
- 1Tensorflow CNN(两层卷积+全连接+softmax)_全连接层加卷积层代码
- 2今天解决了一个难题,庆祝一下_smbclient访问共享,提示tree connect failed:nt_status_bad_
- 3笔记:FRPS_nssm frp
- 4转计算机科学与技术专业要求,信息与计算机工程学院学生转入计算机科学与技术专业考核办法...
- 5Scrapy 链家网爬取(存储到MySQL、json、xlsx)_爬取链家官方网站新房的数据保存json
- 6腾讯云安装MYSQL远程连接不上解决方案
- 7刚刚!国产统一操作系统 UOS 正式对外公开,太牛逼了!
- 8chatgpt赋能python:Python如何处理大文件
- 9关东升python从小白到大牛_《Python从小白到大牛》第3章 第一个Python程序
- 10基于python+django+mysql网上鲜花水果购物商城系统设计与实现 开题报告参考
【Python机器学习】文本特征提取及文本向量化讲解和实战(图文解释 附源码)_文本向量化和特征提取的关系
赞
踩
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
文本提取及文本向量化
词频和所谓的Tf-idf是传统自然语言处理中常用的两个文本特征。
以词频特征和Tf-idf特征为基础,可以将一段文本表示成一个向量。将多个文本向量化后,然后就可以运用向量距离计算方法来比较它们的相似性、用聚类算法来分析它们的自然分组。如果文本有标签,比如新闻类、军事类、财经类等等,那么还可以用它们来训练一个分类模型,用于对未知文本进行标签预测。
词频
将文本中每个词出现的次数按一定的顺序排列起来,就得到了一个向量,如已经分好词的句子:
小王 喜欢 看 电影 , 他 还 喜欢 吃 鱼 可以用向量:
[1, 1, 2, 1, 1, 1, 1, 1]
来表示。向量每一特征表示的词依次为: ['他', '吃', '喜欢', '小王', '电影', '看', '还', '鱼']
这种将文本向量化的方法,称为词袋(Bag of Words)模型。由实现过程可以知道,词袋模型只是把文本看成装下词语的“袋子”,它不考虑文本的语法、句法和单词顺序等因素。也就是说,它认为文本中每个词语出现的位置都是独立不相关的,与其它词语是否出现没有关系,不存在依赖性。
在sklearn.feature_extraction.text模块中,CountVectorizer类实现了提取词频特征,并用词袋模型向量化文本。
定义由n个文本组成的集合为S,定义其中第i个文本d_i的特征向量为d_i:

其中,t_j表示第j个词,m为词的总数,TF(t_j,d_i)表示第j个词在第i个文档中的频数。 词频特征有一种简化应用,称为布尔词频。布尔词频是用1来统一表示非0的词频。
TF-IDF
相较于词频,TF-IDF还综合考虑词语的稀有程度。它认为一个词语的重要程度不光正比于它在文本中的频次,还反比于有多少文本包含它。

其中,DF(t_j)是包含单词t_j的文本数,IDF(t_j)是DF(t_j)的倒数。
如果把相继出现的两个词语作为一个特征提取,则考虑了间距为1的关联性。如“小王 喜欢 看 电影”文本中,可以提取出“小王 喜欢”、“喜欢 看”、“看 电影”三个这样的特征。在自然语言处理领域,以这样的特征构建的模型称为2元(2-gram)模型,相应地,把前述的模型称为1元模型。
文本相似度比较示例
余弦相似度刻画的是两个向量之间的夹角,它适合于与向量方向相关的距离度量。点x_i,x_j的余弦相似度为:
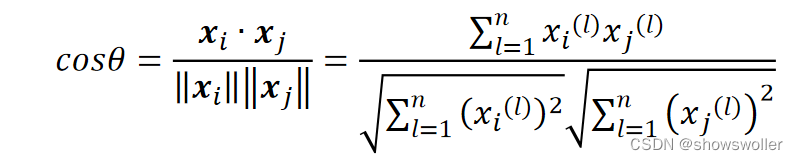
四个字符串如下
str1 = "计算机应用数学课程面向计算机科学本科专业介绍基本数学技巧,以及这些技巧怎样在计算机科学中应用。现代计算机科学教育需要学生掌握宽阔的数学知识,并能灵活和创新地解决现在和将来的科技挑战。在该课程中,数学技巧主要涵括代数、几何、概率理论,随机模型、信息理论等。这些技巧将应用于不同专题的问题和算法设计,包括互联网、无线传感网、密码学、分布式系统、算法设计和优化等。最后,该课程向学生介绍在计算理论基础方面深层次的科学问题,如不可解性、复杂性和量子计算。"
str2 = "人工智能数学基础课程面向人工智能本科专业介绍基本数学技巧,以及这些技巧怎样在人工智能中应用。人 工智能和多学科有紧密联系。因此一个完整的人工智能专业教育需要学生掌握宽阔的数学知 识,并能灵活和创新地解决现在和将来的科技挑战。在该课程中,数学技巧主要涵括线性代 数、高维几何、统计推断,数学优化,信息理论等。这些技巧将应用于不同专题的问题和算 法设计,包括机器学习、大数据,遥感压缩、贝叶斯网络、计算生物和自然语言等。最后, 该课程向学生介绍在计算理论基础方面深层次的科学问题,如复杂性和量子人工智能。"
str3 = "密码学基础课程的主要目的是介绍现代密码学的一些基本概念。与数字内容分布有关的两个主要问题是信息的隐秘性和数据来源。在简短介绍代数之后,将会在现代私钥和公钥加密的背景下讨论隐私问题及其解决方案。之后将回顾一下使用散列函数和数字签名来实现数字内容认证的一些工具。其中所提出的结构是建立设计安全系统和实际应用协议。同时,本课程也将涉及加密方案和协议的攻击和安全分析等内容。"
str4 = "《英汉口译》课程主要训练学生英汉、汉英双语转换的口译能力。课程从句子和简单会话过渡到口语段落以及口语语篇的翻译,内容涉及简单的日常生活会话、涉外导游、商务谈判、会展解说、学术讲座等体裁的演讲或访谈。通过本课程的学习,学生可以提高双语听、说、读、译的综合应用能力,并强化英语语言基础。"
利用余弦相似度计算结果如下

部分代码如下
- #!/usr/bin/env python
- # coding: utf-8
-
- # ## 文本特征提取
-
- # In[1]:
-
-
- from sklearn.feature_extraction.text import CountVectorizer
-
-
- # In[84]:
-
-
- vectorizer = CountVectorizer(token_pattern='(?u)\\b\\w+\\b')
- corpus = [
- '小王 喜欢 看 电影 , 他 还 喜欢 吃 鱼'
- ]
- X = vectorizer.fit_transform(corpus)
-
- prin
-
-
- # In[86]:
-
-
- corpus = [
- '小王 喜欢 看 电影 , 他 还 喜欢 吃 鱼',
- '小温 也 喜欢 看 电影 , 她 还 喜欢 旅游'
- ]
- X = vectorizer.fit_transform(corpus)
- print(vectorizer.get_feature_names())
- X.toarray()
-
-
- # ## 文本相似度比较示例
-
- # In[124]:
-
-
- str1 = "计算机应用数学课程面向计算机科学本科专业介绍基本数学技巧,以及这些技巧怎样在计算机科学中应用。现代计算机科学教育需要学生掌握宽阔的数学知识,并能灵活和创新地解决现在和将来的科技挑战。在该课程中,数学技巧主要涵括代数、几何、概率理论,随机模型、信息理论等。这些技巧将应用于不同专题的问题和算法设计,包括互联网、无线传感网、密码学、分布式系统、算法设计和优化等。最后,该课程向学生介绍在计算理论基础方面深层次的科学问题,如不可解性、复杂性和量子计算。"
- str2 = "人工智能数学基础课程面向人工智能本科专业介绍基本数学技巧,以及这些技巧怎样在人工智能中应用。人 工智能和多学科有紧密联系。因此一个完整的人工智能专业教育需要学生掌握宽阔的数学知 识,并能灵活和创新地解决现在和将来的科技挑战。在该课程中,数学技巧主要涵括线性代 数、高维几何、统计推断,数学优化,信息理论等。这些技巧将应用于不同专题的问题和算 法设计,包括机器学习、大数据,遥感压缩、贝叶斯网络、计算生物和自然语言等。最后, 该课程向学生介绍在计算理论基础方面深层次的科学问题,如复杂性和量子人工智能。"
- str3 = "密码学基础课程的主要目的是介绍现代密码学的一些基本概念。与数字内容分布有关的两个主要问题是信息的隐秘性和数据来源。在简短介绍代数之后,将会在现代私钥和公钥加密的背景下讨论隐私问题及其解决方案。之后将回顾一下使用散列函数和数字签名来实现数字内容认证的一些工具。其中所提出的结构是建立设计安全系统和实际应用协议。同时,本课程也将涉及加密方案和协议的攻击和安全分析等内容。"
- str4 = "《英汉口译》课程主要训练学生英汉、汉英双语转换的口译能力。课程从句子和简单会话过渡到口语段落以及口语语篇的翻译,内容涉及简单的日常生活会话、涉外导游、商务谈判、会展解说、学术讲座等体裁的演讲或访谈。通过本课程的学习,学生可以提高双语听、说、读、译的综合应用能力,并强化英语语言基础。"
-
-
- # In[125]:
-
-
- import jieba
- str1 = " ".join(jieba.lcut(str1))
- str2 = " ".join(jieba.lcut(str2))
- str3 =
-
- corpus = [str1, str2, str3, str4]
- corpus
-
-
- # In[127]:
-
-
- X = vectorizer.fit_transform(corpus)
- print(vectorizer.get_feature_names())
- X.toarray()
-
-
- # In[128]:
-
-
- from sklearn.preprocessing import Normalizer
- X_normal = Normalizer().fit_transform(X.toarray())
- X_normal
-
-
- # In[129]:
-
-
- from sklearn.metrics.pairwise import cosine_similarity, euclidean_distances
- cosine_similarity(X_normal)
-
-
-
-
-
-

创作不易 觉得有帮助请点赞关注收藏~~~

