
- 1人工智能概念
- 2七天入门大模型 :提示词工程 Prompt Engineering,最全的总结来了!_大模型 提示工程
- 3CRNN:文本序列识别
- 4Proxmox ve(PVE)更换国内源_pve8 替换国内源
- 52022年(23届)电子信息/通信工程夏令营保研/考研复试经验贴(吉林大学通信工程学院篇)_吉林大学信通保研
- 6mac下提示MAC电脑GIT提交代码到GITHUB提示GIT-CREDENTIAL-OSXKEYCHAIN 验证解决方案
- 7Linux I2C 驱动_linuxiic设备
- 8CDH大数据平台 27Cloudera Manager Console之superset之Python相关包安装(markdown新版一)
- 9Linux系统中对SSD硬盘优化的方法_ext4针对 ssd优化
- 10CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below m
女朋友问阿里双十一实时大屏如何实现,我惊呆一会,马上手把手教她背后的大数据技术_实时大屏显示是怎么实现的
赞
踩
女朋友问阿里双十一实时大屏如何实现,不懂技术的她居然好奇问这个,身为程序员的我只能用毕生所学开始跟她讲大数据技术。
全网最详细的大数据文章系列,强烈建议收藏加关注!
目录
3、Flink官网介绍:https://flink.apache.org/
前言
全网最详细的大数据笔记,轻松带你从入门到精通,该栏目每天更新,汇总知识分享

阿里双十一实时大屏 背后的大数据技术
一、大数据相关概念剖析
1、什么是大数据?
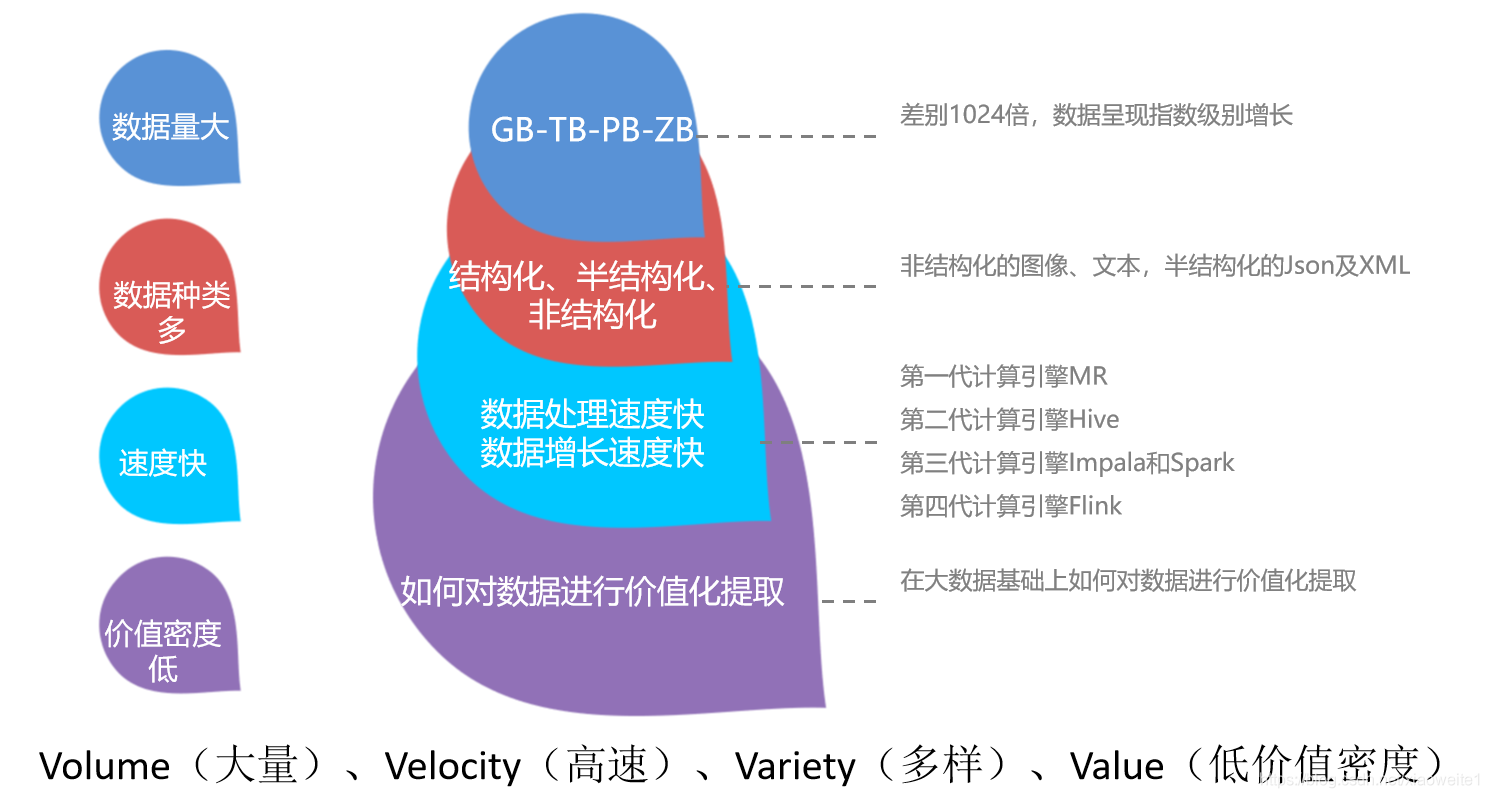
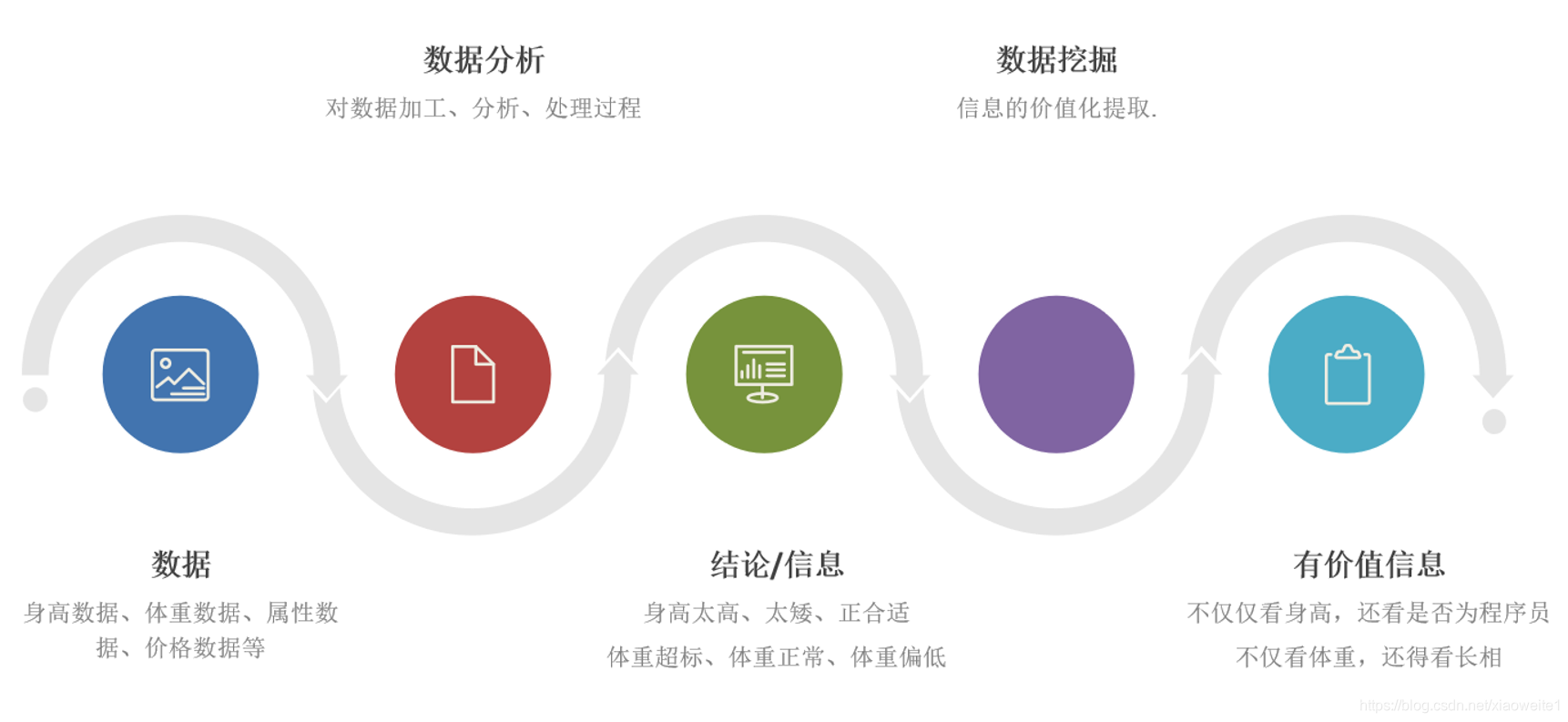
2、数据分析基础概念
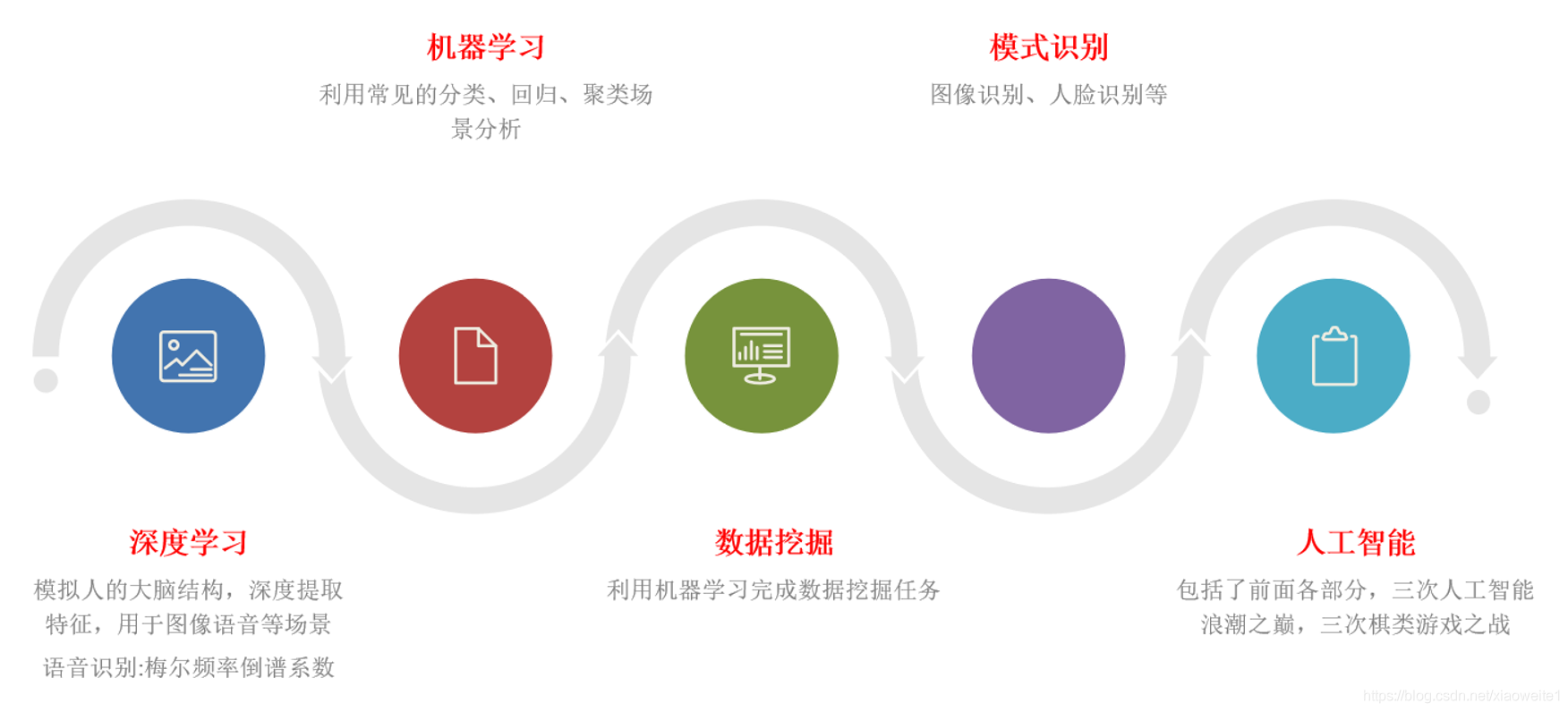
3、人工智能基础概念
4、人工智能+大数据分析场景案例

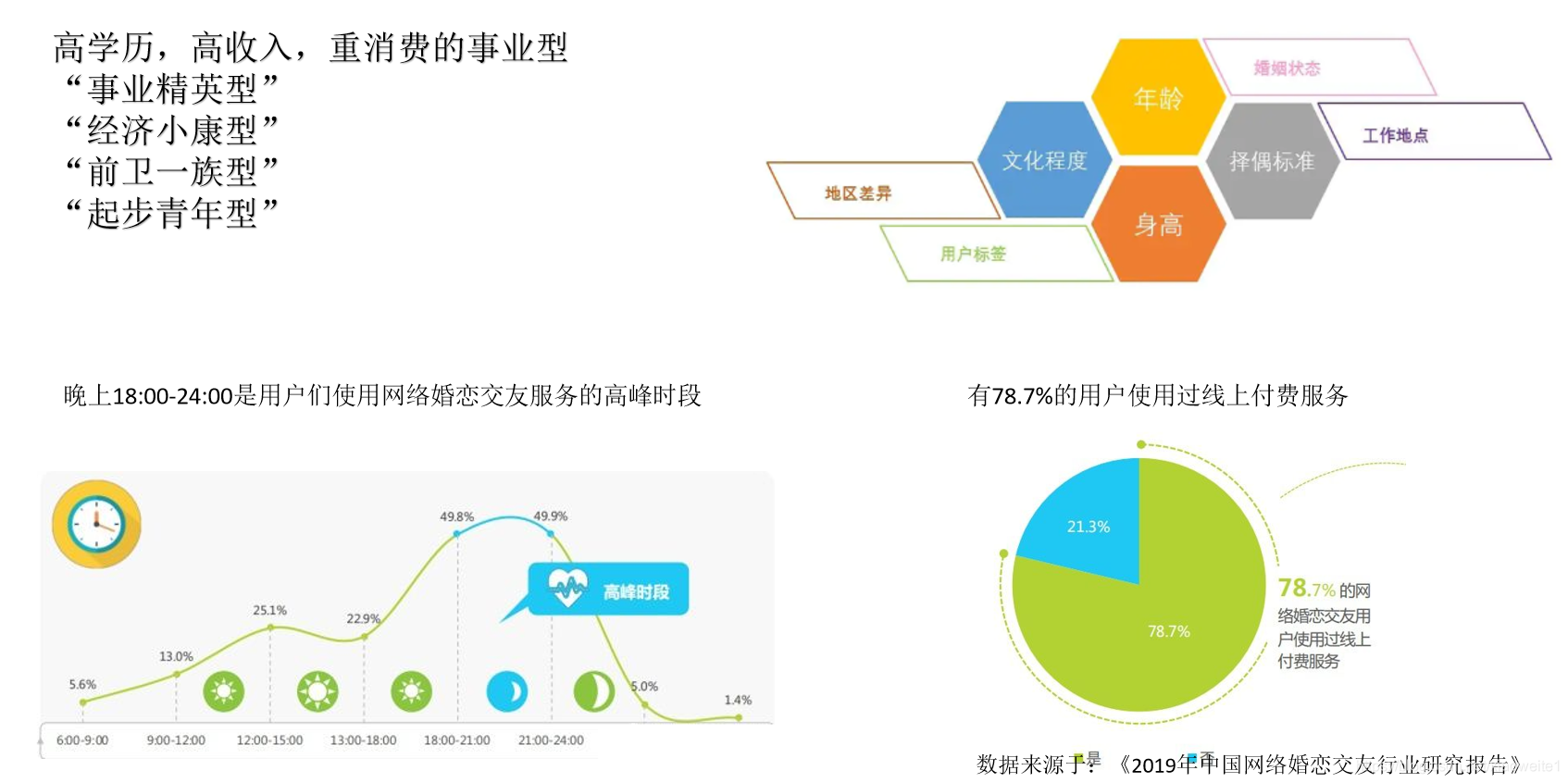
5、相亲场景用户画像分析场景案例
二、双十一面临的技术挑战
双11---世界级互联网技术超级工程!
阿里双11实时业务量和数据量每年都在大幅增长,去年双11的实时计算峰值达到了创纪录的每秒 40 亿条记录,数据体量也达到了惊人的7 TB 每秒,相当于一秒钟需要读完 500 万本《新华字典》。
可以实事求是的说:阿里的双 11 是一次全球商业、科技、数据、智能的大协同,是一个商业社会的大协同,更是一个技术的大协同,是名副其实的世界级互联网技术的超级工程!


短时间内处理这么大的数据量如何解决:高并发、高吞吐、低延迟、稳定性、安全性等问题?
当然,问题很多,解决方案很复杂,今天主要探讨大数据相关的技术解决方案 其他技术方案,可以参考提供的扩展资料!

三、阿里双11大数据技术解决方案
1、Flink流批一体护驾双11
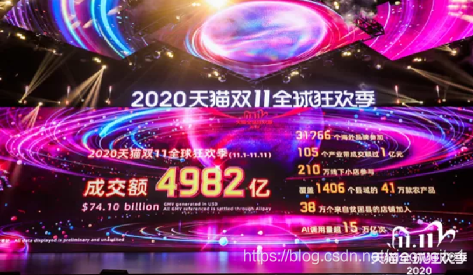
去年的双11,阿里的GMV成交总金额 达到了 4982 亿,实时计算处理的流量洪峰创纪录地达到了每秒40亿条的记录,数据体量也达到了惊人的每秒7TB,基于Flink的流批一体数据应用开始在阿里巴巴最核心的数据业务场景崭露头角,并在稳定性、性能和效率方面都经受住了严苛的生产考验。---丝般顺滑
基于 Flink 的阿里巴巴实时计算平台也圆满完成了去年双 11 整体经济体的实时数据任务保障,再次平稳度过全年大考。
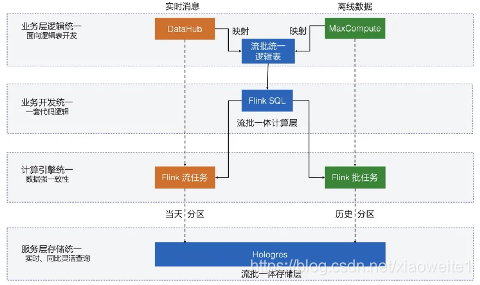
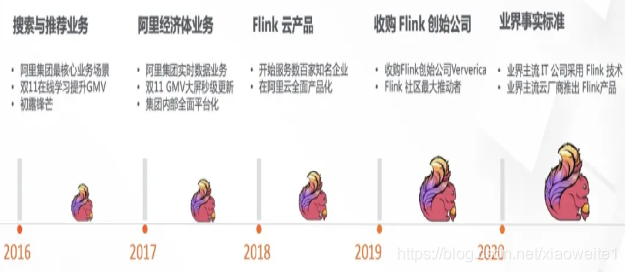
2、Flink简单介绍
2009年Flink 诞生于柏林工业大学的一个大数据研究项目 StratoSphere。
2014 年孵化出 Flink捐献给Apache,并成为 Apache 顶级项目,同时 Flink 的主流方向被定位为流式计算并大数据行业内崭露头角。
2015 年阿里巴巴开始使用 Flink 并持续贡献社区(阿里内部还基于Flink做了一套Blink)
2019年1月8日,阿里巴巴以 9000 万欧元(7亿元人民币)收购了创业公司 Data Artisans。 从此Flink开始了新一轮的乘风破浪!在国内流行的一发不可收拾!

3、Flink官网介绍:https://flink.apache.org/
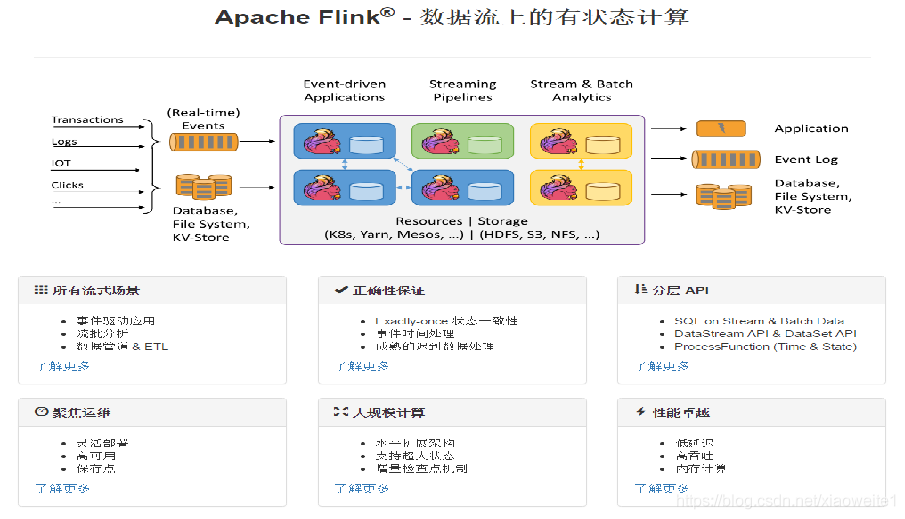
四、Flink实现双十一实时大屏
在大数据的实时处理中,实时的大屏展示已经成了一个很重要的展示项,比如最有名的双十一大屏实时销售总价展示。
今天就做一个最简单的模拟电商统计大屏的小例子,需求如下:
1.实时计算出当天零点截止到当前时间的销售总额
2.计算出各个分类的销售top3
3.每秒钟更新一次统计结果
实现代码
- package cn.lanson.action;
-
- import lombok.AllArgsConstructor;
- import lombok.Data;
- import lombok.NoArgsConstructor;
- import org.apache.commons.lang3.StringUtils;
- import org.apache.flink.api.common.functions.AggregateFunction;
- import org.apache.flink.api.java.tuple.Tuple;
- import org.apache.flink.api.java.tuple.Tuple1;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.source.SourceFunction;
- import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
- import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
- import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
- import org.apache.flink.streaming.api.windowing.time.Time;
- import org.apache.flink.streaming.api.windowing.triggers.ContinuousProcessingTimeTrigger;
- import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
- import org.apache.flink.util.Collector;
-
- import java.math.BigDecimal;
- import java.math.RoundingMode;
- import java.text.SimpleDateFormat;
- import java.util.*;
- import java.util.stream.Collectors;
-
- /**
- * Author Lansonli
- * Desc 模拟双十一电商实时大屏显示:
- * 1.实时计算出当天零点截止到当前时间的销售总额
- * 2.计算出各个分类的销售top3
- * 3.每秒钟更新一次统计结果
- */
- public class DoubleElevenBigScreem {
- public static void main(String[] args) throws Exception {
- //1.env
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
- //2.source
- DataStream<Tuple2<String, Double>> dataStream = env.addSource(new MySource());
-
- //3.transformation
- DataStream<CategoryPojo> result = dataStream
- .keyBy(0)
- .window(
- //定义大小为一天的窗口,第二个参数表示中国使用的UTC+08:00时区比UTC时间早8小时
- TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8))
- )
- .trigger(
- ContinuousProcessingTimeTrigger.of(Time.seconds(1))//定义一个1s的触发器
- )
- .aggregate(new PriceAggregate(), new WindowResult());
-
- //看一下聚合结果
- //result.print("初步聚合结果");
-
- //4.使用上面聚合的结果,实现业务需求:
- // * 1.实时计算出当天零点截止到当前时间的销售总额
- // * 2.计算出各个分类的销售top3
- // * 3.每秒钟更新一次统计结果
- result.keyBy("dateTime")
- .window(TumblingProcessingTimeWindows.of(Time.seconds(1)))//每秒钟更新一次统计结果
- .process(new WindowResultProcess());//在ProcessWindowFunction中实现该复杂业务逻辑
-
- env.execute();
- }
-
- /**
- * 自定义价格聚合函数,其实就是对price的简单sum操作
- */
- private static class PriceAggregate implements AggregateFunction<Tuple2<String, Double>, Double, Double> {
- @Override
- public Double createAccumulator() {
- return 0D;
- }
-
- @Override
- public Double add(Tuple2<String, Double> value, Double accumulator) {
- return accumulator + value.f1;
- }
-
- @Override
- public Double getResult(Double accumulator) {
- return accumulator;
- }
-
- @Override
- public Double merge(Double a, Double b) {
- return a + b;
- }
- }
-
- /**
- * 自定义WindowFunction,实现如何收集窗口结果数据
- */
- private static class WindowResult implements WindowFunction<Double, CategoryPojo, Tuple, TimeWindow> {
- SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
-
- @Override
- public void apply(Tuple key, TimeWindow window, Iterable<Double> input, Collector<CategoryPojo> out) throws Exception {
- BigDecimal bg = new BigDecimal(input.iterator().next());
- double p = bg.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();//四舍五入
-
- CategoryPojo categoryPojo = new CategoryPojo();
- categoryPojo.setCategory(((Tuple1<String>) key).f0);
- categoryPojo.setTotalPrice(p);
- categoryPojo.setDateTime(simpleDateFormat.format(new Date()));
-
- out.collect(categoryPojo);
- }
- }
-
- /**
- * 实现ProcessWindowFunction
- * 在这里我们做最后的结果统计,
- * 把各个分类的总价加起来,就是全站的总销量金额,
- * 然后我们同时使用优先级队列计算出分类销售的Top3,
- * 最后打印出结果,在实际中我们可以把这个结果数据存储到hbase或者redis中,以供前端的实时页面展示。
- */
- private static class WindowResultProcess extends ProcessWindowFunction<CategoryPojo, Object, Tuple, TimeWindow> {
- @Override
- public void process(Tuple tuple, Context context, Iterable<CategoryPojo> elements, Collector<Object> out) throws Exception {
- String date = ((Tuple1<String>) tuple).f0;
- //优先级队列
- //实际开发中常使用PriorityQueue实现大小顶堆来解决topK问题
- //求最大k个元素的问题:使用小顶堆
- //求最小k个元素的问题:使用大顶堆
- //https://blog.csdn.net/hefenglian/article/details/81807527
- Queue<CategoryPojo> queue = new PriorityQueue<>(3,
- (c1, c2) -> c1.getTotalPrice() >= c2.getTotalPrice() ? 1 : -1);//小顶堆
-
- double price = 0D;
- Iterator<CategoryPojo> iterator = elements.iterator();
- int s = 0;
- while (iterator.hasNext()) {
- CategoryPojo categoryPojo = iterator.next();
- //使用优先级队列计算出top3
- if (queue.size() < 3) {
- queue.add(categoryPojo);
- } else {
- //计算topN的时候需要小顶堆,也就是要去掉堆顶比较小的元素
- CategoryPojo tmp = queue.peek();//取出堆顶元素
- if (categoryPojo.getTotalPrice() > tmp.getTotalPrice()) {
- queue.poll();//移除
- queue.add(categoryPojo);
- }
- }
- price += categoryPojo.getTotalPrice();
- }
-
- //按照TotalPrice逆序
- List<String> list = queue.stream().sorted((c1, c2) -> c1.getTotalPrice() <= c2.getTotalPrice() ? 1 : -1)//逆序
- .map(c -> "(分类:" + c.getCategory() + " 销售额:" + c.getTotalPrice() + ")")
- .collect(Collectors.toList());
- System.out.println("时间 :" + date);
- System.out.println("总价 : " + new BigDecimal(price).setScale(2, RoundingMode.HALF_UP));
- System.out.println("Top3 : \n" + StringUtils.join(list, ",\n"));
- System.out.println("-------------");
- }
- }
-
- /**
- * 用于存储聚合的结果
- */
- @Data
- @AllArgsConstructor
- @NoArgsConstructor
- public static class CategoryPojo {
- private String category;//分类名称
- private double totalPrice;//该分类总销售额
- private String dateTime;// 截止到当前时间的时间
- }
-
- /**
- * 模拟生成某一个分类下的订单
- */
- public static class MySource implements SourceFunction<Tuple2<String, Double>> {
- private volatile boolean isRunning = true;
- private Random random = new Random();
- String category[] = {
- "女装", "男装",
- "图书", "家电",
- "洗护", "美妆",
- "运动", "游戏",
- "户外", "家具",
- "乐器", "办公"
- };
-
- @Override
- public void run(SourceContext<Tuple2<String, Double>> ctx) throws Exception {
- while (isRunning) {
- Thread.sleep(10);
- //随机生成一个分类
- String c = category[(int) (Math.random() * (category.length - 1))];
- //随机生成一个该分类下的随机金额的成交订单
- double price = random.nextDouble() * 100;
- ctx.collect(Tuple2.of(c, price));
- }
- }
-
- @Override
- public void cancel() {
- isRunning = false;
- }
- }
- }

五、Flink实现超时订单自动好评
在电商领域会有这么一个场景,如果用户买了商品,在订单完成之后一定时间之内没有做出评价,系统自动给与五星好评, 接下来我使用Flink的定时器来实现这一功能。

实现代码
- package cn.lanson.action;
-
- import org.apache.flink.api.common.state.MapState;
- import org.apache.flink.api.common.state.MapStateDescriptor;
- import org.apache.flink.api.java.tuple.Tuple;
- import org.apache.flink.api.java.tuple.Tuple2;
- import org.apache.flink.configuration.Configuration;
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
- import org.apache.flink.streaming.api.functions.source.SourceFunction;
- import org.apache.flink.util.Collector;
-
- import java.util.Iterator;
- import java.util.Map;
- import java.util.Random;
- import java.util.UUID;
-
- /**
- * Author Lansonli
- * Desc 在电商领域会有这么一个场景,如果用户买了商品,在订单完成之后,一定时间之内没有做出评价,系统自动给与五星好评,
- * 今天我们使用Flink的定时器来实现这一功能。
- */
- public class OrderAutomaticFavorableComments {
- public static void main(String[] args) throws Exception {
- //env
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
- env.enableCheckpointing(5000);
-
- //source
- DataStream<Tuple2<String, Long>> dataStream = env.addSource(new MySource());
-
- //经过interval毫秒用户未对订单做出评价,自动给与好评.为了演示方便,设置了5s的时间
- long interval = 5000L;
- //分组后使用自定义KeyedProcessFunction完成定时判断超时订单并自动好评
- dataStream.keyBy(0).process(new TimerProcessFuntion(interval));
-
- env.execute();
- }
-
- /**
- * 定时处理逻辑
- * 1.首先我们定义一个MapState类型的状态,key是订单号,value是订单完成时间
- * 2.在processElement处理数据的时候,把每个订单的信息存入状态中,这个时候不做任何处理,
- * 并且注册一个定时器(在订单完成时间+间隔时间(interval)时触发).
- * 3.注册的时器到达了订单完成时间+间隔时间(interval)时就会触发onTimer方法,我们主要在这个里面进行处理。
- * 我们调用外部的接口来判断用户是否做过评价,
- * 如果没做评价,调用接口给与五星好评,如果做过评价,则什么也不处理,最后记得把相应的订单从MapState删除
- */
- public static class TimerProcessFuntion extends KeyedProcessFunction<Tuple, Tuple2<String, Long>, Object> {
- //定义MapState类型的状态,key是订单号,value是订单完成时间
- private MapState<String, Long> mapState;
- //超过多长时间(interval,单位:毫秒) 没有评价,则自动五星好评
- private long interval = 0L;
-
- public TimerProcessFuntion(long interval) {
- this.interval = interval;
- }
-
- //创建MapState
- @Override
- public void open(Configuration parameters) {
- MapStateDescriptor<String, Long> mapStateDesc =
- new MapStateDescriptor<>("mapStateDesc", String.class, Long.class);
- mapState = getRuntimeContext().getMapState(mapStateDesc);
- }
-
- //注册定时器
- @Override
- public void processElement(Tuple2<String, Long> value, Context ctx, Collector<Object> out) throws Exception {
- mapState.put(value.f0, value.f1);
- ctx.timerService().registerProcessingTimeTimer(value.f1 + interval);
- }
-
- //定时器被触发时执行
- @Override
- public void onTimer(long timestamp, OnTimerContext ctx, Collector<Object> out) throws Exception {
- Iterator iterator = mapState.iterator();
- while (iterator.hasNext()) {
- Map.Entry<String, Long> entry = (Map.Entry<String, Long>) iterator.next();
- String orderid = entry.getKey();
- boolean evaluated = isEvaluation(entry.getKey()); //调用方法判断订单是否已评价?
- mapState.remove(orderid);
- if (evaluated) {
- System.out.println("订单(orderid: "+orderid+")在"+interval+"毫秒时间内已经评价,不做处理");
- }
- if (evaluated) {
- //如果用户没有做评价,在调用相关的接口给与默认的五星评价
- System.out.println("订单(orderid: "+orderid+")超过"+interval+"毫秒未评价,调用接口自动给与五星好评");
- }
- }
- }
-
- //自定义方法实现查询用户是否对该订单进行了评价,我们这里只是随便做了一个判断
- //在生产环境下,可以去查询相关的订单系统.
- private boolean isEvaluation(String key) {
- return key.hashCode() % 2 == 0;
- }
- }
-
- /**
- * 自定义source模拟生成一些订单数据.
- * 在这里,我们生了一个最简单的二元组Tuple2,包含订单id和订单完成时间两个字段.
- */
- public static class MySource implements SourceFunction<Tuple2<String, Long>> {
- private volatile boolean isRunning = true;
-
- @Override
- public void run(SourceContext<Tuple2<String, Long>> ctx) throws Exception {
- Random random = new Random();
- while (isRunning) {
- Thread.sleep(1000);
- //订单id
- String orderid = UUID.randomUUID().toString();
- //订单完成时间
- long orderFinishTime = System.currentTimeMillis();
- ctx.collect(Tuple2.of(orderid, orderFinishTime));
- }
- }
-
- @Override
- public void cancel() {
- isRunning = false;
- }
- }
- }
六、大数据行业趋势分析
1、新基建和数字化转型助力大数据+AI多场景落地
- 新型基础建设场景分析
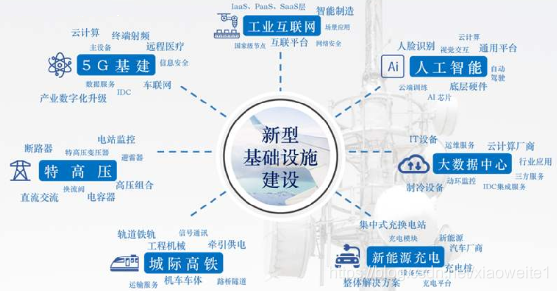
- 各行业数字化转型场景分析
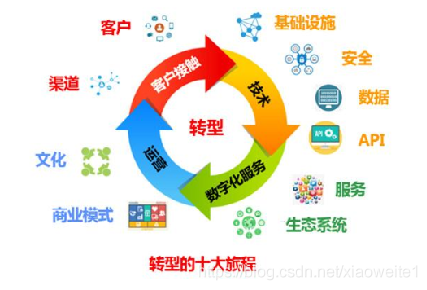
- 发展新机遇,产业新高度
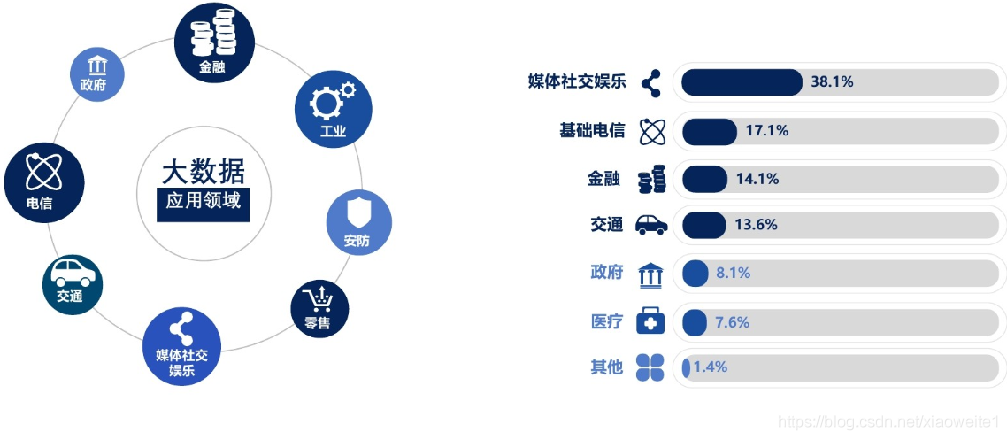
2、多行业场景大数据应用占比
3、从传统物流到智慧物流演变之旅
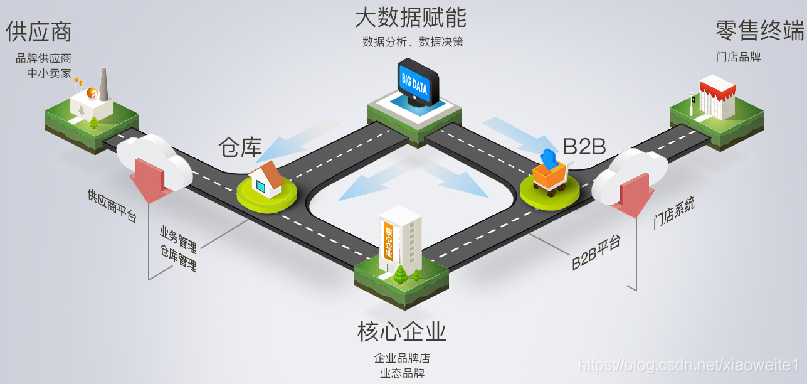
- 赋能新零售:这种收集物流数据、利用物流数据的手段普及到整个零售行业。
- 加持传统物流:物流不等同于快递,与传统物流联手,一定是未来智慧物流的必经之路。
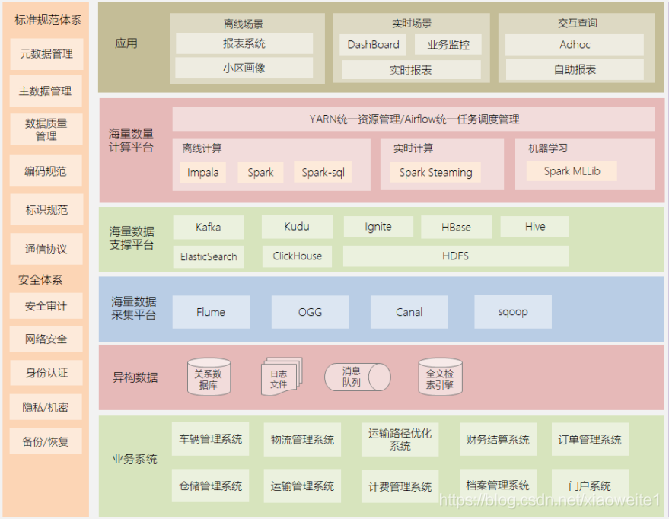
4、智慧物流大数据行业级解决方案
- 基于大型物流公司研发的智慧物流大数据平台,日订单上千万
- 围绕订单、运输、仓储、搬运装卸、包装以及流通加工等物流环节中涉及的数据信息等
- 提高运输以及配送效率、减少物流成本、更有效地满足客户服务要求,并针对数据分析结果,提出具有中观指导意义的解决方案
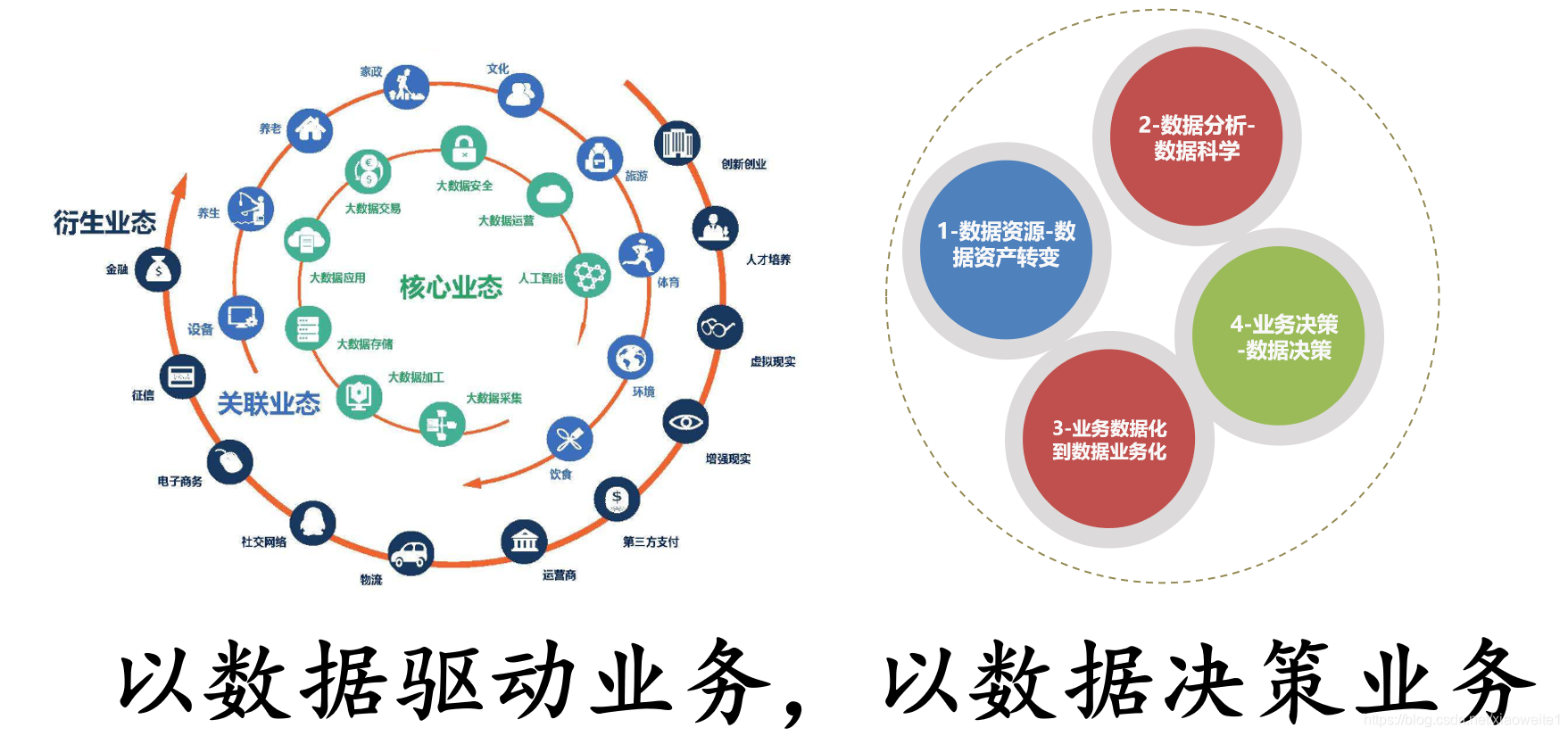
5、大数据行业趋势分析
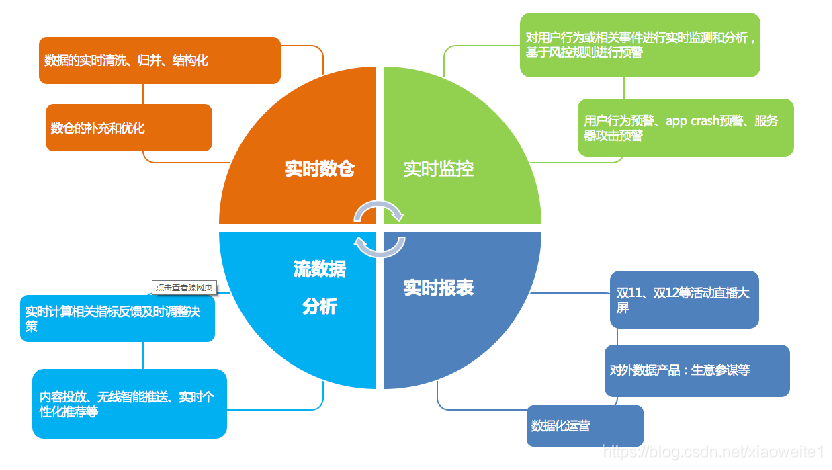
6、大数据技术框架应用
7、大数据开发岗位

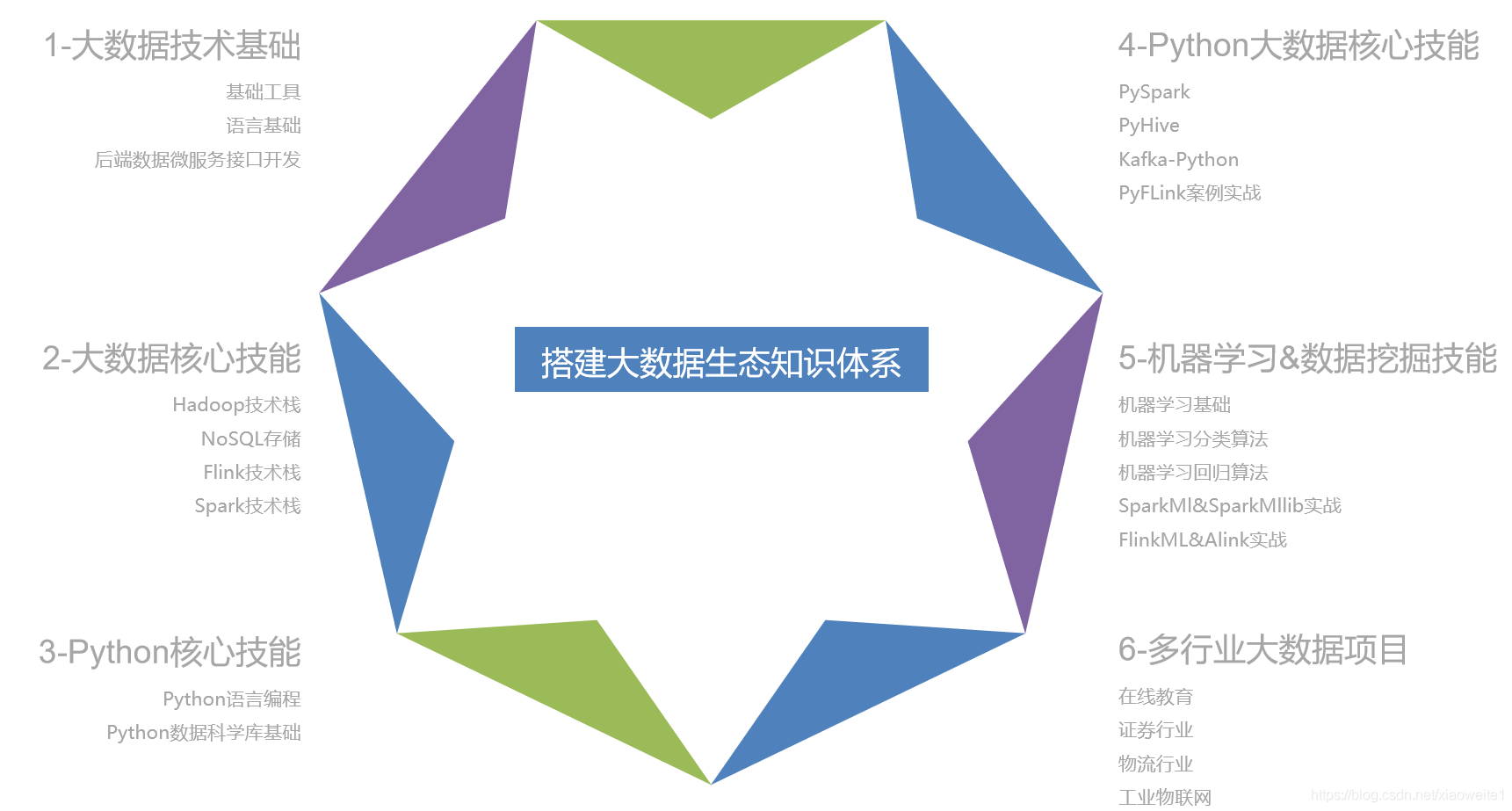
七、大数据技术知识体系
- 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/232893
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

