
- 1Android --调启百度地图_geo:0,0:?q=
- 2Latex--TikZ和PGF--高级文本绘图,思维绘图,想到--得到!
- 3HarmonyOS云开发简介_harmonyos云开发工程创建后,会自动开通哪些服务?
- 4Mysql TIMESTAMP 和 DATETIME的区别_mysql timestamp 和datetime区别
- 5荣耀es升级鸿蒙,华为手机明年全部升级鸿蒙系统 所有自研设备换OS
- 6Sass(Scss)的学习和安装_安装sacc的命令是什么
- 7高并发架构设计经验_适合大单元设计建立多级互联模式
- 8RHCS集群使用GFS2实现文件实时共享(多点挂载)_gfs2使用
- 9vue3-admin-element安装_vue3-admin-element-template
- 10获取Android设备DeviceId与反Xposed Hook_系统隐藏接口获取安卓id
【数据挖掘】练习1:R入门
赞
踩
课后作业1:R入门
一:习题内容
1.要与R交互必须安装Rstudio,这种说法对不对?
不对。虽然RStudio是一个流行的R交互集成开发环境,但并不是与R交互的唯一方式。
与R交互可以采用以下几种方法:
- 使用R Console:R语言自带了一个控制台界面。这种方式不需要安装任何额外的软件,只需安装R本身。
- 使用其他编辑器:用户可以使用任何文本编辑器编写R代码,并在R控制台或者终端中执行。一些常见的文本编辑器包括Notepad++、Sublime Text、Atom等。用户只需要将编辑器中编写的R代码复制粘贴到R控制台中执行即可。
- 使用其他集成开发环境:其他集成开发环境包括Visual Studio Code(通过R扩展)、Jupyter Notebook(通过IRkernel)、Emacs(通过ESS包)等。
2.下面哪一个不能用于R的赋值?
A.<- B.-> C.= D._
答案是:D。
A是采用左箭头进行赋值,例如 x <- c(1,2)。
B是采用右箭头进行赋值,例如 c(1,2) -> x。
C是采用等于号进行赋值,例如x = c(1,2)。
3.objects(4)输出什么?

在R中,执行 objects(4) 会列出所有默认加载的函数名称,这些函数包含在R的基本命名空间中。输出函数包括绘图函数(如plot()、points()、lines()等)、统计函数(如hist()、boxplot()等)以及其他常用函数(如title()、legend()等)。
4.安装R包和载入R包有什么区别。
安装R包是指将R包从CRAN(Comprehensive R Archive Network)或其他来源下载并安装到你的计算机上。当用户第一次使用某个R包时,用户需要先安装R包,然后才能在R环境中使用。安装R包通常只需要进行一次,在R环境中安装后,用户就可以在需要的时候随时载入并使用该包。
载入R包是指在用户的R会话中将某个已经安装的R包加载到内存中,以便在当前会话中使用该包中的函数和数据。当用户需要使用某个已安装的R包时,用户需要使用library()函数或require()函数来加载。载入R包通常需要在每个新的R会话中执行一次,以确保该包的函数和数据可用。
总而言之,安装是将包下载到你的环境中的过程,只需要做一次(除非需要更新)。载入是在每次R会话中激活包以便使用的过程,需要在每次需要使用包时进行。
5.Rhistory和Rdata文件有什么区别。
Rhistory和Rdata文件是在R中用于保存数据和历史记录的两种不同类型的文件,其作用和内容有所不同。
| Rhistory | Rdata |
| Rhistor文件记录了在R控制台中输入的命令历史记录。 | Rdata文件用于保存R工作环境中的数据和对象。 |
| 每次在R控制台中输入命令并按下回车键时,该命令都会被追加到 Rhistory 文件中。 | 可以使用save()函数将R工作空间中的数据和对象保存到一个 .Rdata 文件中。 |
| Rhistory 文件可以在退出R会话时保存,以便下次重新进入R时恢复命令历史记录。 | 可以包含多个数据框、向量、列表等R对象,以及与它们相关的元数据。 |
| 通常,Rhistory 文件的扩展名是 .Rhistory,并且位于用户主目录下(如~/.Rhistory)。 | 可以使用load()函数加载 .Rdata 文件,并将其中保存的数据和对象恢复到R工作环境中。 |
总而言之,RData以二进制的方式保存了会话中的变量值,而Rhistory以文本文件的方式保存了R会话中的所有命令。
6.什么是屏蔽?
在R中,屏蔽(masking)是指当两个或多个具有相同名称的函数或对象存在时,较近的作用域中的函数或对象将屏蔽较远处的函数或对象。
这种情况通常发生在使用多个包或在不同的作用域中定义相同名称的函数或对象时。
例如,假设用户在一个R脚本中加载了两个包,这两个包都定义了名为mean()的函数。当用户调用mean()函数时,由于R按照搜索路径的顺序查找函数,将优先使用最近加载的包中定义的mean()函数。
7.显示R会话的搜索路径。
在R中,可以使用search()函数来显示R会话的搜索路径。

同时,可以使用getwd()函数获取当前工作目录的路径。

8.用objects列出“datasets”包中的所有对象。
代码:
| objects("package:datasets") |
运行结果:

9.在packages窗口中从CRAN安装mangoTraining包。


根据网站可知,mangoTraining依赖包目前无法匹配R4.3的版本(CRAN - Package mangoTraining)。通过访问曾经该依赖包的存档压缩文件在网站(Index of /src/contrib/Archive/mangoTraining),可下载相应版本的mangoTraining压缩包。
下载某个压缩包后,解压到本地。

在RStudio的console处,通过install.packages的代码【install.packages("C:\\Users\\86158\\Desktop\\mangoTraining", repos = NULL, type = "source")】可以安装完毕。

10.列出mangoTraining中包含的对象。
代码:
| library("mangoTraining") objects("package:mangoTraining") |
运行结果:

11. 计算31079除170166719的余数。
代码:
| a <- 31079 b <- 170166719 c <- b%%a c |
运行结果:

12.利用R计算以下数值,小数点精确到后5位。
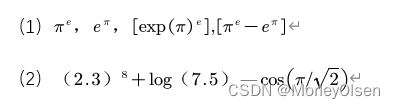
(1)
代码:
| round(pi**exp(1),5) round(exp(1)**pi,5) round(exp(pi)**exp(1),5) # 这个也可用sprintf进行省略数的计算,参考(2)中的代码 round(pi**exp(1)-exp(1)**pi,5) |
运行结果:

(2)
代码:
| result <- round((2.3)^8 + log(7.5) - cos(pi/sqrt(2)), 5) formatted_result <- sprintf("%.5f", result) formatted_result |
运行结果:

13. 使用seq和rep函数生成向量(1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9)。
分析可知,该向量由(1 2 3 4 5)、(2 3 4 5 6)、(3 4 5 6 7)、(4 5 6 7 8)、(5 6 7 8 9)5个子向量组成,且后面一个子向量在前面一个子向量的基础上进行了+1操作。
代码:(1)生成从1到5的向量;(2)使用rep()函数重复向量,并逐步增加重复的次数。
| vec <- seq(1, 5) result <- rep(vec, each = 5) + rep(0:4, times = 5) result |
运行结果:
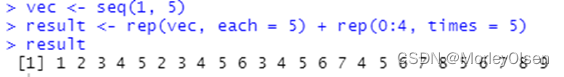
14.用1-9的整数列创建长度为9的字符型向量,以letters作为向量的元素名,使用该向量完成以下操作。
(0)创建向量。
代码:
| char_vec <- as.character(1:9) names(char_vec) <- letters[1:9] char_vec |
运行结果:

(1)选择向量的第一个值和最后一个值。
代码:
| char_vec[c("a","i")] |
运行结果:

(2)选择向量中大于3的值。
代码:
| char_vec[char_vec > 3] |
运行结果:

(3)选择向量中2-7之间的所有值。
代码:
| char_vec[2:7] |
运行结果:

(4)选择除了5以外的所有值。
代码:
| char_vec[-5] |
运行结果:

(5)选择向量中名称为“D”、“E”,“G”的元素。
代码:
| char_vec[c("d", "e", "g")] |
运行结果:


