
- 1Spring Boot 启动成功,但是无法访问 Controller 里面的方法_springboot进不去controller
- 2keras: Data Load & Data Preprocessing_keras data dataloader
- 3vue-element-admin $notify 内容过长不自动换行的问题_$notify数据过长换行
- 4小米游戏本bios_年轻人的第一台游戏本?——小米游戏本2019评测
- 5逻辑运算符
- 6爬虫遇到网页审查元素(开发者工具)打不开怎么办?_爬虫无权访问开发者工具
- 7汽车多重定位,实时定位追踪,远程查看汽车运行轨迹_lbs轨迹实时定位
- 8GEE系列:第7单元 利用GEE进行遥感影像分类【随机森林分类】_gee遥感影像分类实习报告
- 9随机森林如何评估特征重要性_随机森林 特征重要性
- 10YOLOv9改进 | 一文带你了解全新的SOTA模型YOLOv9(论文阅读笔记,效果完爆YOLOv8)
《剑指 Offer》专项突破版 - 面试题 65、66 和 67 : 关于前缀树应用的面试题(C++ 实现)
赞
踩
目录
面试题 65 : 最短的单词编码
题目:
输入一个包含 n 个单词的数组,可以把它们编码成一个字符串和 n 个下标。例如,单词数组 ["time", "me", "bell"] 可以编码成一个字符串 "time#bell#",然后这些单词就可以通过下标 [0, 2, 5] 得到。对于每个下标,都可以从编码得到的字符串中相应的位置开始扫描,直到遇到 '#' 字符前所经过的子字符串为单词数组中的一个单词。例如,从 "time#bell#" 下标为 2 的位置开始扫描,直到遇到 '#' 前经过子字符串 "me" 是给定单词数组的第 2 个单词。给定一个单词数组,请问按照上述规则把这些单词编码之后得到的最短字符串的长度是多少?如果输入的是字符串数组 ["time", "me", "bell"],那么编码之后最短的字符串是 "time#bell#",长度是 10。
分析:
如果仔细观察输入的单词数组 ["time", "me", "bell"] 和编码得到的字符串 "time#bell#",就能发现输入的单词有 3 个,但编码之后的字符串中用 '#' 隔开的单词只有两个。单词 "me" 并没有单独出现在编码得到的字符串中。单词 "me" 和单词 "time" 的后半段一样,也就是说,单词 "me" 是单词 "time" 的一个后缀,可以通过下标偏移从 "time" 中得到 "me"。
这个题目的目标是得到最短的编码,因此,如果一个单词 A 是另一个单词的后缀,那么单词 A 在编码字符串中就不需要单独出现,这是因为单词 A 可以通过在单词 B 中偏移下标得到。
前缀树是一种常见的数据结构,它能够很方便地表达一个字符串是另一个字符串的前缀。这个题目是关于字符串的后缀。要把字符串的后缀转换成前缀也比较直观:如果一个字符串 A 是另一个字符串 B 的后缀,分别反转字符串 A 和 B 得到 A' 和 B',那么 A' 是 B' 的前缀。例如,把字符串 "me" 和 "time" 反转得到 "em" 和 "emit","em" 是 "emit" 的前缀。
如果一个字符串是另一个字符串的前缀,那么在前缀树中短字符串对应的路径是长字符串对应的路径的一部分。例如,"time"、"me" 和 "bell" 这 3 个单词反转之后生成的前缀树如下图一所示。
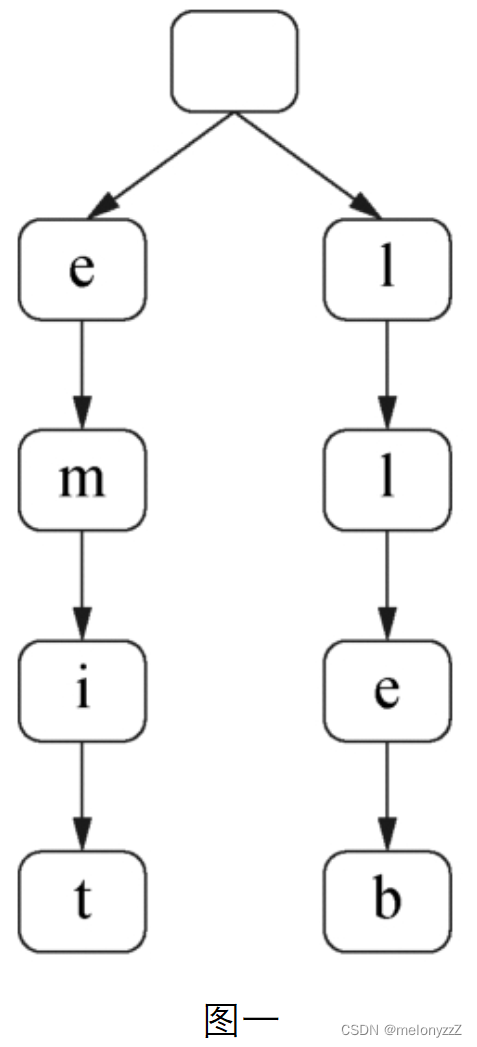
由于作为前缀的单词在最短编码中不单独出现,因此在计算最短编码的长度时前缀单词的长度不用考虑,即它在前缀树中对应的路径的长度也不需要考虑。因此,只需要统计前缀树中从根节点到叶节点的所有路径的长度。例如,"time"、"me" 和 "bell" 这 3 个单词的最短编码 "time#bell#" 中只出现了 "time" 和 "bell",在图一所示的前缀树中,只需要统计路径 e->m->i->t 和 l->l->e->b 的长度。单词 "me" 在前缀树中对应的路径应该忽略。
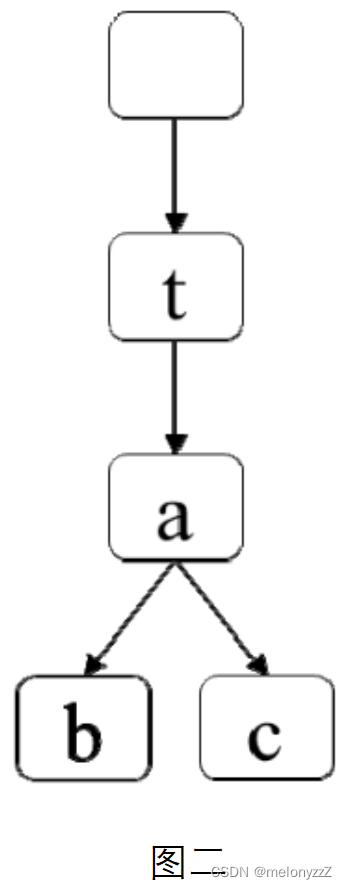
如果两个单词共享前缀,但一个字符串不是另一个字符串的子字符串,那么公共前缀部分在编码中将会出现,在前缀树中统计路径长度时也会重复统计。例如,单词 "at"、"bat" 和 "cat" 的一个最短编码是 "bat#cat#",它的长度为 8。3 个单词可以通过下标 1、0 和 4 得到。这 3 个单词反转之后分别为 "ta"、"tab" 和 "tac",它们的前缀树如下图二所示。虽然单词 "tab" 和 "tac" 共享前缀 "ta",但公共前缀在最短编码中重复出现,单词 "ta" 是 "tab" 或 "tac" 的子字符串,它在最短编码中没有单独出现。因此,在前缀树中统计路径长度时只需要统计 t->a->b 和 t->a->c 的长度。
由于在最短编码之中出现的每个单词之后都有一个字符 '#',因此计算长度时出现的每个单词的长度都要加 1。在前缀树中统计路径长度时,可以统计从根节点到每个叶节点的路径的长度。前缀树的根节点并不对应单词的任何字符,在统计路径时将根节点包括进去相当于将单词的长度加 1。通常用深度优先遍历的算法统计路径的长度。
代码实现:
- struct TrieNode {
- vector<TrieNode*> children;
-
- TrieNode() : children(26, nullptr) {}
- };
-
- class Solution {
- public:
- int minimumLengthEncoding(vector<string>& words) {
- TrieNode* root = buildTrie(words);
-
- int total = 0;
- dfs(root, 1, total);
- return total;
- }
- private:
- TrieNode* buildTrie(vector<string>& words) {
- TrieNode* root = new TrieNode;
- for (string& word : words)
- {
- TrieNode* cur = root;
- for (int i = word.size() - 1; i >= 0; --i)
- {
- int index = word[i] - 'a';
- if (cur->children[index] == nullptr)
- cur->children[index] = new TrieNode;
-
- cur = cur->children[index];
- }
- }
- return root;
- }
-
- void dfs(TrieNode* cur, int length, int& total) {
- bool isLeaf = true;
- for (TrieNode* child : cur->children)
- {
- if (child)
- {
- isLeaf = false;
- dfs(child, length + 1, total);
- }
- }
-
- if (isLeaf)
- total += length;
- }
- };

由于这个题目只关注前缀树的所有从根节点到叶节点的路径的长度,并不需要查找单词,因此并不需要知道哪些节点对应一个单词的最后一个字符,上述代码中表示前缀树节点的类型 TrieNode 中没有字段 isWord。
面试题 66 : 单词之和
题目:
请实现一个类型 MapSum,它有如下两个操作。
-
函数 insert,输入一个字符串和一个整数,在数据集合中添加一个字符串及其对应的值。如果数据集合中已经包含该字符串,则将字符串对应的值替换成新值。
-
函数 sum,输入一个字符串,返回数据集合中所有以该字符串为前缀的字符串对应的值之和。
例如,第 1 次调用函数 insert 添加字符串 "happy" 和它的值 3,此时如果输入 "hap" 调用函数 sum 则返回 3。第 2 次调用函数 insert 添加字符串 "happen" 和它的值 2,此时如果输入 "hap" 调用函数 sum 则返回 5。
分析:
在这个题目中,每个字符串和一个整数值对应,存在从字符串到值的映射,看起来可以用哈希表类型 unordered_map 解决。但在 unordered_map 中只能实现一对一的查找,即根据一个完整的字符串查找它对应的值,无法找到以某个前缀开头的所有字符串及其对应的值。
既然需要根据字符串的前缀进行查找,就可以使用前缀树。首先定义前缀树节点的数据结构。由于每个字符串对应一个数值,因此需要在节点中增加一个整数字段。如果一个节点对应一个字符串的最后一个字符,那么该节点的整数字段的值就设为字符串对应的值;如果一个节点对应字符串的其他字符,那么该节点的整数字段将被设为 0。由于这个题目只关注所有以输入的字符串为前缀的字符串对应的值之和,这些值已经在节点中的整数字段得以体现,因此节点中没有必要包含一个布尔变量标识节点是否对应字符串的最后一个字符。
- struct TrieNode {
- vector<TrieNode*> children;
- int value;
-
- TrieNode() : children(26, nullptr), value(0) {}
- };
接下来考虑 MapSum 的成员函数 insert。在前缀树中添加字符串的过程和之前类型,唯一和之前不同的是,当到达字符串最后一个字符对应的节点时,将该节点的 value 字段的值设为字符串对应的值。
最后考虑 MapSum 的成员函数 sum。当输入一个前缀在前缀树中查找时,可以在前缀树中逐个查找和前缀中每个字符对应的节点。如果当扫描到字符串的某个字符时前缀树中已经没有节点与之对应,那么前缀树中没有以该前缀开头的字符串,直接返回 0。
如果一直到字符串的最后一个字符前缀树都有节点与其对应,那么前缀树中存在若干以该前缀开头的字符串。在前缀树中查找前缀的所有字符之后,处在的节点对应前缀的最后一个字符,以该前缀开头的所有字符的后序字符对应的节点都在当前所处节点的子树中,可以遍历整个子树找出所有以前缀开头的字符串。
- class MapSum {
- public:
- MapSum() : root(new TrieNode) {}
-
- void insert(string key, int val) {
- TrieNode* cur = root;
- for (char ch : key)
- {
- int index = ch - 'a';
- if (cur->children[index] == nullptr)
- cur->children[index] = new TrieNode;
-
- cur = cur->children[index];
- }
- cur->value = val;
- }
-
- int sum(string prefix) {
- TrieNode* cur = root;
- for (char ch : prefix)
- {
- int index = ch - 'a';
- if (cur->children[index] == nullptr)
- return 0;
-
- cur = cur->children[index];
- }
- return getSum(cur);
- }
- private:
- int getSum(TrieNode* cur) {
- if (cur == nullptr)
- return 0;
-
- int result = cur->value;
- for (TrieNode* child : cur->children)
- {
- if (child)
- result += getSum(child);
- }
- return result;
- }
- private:
- TrieNode* root;
- };
面试题 67 : 最大的异或
题目:
输入一个整数数组(每个数字都大于或等于 0),请计算其中任意两个数字的异或的最大值。例如,在数组 [1, 3, 4, 7] 中,3 和 4 的异或结果最大,异或结果为 7。
分析:
这个题目的蛮力法不难想到。如果找出数组中所有可能由两个数字组成的数对并求出它们的异或,通过比较就能得出最大的异或值。如果整数数组的长度为 n,那么这种直观的算法的时间复杂度是 O(n^2)。
接下来尝试找到更好的解法。整数的异或有一个特点:两个相同数位异或的结果是 0,两个相反数位异或的结果是 1。如果想找到某个整数 k 和其他整数的最大异或值,那么尽量找和 k 的数位不同的整数。
因此,这个问题可以转换为查找的问题,而且还是按照整数的二进制数位进行查找的问题。需要将整数的每个数位都保存下来。前缀树可以实现这种思路,前缀树中除根节点外的每个节点对应整数的一个数位,路径对应一个整数。
由于每个节点只有两个分别表示 0 和 1 的子节点,因此前缀树节点的数据结构可以定义为如下的形式:
- struct TrieNode {
- vector<TrieNode*> children;
-
- TrieNode() : children(2, nullptr) {}
- };
由于整数都是 32 位,它们在前缀树中对应的路径的长度都是一样的,因此没有必要用一个布尔值字段标记最后一个数位。
然后创建一棵能够保存整数的前缀树,这和保存字符串的前缀树类似。从左到右逐一取出整数的每个数位,并根据值 0 或 1 在必要的时候创建新的节点。创建前缀树的参考代码如下所示:
- TrieNode* buildTrie(vector<int>& nums) {
- TrieNode* root = new TrieNode;
- for (int num : nums)
- {
- TrieNode* cur = root;
- for (int i = 31; i >= 0; --i)
- {
- int bit = (num >> i) & 1;
- if (cur->children[bit] == nullptr)
- cur->children[bit] = new TrieNode;
-
- cur = cur->children[bit];
- }
- }
- return root;
- }
最后考虑如何基于前缀树的查找计算最大的异或值。从高位开始扫描整数 num 的每个数位。如果前缀树中存在某个整数的相同位置的数位和 num 的数位相反,则优先选择这个相反的数位,这是因为两个相反的数位异或的结果为 1,比两个相同的数位异或的结果大。按照优先选择与整数 num 相反的数位的规则就能找出与 num 异或最大的整数。
计算最大异或值的参考代码如下所示:
- int findMaximumXOR(vector<int>& nums) {
- TrieNode* root = buildTrie(nums);
-
- int max = 0;
- for (int num : nums)
- {
- TrieNode* cur = root;
- int XOR = 0;
- for (int i = 31; i >= 0; --i)
- {
- int bit = (num >> i) & 1;
- if (cur->children[1 - bit])
- {
- XOR = (XOR << 1) + 1;
- cur = cur->children[1 - bit];
- }
- else
- {
- XOR = XOR << 1;
- cur = cur->children[bit];
- }
- }
-
- if (XOR > max)
- max = XOR;
- }
- return max;
- }
函数 buildTrie 和 findMaximumXOR 都有两层循环。第 1 层循环逐个扫描数组中的每个整数,而第 2 层循环的执行次数是 32,是一个常数。如果数组 nums 的长度为 n,那么这种算法的时间复杂度是 O(n)。

