- 1Win11跳过联网激活的3种办法
- 2local storage在不同标签页,不同浏览器之间通用吗,可以跨域吗_localstorage可以跨页面吗
- 3黑马程序员——C基础之逻辑运算符_同真为真c语言符号
- 4史上最详细宝塔面板安装教程(收藏)
- 5程序员离职后被公司索赔35万,这件事职场人必须知道!_程序员离职对公司的损失
- 6Far3D: Expanding the Horizon for Surround-view 3D Object Detection 论文翻译
- 7Windows下关闭MySQL的自动提交(autocommit)功能
- 8Java---抽象类和接口_java 抽象类和抽象接口
- 9UE5渲染视频教程推荐
- 10数学建模【因子分析】
【引言】浙大机器学习课程记录
赞
踩
机器学习的定义
第一种定义
ARTHUR SAMUEL对Machine learning 的定义
Machine Learning is Fields of study that gives computers the ability to learn without being explicitly programmed
机器学习是这样的领域,它赋予计算机学习的能力,(这种学历能力)不是通过显著式编程获得的
- 显著式编程
- 提前人为指定规律的编程方式
- 非显著式编程
- 让计算机自己总结规律的编程方式
Arthur Samuel 所定义的机器学习是专指这种非显著式编程的方式
非显著式编程方式的做法:
我们规定了行为和收益函数后,让计算机自己去找最大化收益函数的行为
让计算机通过数据、经验自动的学习。
第二种定义
来自于1998年 Tom Mistshell 在《MACHINE LEARNING》书中给出的定义
A computer program is said to learn from experience E with respect to some task T and some performance measurc P, if its performance on T, as measured by P , improves with experience E
一个计算机程序被称为可以学习,是指它能够针对某个任务 T 和某个性能指标 P,从经验 E 中学习。这种学习的特点是,它在 T 上的被 P 所衡量的性能,会随着经验 E 的增加而提高。
据 Tom Mitshell 的定义,机器学习为为识别不同任务而改造某种算法
这种算法的特点:
随着 Experience 的增多,Performance Measure 也会提高
这种算法的具体体现:
| 标识 | 动作 |
|---|---|
| 任务 T | 设计程序让 AI执行某种行为 |
| 经验 E | AI 多次尝试的行为和这些行为产生的结果 |
| 性能测试 P | 在规定时间内成功执行的次数 |
据经验 E 来提高性能指标 P 的过程,为典型的最优化问题
机器学习的分类
按照任务性质的不同进行分类为:
-
监督学习
-
强化学习
- 计算机通过与环境的互动逐渐强化自己的行为模式
但不绝对
这里主要介绍了监督学习
监督学习
(1)监督学习根据数据标签存在与否分类为:
- 传统监督学习(Traditional Supervised Learning)
- 非监督学习(Unsupervised Learning)
- 半监督学习(Semi-supervised Learning)
(2)基于标签的固有属性,按照标签是连续还是离散分类为:
-
分类问题
-
回归问题
基于标签存在分类
传统监督学习
Traditional Supervised Learning 中每一个训练数据都有对应的标签
算法包括
-
支持向量机 (SUPPORT VECTOR MACHINE)
-
人工神经网络(NEURAL NETWORKS)
-
深度神经网络(Deep Neural Networks)
非监督学习
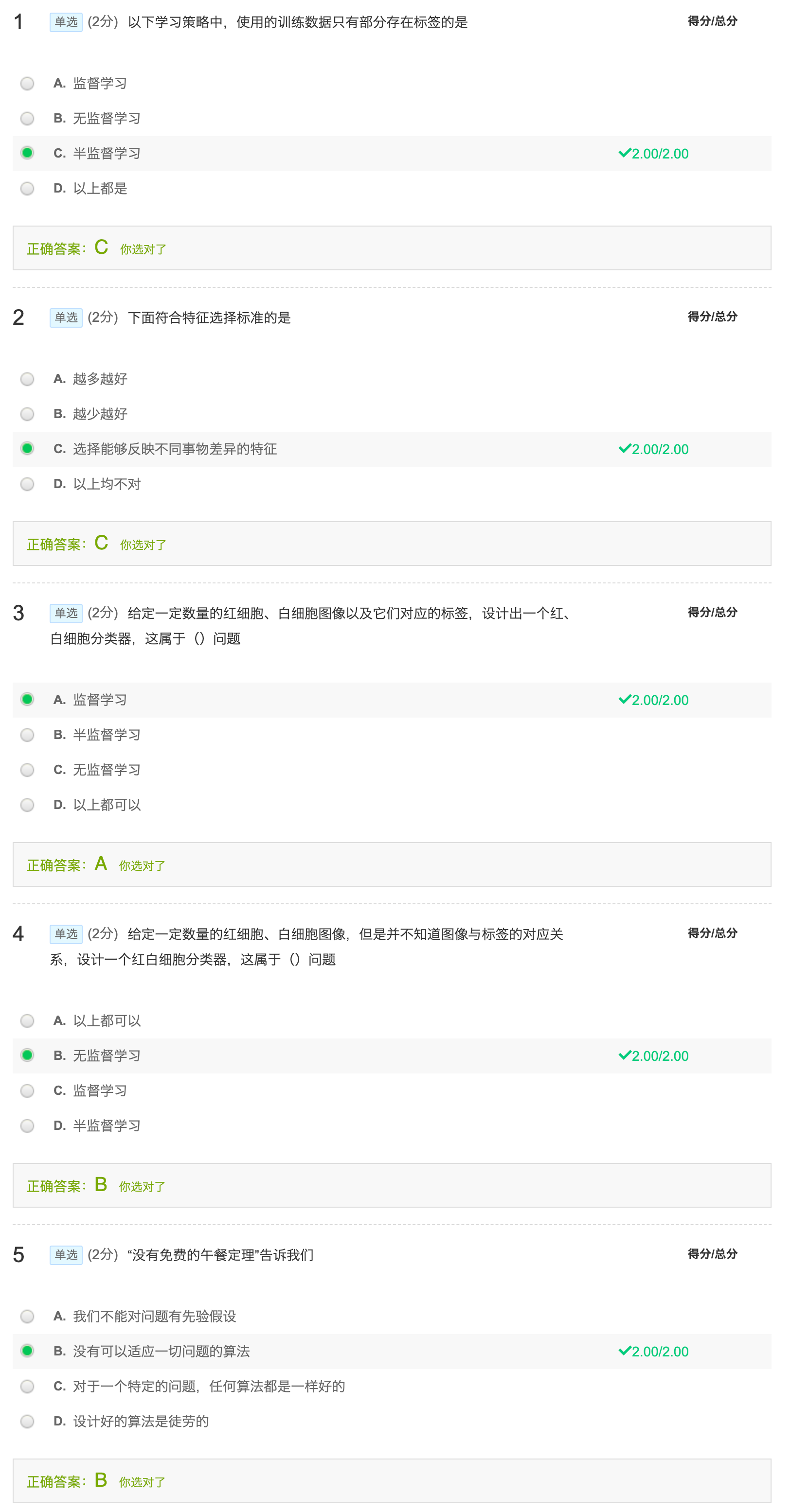
Unsupervised Learning 中所有的训练数据都没有对应的标签
在Traditional Supervised Learning中的数据可能有像:X 代表一类,圆形代表另一类,但在 Unsupervised Learning 中可能如下图:
尽管我们不知道训练数据的类别标签,但我们可以这样处理:
算法包括
- 聚类(Clustering)
- EM 算法(Expectation–Maximizationg algorithm)
- 主成分分析(Principle Component Analysis)
半监督学习
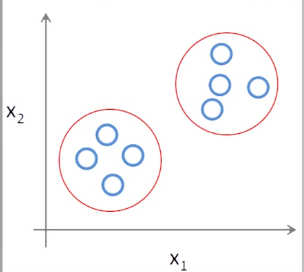
Semi-supervised Learning 中训练数据中有一部分有标签,一部分没有标签
在大量的数据面前,数据标注是成本巨大的工作
所以我们需要:
少量的标注数据 + 大量未标注数据 训练一个更好的机器学习算法
例如下图:
在左边,如果只有两个标注过的训练样本,那么便不好进行分类;如果像右图增加没有标签的训练样本,那么可能设计算法就能实现更准确的分类。
基标签固有属性分类
分类和回归的分别是十分模糊的,因为离散和连续的区别也是模糊的。
我们主要研究机器学习模型解决分类问题。
分类
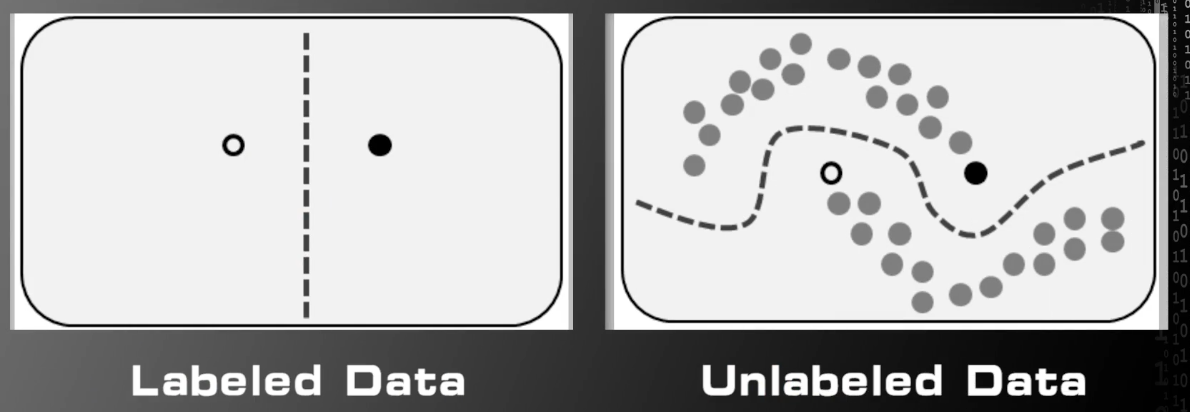
Classifcation:标签是离散的值
例如人脸识别为分类问题
如图:
模式一为双人脸比对,模式二为人群中单人脸匹配。
回归
Regression:标签是连续的值
例如:预测股票价格、预测温度、预测人的年龄等任务
机器学习算法的过程
特征提取(Feature Extraction):
通过训练样本获得的,对机器学习任务有帮助的多维度数据。
机器学习的重点应该是:
假设在已经提取好的特征的前提下,如何构造算法获得更好的性能
当然好的特征是能构造出好算法的前提,特征越好算法结果越好
我们需要研究不同应用场景下应该采取哪种算法,甚至研究新的机器学习算法以便适应新的场景
没有免费午餐定理
1995年,D. H. Wolpert 等人提出:
没有免费午餐定理(No Free Lunch Theorem)
任何一个预测函数,如果在一些训练样本上表现好,那么必然在另一些训练样本上表现不好,如果不对数据在特征空间的先验分布上有一定假设,那么表现好与表现不好的情况一样多。
在设计机器学习算法的时候有一个假设:
在特征空间上距离接近的样本,他们属于同一类别的概率会更高,但是并不绝对,是有可能出错的
如果不对特征空间的先验分布有假设,那么所有算法的表现都一样
机器学习本质:
通过有限的已知数据基础,在复杂的高维特征空间中预测未知的样本
没有放之四海而皆为准的最好算法,因为评价算法的好坏涉及特征空间先验分布的假设
测试