
- 1使用 Fiddler 抓包PC微信小程序_fiddler 可以抓到微信的请求地址嘛
- 2实用攻略:云服务器如何选购?要考虑哪些因素?超详细!(上)_业务云服务器怎么选购集群
- 3探索Web中的颜色选择:不同取色方法的实现
- 4使用docker快速搭建openvpn
- 5Local to local copy not supported
- 6基于JavaScript在Web端用Cesium加载自己的点云数据_cesium加载点云数据
- 7C++ replace() 函数用法_c++ replace函数怎么用
- 8前端面试八股文(详细版)— 下_前端八股文pdf
- 9Kubernetes 集群疑难杂症排障:服务器 IP 变更后集群故障了,我该如何修复?
- 102024年AI辅助研发:科技变革的引擎
2023年JAVA最新面试题_2023java面试题
赞
踩
2023年JAVA最新面试题
- 1 JavaWeb基础
- 1.1 HashMap的底层实现原理?
- 1.2 HashMap 和 HashTable的异同?
- 1.2 HashMap的线程不安全主要体现在下面两个方面:
- 1.3 Collection 和 Collections的区别?
- 1.4 Collection和Map接口的区别
- 1.5 ArrayList、LinkedList的异同?
- 1.6 HashMap怎么解决hash冲突
- 1.7 String、StringBuffer、StringBuilder三者的对比
- 1.8 String长度为什么不可变
- 1.9 JDK1.8新增的功能
- 1.10 字符流和字节流
- 1.11 序列化和反序列化
- 1.12 多线程有几种实现方法,都是什么?同步有几种实现方法,都是什么?
- 1.13 创建线程安全(arraylist为例)
- 1.14 创建对象除了new 还有什么方式?
- 1.15 什么是死锁?死锁产生的必要条件?怎么避免死锁?
- 1.16 Java 中常用的设计模式?说明工厂模式?
- 1.17 什么是线程安全
- 1.18 并行与并发的理解
- 1.19 重载和重写的区别
- 1.20 数组的排序算法
- 1.21 截取字符串
- 1.22 Lock锁
- 1.23 synchronized重锁以及减轻方案
- 1.24 List去重
- 2 Spring相关框架
- 2.1 在Spring中AOP有了解吗
- 2.2 Spring AOP和AspectJ AOP有什么区别?
- 2.3 谈谈你对SpringBoot的理解
- 2.4 Spring里面Controller 中(SpringMVC表现层)的注解
- 2.5 SpringBoot的常用注解
- 2.6 异常类的基类
- 2.7 SVN和Git区别?
- 2.8 Maven的打包方式有几种
- 2.9 MyBatis如何实现多表查询
- 2.10 Nagix的理解
- 2.11 nagix中能否多个服务器共用80端口?
- 2.11 nagix负载均衡
- 2.12 Redis是什么?优点是什么
- 2.13 Redis的事务机制
- 2.14 CPU占用过高,分析定位到哪一行代码存在bug
- 2.15 MyBatis中的缓存机制
- 2.16 MyBatis中#{ }和${ } 区别
- 2.17 文件上传下载的框架
- 3 SQL相关
1 JavaWeb基础
1.1 HashMap的底层实现原理?
HashMap的底层实现原理?以jdk7为例说明:
HashMap map = new HashMap();
在实例化以后,底层创建了长度是16的一维数组Entry[] table。 可能已经执行过多次put, map.put(key1,value1):
- 首先调用
key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存放位置。- 如果此位置上的数据为空,此时的
key1-value1添加成功。 ----情况1 - 如果此位置上的数据不为空,(意味着此位置上存在一个或多个数据(以链表形式存在))
比较key1和已经存在的一个或多个数据的哈希值:- 如果
key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。----情况2 - 如果
key1的哈希值和已经存在的某一个数据(key2-value2)的哈希值相同,继续比较:调用key1所在类的equals(key2)方法,比较:- 如果
equals()返回false:此时key1-value1添加成功。----情况3 - 如果
equals()返回true:使用value1替换value2。 - 补充:关于情况2和情况3:此时
key1-value1和原来的数据以链表的方式存储。
- 如果
- 如果
- 如果此位置上的数据为空,此时的
在不断的添加过程中,会涉及到扩容问题,当超出临界值(且要存放的位置非空)时,扩容。默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
jdk8 相较于jdk7在底层实现方面的不同:
-
new HashMap():jdk8底层没有创建一个长度为16的数组
-
jdk8底层的数组是:Node[],而非Entry[]
-
- 首次调用
put()方法时,底层创建长度为16的数组
- 首次调用
-
- jdk7底层结构只有:数组+链表。
jdk8中底层结构:数组+链表+红黑树。
- 4.1 形成链表时,七上八下(
jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素) - 4.2
jdk8中当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16 DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75 threshold:扩容的临界值,=容量*填充因子:16 * 0.75 => 12 TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8 MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64- 1
- 2
- 3
- 4
- 5
- jdk7底层结构只有:数组+链表。
1.2 HashMap 和 HashTable的异同?
HashMap:作为Map的主要实现类;线程不安全的,效率高;存储null的key和value,扩容的话是原来的二倍
Hashtable:作为古老的实现类;线程安全的,效率低;不能存储null的key和value
扩容的话是原来的二倍+1
Propertie:常用来处理配置文件。key和value都是String类型
HashMap的底层:数组+链表 (jdk7及之前) , 数组+链表+红黑树 (jdk 8)
相同点:
(1) 都是java.util包下的类
(2) 都实现了Map接口,存储方式都是key-value形式
(3) 同时也都实现了Serializable和Cloneable接口
(4) 负载因子都是0.75
负载因子(loadFactor):
当我们第一次创建 HashMap 的时候,就会指定其容量(如果未明确指定,默认是 16),随着我们不断的向 HashMap 中 put 元素的时候,就有可能会超过其容量,那么就需要有一个扩容机制。 所谓扩容,就是扩大 HashMap 的容量,在向 HashMap中添加元素过程中,如果 元素个数(size)超过临界值(threshold)的时候,就会进行自动扩容(resize),并且,在扩容之后,还需要对 HashMap 中原有元素进行rehash,即将原来桶中的元素重新分配到新的桶中。
在 HashMap 中,临界值(threshold) = 负载因子(loadFactor) * 容量(capacity)。 loadFactor 是装载因子(负载因子),表示 HashMap 满的程度,默认值为 0.75f,也就是说默认情况下,当 HashMap 中元素个数达到了容量的 3/4 的时候就会进行自动扩容。
不同点:
(1) HashMap是非线程安全,效率高;HashTable是线程安全的,效率低
(2) HashMap允许null作为键或值,HashTable不允许,运行时会报NullPointerException
(3) HashMap添加元素使用的是自定义hash算法,HashTable使用的是key的hashCode
(4) HashMap在数组+链表的结构中引入了红黑树,HashTable没有
(5) HashMap初始容量为16,HashTable初始容量为11
(6) HashMap扩容是当前容量翻倍,HashTable是当前容量翻倍+1
(7) HashMap只支持Iterator遍历,HashTable支持Iterator和Enumeration
(8) HashMap与HashTable的部分方法不同,比如HashTable有contains方法。
1.2 HashMap的线程不安全主要体现在下面两个方面:
- 在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
- 在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
1.3 Collection 和 Collections的区别?
相同点:两者都可以在java.util包的类
不同点:
- Collection是接口
- Collections是工具类
1.4 Collection和Map接口的区别
-
Collection接口:单列集合,用来存储一个一个的对象
-
List接口:存储有序的、可重复的数据。 -->“动态”数组,替换原的数组
- ArrayList:作为List接口的主要实现类;线程不安全的,效率高;底层使用
Object[ ] elementData存储,适用于查找频繁。 - LinkedList:线程不安全的。对于频繁的插入、删除操作,使用此类效率比
ArrayList高;底层使用双向链表存储 - Vector:作为List接口的古老实现类;线程安全的,效率低;底层使用
Object[ ] elementData存储
- ArrayList:作为List接口的主要实现类;线程不安全的,效率高;底层使用
-
Set接口:存储无序的、不可重复的数据 -->高中讲的“集合”(无序互斥)
- HashSet:作为
Set接口的主要实现类;线程不安全的;可以存储null值 - LinkedHashSet:作为
HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历
在添加数据的同时,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。 对于频繁的遍历操作,LinkedHashSet效率高于HashSet。 - TreeSet:可以照添加对象的指定属性,进行排序。
- HashSet:作为
-
-
Map:双列数据,存储
key-value对的数据 —类似于高中的函数:y = f(x)- HashMap:作为Map的主要实现类;线程不安全的,效率高;存储
null的key和value扩容的话是原来的二倍 - LinkedHashMap:保证在遍历
map元素时,可以照添加的顺序实现遍历。
原因:在原的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。
对于频繁的遍历操作,此类执行效率高于HashMap。 - TreeMap:保证照添加的
key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序
底层使用红黑树 - HashTable:作为古老的实现类;线程安全的,效率低;不能存储
null的key和value扩容的话是原来的二倍+1 - Properties:常用来处理配置文件。
key和value都是String类型
- HashMap:作为Map的主要实现类;线程不安全的,效率高;存储
1.5 ArrayList、LinkedList的异同?
ArrayList和LinkedList的异同
相同点:
- 都实现了List接口, 都是存储有序、可重复的数据
- 二者都线程不安全,相对线程安全的Vector,执行效率高。
- ArrayList基于动态数组的数据结构,LinkedList基于链表的数据结构。
不同点
- 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add(特指插入)和remove,LinkedList比较占优势,因为ArrayList要移动数据。
1.6 HashMap怎么解决hash冲突
(1)什么是hash冲突?
哈希算法被计算的数据是无限的,而计算后的结果范围有限,所以总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突
(2)HashMap如何解决hash冲突?
- 线性探测法
也称为开放定址法,就是从发生冲突的那个位置开始,按照一定的次序从hash表中找到一个空闲的位置,然后把发生冲突的元素存入到这个空闲位置中。 - 链式寻址法
这是一种非常常见的方法,简单理解就是把存在hash冲突的key,以单向链表的方式来存储,比如HashMap就是采用链式寻址法来实现的。 - 再hash法
就是当通过某个hash函数计算的key存在冲突时,再用另外一个hash函数对这个key做hash,一直运算直到不再产生冲突。这种方式会增加计算时间,性能影响较大。 - 建立公共溢出区
就是把hash表分为基本表和溢出表两个部分,凡事存在冲突的元素,一律放入到溢出表中。
1.7 String、StringBuffer、StringBuilder三者的对比
String:不可变的字符序列;底层使用char[ ]存储StringBuffer:可变的字符序列;线程安全的,效率低;底层使用char[]存储StringBuilder:可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[]存储
1.8 String长度为什么不可变
(1)不可变性:当你给一个字符串重新赋值之后,老值并没有在内存中销毁,而是重新开辟一块空间存储新值。
(2)String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[ ],所以String 对象是不可变的。
(3)线程安全
1.9 JDK1.8新增的功能
- 1、Lambda表达式和函数式接口
Lambda表达式也称为闭包,是Java 8中最大和最令人期待的语言改变。它允许我们将函数当成参数传递给某个方法,或者把代码本身当作数据处理,这就是典型的函数式开发。最简单的Lambda表达式可由逗号分隔的参数列表、-> 符号和语句块组成。
在Lambda表达式中,将其划分了几块。这一行就是
lambda表达式。
() -> System.out.println(“使用Lambda表达式”);下面我们对lambda的格式进行一个介绍:(1)左边括号:
lambda的形参列表,就好比是我们定义一个接口,里面有一个抽象方法,这个抽象方法的形参列表。(2)箭头:
lambda的操作符,所以你看见这个箭头心中知道这是一个lambda表达式就可以了。(3)右边
lambda体:就好比是我们实现了接口中的抽象方法。
-
2、接口的默认方法和静态方法
默认方法使得开发者可以在不破坏二进制兼容性的前提下,往现存接口中添加新的方法,即不强制那些实现了该接口的实现类也同时实现这个新添加的方法。
简单说,默认方法就是接口可以有实现方法,而且不需要实现类去实现其方法。 -
3、方法引用
方法引用使得开发者可以直接引用现存的方法、Java类的构造方法或者实例对象。方法引用和Lambda表达式配合使用,使得java类的构造方法看起来更加紧凑简洁,减少冗余代码。
方法引用通过方法的名字来指向一个方法
方法引用使用一对冒号 ::public class Test { public static void main(String[] args) { //传统的方式来实现MyFunction/得到一个实现接口的对象 可以使用 //匿名内部类 //MyFunction<Desk, String> hf = new MyFunction<Desk, String>() { // @Override // public String apply(Desk desk) { // return "hello desk"; // } //}; //String val = hf.apply(new Desk()); //System.out.println("val-" + val); MyFunction<Desk,String> hf2 = Desk::getBrand; String val2 = hf2.apply(new Desk()); System.out.println("val2-" + val2);//这里输出结果就是val2-北京牌 } } //定义一个函数式接口: 有且只有一个抽象方法的接口 //我们可以使用@FunctionalInterface 来标识一个函数式接口 //MyFunction是一个函数式接口 (是自定义泛型接口) @FunctionalInterface interface MyFunction<T, R> { R apply(T t); //抽象方法: 表示根据类型T的参数,获取类型R的结果 //public void hi(); //函数式接口,依然可以有多个默认实现方法 default public void ok() { System.out.println("ok"); } } @FunctionalInterface interface MyInterface { public void hi(); } class Desk { //Bean private String name = "my desk"; private String brand = "北京牌"; private Integer id = 10; //getter setter tostring 方法 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
-
4、重复注解
在Java 5中使用注解有一个限制,即相同的注解在同一位置只能声明一次,Java 8引入重复注解,这样相同的注解在同一地方也可以声明多次;Java 8在编译器层做了优化,相同注解会以集合的方式保存,因此底层的原理并没有变化。 -
5、扩展注解的支持
Java 8扩展了注解的上下文,几乎可以为任何东西添加注解,包括局部变量、泛型类、父类与接口的实现,连方法的异常也能添加注解。 -
6、Optional类
Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Java应用中最常见的bug就是空指针异常,Optional 类的引入很好的解决空指针异常,从而避免源码被各种null检查污染,以便开发者写出更加整洁的代码。 -
7、Stream(流)
什么是 Stream?
Stream API(java.util.stream)是把真正的函数式编程风格引入到Java库中,这是目前为止最大的一次对Java库的完善,以便开发者能够写出高效率、干净、简洁的代码。其实简单来说可以把Stream理解为MapReduce,当然Google的MapReduce的灵感也是来自函数式编程,它其实是一连串支持连续、并行聚集操作的元素,从语法上看,也很像linux的管道、或者链式编程,代码写起来简洁明了!
Stream(流)是一个来自数据源的元素队列并支持聚合操作,Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对
Java 集合运算和表达的高阶抽象。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选,
排序,聚合等。元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal
operation)得到前面处理的结果
-
8、日期时间 API
Java 8通过发布新的Date-Time API (JSR 310)来进一步加强对日期与时间的处理。在旧版的 Java 中,日期时间 API 存在诸多问题,其中有:
非线程安全 java.util.Date 是非线程安全的,所有的日期类都是可变的,这是Java日期类最大的问题之一。
设计很差 Java的日期/时间类的定义并不一致,在java.util和java.sql的包中都有日期类,此外用于格式化和解析的类在java.text包中定义。java.util.Date同时包含日期和时间,而java.sql.Date仅包含日期,将其纳入java.sql包并不合理。另外这两个类都有相同的名字,这本身就是一个非常糟糕的设计。
时区处理麻烦 日期类并不提供国际化,没有时区支持,因此Java引入了java.util.Calendar和java.util.TimeZone类,但他们同样存在上述所有的问题。
Java8 在 java.time 包下提供了很多新的 API,新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。以下仅介绍两个比较重要的 API:- Local(本地): 简化了日期时间的处理,没有时区的问题。
- Zoned(时区) : 通过制定的时区处理日期时间。
-
9、JavaScript引擎Nashorn
从 JDK 1.8 开始,Nashorn取代Rhino(JDK 1.6, JDK1.7) 成为 Java 的嵌入式 JavaScript 引擎。Nashorn 完全支持 ECMAScript 5.1 规范以及一些扩展,它使用基于 JSR 292 的新语言特性,其中包含在 JDK 7 中引入的 invokedynamic,将 JavaScript 编译成 Java 字节码,与先前的 Rhino 实现相比,这带来了 2 到 10倍的性能提升。
Nashorn的主要用途:允许在JVM上开发运行JavaScript应用,允许Java与JavaScript相互调用。 -
10、Base64
在Java 8中,Base64编码成为了Java类库的标准。Base64类同时还提供了对URL、MIME友好的编码器与解码器。
除了这十大新特性之外,还有另外的一些新特性: -
11、更好的类型推测机制:
Java 8在类型推测方面有了很大的提高,这就使代码更整洁,不需要太多的强制类型转换了。 -
12、编译器优化:
Java 8将方法的参数名加入了字节码中,这样在运行时通过反射就能获取到参数名,只需要在编译时使用-parameters参数。 -
13、并行(parallel)数组:
支持对数组进行并行处理,主要是parallelSort()方法,它可以在多核机器上极大提高数组排序的速度。 -
14、并发(Concurrency):
在新增Stream机制与Lambda的基础之上,加入了一些新方法来支持聚集操作。 -
15、Nashorn引擎jjs:
基于Nashorn引擎的命令行工具。它接受一些JavaScript源代码为参数,并且执行这些源代码。 -
16、类依赖分析器jdeps:
可以显示Java类的包级别或类级别的依赖。 -
17、JVM的PermGen空间被移除:
取代它的是Metaspace(JEP 122)。
1.10 字符流和字节流
- 字符流 getWriter(): 常用于回传字符串(常用)
- 字节流 getOutputStream():常用于下载(传递二进制数据)
两个流同时只能使用一个。 使用了字节流,就不能再使用字符流,反之亦然,否则就会报错
1.11 序列化和反序列化
- 序列化:将 Java 对象转换成字节流的过程
- 反序列化:将字节流转换成 Java 对象的过程。
为什么需要序列化与反序列化?
当两个进程进行远程通信时,可以相互发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。当两个
Java 进程进行通信时,需要 Java 序列化与反序列化实现进程间的对象传送。换句话说,一方面,发送方需要把这个 Java
对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出 Java 对象。
优点:
- 实现了数据的持久化,序列化可以把数据永久地保存到硬盘上(通常存放在文件里)。
- 通过序列化以字节流的形式使对象在网络中进行传递和接收。
- 通过序列化在进程间传递对象。
1.12 多线程有几种实现方法,都是什么?同步有几种实现方法,都是什么?
多线程有两种实现方法,
- 继承Thread 类
- 实现Runnable 接口,
同步的实现方面有两种
- synchronized,wait
- notify。
1.13 创建线程安全(arraylist为例)
在线程上添加锁。Lock 或者synchronized 可以将线程不安全变为线程安全,
Lock 能完成synchronized 所实现的所有功能;
Collections.synchronizedList();也能实现线程安全
主要不同点:
- Lock 有比synchronized 更精确的线程语义和更好的性能。
- synchronized 会自动释放锁,而Lock 一定要求程序员手工释放,并且必须在finally 从句中释放。
1.14 创建对象除了new 还有什么方式?
-
使用
new关键字 -
Class对象的newInstance()方法
Class的newInstance()方法可以在运行时创建一个类的新实例。它等效于使用new操作符,但是语法更加动态。 -
构造函数对象的
newInstance()方法
Constructor的newInstance()方法可以在运行时创建一个类的新实例,并且可以传入构造函数的参数。这种方式比Class的newInstance()方法更加灵活,因为可以选择不同的构造函数。 -
对象反序列化
反序列化是将对象从字节流中恢复的过程。通过序列化后,可以把对象存储到文件或网络中,然后再通过反序列化的方式恢复成对象。 -
Object对象的clone()方法
clone( )方法可以创建对象的一个副本,并且可以重写clone()方法来实现深克隆。 -
使用工厂模式
可以将对象的创建和使用解耦。通过定义一个对象工厂,可以更加灵活地产生对象。
1.15 什么是死锁?死锁产生的必要条件?怎么避免死锁?
1)死锁定义:
死锁是指两个或多个进程在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
2)产生死锁的必要条件
- 互斥条件:进程要求对所分配的资源(如打印机)在一段时间内仅为一个进程所占有。此时若有其他进程请求该资源,则请求进程只能等待。
- 不可剥夺条件:进程所获得的资源在未使用完毕之前,不能被其他进程强行夺走,即只能由获得该资源的进程自己来释放(只能是主动释放)。
- 请求和保持条件:进程已经保持了至少一个资源,但又提出了新的资源请求,而该资源已被其他进程占有,此时请求进程被阻塞,但对自己已获得的资源保持不放。
- 循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被链中下一个进程所请求。
3)怎么避免死锁
- 如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可以大大降低死锁机会。
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率。
- 对于非常容易产生死锁的业务部分,可以尝试使用升级锁定颗粒度,通过表级锁定来减少死锁产生的概率。
- 如果业务处理不好,可以用分布式事务锁或者使用乐观锁。
1.16 Java 中常用的设计模式?说明工厂模式?
答:Java 中的23 种设计模式:Builder( 建造模式),Factory( 工厂模式),Factory Method(工厂方法模式),Prototype(原始模型模式),Singleton(单例模式),Facade(门面模式),Adapter(适配器模式), Bridge(桥梁模式), Composite(合成模式),Decorator(装饰模式), Flyweight(享元模式), Proxy(代理模式),Command(命令模式), Interpreter(解释器模式), Visitor(访问者模式),Iterator(迭代子模式), Mediator(调停者模式), Memento(备忘录模式),Observer(观察者模式),State(状态模式),Strategy(策略模式),Template Method(模板方法模式), Chain Of Responsibleity(责任链模式)。
工厂模式:
根据工厂模式实现的类可以根据提供的数据生成一组类中某一个类的实例,通常这一组类有一个公共的抽象父类并且实现了相同的方法,但是这些方法针对不同的数据进行了不同的操作。
首先需要定义一个基类,该类的子类通过不同的方法实现了基类中的方法。然后需要定义一个工厂类,工厂类可以根据条件生成不同的子类实例。当得到子类的实例后,开发人员可以调用基类中的方法而不必考虑到底返回的是哪一个子类的实例。
1.17 什么是线程安全
如果一段代码可以保证多个线程访问的时候正确操作共享数据,那么它是线程安全的。
当多个线程访问一个对象时,如果不用考虑这些线程在运行时环境下的调度和交替执行,也不需要进行额外的同步,或者在调用方进行任何其他的协调操作,调用这个对象的行为都可以获得正确的结果,那这个对象就是线程安全的。
1.18 并行与并发的理解
- 并行:多个CPU同时执行多个任务。比如:多个人同时做不同的事。
- 并发:一个CPU(采用时间片)同时执行多个任务。比如:秒杀、多个人做同一件事
1.19 重载和重写的区别
二者都是java多态的体现
(1) 重载:
两同一不同:同一个类里面、相同方法名
参数列表不同:参数个数不同,参数类型不同
(2)重写
子类重写父类的方法。
1.20 数组的排序算法
- 选择排序:
直接选择排序,堆排序 - 交换排序
冒泡排序、快速排序 - 插入排序
直接插入排序,折半插入排序,Shell排序 - 归并排序
桶式排序、基数排序
1.21 截取字符串
- 通过substring()截取字符串
-
只传入一个参数 substring(int beginIndex)
传一个参数,含义为将字符串从索引号为beginIndex开始截取,一直到字符串末尾。注意第一个字符的索引值为零,截取时包含索引beginIndex的字符;示例代码如下:String oldStr = "zifu截取练习ing"; String str = oldStr.substring(5); System.out.println(str); 运行结果: 取练习ing- 1
- 2
- 3
- 4
- 5
-
传入两个参数 substring(int beginIndex, int endIndex)
从索引号beginIndex开始到索引号endIndex结束,返回结果包含索引为beginIndex的字符,不包含索引endIndex的字符;String oldStr = "zifu截取练习ing"; String str = oldStr.substring(0,5); System.out.println(str); 运行结果: zifu截- 1
- 2
- 3
- 4
- 5
- 6
-
- 通过split()切割字符串,返回结果为字符串数组
-
只传一个参数:split(String regex)
参数支持正则或普通字符,根据给定正则表达式或字符匹配拆分此字符串。示例代码如下:String oldStr = "China,Japan,美国,俄罗斯"; String[] strs = oldStr.split(",");//根据,切分字符串 for(int i = 0;i < strs.length; i++){ System.out.println(strs[i]); }- 1
- 2
- 3
- 4
- 5
- 6
-
传入两个参数:split(String regex,int limit)
regex正则表达式分隔符。limit 分割的份数。根据正则表达式或者字符和想要分割的份数来拆分此字符串。示例代码如下:String oldStr = "China,Japan,美国,俄罗斯"; String[] strs = oldStr.split(",",2);//根据,切分字符串;切两份 for(int i = 0;i < strs.length; i++){ System.out.println(strs[i]); } //运行结果: //China //Japan,美国,俄罗斯- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
1.22 Lock锁
1.23 synchronized重锁以及减轻方案
1.24 List去重
借鉴文章:List元素去重的六种方式
1、借助Set的特性进行去重
由于Set的特性是无需且不可重复,我们利用这个特性进行两部操作
(1)把list放入set中
(2)把set还回list里
public static List<String> distinct(List<String> list) {
List doubleList = new ArrayList();
if(list.size()>0&&list != null){ //判断传入的list是否为空
Set set = new HashSet(); //新建一个HashSet
set.addAll(list); //list里的所有东西放入set中 进行去重
doubleList.addAll(set); //把去重完的set重新放回list里
}
return doubleList;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
原:22 11 33 55 66 22 33 66
去重后:22 11 33 55 66
2、利用LinkedHashSet集合去重
经过验证之后发现,LinkedHashSet虽然可以去重,但是根据他的特性,他不能对数据进行排序,只能维持原来插入时的秩序
public static List<String> delRepeat1(List<String> list) {
List<String> listNew2 = new ArrayList<String>(new LinkedHashSet<String>(list));
return listNew2;
}
- 1
- 2
- 3
- 4
原:22 11 33 55 66 22 33 66
去重后:22 11 33 55 66
3、使用list.contains()对全部元素进行判断
为了探究contains()方法的作用,我特意用List和String两种类型分别尝试了一下
结果长这样
String aaa = "aaa"; //声明一个String
String aa = "aa"; //再声明一个不同的String
boolean b = aaa.contains(aa); //比较一下 结果为true
List<String> listA = new ArrayList<String>(); //新建一个list
listA.add("aaa"); //添加一个String类型的元素
boolean b = listA.contains("aa"); //比较一下 结果为false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
String类型会判断字符串里是否有相同的部分
List里则会判断是否有相同的元素
有了这样的结果,我们就可以用list.contains()的方法进行判断,然后将其添加到新的list当中,元素的顺序不发生改变
public static List<String> delRepeat(List<String> list) {
List<String> listNew = new ArrayList<String>();
for (String str : list) {
if (!listNew.contains(str)) {
listNew.add(str);
}
}
return listNew ;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
原:22 11 33 55 66 22 33 66
去重后:22 11 33 55 66
4、使用Java8特性去重
这部分没有深究,大概意思就是把list集合->Stream流,然后对流用distinct()去重,再用collect()收集
public static List<String> delRepeat(List<String> list) {
List<String> myList = list.stream().distinct().collect(Collectors.toList());
return myList ;
}
- 1
- 2
- 3
- 4
原:22 11 33 55 66 22 33 66
去重后:22 11 33 55 66
5、使用list自身方法remove()–>不推荐
如果你的list里存的比较复杂,是一个List<Map<String,Object>>格式的情况,最无奈之举就是这种方法
主要操作是将同一个list用两层for循环配合.equals()方法,有相同的就用remove()方法剔除掉,然后得到一个没有重复数据的list
public static List<Map<String, Object>> distinct(List<Map<String, Object>> list) {
if (null != list && list.size() > 0) {
//循环list集合
for ( int i = 0 ; i < list.size() - 1 ; i ++ ) {
for ( int j = list.size() - 1 ; j > i; j -- ) {
// 这里是对象的比较,如果去重条件不一样,在这里修改即可
if (list.get(j).equals(list.get(i))) {
list.remove(j);
}
}
}
}
//得到最新移除重复元素的list
return list;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2 Spring相关框架
2.1 在Spring中AOP有了解吗
SSM学习笔记—AOP详解
AOP作用:
AOP(Aspect-Oriented Programming,面向切面编程)能在不改变原来代码的情况下对程序的某些功能进行增强。降低模块间的耦合度,提升代码的可读性和可维护性。在Spring中事务处理、日志管理、权限控制等场景用到了AOP原理。
Spring AOP是基于动态代理的,如果要代理的对象实现了某个接口,那么Spring AOP就会使用JDK动态代理去创建代理对象;而对于没有实现接口的对象,就无法使用JDK动态代理,转而使用CGlib动态代理生成一个被代理对象的子类来作为代理。当然也可以使用AspectJ,Spring AOP中已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。使用AOP之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样可以大大简化代码量。我们需要增加新功能也方便,提高了系统的扩展性。日志功能、事务管理和权限管理等场景都用到了AOP。
2.2 Spring AOP和AspectJ AOP有什么区别?
- Spring AOP是属于运行时增强,而AspectJ是编译时增强。
- Spring AOP基于代理(Proxying),而AspectJ基于字节码操作(Bytecode Manipulation)。
- Spring AOP已经集成了AspectJ,AspectJ应该算得上是Java生态系统中最完整的AOP框架了。
- AspectJ相比于Spring AOP功能更加强大,但是Spring AOP相对来说更简单。如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择AspectJ,它比SpringAOP快很多。
2.3 谈谈你对SpringBoot的理解
Spring的缺点
- 依赖设置繁琐
- 配置繁琐
SpringBoot的优点
- 起步依赖(简化依赖配置)
- 自动配置(简化常用工程相关配置)
- 辅助功能(内置服务器)
2.4 Spring里面Controller 中(SpringMVC表现层)的注解
- @Controller
Spring注入bean,将此类交给Spring管理。
1)在类的上面两个注解:
-
@RestController 复合注解
@RestController注解= @ResponseBody+@Controller,效果是将方法返回的对象直接在浏览器上展示成json格式。 -
@RequestMapping
将 HTTP 请求映射到 MVC 和 REST 控制器的处理方法上,提供路由信息,负责URL到Controller中的具体函数的映射。
2)四中REST风格的请求方式
-
@PostMapping (增加)
将HTTP post请求映射到特定处理程序的方法注解 -
@DeleteMapping (删除)
将HTTP post请求映射到特定处理程序的方法注解 -
@PutMapping (修改)
将HTTP post请求映射到特定处理程序的方法注解 -
@GetMapping (查询)
将HTTP get请求映射到特定处理程序的方法注解
3)几个请求参数注解
- @PathVariable
它是以“/”方式来获取参数值。
也是RSET风格的springmvc取值。

- @PathParam
它是以键值对方式来获取参数值的。
这个注解相对简单,就是从地址栏取参数值,采用的是传统的拼接参数方法。
如:http://localhost:8080/HNZGDXSYS/ImgbyNumber?name=李四&name1=张三

- @RequestParam( ) 请求参数
- @RequestBody(请求体参数)
通过HttpMessageConverter读取RequestBody并反序列化为Object(泛指)对象
@RequestBody主要用来接收前端传递给后端的json字符串中的数据的(请求体中的数据的);而最常用的使用请求体传参是POST请求,所以使用@RequestBody接收数据时,一般都用POST方式进行提交。在后端的同一个接收方法里,@RequestBody与@RequestParam()可以同时使用,@RequestBody最多只能有一个,而@RequestParam()可以有多个。 - @ResponseBody (响应体参数)
@ResponseBody这个注解通常使用在控制层(controller)的方法上,其作用是将方法的返回值以特定的格式写入到response的body区域,进而将数据返回给客户端。当方法上面没有写ResponseBody,底层会将方法的返回值封装为ModelAndView对象。
是字符串则直接将字符串写到客户端。
是一个对象,此时会将对象转化为json串然后写到客户端。这里需要注意的是,如果返回对象,按utf-8编码。如果返回String,默认按iso8859-1编码,页面可能出现乱码。因此在注解中我们可以手动修改编码格式,比如@RequestMapping(value=“/cat/query”,produces=“text/html;charset=utf-8”),前面是请求的路径,后面是编码格式。
转化为json格式的字符串是通过HttpMessageConverter中的方法实现的,因为它是一个接口,因此由其实现类完成转换。如果是bean对象,会调用对象的getXXX()方法获取属性值并且以键值对的形式进行封装,进而转化为json串。如果是map集合,采用get(key)方式获取value值,然后进行封装。
一般在异步获取数据时使用,在使用@RequestMapping 后,返回值通常解析为跳转路径,加上@responsebody 后返回结果不会被解析为跳转路径,而是直接写入 HTTP response body 中。比如异步获取json 数据,加上 @responsebody 后,会直接返回 json 数据。
2.5 SpringBoot的常用注解
1)启动注解 @SpringBootApplication
-
@SpringBootConfiguration 注解,继承@Configuration注解,主要用于加载配置文件
-
@EnableAutoConfiguration 注解,开启自动配置功能
-
@ComponentScan 注解,主要用于组件扫描和自动装配
2)Controller 相关注解
-
@Controller
-
@RestController 复合注解
-
@RequestBody
-
@RequestMapping
-
@PostMapping用于将HTTP post请求映射到特定处理程序的方法注解
-
@DeleteMapping用于将HTTP post请求映射到特定处理程序的方法注解
-
@PutMapping用于将HTTP post请求映射到特定处理程序的方法注解
-
@GetMapping用于将HTTP get请求映射到特定处理程序的方法注解
3)取请求参数值
-
@PathVariable:获取url中的数据
-
@RequestParam:获取请求参数的值
-
@RequestHeader 把Request请求header部分的值绑定到方法的参数上
-
@CookieValue 把Request header中关于cookie的值绑定到方法的参数上
4)注入bean相关
-
@Service
-
@Controller
-
@Component
-
@Repository
-
@Scope作用域注解
-
@Entity实体类注解
-
@Bean产生一个bean的方法
-
@Autowired 自动导入
5)导入配置文件
-
@PropertySource注解
-
@ImportResource导入xml配置文件
-
@Import 导入额外的配置信息
6)事务注解
@Transactional(rollbackFor=Exception.class)
7)全局异常处理
-
@ControllerAdvice 统一处理异常
-
@ExceptionHandler 注解声明异常处理方法
2.6 异常类的基类
exception
2.7 SVN和Git区别?
SVN
SVN:集中式版本控制器(版本控制器),基于C/S架构并且严重依赖服务器端,它将数据存放在SVN的中央仓库,当服务器端无法使用的时候,版本控制也就无法再使用了。
GIT
Git是目前世界上最先进的分布式版本控制系统(没有之一)。当这个系统的任何一个客户端出现问题的时候,都可以从另外的客户端(即使服务器挂了)获取所有的代码。
SVN与GIT的区别:
- GIT是分布式的,而SVN是集中式的
- GIT把内容按元数据方式存储,而SVN是按文件。
- 二者分支不同:svn会发生分支遗漏的情况,而git可以同一个工作目录下快速的在几个分支间切换,很容易发现未被合并的分支。
- GIT没有一个全局的版本号,而SVN有
- GIT的内容完整性要优于SVN:GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
2.8 Maven的打包方式有几种
Pom、jar、war包
-
pom:用在父级工程或聚合工程中,用来做jar包的版本控制,必须指明这个聚合工程的打包方式为pom。
聚合工程只是用来帮助其他模块构建的工具,本身并没有实质的内容。具体每个工程代码的编写还是在生成的工程中去写。
对于在父工程中导的依赖工程也可享有。 -
jar:工程的默认打包方式,打包成jar用作jar包使用。存放一些其他工程都会使用的类,工具类。我们可以在其他工程的pom文件中去引用它
-
war:打包成war,发布在服务器上,如网站或服务。用户可以通过浏览器直接访问,或者是通过发布服务被别的工程调用
2.9 MyBatis如何实现多表查询
1)级联属性
联合查询:级联属性封装结果集
eg:dept.id
eg:dept.departmentName
部门表结构:
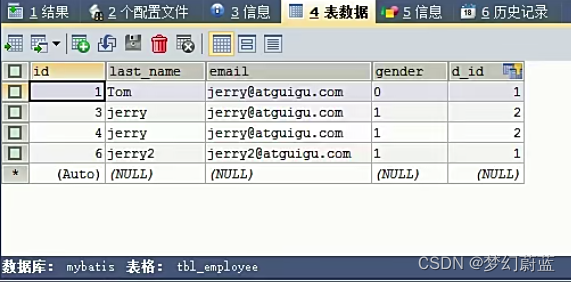
<resultMap type="com.atguigu.mybatis.bean.Employee" id="MyDifEmp">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/ >
<result column="gender" property="gender"/>
<result column="did" property="dept.id"/>
<result column="dept_name" property="dept.departmentName"/>
</resultMap>
<!-- public Employee getEmpAndDept(Integer id);-->
<select id="getEmpAndDept" resultMap="MyDifEmp">
SELECT e.id id,e.last_name last_name,e.gender gender,e.d_id d_id, d.id did,d.dept_name dept_name
FROM tbl_employee e,tbl_dept d
HERE e.d_id=d.id AND e.id=#{id}
</select>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2)association
- 使用association定义关联的单个对象的封装规则
<resultMap type="com.atguigu.mybatis.bean.Employee" id="MyDifEmp2"> <id column="id" property="id"/> <result column="last_name" property="lastName"/> <result column="gender" property="gender"/> <!--association可以指定联合的javaBean对象 property="dept":指定哪个属性是联合的对象 javaType:指定这个属性对象的类型[不能省略] --> <!--定义的association 的封装规则 下面的id是 dept的返回值主键--> <association property="dept" javaType="com.atguigu.mybatis.bean.Department"> <id column="did" property="id"/> <result column="dept_name" property="departmentName"/> </association> </resultMap>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 使用association进行分步查询:
(1)先按照员工id查询员工信息
(2)根据查询员工信息中的d_id值去部门表查出部门信息
(3)部门设置到员工中;<!-- id last_name email gender d_id --> <resultMap type="com.atguigu.mybatis.bean.Employee" id="MyEmpByStep"> <id column="id" property="id"/> <result column="last_name" property="lastName"/> <result column="email" property="email"/> <result column="gender" property="gender"/> <!-- association定义关联对象的封装规则 select:表明当前属性是调用select指定的方法查出的结果 column:指定将哪一列的值传给这个方法 流程:使用select指定的方法(传入column指定的这列参数的值)查出对象,并封装给property指定的属性 --> <association property="dept" select="com.atguigu.mybatis.dao.DepartmentMapper.getDeptById" column="d_id"> </association> </resultMap> <!-- public Employee getEmpByIdStep(Integer id);--> <select id="getEmpByIdStep" resultMap="MyEmpByStep"> select * from tbl_employee where id=#{id} <if test="_parameter!=null"> and 1=1 </if> </select>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
测试:
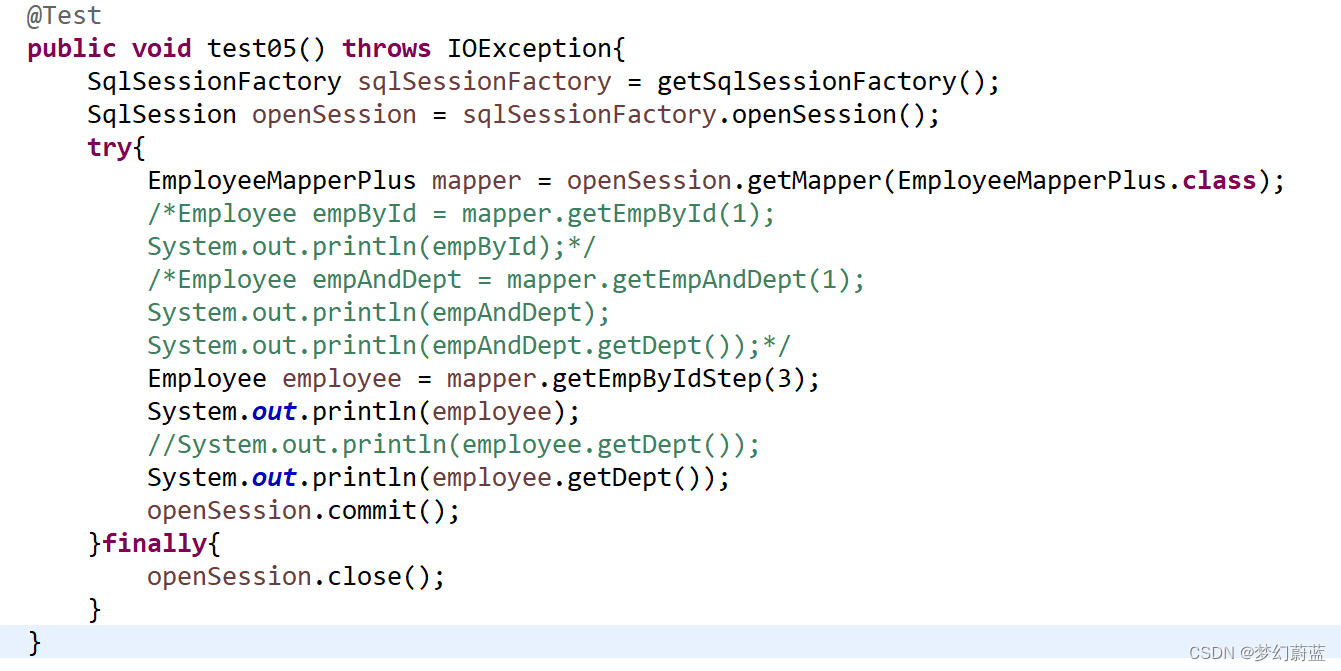
运行结果
2.10 Nagix的理解
反向代理、负载均衡、动静分离
2.11 nagix中能否多个服务器共用80端口?
可以共用一个80端口详细配置如下:
做负载均衡、反向代理时使用
-
方案一:多个不同端口服务共用80端口
#管理端转发 server { listen 80; server_name admin-xxxxx.xxx.xxx; location / { proxy_pass http://localhost:10003; } } #商家端转发 server { listen 80; server_name store-xxxxx.xxx.xxx; location / { proxy_pass http://localhost:10002; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
-
方案二:多个服务共用80端口
// nginx.conf # nginx 80端口配置 (监听demo二级域名) server { listen 80; server_name demo.test.com; location / { root /home/www/demo; index index.html index.htm; } } # nginx 80端口配置 (监听product二级域名) server { listen 80; server_name product.test.com; location / { root /home/www/product; index index.html index.htm; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
配置完成后保存,重启nginx服务,访问测试
2.11 nagix负载均衡
# 服务器1 server { listen 9001; server_name localhost; default_type text/html; location / { return 200 '<h1>server:9001</h1>'; } } # 服务器2 server { listen 9002; server_name localhost; default_type text/html; location / { return 200 '<h1>server:9002</h1>'; } } # 服务器3 server { listen 9003; server_name localhost; default_type text/html; location / { return 200 '<h1>server:9003</h1>'; } } # 代理服务器 # 设置服务器组 upstream backend { server localhost:9001; server localhost:9002; server localhost:9003; } server { listen 8080; server_name localhost; location / { # backend 就是服务器组的名称 proxy_pass http://backend/; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
2.12 Redis是什么?优点是什么
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存。
另外,Redis也经常用来做分布式锁。
除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案
2.13 Redis的事务机制
Redis通过MULTI、EXEC、WATCH等一组命令集合,来实现事务机制。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
简言之,Redis事务就是顺序性、一次性、排他性的执行一个队列中的一系列命令。
Redis执行事务的流程如下:
- 开始事务(MULTI)
- 命令入队
- 执行事务(EXEC)
- 撤销事务(DISCARD )
2.14 CPU占用过高,分析定位到哪一行代码存在bug
- 第一步找到cpu占用最高的进程id(定位进程)
top
- 1
如下输出,找到这个%CPU表示cpu占用率,默认是降序,因此先定位到进程id 也就是PID
找到进程后,我们接着细致的找进程中的哪一个线程占用cpu过高
- 第二步 定位到是那个java程序
jps -l | grep 进程pid
- 1
这行命令的作用是通过jps -l打印进程pid对应的java程序是哪一个,至于grep只是为了过滤
- 第三步 定位线程的tid
通过下面的命名定位到具体的线程
ps -mp 进程pid -o THREAD,tid,time
- 1
-
第四步 根据tid得到16进制的线程id
下面是为了获取16进制的线程id的命令格式
利用Linux命令,windows环境则通过计算器转换,自己想办法转换一下printf "%x\n" 上面得到的线程tid- 1
也可以自己通过进制转换得到对应的16机制的tid
-
最后通过jstack定位到具体的代码
jstack可以打印堆栈信息,因为堆栈信息内容比较多,所以我们需要知道对应的线程id才可以快速的找到问题所在。jstack 进程id | grep 16进制的tid -A60- 1
这行命令就是打印指定进程的堆栈信息,然后通过 grep 对应的tid进行过滤(找到cpu占用最高的线程),-A60是打印前面60行堆栈信息。
这个时候就会发现报错的信息,就好比在写程序中控制台打印出来的异常一样,然后找到对应的类第几行代码就可以了。一般先根据项目包名找,不是自己项目中的包肯定不是你写的代码,暂时认为其它jar包的代码时没有问题的,如果有问题再回来看这些信息
2.15 MyBatis中的缓存机制
MyBatis详解:SSM学习笔记-------MyBatis,里面有详细的介绍
一级缓存:(本地缓存)
sqlSession级别的缓存。一级缓存是一直开启的;SqlSession级别的一个Map
与数据库同一次会话期间查询到的数据会放在本地缓存中。
以后如果需要获取相同的数据,直接从缓存中拿,没必要再去查询数据库;
一级缓存失效情况:
1、sqlSession不同。
2、sqlSession相同,查询条件不同.(当前一级缓存中还没有这个数据)
3、sqlSession相同,两次查询之间执行了增删改操作(这次增删改可能对当前数据有影响)
4、sqlSession相同,手动清除了一级缓存(缓存清空)
2.16 MyBatis中#{ }和${ } 区别
#占位符的特点
-
MyBatis处理#{ }占位符,使用的JDBC对象是PreparedStatement对象,执行sql语句的效率更高。 -
使用
PreparedStatement对象,能够避免sql注入,使得sql语句的执行更加安全。 -
#{ }常常作为列值使用,位于sql语句中等号的右侧;#{ }位置的值与数据类型是相关的。
$占位符的特点
-
MyBatis处理${ }占位符,使用的JDBC对象是Statement对象,执行sql语句的效率相对于#{ }占位符要更低。 -
${ }占位符的值,使用的是字符串连接的方式,有sql注入的风险,同时也存在代码安全的问题。 -
${ }占位符中的数据是原模原样的,不会区分数据类型。 -
${ }占位符常用作表名或列名,这里推荐在能保证数据安全的情况下使用${ }。
二者区别:
1.#和$两者含义不同
- #会把传入的数据都当成一个字符串来处理,会在传入的数据上面加一个双引号来处理。
- 而$则是把传入的数据直接显示在sql语句中,不会添加双引号。
2.两者的实现方式不同
(1) $作用相等于是字符串拼接
(2) #作用相当于变量值替换
3、#和$使用场景不同
(1)在sql语句中,如果要接收传递过来的变量的值的话,必须使用#。因为使用#是通过PreparedStement接口来操作,可以防止sql注入,并且在多次执行sql语句时可以提高效率。
(2) 注意sql注入
$只是简单的字符串拼接而已,所以要特别小心sql注入问题。对于sql语句中非变量部分,那就可以使用$,比如$方式一般用于传入数据库对象(如传入表名)。
例如:
select * from ${tableName},
$ 对于不同的表执行统一的查询操作时,就可以使用$来完成。
- 1
- 2
(3)如果在sql语句中能同时使用#和$的时候,最好使用#。
2.17 文件上传下载的框架
3 SQL相关
3.1 oracle 里delete、trunk和drop 区别
| delete | truncate | drop |
|---|---|---|
| 删除表中数据(表结构保留 可回滚rollback) | 删除表,再以原表结构新建表。(如果之前的表有自增auto_increment 那么清空计数器) | 删表 |
| DML语言(数据处理语言), 在开启事务时,delete删除的数据可以回滚 | DDL (数据定义语言)删除的数据无法回滚 | DDL (数据定义语言)删除的数据无法回滚 |
1)相同点:
- truncate和不带where子句的delete、以及drop都会删除表内的数据。
- drop、truncate都是DDL语句(数据定义语言),执行后会自动提交。
2)不同点:
-
truncate 和 delete 只删除数据不删除表的结构(定义)
drop 语句将删除表的结构被依赖的约束(constrain)、触发器(trigger)、索引(index);依赖于该表的存储过程/函数将保留,但是变为 invalid 状态。 -
速度,一般来说: drop> truncate > delete
-
delete 语句是数据库操作语言(dml),如果开启事务,不会自动提交,能够回滚
truncate、drop 是数据库定义语言(ddl),操作立即生效,不能回滚。 -
delete 语句不影响表所占用的 extent,高水线(high watermark)保持原位置不动
drop 语句将表所占用的空间全部释放。
truncate 语句缺省情况下见空间释放到 minextents个 extent,除非使用reuse storage;truncate 会将高水线复位(回到最开始)。 -
安全性:小心使用 drop 和 truncate,尤其没有备份的时候.否则哭都来不及
使用上,想删除部分数据行用 delete,注意带上where子句. 回滚段要足够大.
想删除表,当然用 drop
想保留表而将所有数据删除,如果和事务无关,用truncate即可。如果和事务有关,用delete。
如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。 -
对于由 FOREIGN KEY 约束引用的表,不能使用 truncate,而应使用不带 WHERE 子句的 delete语句。
由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。 -
TRUNCATE TABLE 不能用于参与了索引视图的表
3.2 Oracle中视图和表的区别
-
视图是已经编译好的sql语句。而表不是。
-
视图没有实际的物理记录。而表有。
-
表是内容,视图是窗口。
-
表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改。
-
表是内模式,视图是外模式。
-
视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
-
表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
-
视图的建立和删除只影响视图本身,不影响对应的基本表。
3.3 数据库事务的隔离级别
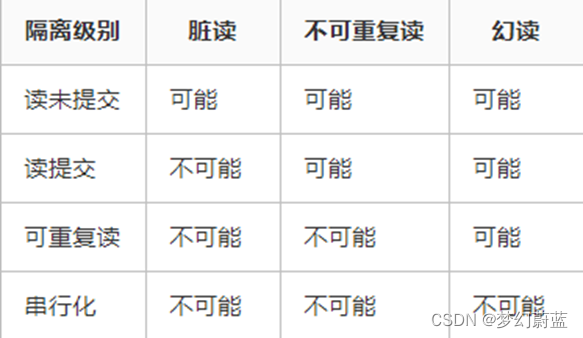
- 脏读:指的是读到了其他事务未提交的数据,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读。
- 可重复读:指的是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据都是一致的。通常针对数据更新(UPDATE)操作。
- 不可重复读:指的是在同一事务内,不同的时刻读到的同一批数据可能是不一样的,可能会受到其他事务的影响,比如其他事务改了这批数据并提交了。通常针对数据更新(UPDATE)操作。
- 幻读:是针对数据插入(INSERT)操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现好像刚刚的更改对于某些数据未起作用,但其实是事务B刚插入进来的,让用户感觉很魔幻,感觉出现了幻觉,这就叫幻读。
3.4 事务的四大特性
-
原子性(atomicity)
一个事务要么全部提交成功,要么全部失败回滚,不能只执行其中的一部分操作,这就是事务的原子性 -
一致性(consistency)
事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。指数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。例如对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNTS表中Tom和Jack的存款总额为2000元。 -
隔离性(isolation)
事务的隔离性是指在并发环境中,并发的事务时相互隔离的,一个事务的执行不能不被其他事务干扰。不同的事务并发操作相同的数据时,每个事务都有各自完成的数据空间,即一个事务内部的操作及使用的数据对其他并发事务时隔离的,并发执行的各个事务之间不能相互干扰。 -
持久性(durability)
一旦事务提交,那么它对数据库中的对应数据的状态的变更就会永久保存到数据库中。–即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束的状态
3.5 如何让索引失效
-
查询条件中有or,即使有部分条件带索引也会失效
-
索引本身失效
-
like查询是以%开头
-
违背最左匹配原则
比如一个表有a,b,c 三个字段,然后建立联合索引 index(a,b,c) 注意这里索引字段的顺序//因为建立索引树的时候,a是第一个,就好像树干一样。 //没有最左边的字段,即使后面的字段建立了索引,也无法命中。 select * from table where c = "3"; //不会走索引 select * from table where b = 2 and c = "3"; //不会走索引- 1
- 2
- 3
- 4
- 5
-
如果列类型是字符串,那在查询条件中需要将数据用引号引用起来,否则不走索引
-
索引列上参与计算会导致索引失效
-
如果mysql估计全表扫描要比使用索引要快,会不适用索引
-
没有查询条件,或者查询条件没有建立索引
-
在查询条件上没有使用引导列
-
查询的数量是大表的大部分,应该是30%以上。
3.6 需要建立索引和不需要建立索引
3.6.1. 需要创建索引的情况
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 单键组索引的选择问题,组合索引性价比更高
- 查询中排序的字段,排序字段若通过索引法访问将大大提高排序速度。
- 查询中统计或者分组字段
3.6.2. 哪些表中不需要创建索引
-
表的记录太少
因为这个会提高查询速度,但是却降低了更新表的速度 -
经常增删改的表
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件数据重复且分布平均的表字段,因此应该只为经常查询和经常排序的数据列建立索引。 -
不要定义冗余或重复的索引
-
不建议用无序的值作为索引;
-
删除不再使用或者很少使用的索引;
-
数据量小的表最好不要使用索引;
-
有大量重复数据的列上不要建立索引;
-
避免对经常更新的表创建过多的索引;
-
在 WHERE 中使用不到的字段,不要设置索引;
3.7 根据E-R图回答以下问题
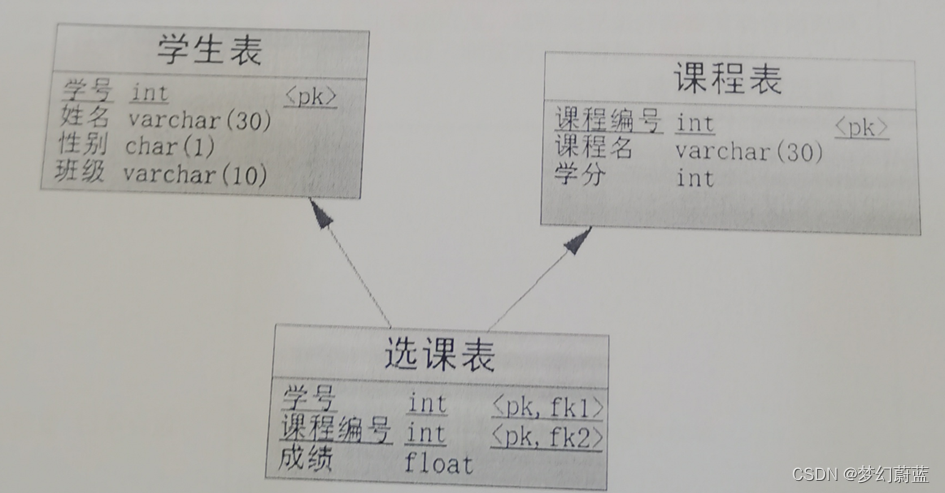
学生表S(学号Sno,学生姓名Sname,性别Ssex,系别Sdept)
课程表C(课程号cno,课程名cname,学分ccredit)
选课表SC(学号sno,课程号cno,成绩grade)
问题
# 1、查询“CS”系学生的基本信息; SELECT * FROM s WHERE Sdept="CS"; # 2、统计各系学生的人数,结果按升序排列; SELECT Sdept,COUNT(*) '人数' FROM s GROUP BY Sdept ORDER BY '人数'; # 3、查询选修了“1”或“2”号课程的学生学号和姓名; SELECT s.Sno,Sname,grade FROM s ,sc where s.`Sno`=sc.`Sno` AND Cno IN ('1','2'); # 4、查询选修了课程名为“数据库”且成绩在60分以下的学生的学号、姓名和成绩; SELECT s.Sno,Sname FROM s JOIN sc ON s.`Sno`=sc.`Sno` JOIN c ON sc.`Cno`=c.`Cno` WHERE Cname ="数据库" AND grade<60; # 5、查询选修了3门以上课程的学生学号; SELECT sno FROM sc GROUP BY sc.Sno HAVING COUNT(*)>=3; # 6、查询选修课程成绩至少有一门在80分以上的学生学号; SELECT sno FROM sc GROUP BY sc.Sno HAVING MAX(grade)>80; # 7、查询选修课程成绩均在80分以上的学生学号; SELECT sno FROM sc GROUP BY sc.Sno HAVING MIN(grade)>80; # 8、查询选修课程平均成绩在80分以上的学生学号 SELECT sno FROM sc GROUP BY sc.Sno HAVING AVG(grade)>80;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
数据准备
创建数据库,设置字符集
CREATE DATABASE IF NOT EXISTS test DEFAULT CHARSET utf8;
use test;
- 1
- 2
- 3
#创建学生表:包括学号,姓名,年龄,性别,院系 CREATE TABLE s ( Sno VARCHAR(7)PRIMARY KEY, Sname VARCHAR(10)NOT NULL, Sage INT, Ssex VARCHAR(2), Sdept VARCHAR(20) DEFAULT '计算机系' ); #创建课程表:包括课程号,课程名,选修课课程号,学分 CREATE TABLE c ( Cno VARCHAR(10)PRIMARY KEY, Cname VARCHAR (20)NOT NULL, Cpno VARCHAR(10), Ccredit INT ); #创建选课表 CREATE TABLE sc ( Sno VARCHAR(7), Cno VARCHAR(10), grade INT, FOREIGN KEY (sno) REFERENCES s(Sno), FOREIGN KEY (cno) REFERENCES c(cno) ); # 向学生表S中插入数据 INSERT INTO s (Sno,Sname,Sage,Ssex,Sdept) VALUE ("10001","张三",20,'男','计算机'), ("10002","李梅",19,'女','计算机'), ("10003","王五",18,'男','CS'), ("10004","小明",21,'男','计算机'), ("10006","黎明",18,'男','艺术表演'), ("10008","杰克",21,'男','计算机'), ("10005","小红",22,'女','CS'); # 向课程表C中插入数据 INSERT INTO c (Cno,Cname,Cpno,Ccredit) VALUE ("1","离散数学",NULL,5), ("2","线性代数",'3',6), ("3","高等数学",NULL,4), ("4","数据结构",'3',6), ("5","操作系统",'1',4), ("6","数据库",'4',5); # 向选课表SC中插入数据 INSERT INTO sc (Sno,Cno,grade) VALUE ("10001","1",70), ("10001","6",56), ("10003","4",90), ("10003","5",83), ("10004","1",75), ("10004","3",90), ("10008","1",70), ("10008","5",70), ("10008","6",88), ("10002","1",85), ("10002","6",89);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
3.8 查询分组内的前五条数据
问题:在学生表中查询每个班级中的成绩前五名
数据准备:
DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `id` int(40) NOT NULL AUTO_INCREMENT, `name` varchar(40) DEFAULT NULL, `age` int(20) DEFAULT NULL, `class_id` int(50) DEFAULT NULL, `class_name` varchar(40) DEFAULT NULL, `grad` int(30) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=29 DEFAULT CHARSET=utf8; -- ---------------------------- -- Records of student -- ---------------------------- INSERT INTO `student` VALUES ('1', 'Tom', '19', '1', '计算机系', '80'); INSERT INTO `student` VALUES ('2', 'Jun', '20', '1', '计算机系', '90'); INSERT INTO `student` VALUES ('3', 'Tim', '23', '2', '数学系', '78'); INSERT INTO `student` VALUES ('4', 'Pom', '21', '1', '计算机系', '87'); INSERT INTO `student` VALUES ('5', 'wom', '23', '1', '计算机系', '70'); INSERT INTO `student` VALUES ('6', 'Jury', '23', '1', '计算机系', '78'); INSERT INTO `student` VALUES ('7', 'Tim', '22', '1', '计算机系', '74'); INSERT INTO `student` VALUES ('8', 'Tom', '20', '1', '计算机系', '75'); INSERT INTO `student` VALUES ('9', 'ERT', '13', '1', '计算机系', '76'); INSERT INTO `student` VALUES ('10', 'RYn', '18', '1', '计算机系', '71'); INSERT INTO `student` VALUES ('11', 'Qom', '20', '2', '数学系', '78'); INSERT INTO `student` VALUES ('12', 'Jury', '23', '2', '数学系', '98'); INSERT INTO `student` VALUES ('13', 'Jim', '22', '3', '中文系', '99'); INSERT INTO `student` VALUES ('14', 'Kom', '20', '3', '中文系', '77'); INSERT INTO `student` VALUES ('15', 'ORT', '13', '3', '中文系', '32'); INSERT INTO `student` VALUES ('16', 'TTYn', '18', '3', '中文系', '56'); INSERT INTO `student` VALUES ('17', 'SM', '18', '3', '外语系', '78'); INSERT INTO `student` VALUES ('18', 'Hid', '23', '3', '外语系', '98'); INSERT INTO `student` VALUES ('19', 'Wed', '22', '3', '外语系', '58'); INSERT INTO `student` VALUES ('20', 'Uim', '20', '3', '外语系', '65'); INSERT INTO `student` VALUES ('21', 'Dom', '13', '3', '外语系', '32'); INSERT INTO `student` VALUES ('22', 'Kfg', '18', '3', '外语系', '56'); INSERT INTO `student` VALUES ('23', 'SM', '18', '2', '数学系', '96'); INSERT INTO `student` VALUES ('24', 'Hid', '23', '2', '数学系', '95'); INSERT INTO `student` VALUES ('25', 'Wed', '22', '2', '数学系', '94'); INSERT INTO `student` VALUES ('26', 'Uim', '20', '2', '数学系', '93'); INSERT INTO `student` VALUES ('27', 'Dom', '13', '2', '数学系', '92'); INSERT INTO `student` VALUES ('28', 'Kfg', '18', '2', '数学系', '91');
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
查询:
select a.*
from student a
where 5 > (
select count(*)
from student b
where b.class_id = a.class_id
and b.grad > a.grad
)
order by a.class_id, a.grad DESC
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
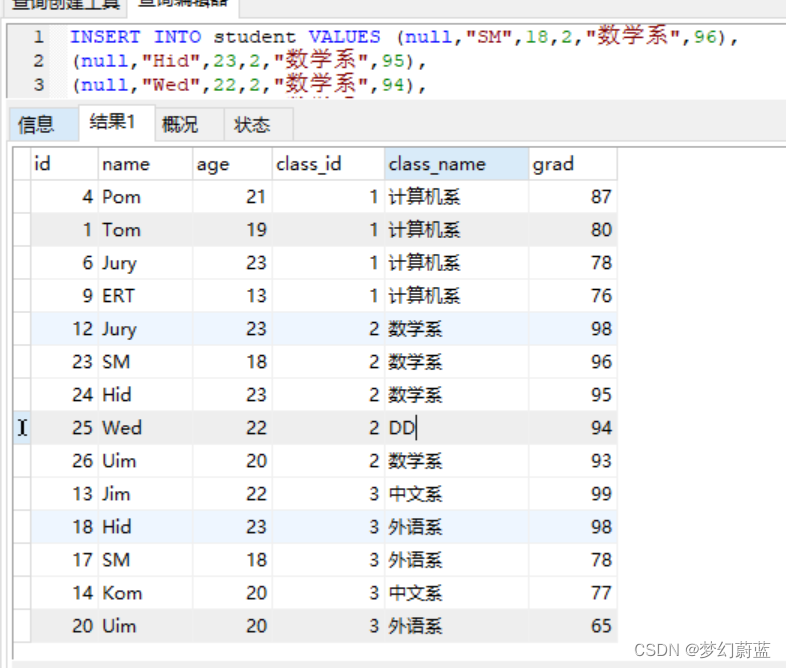
效果展示:
3.9 乐观锁和悲观锁
悲观锁:
就是比较悲观的锁,总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。
传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁:
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和
CAS算法实现。
乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
Mybatis-Plus实现乐观锁
1、在表中添加version字段。
2、修改实体
3、添加乐观锁插件配置
<!--配置乐观锁插件-->
<bean id="optimi sti cLockerInnerInterceptor"
class="com. baomi dou . mybatisplus . extension. plugins. inner . optimisticlockerInnerInt
erceptor"> </bean>
- 1
- 2
- 3
- 4
4、SpringBoot实现:
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//乐观锁插件
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
//分页插件
interceptor.addInnerInterceptor(new PaginationInnerInterceptor());
//防止全表更新插件
interceptor.addInnerInterceptor(new BLockAttackInnerInterceptor());
//乐观锁插件
interceptor.addInnerInterceptor(new optimisticLocker InnerInterceptorp;
return interceptor ;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.10 存储过程
存储过程:是事先经过编译并存储在数据库中的一段SQL语句的集合,就是数据库 SQL 语言层面的代码封装与重用。
存储过程参数:
IN类型的参数表示接受调用者传入的数据;OUT类型的参数表示向调用者返回数据;INOUT类型的参数即可以接受调用者传入的参数,也可以向调用者返回数据。
优点
-
存储过程是通过处理封装在容易使用的单元中,简化了复杂的操作。
-
简化对变动的管理。如果表名、列名、或业务逻辑有了变化。只需要更改存储过程的代码。使用它的人不用更改自己的代码。
-
通常存储过程是有助于提高应用程序的性能。当创建的存储过程被编译之后,就存储在数据库中。
但是,MySQL实现的存储过程略有所不同。
MySQL存储过程是按需编译。在编译存储过程之后,MySQL将其放入缓存中。
MySQL为每个连接维护自己的存储过程高速缓存。如果应用程序在单个连接中多次使用存储过程,则使用编译版本,否则存储过程的工作方式类似于查询。 -
存储过程有助于减少应用程序和数据库服务器之间的流量。
因为应运程序不必发送多个冗长的SQL语句,只用发送存储过程中的名称和参数即可。 -
存储过程度任何应用程序都是可重用的和透明的。存储过程将数据库接口暴露给所有的应用程序,以方便开发人员不必开发存储过程中已支持的功能。
-
存储的程序是安全的。数据库管理员是可以向访问数据库中存储过程的应用程序授予适当的权限,而不是向基础数据库表提供任何权限。
缺点
-
内存占用量大,APU利用率增加
如果使用大量的存储过程,那么使用这些存储过程的每个连接的内存使用量将大大增加。
此外,如果在存储过程中过度使用大量的逻辑操作,那么CPU的使用率也在增加,因为MySQL数据库最初的设计就侧重于高效的查询,而不是逻辑运算。 -
存储过程的构造使得开发具有了复杂的业务逻辑的存储过程变得困难。
-
很难调试存储过程。只有少数数据库管理系统允许调试存储过程,MySQL不提供调试存储过程的功能。
-
开发和维护存储过程都不容易。
开发和维护存储过程通常需要一个不是所有应用程序开发人员拥有的专业技能。这可能导致应用程序开发和维护阶段的问题。 -
对数据库依赖程度较高,移值性差。
定义一个有参数的存储过程:
先定义一个student数据库表:
现在要查询这个student表中的sex为男的有多少个人。
DELIMITER $$
CREATE
PROCEDURE `demo`.`demo2`(IN s_sex CHAR(1),OUT s_count INT)
-- 存储过程体
BEGIN
-- 把SQL中查询的结果通过INTO赋给变量
SELECT COUNT(*) INTO s_count FROM student WHERE sex= s_sex;
SELECT s_count;
END$$
DELIMITER ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
调用这个存储过程
-- @s_count表示测试出输出的参数
CALL demo2 ('男',@s_count);
- 1
- 2
- 3
详细请看:MySQL中的存储过程(详细篇)
3.11 事务和锁的区别
锁:
悲观锁:认为在修改数据库数据的这段时间里存在着也想修改此数据的事务;
乐观锁:认为在短暂的时间里不会有事务来修改此数据库的数据;
我们一般意义上讲的锁其实是指悲观锁,在数据处理过程中,将数据置于锁定状态(由数据库实现)。
事务
事务就是并发控制的单位,是用户定义的一个操作序列,满足ACID属性(原子性、一致性、隔离性和持久性)。
锁是用于解决隔离性的一种机制。事务的隔离级别通过锁的机制来实现。另外锁有不同的粒度,同时事务的隔离级别一般有四种:
- 读未提交
Read uncommitted, - 读已提交
Read committed, - 可重复读
Repeatable read, - 可串行化
Serializable。
重点:一般事务使用的是悲观锁(具有排他性)。
3.12 常用的数据库引擎
常用的是MyISAM和InnoDB。
InnoDB:支持事务、支持外键、支持行级锁、不支持全文索引、
MyISAM:不支持事务、不支持外键、不支持行级锁、支持全文索引
3.13 mysql查看历史执行时间
可以打开系统数据表 performance_schema 的相关表:
USE performance_schema;
- 1
然后,输入以下命令可以查看所有执行过的语句的历史执行时间:
SELECT * FROM events_statements_history;
- 1
如果只想查看最近一段时间的执行时间,可以输入以下命令:
SELECT * FROM events_statements_history
WHERE event_time >NOW() - INTERVAL 1 DAY;
- 1
- 2
3.14 Mysql的查询语法
select 查询列表 ⑦
from 表1 别名 ①
连接类型 join 表2 ②
on 连接条件 ③
where 筛选 ④
group by 分组列表 ⑤
having 分组后的筛选 ⑥
order by 排序列表 ⑧
limit 起始条目索引,条目数; ⑨
3.15 ORM是什么,用过相关框架吗?
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。ORM框架是连接数据库的桥梁,只要提供了持久化类与表的映射关系,ORM框架在运行时就能参照映射文件的信息,把对象持久化到数据库中。
ORM 框架:为了解决面型对象与关系数据库存在的互不匹配的现象的框架。
Hibernate全自动 需要写hql语句iBATIS半自动 自己写sql语句,可操作性强,小巧mybatiseclipseLinkJFinal

