
- 1架构_ifar构架
- 2史上最全的渗透测试面试题,都是干货。
- 3AI Mass人工智能大模型即服务时代:大模型即服务的算法选择_ai大模型服务
- 4web应用模式中,前后端不分离与前后端分离的区别_前后端分离和不分离的区别
- 5支持向量机svm分类、回归、网格搜索 基于sklearn(python)实现_svm网格搜索
- 6大模型时代,自动驾驶落地还需几步?
- 7第二周神经网络基础_给定输入向量计算通过网络后的输出
- 8Angular的路由_angular路由
- 9DATAX:MongoDB增量数据写入到mysql中_datax以增量导入数据
- 10【数据库运维】postgresql ODBC 安装配置与连接测试_postgres odbc测试及使用
C++开发必知的内存问题及常用的解决方法-经典文章_c++自带栈引用内存无效
赞
踩
1. 内存管理功能问题
由于C++语言对内存有主动控制权,内存使用灵活和效率高,但代价是不小心使用就会导致以下内存错误:
• memory overrun:写内存越界 • double free:同一块内存释放两次 • use after free:内存释放后使用 • wild free:释放内存的参数为非法值 • access uninitialized memory:访问未初始化内存 • read invalid memory:读取非法内存,本质上也属于内存越界 • memory leak:内存泄露 • use after return:caller访问一个指针,该指针指向callee的栈内内存 • stack overflow:栈溢出
常用的解决内存错误的方法
- 代码静态检测
静态代码检测是指无需运行被测代码,通过词法分析、语法分析、控制流、数据流分析等技术对程序代码进行扫描,找出代码隐藏的错误和缺陷,如参数不匹配,有歧义的嵌套语句,错误的递归,非法计算,可能出现的空指针引用等等。统计证明,在整个软件开发生命周期中,30%至70%的代码逻辑设计和编码缺陷是可以通过静态代码分析来发现和修复的。在C++项目开发过程中,因为其为编译执行语言,语言规则要求较高,开发团队往往要花费大量的时间和精力发现并修改代码缺陷。所以C++静态代码分析工具能够帮助开发人员快速、有效的定位代码缺陷并及时纠正这些问题,从而极大地提高软件可靠性并节省开发成本。
静态代码分析工具的优势:
1、自动执行静态代码分析,快速定位代码隐藏错误和缺陷。
2、帮助代码设计人员更专注于分析和解决代码设计缺陷。
3、减少在代码人工检查上花费的时间,提高软件可靠性并节省开发成本。
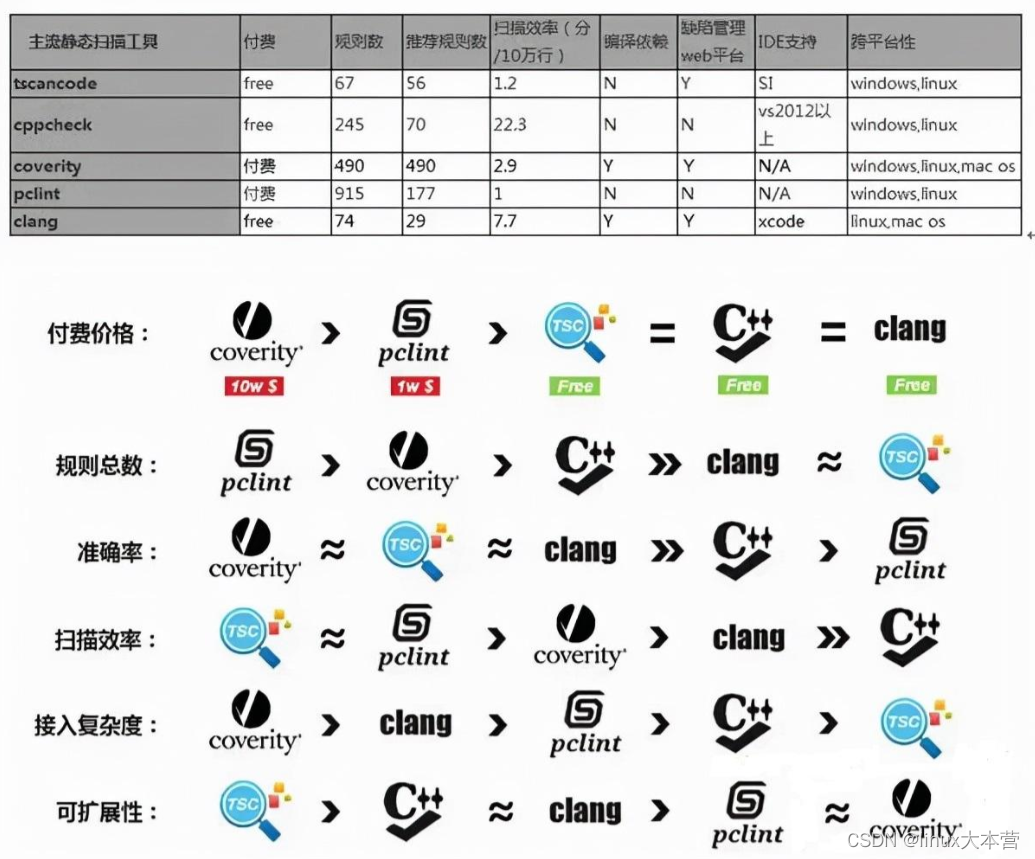
一些主流的静态代码检测工具,免费的cppcheck,clang static analyzer;
商用的coverity,pclint等
各个工具性能对比:
- 代码动态检测
所谓的代码动态检测,就是需要再程序运行情况下,通过插入特殊指令,进行动态检测和收集运行数据信息,然后分析给出报告。
1.为了检测内存非法使用,需要hook内存分配和操作函数。hook的方法可以是用C-preprocessor,也可以是在链接库中直接定义(因为Glibc中的malloc/free等函数都是weak symbol),或是用LD_PRELOAD。另外,通过hook strcpy(),memmove()等函数可以检测它们是否引起buffer overflow。
- 为了检查内存的非法访问,需要对程序的内存进行bookkeeping,然后截获每次访存操作并检测是否合法。bookkeeping的方法大同小异,主要思想是用shadow memory来验证某块内存的合法性。至于instrumentation的方法各种各样。有run-time的,比如通过把程序运行在虚拟机中或是通过binary translator来运行;或是compile-time的,在编译时就在访存指令时就加入检查操作。另外也可以通过在分配内存前后加设为不可访问的guard page,这样可以利用硬件(MMU)来触发SIGSEGV,从而提高速度。
3.为了检测栈的问题,一般在stack上设置canary,即在函数调用时在栈上写magic number或是随机值,然后在函数返回时检查是否被改写。另外可以通过mprotect()在stack的顶端设置guard page,这样栈溢出会导致SIGSEGV而不至于破坏数据。
工具总结对比,常用valgrind(检测内存泄露),gperftools(统计内存消耗)等:
DBI:动态二进制工具 CTI:编译时工具 UMR:未初始化的存储器读取 UAF:释放后使用(又名悬挂指针) UAR:返回后使用 OOB:越界 x86:包括32和64-少量。在GCC 4.9中已删除了 Mudflap,因为它已被AddressSanitizer取代。 Guard Page:一系列内存错误检测器(Linux上为电子围栏或DUMA,Windows上为Page Heap,OS X上为 libgmalloc)gperftools:与TCMalloc捆绑在一起的各种性能工具/错误检测器。堆检查器(检漏器)仅在Linux上可用。调试分配器同时提供了保护页和Canary值,以更精确地检测OOB写入,因此它比仅保护页的检测器要好。
2. C++内存管理效率问题
1、内存管理可以分为三个层次
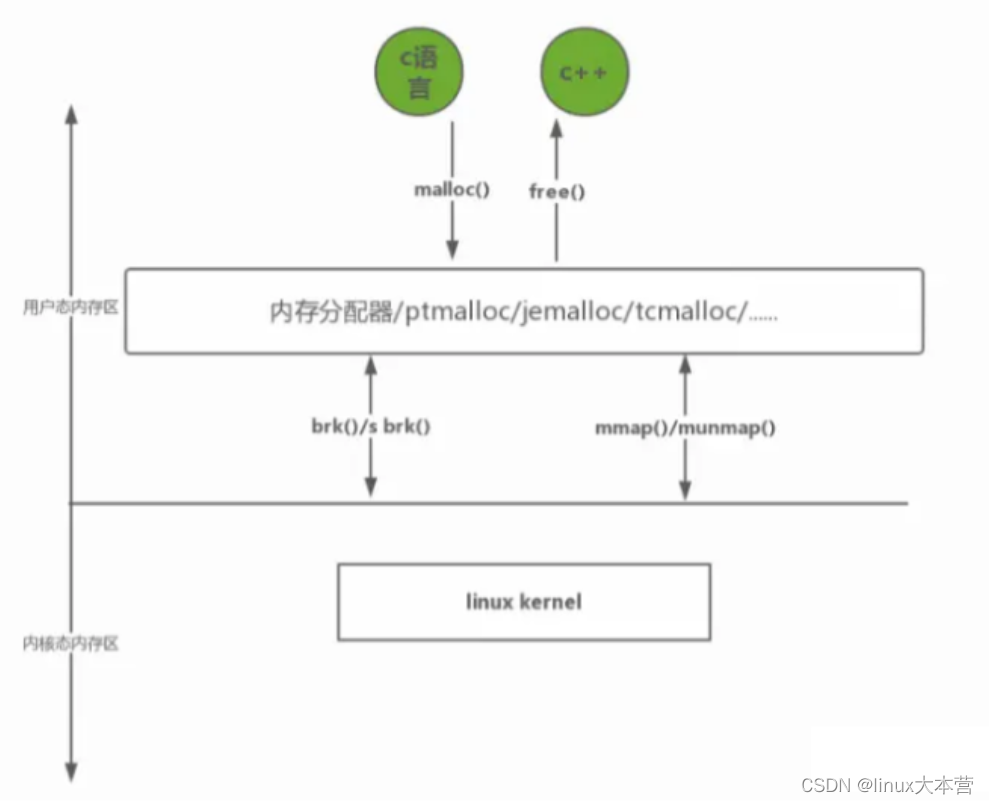
自底向上分别是:
- 第一层:操作系统内核的内存管理-虚拟内存管理
- 第二层:glibc层维护的内存管理算法
- 第三层:应用程序从glibc动态分配内存后,根据应用程序本身的程序特性进行优化, 比如SGI STL allocator,使用引用计数std::shared_ptr,RAII,实现应用的内存池等等。
当然应用程序也可以直接使用系统调用从内核分配内存,自己根据程序特性来维护内存,但是会大大增加开发成本。
2、C++内存管理问题
- 频繁的new/delete势必会造成内存碎片化,使内存再分配和回收的效率下降;
- new/delete分配内存在linux下默认是通过调用glibc的api-malloc/free来实现的,而这些api是通过调用到linux的系统调用:
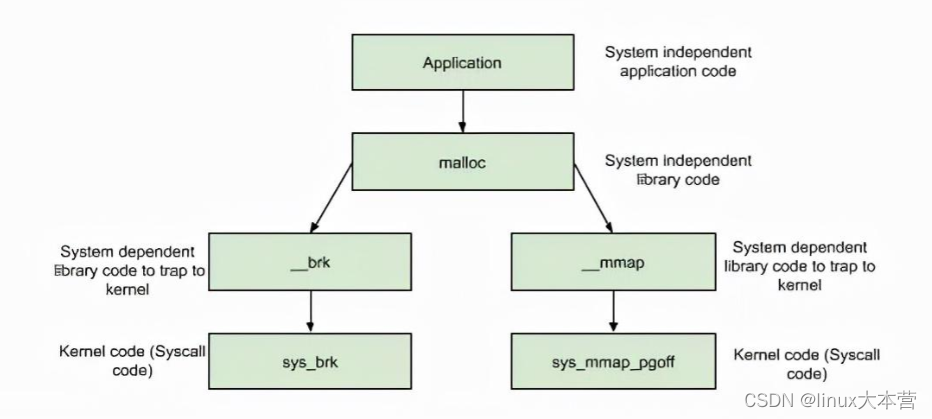
brk()/sbrk() // 通过移动Heap堆顶指针brk,达到增加内存目的 mmap()/munmap() // 通过文件影射的方式,把文件映射到mmap区
分配内存 < DEFAULT_MMAP_THRESHOLD,走brk,从内存池获取,失败的话走brk系统调用
分配内存 > DEFAULT_MMAP_THRESHOLD,走mmap,直接调用mmap系统调用
其中,DEFAULT_MMAP_THRESHOLD默认为128k,可通过mallopt进行设置。
sbrk/brk系统调用的实现:分配内存是通过调节堆顶的位置来实现, 堆顶的位置是通过函数 brk 和 sbrk 进行动态调整,参考例子:
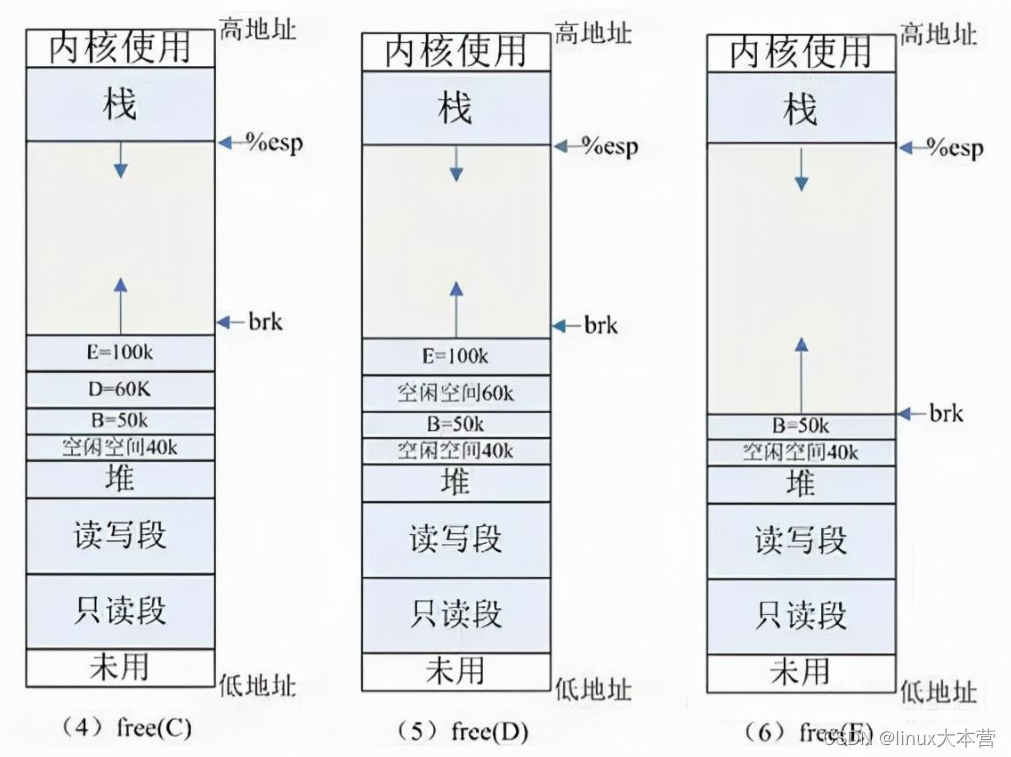
(1) 初始状态:如图 (1) 所示,系统已分配 ABCD 四块内存,其中 ABD 在堆内分配, C 使用 mmap 分配。为简单起见,图中忽略了如共享库等文件映射区域的地址空间。
(2) E=malloc(100k) :分配 100k 内存,小于 128k ,从堆内分配,堆内剩余空间不足,扩展堆顶 (brk) 指针。
(3) free(A) :释放 A 的内存,在 glibc 中,仅仅是标记为可用,形成一个内存空洞 ( 碎片 ),并没有真正释放。如果此时需要分配 40k 以内的空间,可重用此空间,剩余空间形成新的小碎片。
(4) free(C) :C 空间大于 128K ,使用 mmap 分配,如果释放 C ,会调用 munmap 系统调用来释放,并会真正释放该空间,还给 OS ,如图 (4) 所示。
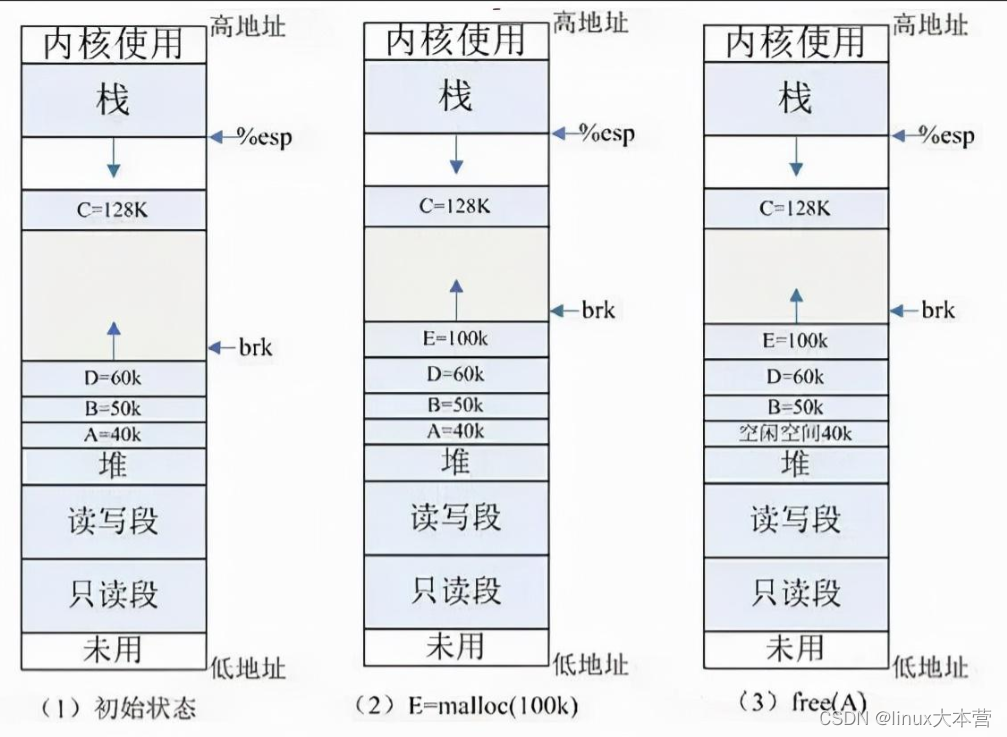
所以free的内存不一定真正的归还给OS,随着系统频繁地 malloc 和 free ,尤其对于小块内存,堆内将产生越来越多不可用的碎片,导致“内存泄露”。而这种“泄露”现象使用 valgrind 是无法检测出来的。
- 综上,频繁内存分配释放还会导致大量系统调用开销,影响效率,降低整体性能;
相关视频推荐
免费学习地址:C/C++Linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

3. 常用解决上述问题的方案
内存池技术
内存池方案通常一次从系统申请一大块内存块,然后基于在这块内存块可以进行不同内存策略实现,可以比较好得解决上面提到的问题,一般采用内存池有以下好处:
1.少量系统申请次数,非常少(几没有) 堆碎片。 2.由于没有系统调用等,比通常的内存申请/释放(比如通过malloc, new等)的方式快。 3.可以检查应用的任何一块内存是否在内存池里。 4.写一个”堆转储(Heap-Dump)”到你的硬盘(对事后的调试非常有用)。 5.可以更方便实现某种内存泄漏检测(memory-leak detection)。
6.减少额外系统内存管理开销,可以节约内存;
内存管理方案实现的指标:
- 额外的空间损耗尽量少
- 分配速度尽可能快
- 尽量避免内存碎片
- 多线程性能好
- 缓存本地化友好
- 通用性,兼容性,可移植性,易调试等
各个内存分配器的实现都是在以上的各种指标中进行权衡选择.
4. 一些业界主流的内存管理方案
SGI STL allocator
是比较优秀的 C++库内存分配器(细节参考上面描述)
ptmalloc
是glibc的内存分配管理模块, 主要核心技术点:
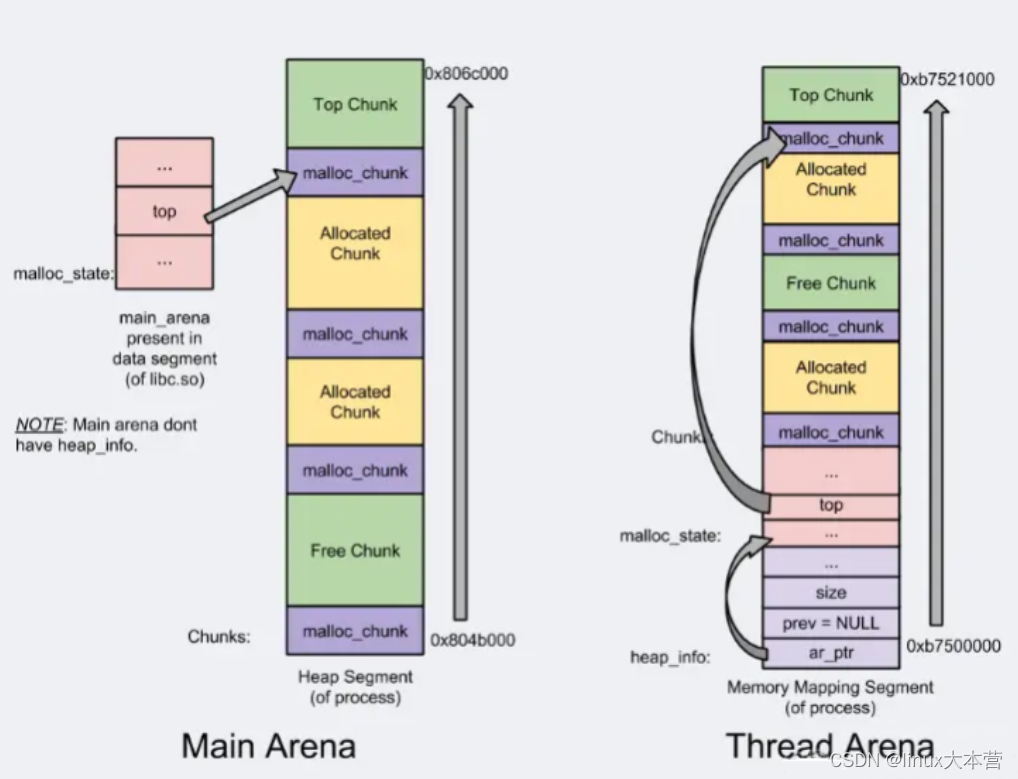
- Arena-main /thread;支持多线程
- Heap segments;for thread arena via by mmap call ;提高管理
- chunk/Top chunk/Last Remainder chunk;提高内存分配的局部性
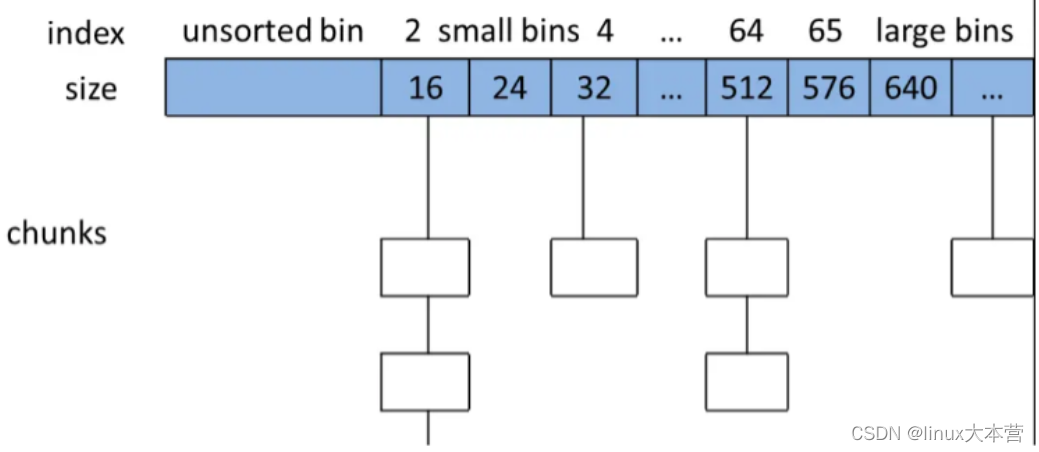
- bins/fast bin/unsorted bin/small bin/large bin;提高分配效率
ptmalloc的缺陷
- 后分配的内存先释放,因为 ptmalloc 收缩内存是从 top chunk 开始,如果与 top chunk 相邻的 chunk 不能释放, top chunk 以下的 chunk 都无法释放。
- 多线程锁开销大, 需要避免多线程频繁分配释放。
- 内存从thread的areana中分配, 内存不能从一个arena移动到另一个arena, 就是说如果多线程使用内存不均衡,容易导致内存的浪费。比如说线程1使用了300M内存,完成任务后glibc没有释放给操作系统,线程2开始创建了一个新的arena, 但是线程1的300M却不能用了。
- 每个chunk至少8字节的开销很大
- 不定期分配长生命周期的内存容易造成内存碎片,不利于回收。64位系统最好分配32M以上内存,这是使用mmap的阈值。
tcmalloc
google的gperftools内存分配管理模块, 主要核心技术点:
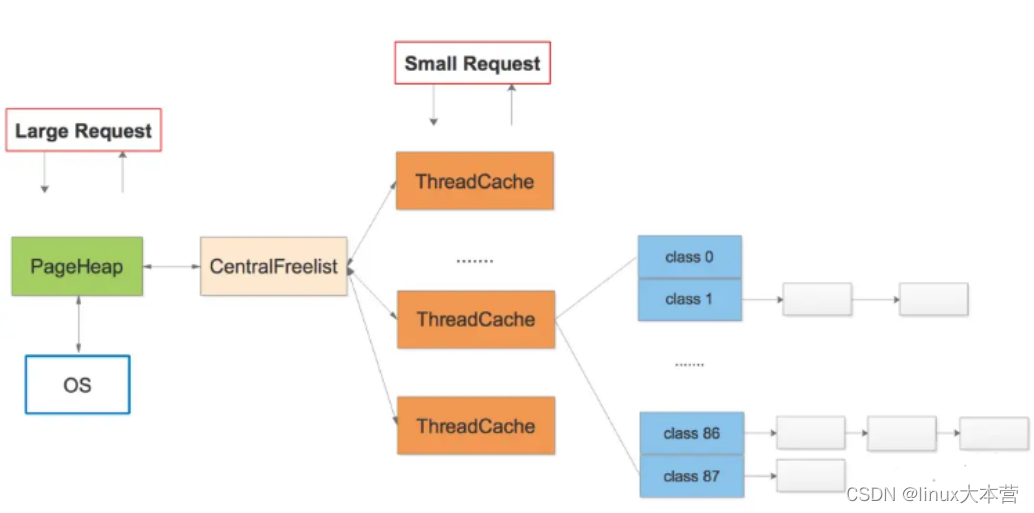
- thread-localcache/periodic garbagecollections/CentralFreeList;提高多线程性能,提高cache利用率
TCMalloc给每个线程分配了一个线程局部缓存。小分配可以直接由线程局部缓存来满足。需要的话,会将对象从中央数据结构移动到线程局部缓存中,同时定期的垃圾收集将用于把内存从线程局部缓存迁移回中央数据结构中:
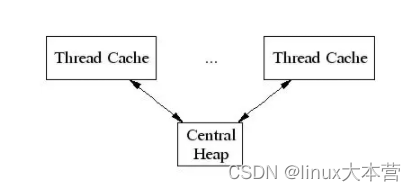
2. Thread Specific Free List/size-classes [8,16,32,…32k]: 更好小对象内存分配;
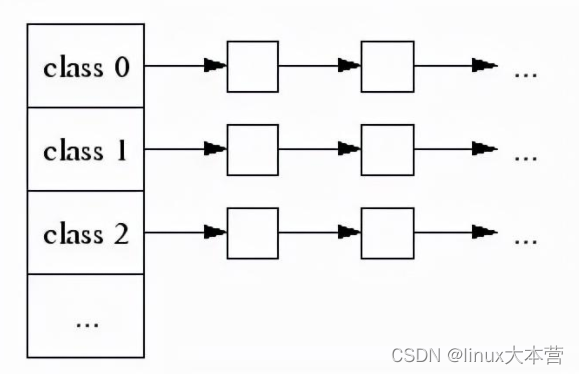
每个小对象的大小都会被映射到170个可分配的尺寸类别中的一个。例如,在分配961到1024字节时,都会归整为1024字节。尺寸类别这样隔开:较小的尺寸相差8字节,较大的尺寸相差16字节,再大一点的尺寸差32字节,如此类推。最大的间隔(对于尺寸 >= ~2K的)是256字节。一个线程缓存对每个尺寸类都包含了一个自由对象的单向链表
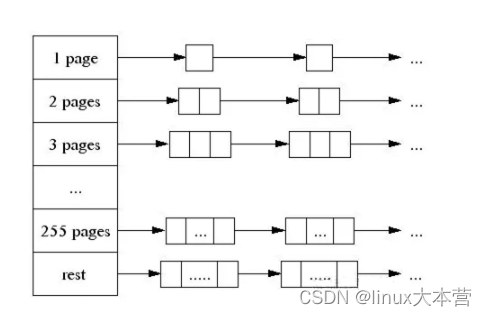
3. The central page heap:更好的大对象内存分配,一个大对象的尺寸(> 32K)会被除以一个页面尺寸(4K)并取整(大于结果的最小整数),同时是由中央页面堆来处理 的。中央页面堆又是一个自由列表的阵列。对于i < 256而言,第k个条目是一个由k个页面组成的自由列表。第256个条目则是一个包含了长度>= 256个页面的自由列表:
4. Spans:
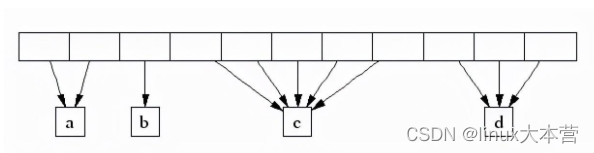
TCMalloc管理的堆由一系列页面组成。连续的页面由一个“跨度”(Span)对象来表示。一个跨度可以是_已被分配_或者是_自由_的。如果是自由的,跨度则会是一个页面堆链表中的一个条目。如果已被分配,它会是一个已经被传递给应用程序的大对象,或者是一个已经被分割成一系列小对象的一个页面。如果是被分割成小对象的,对象的尺寸类别会被记录在跨度中。
由页面号索引的中央数组可以用于找到某个页面所属的跨度。例如,下面的跨度_a_占据了2个页面,跨度_b_占据了1个页面,跨度_c_占据了5个页面最后跨度_d_占据了3个页面。
tcmalloc的改进
- ThreadCache会阶段性的回收内存到CentralCache里。解决了ptmalloc2中arena之间不能迁移的问题。
- Tcmalloc占用更少的额外空间。例如,分配N个8字节对象可能要使用大约8N * 1.01字节的空间。即,多用百分之一的空间。Ptmalloc2使用最少8字节描述一个chunk。
- 更快。小对象几乎无锁, >32KB的对象从CentralCache中分配使用自旋锁。并且>32KB对象都是页面对齐分配,多线程的时候应尽量避免频繁分配,否则也会造成自旋锁的竞争和页面对齐造成的浪费。
jemalloc
FreeBSD的提供的内存分配管理模块, 主要核心技术点:
1. 与tcmalloc类似,每个线程同样在<32KB的时候无锁使用线程本地cache;
- Jemalloc在64bits系统上使用下面的size-class分类:
Small: [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840] Large: [4 KiB, 8 KiB, 12 KiB, …, 4072 KiB] Huge: [4 MiB, 8 MiB, 12 MiB, …]
- small/large对象查找metadata需要常量时间, huge对象通过全局红黑树在对数时间内查找
- 虚拟内存被逻辑上分割成chunks(默认是4MB,1024个4k页),应用线程通过round-robin算法在第一次malloc的时候分配arena, 每个arena都是相互独立的,维护自己的chunks, chunk切割pages到small/large对象。free()的内存总是返回到所属的arena中,而不管是哪个线程调用free().
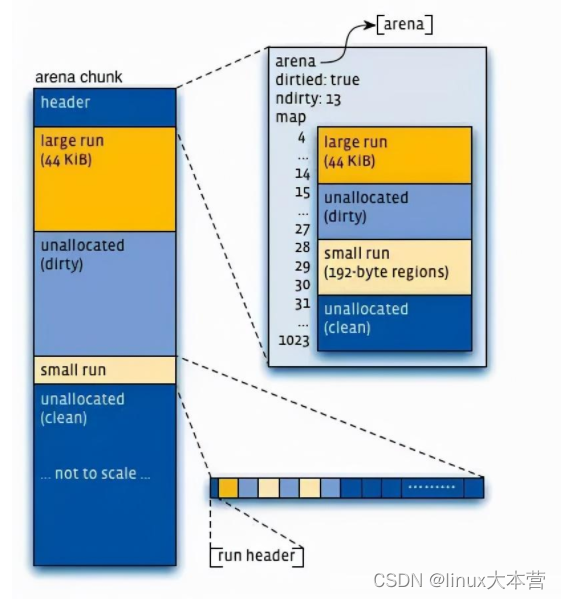
上图可以看到每个arena管理的arena chunk结构, 开始的header主要是维护了一个page map(1024个页面关联的对象状态), header下方就是它的页面空间。Small对象被分到一起, metadata信息存放在起始位置。large chunk相互独立,它的metadata信息存放在chunk header map中。
- 通过arena分配的时候需要对arena bin(每个small size-class一个,细粒度)加锁,或arena本身加锁。并且线程cache对象也会通过垃圾回收指数退让算法返回到arena中。
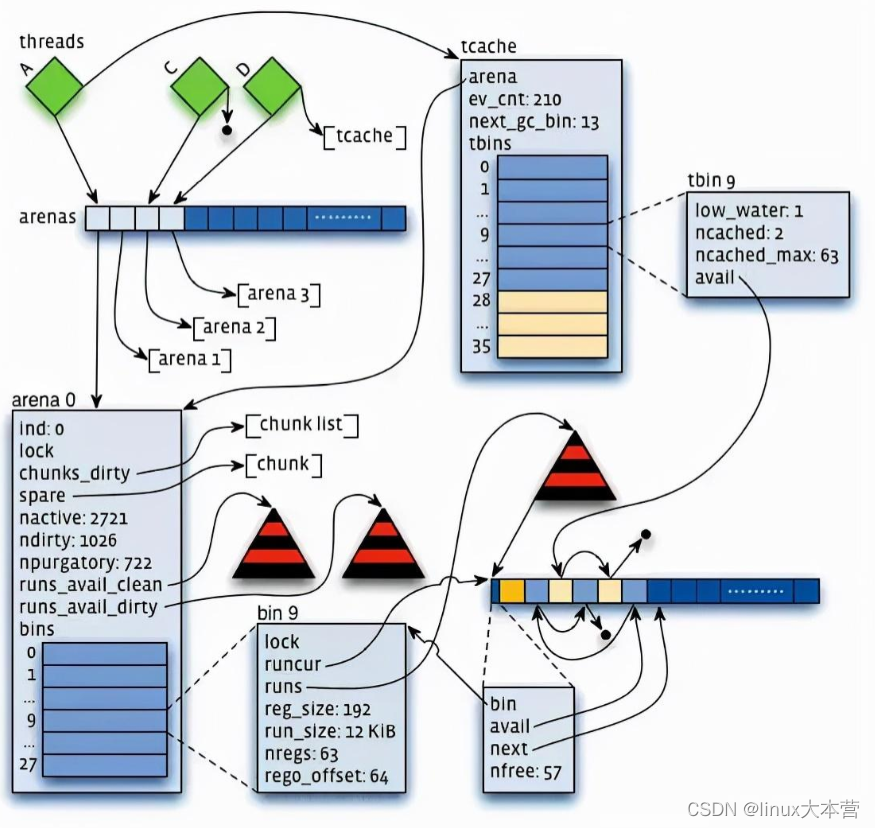
jemalloc的优化
- Jmalloc小对象也根据size-class,但是它使用了低地址优先的策略,来降低内存碎片化。
- Jemalloc大概需要2%的额外开销。(tcmalloc 1%, ptmalloc最少8B).
- Jemalloc和tcmalloc类似的线程本地缓存,避免锁的竞争 .
- 相对未使用的页面,优先使用dirty page,提升缓存命中。
性能比较
测试环境:2x Intel E5/2.2Ghz with 8 real cores per socket,16 real cores, 开启hyper-threading, 总共32个vcpu。16个table,每个5M row。OLTP_RO测试包含5个select查询:select_ranges, select_order_ranges, select_distinct_ranges, select_sum_ranges:
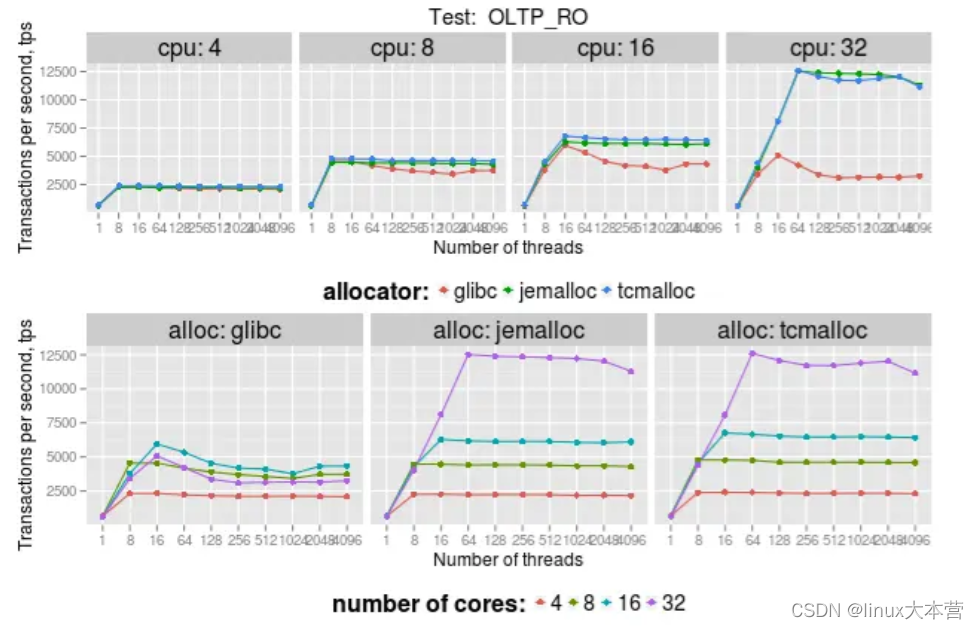
facebook的测试结果:
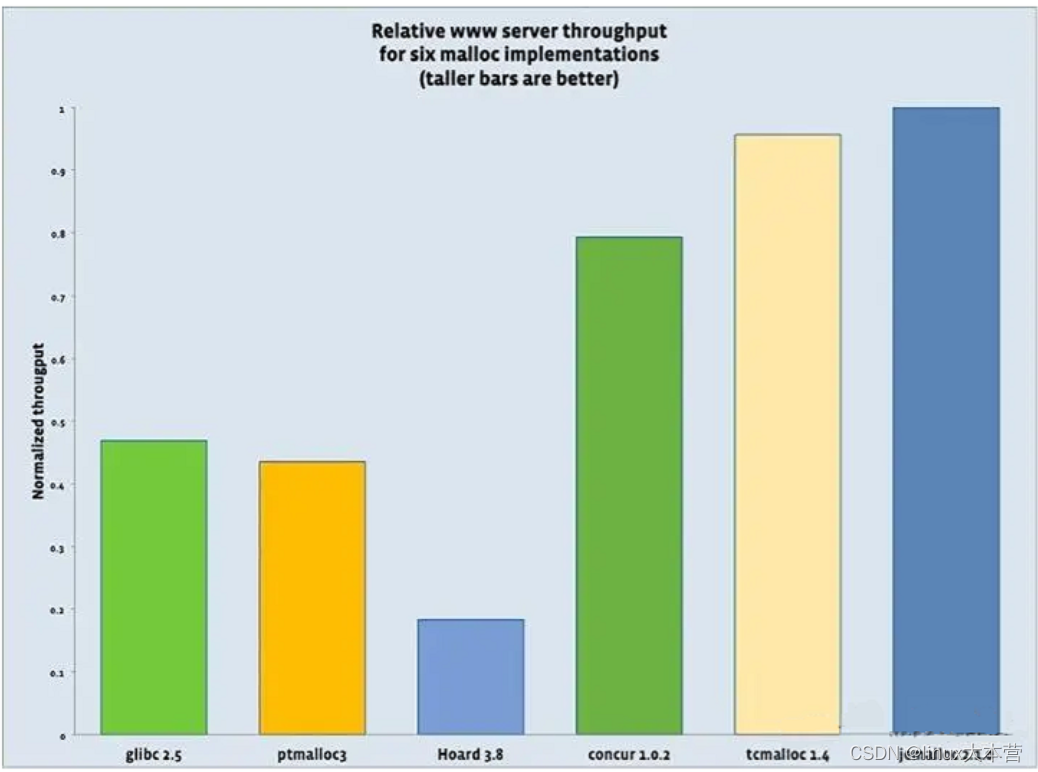
服务器吞吐量分别用6个malloc实现的对比数据,可以看到tcmalloc和jemalloc最好(tcmalloc这里版本较旧)。
总结
可以看出tcmalloc和jemalloc性能接近,比ptmalloc性能要好,在多线程环境使用tcmalloc和jemalloc效果非常明显。一般支持多核多线程扩展情况下可以使用jemalloc;反之使用tcmalloc可能是更好的选择。
思考问题:
1 jemalloc和tcmalloc最佳实践是什么?
2 内存池的设计有哪些套路?为什么?

