
- 1Python 爬虫 requests 库教程(附案例)
- 2鸿蒙-arkTs:开发工具安装_arkts怎么打包安装到手机
- 3win10中搭建并配置ftp服务器的方法(实现多用户登录整合版)_win10添加ftp网络存储设备
- 4Oracle19C图形界面安装教程
- 5uniCloud 微信小程序登陆全流程demo
- 6Android Studio 连接真机调试
- 7Flutter 输入框(TextField)被键盘遮挡两种解决方案_flutter 键盘遮挡输入框问题
- 8ConstraintLayout基本使用之toLeftOf 、toTopOf、toRightOf、toBottomOf_layout_constraintleft_toleftof
- 9COMP9315 week07课堂笔记_bit-sliced index
- 10写代码常用英文及缩写_代码里的英文缩写
12 权重衰退【李沐动手学深度学习v2课程笔记】
赞
踩
1.权重衰退

使用均方范数来进行权重衰退

柔性限制
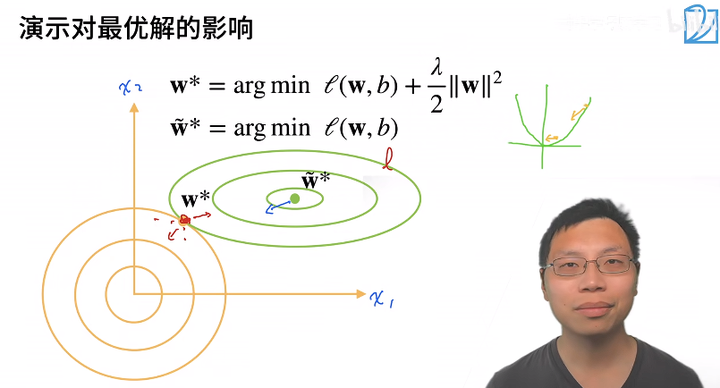
柔性限制对最优解的影响

参数更新法则

总结
2.代码实现
%matplotlib inline import torch from torch import nn from d2l import torch as d2l

生成数据
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5 true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05 train_data = d2l.synthetic_data(true_w, true_b, n_train) train_iter = d2l.load_array(train_data, batch_size) test_data = d2l.synthetic_data(true_w, true_b, n_test) test_iter = d2l.load_array(test_data, batch_size, is_train=False)
synthetic_data函数和load_array函数在线性回归封装过
2.1 初始化模型参数
def init_params(): w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True) b = torch.zeros(1, requires_grad=True) return [w, b]
2.2 定义L2范数惩罚
def l2_penalty(w): return torch.sum(w.pow(2)) / 2
实现这一惩罚最方便的方法是对所有项求平方后并将它们求和
2.3 训练
下面的代码将模型拟合训练数据集,并在测试数据集上进行评估,线性网络和平方损失没有变化, 所以我们通过d2l.linreg和d2l.squared_loss(同样在线性回归那里定义过)导入它们。 唯一的变化是损失现在包括了惩罚项。
def train(lambd): w, b = init_params() net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss num_epochs, lr = 100, 0.003 animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test']) for epoch in range(num_epochs): for X, y in train_iter: # 增加了L2范数惩罚项, # 广播机制使l2_penalty(w)成为一个长度为batch_size的向量 l = loss(net(X), y) + lambd * l2_penalty(w) l.sum().backward() d2l.sgd([w, b], lr, batch_size) if (epoch + 1) % 5 == 0: animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss))) print('w的L2范数是:', torch.norm(w).item())
2.4 忽略正则化直接训练
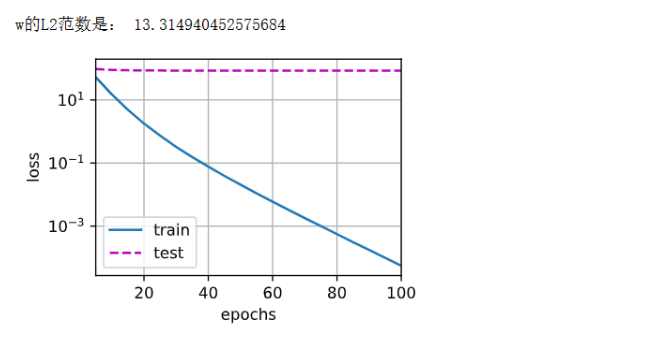
现在用lambd = 0禁用权重衰减后运行这个代码。 注意,这里训练误差有了减少,但测试误差没有减少, 这意味着出现了严重的过拟合。
train(lambd=0)
添加图片注释,不超过 140 字(可选)
2.5 使用权重衰退
train(lambd=20)
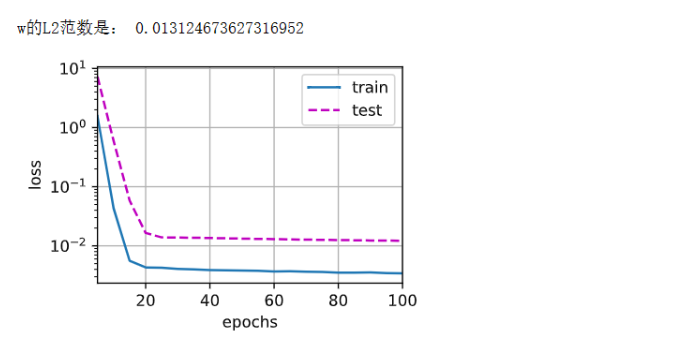
添加图片注释,不超过 140 字(可选)
3.简洁实现
由于权重衰减在神经网络优化中很常用, 深度学习框架为了便于我们使用权重衰减, 将权重衰减集成到优化算法中,以便与任何损失函数结合使用。 此外,这种集成还有计算上的好处, 允许在不增加任何额外的计算开销的情况下向算法中添加权重衰减。 由于更新的权重衰减部分仅依赖于每个参数的当前值, 因此优化器必须至少接触每个参数一次。
在下面的代码中,我们在实例化优化器时直接通过weight_decay指定weight decay超参数。 默认情况下,PyTorch同时衰减权重和偏移。 这里我们只为权重设置了weight_decay,所以偏置参数b不会衰退
def train_concise(wd): net = nn.Sequential(nn.Linear(num_inputs, 1)) for param in net.parameters(): param.data.normal_() loss = nn.MSELoss(reduction='none') num_epochs, lr = 100, 0.003 # 偏置参数没有衰减 trainer = torch.optim.SGD([ {"params":net[0].weight,'weight_decay': wd}, {"params":net[0].bias}], lr=lr) animator = d2l.Animator(xlabel='epochs', ylabel='loss', yscale='log', xlim=[5, num_epochs], legend=['train', 'test']) for epoch in range(num_epochs): for X, y in train_iter: trainer.zero_grad() l = loss(net(X), y) l.mean().backward() trainer.step() if (epoch + 1) % 5 == 0: animator.add(epoch + 1, (d2l.evaluate_loss(net, train_iter, loss), d2l.evaluate_loss(net, test_iter, loss))) print('w的L2范数:', net[0].weight.norm().item())
忽略正则化直接训练
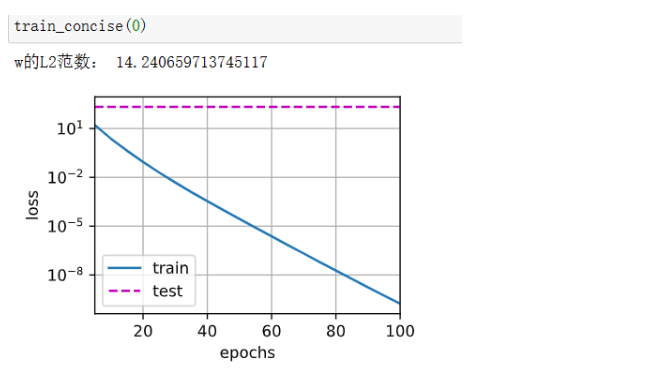
忽略正则化直接训练
使用权重衰退
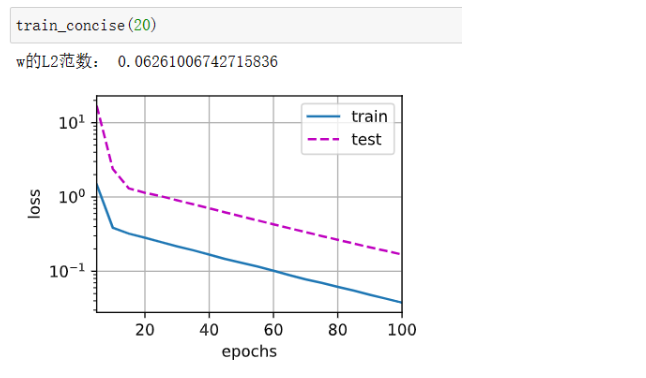
使用权重衰退
代码可以直接从这里copy~

