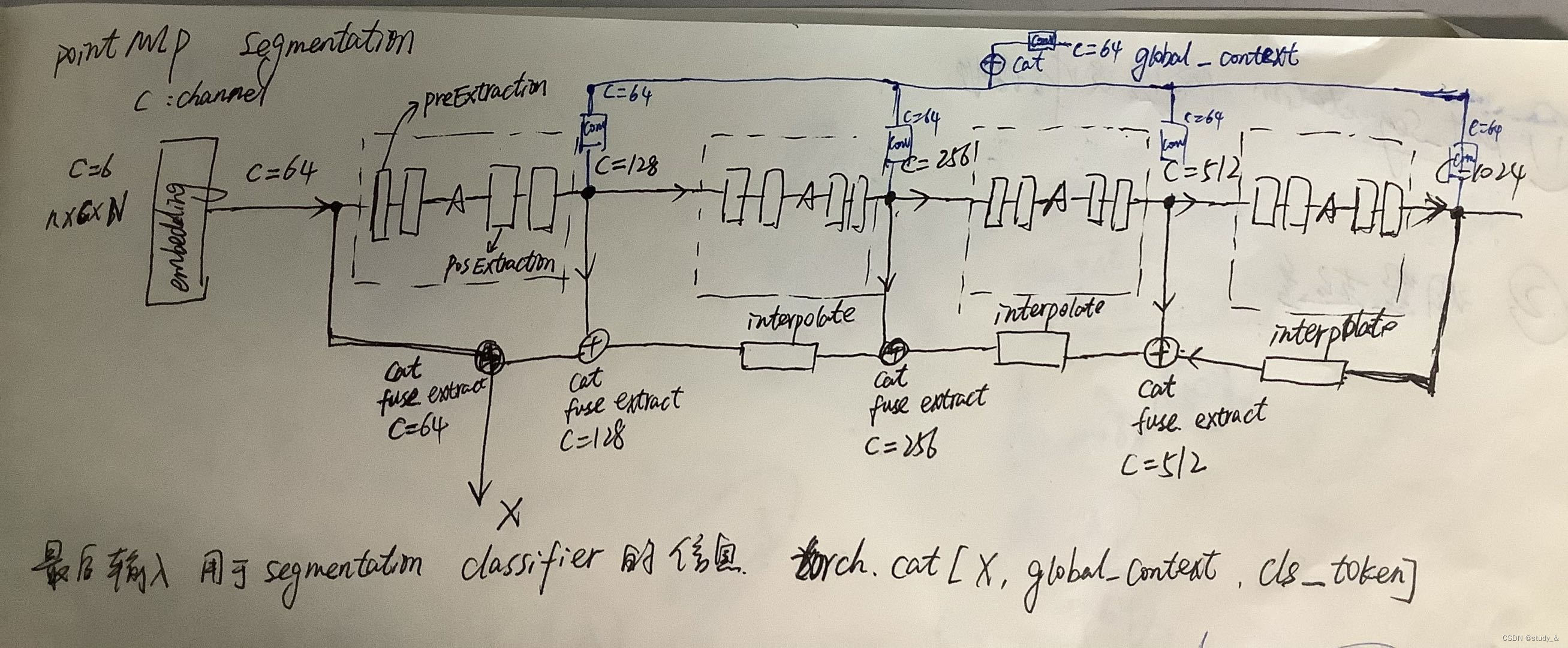
class PointNetFeaturePropagation(nn.Module): def __init__(self, in_channel, out_channel, blocks=1, groups=1, res_expansion=1.0, bias=True, activation='relu'): super(PointNetFeaturePropagation, self).__init__() self.fuse = ConvBNReLU1D(in_channel, out_channel, 1, bias=bias) self.extraction = PosExtraction(out_channel, blocks, groups=groups, res_expansion=res_expansion, bias=bias, activation=activation) def forward(self, xyz1, xyz2, points1, points2): """ Input: xyz1: input points position data, [B, N, 3] xyz2: sampled input points position data, [B, S, 3] points1: input points data, [B, D', N] points2: input points data, [B, D'', S] Return: new_points: upsampled points data, [B, D''', N] """ # xyz1 = xyz1.permute(0, 2, 1) # xyz2 = xyz2.permute(0, 2, 1) points2 = points2.permute(0, 2, 1) B, N, C = xyz1.shape _, S, _ = xyz2.shape if S == 1: interpolated_points = points2.repeat(1, N, 1) else: dists = square_distance(xyz1, xyz2) dists, idx = dists.sort(dim=-1) dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3] dist_recip = 1.0 / (dists + 1e-8) norm = torch.sum(dist_recip, dim=2, keepdim=True) weight = dist_recip / norm interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2) if points1 is not None: points1 = points1.permute(0, 2, 1) new_points = torch.cat([points1, interpolated_points], dim=-1) else: new_points = interpolated_points new_points = new_points.permute(0, 2, 1) new_points = self.fuse(new_points) new_points = self.extraction(new_points) return new_points class PointMLP(nn.Module): def __init__(self, num_classes=50,points=2048, embed_dim=64, groups=1, res_expansion=1.0, activation="relu", bias=True, use_xyz=True, normalize="anchor", dim_expansion=[2, 2, 2, 2], pre_blocks=[2, 2, 2, 2], pos_blocks=[2, 2, 2, 2], k_neighbors=[32, 32, 32, 32], reducers=[4, 4, 4, 4], de_dims=[512, 256, 128, 128], de_blocks=[2,2,2,2], gmp_dim=64,cls_dim=64, **kwargs): super(PointMLP, self).__init__() self.stages = len(pre_blocks) self.class_num = num_classes self.points = points #points=2048 self.embedding = ConvBNReLU1D(6, embed_dim, bias=bias, activation=activation) assert len(pre_blocks) == len(k_neighbors) == len(reducers) == len(pos_blocks) == len(dim_expansion), \ "Please check stage number consistent for pre_blocks, pos_blocks k_neighbors, reducers." self.local_grouper_list = nn.ModuleList() self.pre_blocks_list = nn.ModuleList() self.pos_blocks_list = nn.ModuleList() last_channel = embed_dim ##embed_dim=64 anchor_points = self.points #points=2048 en_dims = [last_channel] ####相比cls任务多出来的变量 en_dims=64 ### Building Encoder ##### for i in range(len(pre_blocks)): # len(pre_blocks)=4 out_channel = last_channel * dim_expansion[i] #每次输出维度都以2倍扩大 dim_expansion=[2, 2, 2, 2] pre_block_num = pre_blocks[i] pos_block_num = pos_blocks[i] kneighbor = k_neighbors[i] #k_neighbors=[32, 32, 32, 32] reduce = reducers[i] #reducers=[4, 4, 4, 4] anchor_points[2048 1024 512 256] anchor_points = anchor_points // reduce # append local_grouper_list local_grouper = LocalGrouper(last_channel, anchor_points, kneighbor, use_xyz, normalize) # [b,g,k,d] last_channel [64 128 256 512] 不是实际channel 作用不大 self.local_grouper_list.append(local_grouper) # append pre_block_list pre_block_module = PreExtraction(last_channel, out_channel, pre_block_num, groups=groups, res_expansion=res_expansion, bias=bias, activation=activation, use_xyz=use_xyz) self.pre_blocks_list.append(pre_block_module) # append pos_block_list pos_block_module = PosExtraction(out_channel, pos_block_num, groups=groups, res_expansion=res_expansion, bias=bias, activation=activation) self.pos_blocks_list.append(pos_block_module) last_channel = out_channel en_dims.append(last_channel) ### [embed_dim,128,256,512,1024] embed=64 seg和cls不一样的行,从此行开始,把每个输出维度都存了起来(输出维度都以两倍增大) ### Building Decoder ##### self.decode_list = nn.ModuleList() en_dims.reverse() # en_dims=[1024,512,256,128,64] de_dims.insert(0,en_dims[0]) # de_dims=[1024, 512, 256, 128, 128] assert len(en_dims) ==len(de_dims) == len(de_blocks)+1 for i in range(len(en_dims)-1): #len(en_dims)-1 = 4 4次循环 self.decode_list.append( PointNetFeaturePropagation(de_dims[i]+en_dims[i+1], de_dims[i+1], blocks=de_blocks[i], groups=groups, res_expansion=res_expansion, bias=bias, activation=activation) ) #第一次:input channel:1024+512 output channel:512 #第二次:input channel:512+256 output channel:256 #第三次:input channel:256+128 output channel:128 #第四次:input channel:128+62 output channel:128 self.act = get_activation(activation) # class label mapping self.cls_map = nn.Sequential( #类别有16类,所以初始通道数16 cls_dim=64 ConvBNReLU1D(16, cls_dim, bias=bias, activation=activation), ConvBNReLU1D(cls_dim, cls_dim, bias=bias, activation=activation) ) # global max pooling mapping self.gmp_map_list = nn.ModuleList() for en_dim in en_dims:# en_dims=[1024,512,256,128,64] gmp_dim=64 self.gmp_map_list.append(ConvBNReLU1D(en_dim, gmp_dim, bias=bias, activation=activation)) self.gmp_map_end = ConvBNReLU1D(gmp_dim*len(en_dims), gmp_dim, bias=bias, activation=activation) # classifier self.classifier = nn.Sequential( #gmp_dim=64 cls_dim=64 de_dims=[1024, 512, 256, 128, 128] nn.Conv1d(gmp_dim+cls_dim+de_dims[-1], 128, 1, bias=bias), # 输入64+64+128 输出128 nn.BatchNorm1d(128), nn.Dropout(), nn.Conv1d(128, num_classes, 1, bias=bias) ) self.en_dims = en_dims def forward(self, x, norm_plt, cls_label): #norm_plt应该指norm xyz = x.permute(0, 2, 1) x = torch.cat([x,norm_plt],dim=1) #xyz和norm的结合 通道数6 x = self.embedding(x) # B,D,N #通道数6 ->embed_dim=64 xyz_list = [xyz] # [B, N, 3] x_list = [x] # [B, D, N] # here is the encoder # self.stages=4 pre_block_module:[128 256 512 1024] # local_grouper_list output channel:[64 128 256 512] anchor_points[2048 1024 512 256] # 第一次 x input channel:64 output channel:128 # 第二次 x input channel:128 output channel:256 # 第三次 x input channel:256 output channel:512 # 第四次 x input channel:512 output channel:1024 for i in range(self.stages): # Give xyz[b, p, 3] and fea[b, p, d], return new_xyz[b, g, 3] and new_fea[b, g, k, d] xyz, x = self.local_grouper_list[i](xyz, x.permute(0, 2, 1)) # [b,g,3] [b,g,k,d] x = self.pre_blocks_list[i](x) # [b,d,g] x = self.pos_blocks_list[i](x) # [b,d,g] xyz_list.append(xyz) # 每次采样后的xyz都存在xyz_list x_list.append(x) #经过pre和pos处理的数据x 每个stage的x都存在x_list [128 256 512 1024] # here is the decoder xyz_list.reverse() x_list.reverse() #x_list [1024 512 256 128] x = x_list[0] for i in range(len(self.decode_list)): x = self.decode_list[i](xyz_list[i+1], xyz_list[i], x_list[i+1],x) # here is the global context gmp_list = [] for i in range(len(x_list)): gmp_list.append(F.adaptive_max_pool1d(self.gmp_map_list[i](x_list[i]), 1)) global_context = self.gmp_map_end(torch.cat(gmp_list, dim=1)) # [b, gmp_dim, 1] #here is the cls_token cls_token = self.cls_map(cls_label.unsqueeze(dim=-1)) # [b, cls_dim, 1] x = torch.cat([x, global_context.repeat([1, 1, x.shape[-1]]), cls_token.repeat([1, 1, x.shape[-1]])], dim=1) x = self.classifier(x) x = F.log_softmax(x, dim=1) x = x.permute(0, 2, 1) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
2.PAconv segmentation任务代码
class PAConv(nn.Module): def __init__(self, args, num_part): super(PAConv, self).__init__() # baseline args: self.args = args self.num_part = num_part # PAConv args: self.k = args.get('k_neighbors', 30) self.calc_scores = args.get('calc_scores', 'softmax') self.hidden = args.get('hidden', [[16], [16], [16], [16]]) # the hidden layers of ScoreNet self.m2, self.m3, self.m4, self.m5 = args.get('num_matrices', [8, 8, 8, 8]) self.scorenet2 = ScoreNet(10, self.m2, hidden_unit=self.hidden[0]) self.scorenet3 = ScoreNet(10, self.m3, hidden_unit=self.hidden[1]) self.scorenet4 = ScoreNet(10, self.m4, hidden_unit=self.hidden[2]) self.scorenet5 = ScoreNet(10, self.m5, hidden_unit=self.hidden[3]) i2 = 64 # channel dim of input_2nd o2 = i3 = 64 # channel dim of output_2st and input_3rd o3 = i4 = 64 # channel dim of output_3rd and input_4th o4 = i5 = 64 # channel dim of output_4th and input_5th o5 = 64 # channel dim of output_5th tensor2 = nn.init.kaiming_normal_(torch.empty(self.m2, i2 * 2, o2), nonlinearity='relu') \ .permute(1, 0, 2).contiguous().view(i2 * 2, self.m2 * o2) tensor3 = nn.init.kaiming_normal_(torch.empty(self.m3, i3 * 2, o3), nonlinearity='relu') \ .permute(1, 0, 2).contiguous().view(i3 * 2, self.m3 * o3) tensor4 = nn.init.kaiming_normal_(torch.empty(self.m4, i4 * 2, o4), nonlinearity='relu') \ .permute(1, 0, 2).contiguous().view(i4 * 2, self.m4 * o4) tensor5 = nn.init.kaiming_normal_(torch.empty(self.m5, i5 * 2, o5), nonlinearity='relu') \ .permute(1, 0, 2).contiguous().view(i4 * 2, self.m5 * o5) self.matrice2 = nn.Parameter(tensor2, requires_grad=True) self.matrice3 = nn.Parameter(tensor3, requires_grad=True) self.matrice4 = nn.Parameter(tensor4, requires_grad=True) self.matrice5 = nn.Parameter(tensor5, requires_grad=True) self.bn2 = nn.BatchNorm1d(64, momentum=0.1) self.bn3 = nn.BatchNorm1d(64, momentum=0.1) self.bn4 = nn.BatchNorm1d(64, momentum=0.1) self.bn5 = nn.BatchNorm1d(64, momentum=0.1) self.bnt = nn.BatchNorm1d(1024, momentum=0.1) self.bnc = nn.BatchNorm1d(64, momentum=0.1) self.bn6 = nn.BatchNorm1d(256, momentum=0.1) self.bn7 = nn.BatchNorm1d(256, momentum=0.1) self.bn8 = nn.BatchNorm1d(128, momentum=0.1) self.conv1 = nn.Sequential(nn.Conv2d(6, 64, kernel_size=1, bias=True), nn.BatchNorm2d(64, momentum=0.1)) self.convt = nn.Sequential(nn.Conv1d(64*5, 1024, kernel_size=1, bias=False), self.bnt) self.convc = nn.Sequential(nn.Conv1d(16, 64, kernel_size=1, bias=False), self.bnc) self.conv6 = nn.Sequential(nn.Conv1d(1088+64*5, 256, kernel_size=1, bias=False), self.bn6) self.dp1 = nn.Dropout(p=args.get('dropout', 0.4)) self.conv7 = nn.Sequential(nn.Conv1d(256, 256, kernel_size=1, bias=False), self.bn7) self.dp2 = nn.Dropout(p=args.get('dropout', 0.4)) self.conv8 = nn.Sequential(nn.Conv1d(256, 128, kernel_size=1, bias=False), self.bn8) self.conv9 = nn.Conv1d(128, num_part, kernel_size=1, bias=True) def forward(self, x, norm_plt, cls_label, gt=None): B, C, N = x.size() idx, _ = knn(x, k=self.k) # different with DGCNN, the knn search is only in 3D space xyz = get_scorenet_input(x, k=self.k, idx=idx) # ScoreNet input ################# # use MLP at the 1st layer, same with DGCNN x = get_graph_feature(x, k=self.k, idx=idx) x = x.permute(0, 3, 1, 2) # b,2cin,n,k x = F.relu(self.conv1(x)) x1 = x.max(dim=-1, keepdim=False)[0] ################# # replace the last 4 DGCNN-EdgeConv with PAConv: """CUDA implementation of PAConv: (presented in the supplementary material of the paper)""" """feature transformation:""" x2, center2 = feat_trans_dgcnn(point_input=x1, kernel=self.matrice2, m=self.m2) score2 = self.scorenet2(xyz, calc_scores=self.calc_scores, bias=0) """assemble with scores:""" x = assemble_dgcnn(score=score2, point_input=x2, center_input=center2, knn_idx=idx, aggregate='sum') x2 = F.relu(self.bn2(x)) x3, center3 = feat_trans_dgcnn(point_input=x2, kernel=self.matrice3, m=self.m3) score3 = self.scorenet3(xyz, calc_scores=self.calc_scores, bias=0) x = assemble_dgcnn(score=score3, point_input=x3, center_input=center3, knn_idx=idx, aggregate='sum') x3 = F.relu(self.bn3(x)) x4, center4 = feat_trans_dgcnn(point_input=x3, kernel=self.matrice4, m=self.m4) score4 = self.scorenet4(xyz, calc_scores=self.calc_scores, bias=0) x = assemble_dgcnn(score=score4, point_input=x4, center_input=center4, knn_idx=idx, aggregate='sum') x4 = F.relu(self.bn4(x)) x5, center5 = feat_trans_dgcnn(point_input=x4, kernel=self.matrice5, m=self.m5) score5 = self.scorenet5(xyz, calc_scores=self.calc_scores, bias=0) x = assemble_dgcnn(score=score5, point_input=x5, center_input=center5, knn_idx=idx, aggregate='sum') x5 = F.relu(self.bn5(x)) ############### xx = torch.cat((x1, x2, x3, x4, x5), dim=1) xc = F.relu(self.convt(xx)) #input channel:64*5 output channel: 1024 xc = F.adaptive_max_pool1d(xc, 1).view(B, -1) cls_label = cls_label.view(B, 16, 1) cls_label = F.relu(self.convc(cls_label)) #input channel:16 output channel:64 cls = torch.cat((xc.view(B, 1024, 1), cls_label), dim=1) #cat后 output channel:1088 cls = cls.repeat(1, 1, N) # B,1088,N x = torch.cat((xx, cls), dim=1) # 1088+64*3 x = F.relu(self.conv6(x)) x = self.dp1(x) x = F.relu(self.conv7(x)) x = self.dp2(x) x = F.relu(self.conv8(x)) x = self.conv9(x) x = F.log_softmax(x, dim=1) x = x.permute(0, 2, 1) # b,n,50 if gt is not None: return x, F.nll_loss(x.contiguous().view(-1, self.num_part), gt.view(-1, 1)[:, 0]) else: return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
参考:
【1】论文笔记:PointNet++论文代码讨论
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/115906
推荐阅读
相关标签

