
- 1React18源码: Fiber树中的优先级与帧栈模型_react fiber 优先级顺序
- 2linux下使用C++ Json库_#include
- 3基于Python爬虫广西南宁酒店数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 4最新Zabbix5.0监控cisco交换机配置详细手把手步骤_zabbix5.0添加网络交换机
- 5SQL查询执行流程_sql查询 流程图
- 6[pdf]软件方法上册第二版自测题答案和解析-共144页
- 7盘点2023年Q3的开源模型,这些值得推荐!_tigerbot-13b-chat-v4
- 8腾讯自研交换机系统优化之路
- 9systemctl 管理服务的启动、重启、停止、重载、查看状态命令_systemctl restart
- 10TVM框架详解
SnappyData-一个构建在Spark上的支持实时HTAP场景的解决方案_snappy框架 spark
赞
踩
1、设计目标
2、数据规模在50TB-100TB以下:太大规模的数据(PB规模),还要求实时出结果的场景,并不是SnappyData的设计目标。
3、微批的流失写入:实时数据的写入最好按批次写入。例如列表上的频繁的基于点的update,效率并不是很高。

上图介绍了流数据的注入以及数据分析的过程,如下:
1、当集群搭建完成,此时就可以从外部数据源导入到SnappyData了。可以从HDFS或者RDBMS中导入数据到SD的列表中,以便压缩;如果是维度或者配置表,可以创建为行表。这些外部数据源可以建成外部表。
2、此时实时的流数据就可以通过类似于Spark Streaming来实时注入了
3、通过SQL对流数据进行分析,以便获得准实时的结果。注意这里的SQL还没有涉及到历史数据的查询
4、流失的数据可以高效的存储到列表中,当有新的数据包括更新的数据到达时,首先会放入一个row dealta buffer中,这样做是为了写入更高效;之后会按照批次合并到列表中;同时查询时,会合并buffer与表中的数据
5、表中的数据可以按照LRU算法写到磁盘以释放内存空间。也可以定期将历史数据写入到HDFS中
6、一旦注入流数据,SnappyData便可以提供实时的OLAP分析
3、数据模型
3.1、行存与列存兼容
表可以设置为列表或行表,列表和行表都可以分区,同时行表也可以replicated到每个server。不管行表还是列表,数据都是放到内存中,且集群维护一个或多个副本。
行表存储的内存成本更高,但适合OLTP型的查找,更新,且可以建立索引加速查找。
列表存储的内存成本较低,因为可以压缩;且列表扩展了Spark的列存,为了支持在列表上执行的update操作。
数据写入列表的过程如下:
1、先到达delta row buffer(行存增量缓冲区),以便提高写入率,之后老化批量写入列表
2、行存增量缓冲区就是个行表,其与数据所在的列表具有相同的分区策略
3、行存增量缓冲区还有个好处:insert或update后有一条delete语句,那么这个数据会从合并队列中删除,这样做更高效
4、采用copy-on-write以保证数据一致性
5、当在列表上进行查询时,扩展了Spark Catalyst,以便可以合并delta row buffer中的数据
3.2、统一的API
Spark的应用程序是面向过程的DAG模型。为了简化SnappyData并与Spark保持一致的编程模型,它隐藏了GemFire的API并对DataFrame和Spark SQL做了扩展以便支持列存的更新、SQL语句增强等功能。
SnappyData扩展Spark SQL,支持Spark SQL同时支持标准SQL。且某些DDL的功能更加丰富,例如下面是一个创建表的语句:

可以看到,SD中可以创建行表也可以创建列表;可以指定分区键,默认为replicated;且列表上可以指定与母表相同的分区键,这样可以在join时使得数据本地化;也可以指定内存内的副本数以及持久化的方式等。
3.3、基于SQL的流失处理
2、流处理,当展示维度非常多,即keyBy的数量很多时,用flink实现比较困难;
3、流处理,如果需要union大量的历史数据时,flink中的数据初始化时间过长,且当流+表的数据过大时,实现也比较困难。
Snappydata扩展了Spark Streaming,可以创建stream table,批量更新数据,以支持复杂的、多维度的、关联大量的历史数据的实时OLAP查询。
当然,数据的实时注入不一定非要用Spark Streaming完成,因为很多时候我们要对流数据做些预处理,简单的比如ETL,或者过滤甚至状态维护等,用storm或者flink来完成预处理的工作是不错的选择。且表的设计不一定要stream table,普通的列表也可以。
这样做的数据也是实时的,且用SnappyData在列表上进行的OLAP查询(多维度、涉及历史数据、复杂的),直接可以用SQL既可以满足多种不同的需求了。
某种程度上讲,用SD做流处理,又多了一种选择,它适合的需求是那种需求变化多、实时性强、需要关联历史数据做聚合、查询或聚合维度较多等复杂度较高的SQL,例如下面的一个OLAP SQL的事例:
- SELECT DISTINCT end_minute_timestamp AS minute_timestamp,
- count(order_id) over(order by end_minute_timestamp) AS order_cnt_day,
- count(order_id) over(PARTITION BY end_minute_timestamp) AS order_cnt_minute
- FROM
- (SELECT cast(pay_time / 1000 / 60 + 1 AS int) * 60 AS end_minute_timestamp,
- order_id
- FROM order_table
- WHERE order_status = XXX
- AND pay_date = year(CURRENT_DATE)*10000 + month(CURRENT_DATE)*100 + day(CURRENT_DATE) )
- ORDER BY 1;
上面的SQL逻辑为:统计当天每分钟的分钟订单量以及全天累计订单量。
上述的SQL用Flink SQL也可以实现,如果用Flink DataStream实现的话,就要设置一个1分钟的tumbling event time window,window内汇总订单量,且维护一个ValueState,保存累计订单值。
如果用Flink程序实现,那么你需要写一个DataStream程序,或者Flink SQL程序,复杂度都高于纯SQL,最关键的还是那个job写完后不太能适应需求的变化。
假如你需要看每个城市、每个地区、每个商圈、每个组织、每个用户维度的量呢?那么你的key的数量会很多的,且不能适应某两个的维度组合的数据查看。
用druid或opentsdb,那么你的维度不能太多,且数据没法变更。
4、混合的集群管理
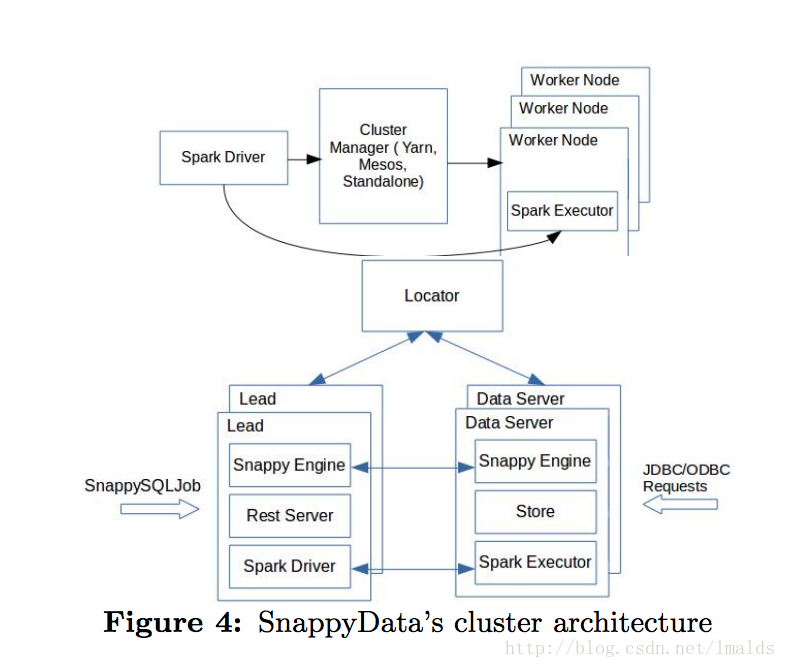
4.1、SnappyData的集群架构
SnappyData由3类不同的角色成员组成了一个peer to peer的集群网络:
1、Locator:提供发现服务,当集群新增成员时,会通知其他成员。通常为了HA,会有多于1个Locator同时存在。JDBC连接SnappyData时也是指定Locator的url进行连接。
2、Lead Node:相当于Spark的driver角色,维护着每个task的SparkContext。Lead通常是一主多备,primary角色负责路由数据到不同的数据server中。
3、Data Server:存储数据,同时负责executor的角色。有些查询可以直接路由到data server,复杂的SQL需要由lead路由到对应的data server上执行。
4.2、SnappyData的高并发
跟TiDB类似,SnappyData也将sql请求分为低延迟的OLTP类SQL以及高延迟的OLAP类SQL。但是与之不同的是,OLTP类的操作直接绕开了Spark的调度机制,直接操作数据;而OLAP类的SQL则通过Spark的fair调度机制完成。
这样的好处是使得SnappyData可以同时处理2类不同的请求,而不用优先执行OLTP,也不用被迫OLAP的SQL等待了。这对于OLAP型的延迟有很大帮助。
4.3、SnappyData中的状态共享
由于表是存于内存的,因此状态天然就是共享的,其数据可以供多个连接共享。同时每个job的执行于data是相互独立的,达到了解耦的效果。
4.4、SnappyData中的HA
P2P的网络,保存了lead以及data server的元数据信息,当有任何机器失败时,P2P网络总能第一时间感知到变化。协调器负责成员之间的数据同步问题。当失败发生时,很容易感知到异常。
对于lead的HA,通常需要多个lead,只有1个primary并多个secondary。
对于executor的HA,也和lead的选主机制一样,允许spark重新部署job。
4.5、SnappyData中的事务一致性
SnappyData支持读提交以及可重复读的事务隔离级别,当通过JDBC连接时就可以指定。当进行更新操作时,通常是由第一个接收到写任务的member负责协调,当写发生时,会对每个member的数据上进行写锁。这里有个假设就是当不能获得写锁或者写冲突时,会返回给调用者。
5、SnappyData上的一些优化
5.1、colocate感知
当用户设计表的时候,往往需要考虑业务通常的访问方式,比如多表join时,join键是什么。假如一个订单表,经常需要和维度表进行join,那么join的条件通常是类似于主外键的关系,所以在设计时,我们就要将订单表的分区键,与维度表的分区键设计为一样的,且订单表要colocate with 维度表。这样设计的好处是当join时,就可以执行本地join了。
5.2、统一的内存管理
SnappyData的内存管理器整合了Spark与GemFire。可以设置内存的使用阀值,其内存使用的监控情况由BlockManager进行管理。GemFire负责更细粒度的表的操作,当内存不足或到达预设的阀值时,会根据LRU算法将陈旧的数据evict到磁盘以释放内存。通过不断的对heap的监控,可以提前使用LRU算法清理数据,这样做使得Gemfire最大限度的防止OOM的发生。
GemFire和Spark都可以使用offheap堆外内存,Gemfire中的表也可以配置使用相同的unsafe API。
6、SnappyData特点
3、支持SQL:支持Spark SQL以及扩展了标准SQL,可以在行存上建索引、约束等,并在列存上分区以及colocate主表。
4、扩展流处理:通过SQL便可对流数据尽心并行处理。
5、NoSQL数据库:可以把任何Spark支持的格式存储在SnappyData中,就当做一个可以执行SQL的数据库一样。
6、数据可变性:SnappyData中支持DML语句,因此存储其中的数据是可变的。同时由于其存储与计算与一身,减少了数据传输提高了性能。
7、行表支持索引:索引只允许创建在行表中,并根据CBO决定是否使用索引来进行优化。
8、colocation:为了使得计算时数据本地化并减少shuffle操作,SnappyData允许在表上分区,并指定与本表的分区规则一致的父表。这样在进行表与父表基关联键相同的join时,可以使得数据本地化并减少shuffle,提高性能。
9、高可用与容错:数据member是个P2P网络,因此可以快速检测到失败并对应用程序的请求提供HA保障。
10、数据恢复:默认情况下,表不仅保存在内存中,也会保存到磁盘。因此一个server的失败,其数据并不会丢失。
7、借助Apache Zeppelin做监控
参考:
SnappyData: A Hybrid Transactional Analytical Store Built On Spark
SnappyData: Streaming, Transactions, and Interactive Analytics in a Unified Engine
SnappyData: A Unified Cluster for Streaming, Transactions, and Interactive Analytics

