
- 1NGINX学习笔记(六):常见错误之403 forbidden (13: Permission denied)_nginx permission denied
- 2配置自定义DNS,以访问公司内网资源
- 3(转)每天一个linux命令(46):vmstat命令
- 4【精华】AIGC启元2024
- 5如何使用安卓平板远程Ubuntu服务器通过VS Code远程开发_安卓端远程到 ubuntu
- 6pycharm选择conda环境无效问题_conda 切环境 没有用
- 7组合预测模型 | ARIMA-WOA-CNN-LSTM时间序列预测(Python)
- 8WDS服务(自动部署系统)部署安装Windows10操作系统——部署安装_win10安装wds
- 9漠河市最好的洗浴是哪儿_玩转漠河,终于找到北了!4条经典线,带你玩转漠河...
- 10分布式存储Ceph应用
Hadoop是否会被Spark取代?Hadoop生态组件原理解析_spark会取代hadoop吗
赞
踩
Hadoop和Spark都是目前主流的大数据框架,但是随着Spark在速度和易用性方面表现出的优势,一些国内外专家逐渐推崇Spark技术,并且认为Spark才是大数据的未来。本文将会浅析Hadoop生态的发展历程及其中部分组件的技术原理,最终就Hadoop是否会被Spark取代给出结论。
一、Hadoop的核心组件
在对Hadoop核心组件进行介绍之前,我们需要先了解Hadoop解决了什么问题。Hadoop主要就是解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。
Hadoop的核心组件主要有三个,分别是:HDFS、YARN和MapReduce。HDFS是是google三大论文之一的GFS的开源实现,是一个高度容错性的系统,适合部署在廉价的机器上的,适合存储海量数据的分布式文件系统。而YARN是Hadoop的资源管理器,可以视为一个分布式的操作系统平台。相比于HDFS和YARN,MapReduce可以说是Hadoop的核心组件,以下会就MapReduce进行重点讨论。
MapReduce,通过简单的Mapper和Reducer的抽象提供一个编程模型,可以在一个由几十台上百台的PC组成的不可靠集群上并发地,分布式地处理大量的数据集,而把并发、分布式(如机器间通信)和故障恢复等计算细节隐藏起来。而Mapper和Reducer的抽象,又是各种各样的复杂数据处理都可以分解为的基本元素。这样,复杂的数据处理可以分解为由多个Job(包含一个Mapper和一个Reducer)组成的有向无环图(DAG),然后每个Mapper和Reducer放到Hadoop集群上执行,就可以得出结果。

在MapReduce中,Shuffle是一个非常重要的过程,正是有了看不见的Shuffle过程,才可以使在MapReduce之上写数据处理的开发者完全感知不到分布式和并发的存在。
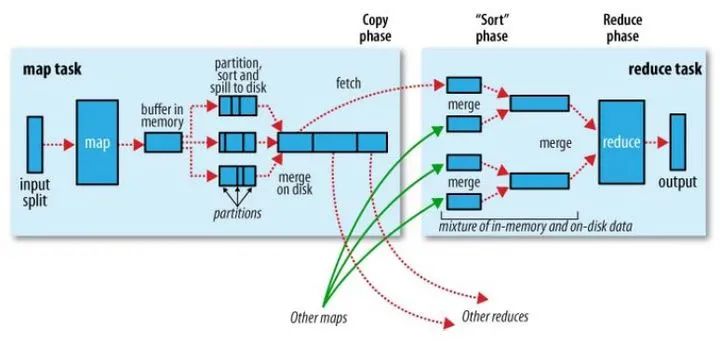
广义的Shuffle是指图中在Map和Reuce之间的一系列过程。
二、Hadoop的局限和改进
尽管Hadoop提供了处理海量数据的能力,但是Hadoop的核心组件——MapReduce的使用问题还是一直困扰着Hadoop的发展,MapReduce的局限主要可以总结为以下几点:
-
抽象层次低,需要手工编写代码来完成,使用上难以上手
-
只提供两个操作,Map和Reduce,表达力欠缺
-
一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的
-
处理逻辑隐藏在代码细节中,没有整体逻辑
-
中间结果也放在HDFS文件系统中
-
ReduceTask需要等待所有MapTask都完成后才可以开始
-
时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
-
对于迭代式数据处理性能比较差
比如说,用MapReduce实现两个表的Join都是一个很有技巧性的过程,如下图所示: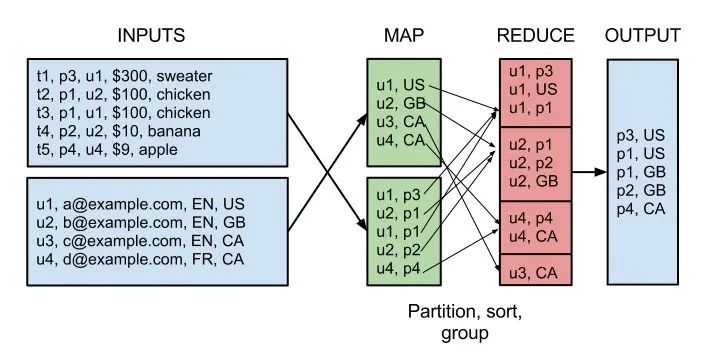
因此,在Hadoop推出之后,出现了很多相关的技术对其中的局限进行改进,如Pig,Cascading,JAQL,OOzie,Tez,Spark等,

