
- 1iOS ANCS学习_pcba关闭ios app与ancs
- 2架构_ifar构架
- 3base64 <==> Buffer
- 4Beautiful Soup4库的使用_beautiful soup find class
- 5Python数据分析入门与实践_python数据分析从入门到实践
- 6Python OCR库比较:pyocr、pytesseract和python-tesseract_python ocr库哪个好
- 7pyqt5 qtchart 画出饼图_pyqt饼状图
- 8Jupyter在美团民宿的应用实践
- 9[Python从零到壹] 十四.机器学习之分类算法五万字总结全网首发(决策树、KNN、SVM、分类对比实验)_机器学习—分类算法的对比实验
- 10navicat连接postgresql报错 column “datlastsysoid“ does not exist_navicat error:column "datlastsoid" does not exist
Elasticsearch集群部署详解_部署elasticsearch的成功标志
赞
踩
#1、题记
之前应用都是Elasticsearch单节点,随着业务的拓展、数据量的增多,部署分布式Elasticsearch刻不容缓。
本文以Elaticsearch2.3.4版本为基础,讲解Elasticsearch三个节点的分布式部署、核心配置的含义以及分布式部署遇到的坑。
#2、三节点 Elasticsearch 分布式部署。
##步骤1:配置好主节点Master信息。
# ======================== Elasticsearch Configuration ========================= 13 # ---------------------------------- Cluster ----------------------------------- 14 # 15 # Use a descriptive name for your cluster: 16 # 簇名称,分布式部署,确保该名称唯一。 17 cluster.name: my-application 18 # 19 # ------------------------------------ Node ------------------------------------ 20 # 21 # Use a descriptive name for the node: 22 # 节点名称 23 node.name: laoyng 24 node.master: true 25 node.data: true 26 # 27 # Add custom attributes to the node: 28 # 29 # node.rack: r1 30 # 31 # ----------------------------------- Paths ------------------------------------ 32 # 数据存储 33 # Path to directory where to store the data (separate multiple locations by comma): 34 # 35 path.data: /data/elasticsearch/data 36 path.logs: /data/logs/elasticsearch 37 path.plugins: /data/elasticsearch/plugins 38 path.scripts: /data/elasticsearch/scripts 39 # 40 # Path to log files: 41 # 42 # path.logs: /path/to/logs 43 # 44 # ----------------------------------- Memory ----------------------------------- 45 # 46 # Lock the memory on startup: 47 # 48 bootstrap.mlockall: true 49 # 50 # Make sure that the `ES_HEAP_SIZE` environment variable is set to about half the memory 51 # available on the system and that the owner of the process is allowed to use this limit. 52 # 53 # Elasticsearch performs poorly when the system is swapping the memory. 54 # 55 # ---------------------------------- Network ----------------------------------- 56 # 57 # Set the bind address to a specific IP (IPv4 or IPv6): 58 # IP地址 59 network.host: 110.10.11.130 60 # 61 # Set a custom port for HTTP: 62 # 端口 63 http.port: 9200 68 # --------------------------------- Discovery ---------------------------------- 69 # 70 # Pass an initial list of hosts to perform discovery when new node is started: 71 # The default list of hosts is ["127.0.0.1", "[::1]"] 76 discovery.zen.ping.unicast.hosts: [" 110.10.11.130 :9300", "10.118.110.112:9300", "110.0.11.143:9300"] 77 # Prevent the "split brain" by configuring the majority of nodes (total number of nodes / 2 + 1): 78 # 79 # discovery.zen.minimum_master_nodes: 3 80 # 81 discovery.zen.minimum_master_nodes: 2 82 # For more information, see the documentation at: 85 # ---------------------------------- Gateway ----------------------------------- 86 # 87 # Block initial recovery after a full cluster restart until N nodes are started: 88 # 89 # gateway.recover_after_nodes: 3 90 gateway.recover_after_nodes: 3 91 gateway.recover_after_time: 5m 92 gateway.expected_nodes: 1 93 # 97 # ---------------------------------- Various ----------------------------------- 98 # 99 # Disable starting multiple nodes on a single system: 100 # 101 # node.max_local_storage_nodes: 1 102 # 103 # Require explicit names when deleting indices: 104 # 105 # action.destructive_requires_name: true 106 #index.analysis.analyzer.ik.type : “ik” 107 script.engine.groovy.inline.search: on 108 script.engine.groovy.inline.aggs: on 109 indices.recovery.max_bytes_per_sec: 100mb 110 indices.recovery.concurrent_streams: 10

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
##步骤2:拷贝到节点2 cient节点;修改节点名称信息。
只列举不一样的配置:
node.name: laoyng02
node.master: true
node.data: false
network.host: 10.118.110.112
- 1
- 2
- 3
- 4
##步骤3:拷贝到节点3 data节点;修改节点名称
只列举不一样的配置:
node.name: laoyng03
node.master: false
node.data: true
network.host: 110.0.11.143
- 1
- 2
- 3
- 4
##步骤4:分别运行Master,client,data节点(顺序无关)
./elasticsearch -d
- 1
##部署成功标志
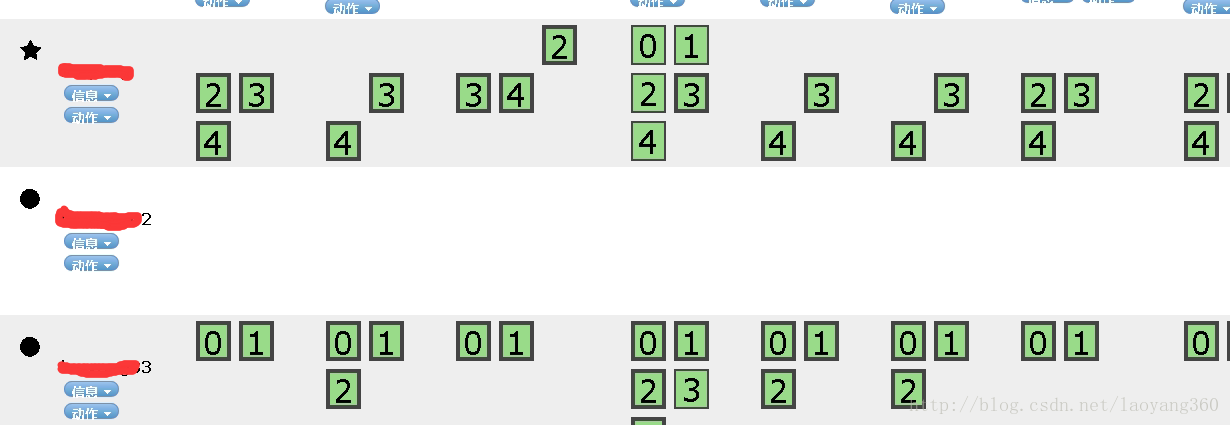
#2、部署节点原理
多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点。Zen发现是ES自带的默认发现机制,使用多播发现其它节点。只要启动一个新的ES节点并设置和集群相同的名称这个节点就会被加入到集群中。(所以,同集群的集群名称一致,才能便于自动发现)
Elasticsearch集群中有的节点一般有三种角色:master node、data node和client node。
1)master node——master节点点主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等。
2)client node——client 节点起到路由请求的作用,实际上可以看做负载均衡器。
3)data node——data 节点上保存了数据分片。它负责数据相关操作,比如分片的 CRUD,以及搜索和整合操作。这些操作都比较消耗 CPU、内存和 I/O 资源;
#3.elasticearch配置含义解释
1)集群名和节点名:
#cluster.name: elasticsearch
#node.name: "Franz Kafka"
- 1
- 2
2)是否参与master选举和是否存储数据
#node.master: true
#node.data: true
- 1
- 2
3)分片数和副本数
#index.number_of_shards: 5
#index.number_of_replicas: 1
- 1
- 2
4)master选举最少的节点数,这个一定要设置为N/2+1,其中N是:具有master资格的节点的数量,而不是整个集群节点个数。
#discovery.zen.minimum_master_nodes: 2
- 1
5)discovery ping的超时时间,拥塞网络,网络状态不佳的情况下设置高一点
#discovery.zen.ping.timeout: 3s
- 1
6)关闭自动发现节点:
discovery.zen.ping.multicast.enabled: false
- 1
单播模式安全,也高效,但是缺点就是如果增加了一个新的机器的话,就需要每个节点上进行配置才生效了。
多播是需要看服务器是否支持的,由于其安全性,其实现在基本的云服务(比如阿里云)是不支持多播的,所以即使你开启了多播模式,你也仅仅只能找到本机上的节点。
7)定义发现的节点:
discovery.zen.ping.unicast.hosts: [" 110.10.11.130 :9300", "10.118.110.112:9300", "110.0.11.143:9300"]
- 1
此处也可以写成hostname的形式。
注意,分布式系统整个集群节点个数N要为奇数个!!
#4、分布式部署遇到的坑
三节点不能联通的原因:
1、各节点的hostname没有正确设置,和节点名称设置为一致。
2、关闭防火墙,service iptables stop;否则,打开防火墙会导致无法正常通信,head插件不能看到节点数据信息。
参考:
1、[官网部署参考]:
https://www.elastic.co/guide/en/elasticsearch/guide/current/deploy.html
2、http://blog.csdn.net/napoay/article/details/52202877
题外话——一个bug引发的思考
注意:
我们正常配置集群的时候,往往会配置好一台机器,然后拷贝这台机器的全部信息到另外两台或者更多台机器。
如果这样的话,可能就会出现:"master_not_discovered_exception 的异常。
[es@master root]$ curl -XGET 'http://localhost:9200/_cluster/state?pretty'
{
"error" : {
"root_cause" : [
{
"type" : "master_not_discovered_exception",
"reason" : null
}
],
"type" : "master_not_discovered_exception",
"reason" : null
},
"status" : 503
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
主节点异常的一般原因是:网络问题,防火墙设置的问题等。
但,还有一种原因是:我把之前的copy到里另外两台,data里的节点没有删除。
根据进一步的错误日志elasticsearch.log进行排查,
] failed to send join request to master
- 1
错误原因在github上有讨论:
描述的情况是因为第二个节点使用的数据文件夹是第一个节点文件夹的副本,这包括其节点ID。这是不受支持的,
如果你这样做,各种各样的事情都可能出错。您应该使用空数据文件夹启动一个新节点,并允许Elasticsearch跨自身复制数据。
思考:
- 遇到类似集群问题,通过state API看到的是状态:“aster_not_discovered_exception”,
- 而通过错误日志:“failed to send join request to master ”,基本能定位到代码级别的报错,
- 进一步结合日志,就能定位到原因。
https://discuss.elastic.co/t/cluster-node-not-joining/136072
https://github.com/elastic/elasticsearch/issues/21405
——————————————————————————————————
更多ES相关实战干货经验分享,请扫描下方【铭毅天下】微信公众号二维码关注。
(每周至少更新一篇!)
和你一起,死磕Elasticsearch!
——————————————————————————————————

2017年6月3日 11:48 于家中床前
作者:铭毅天下
转载请标明出处,原文地址:
http://blog.csdn.net/laoyang360/article/details/72850834
如果感觉本文对您有帮助,请点击‘顶’支持一下,您的支持是我坚持写作最大的动力,谢谢!

