
热门标签
热门文章
- 1jieba分词添加自定义词或者词典不生效的一种情况解决_jieba自定义词典不生效
- 2步进电动机及其控制_步进电机传递函数
- 3邮箱投递简历,如何正确书写正文和主题?_发简历到邮箱的主题和正文怎么写
- 4intent用法
- 5机器学习(选修)(持续更新)
- 6Intent意图_意图intent
- 7html css+其他注意_fuli8.du
- 8使用Barrier共享鼠标键盘,通过macos控制ubuntu系统
- 9iOS6和iOS7代码的适配(6) —— NSLocalizedString_nslocalizedstring path
- 1012.7pygame游戏开发框架(7):碰撞检测_pygame.sprite.collidepoint
当前位置: article > 正文
click house索引_clickhouse 创建索引
作者:我家自动化 | 2024-03-20 11:55:06
赞
踩
clickhouse 创建索引
稀疏索引
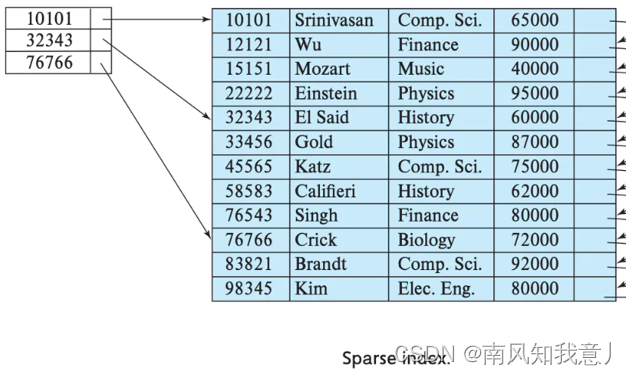
好处: 范围查询过滤比较快
弊端: 不适合点对点查询 索引必须依赖物理存储顺序
排序字段a,b,c 索引字段 a, ab ,abc
索引字段必须是排序字段的前缀
语句级多线程
由于一条数据 不适合高qps的高频短查询,更适合低频的大数据复杂查询 优点:
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index
granularity(颗粒),然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。
在这种设计下,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
弊端:
clickhouse即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多cpu,就不利于同时并发多条查询。所以对于高qps的查询业务,clickhouse并不是强项。
创建二级索引
用法:
create table t_order_mt2(
uid UInt32,
sku_id String,
total_amount Decimal(16,2),
create_time Datetime,
INDEX a total_amount TYPE minmax GRANULARITY 3 //跳数索引
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (uid)
order by (uid,sku_id)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
字段说明:
1,GRANULARITY N 是设定跳数索引对于一级索引粒度的个数
2,minmax GRANULARITY 3 的含义就是为 每3*8192行数据计算一对该列的最大最小值,
3,当扫描行扫描到该区间时,会对比最大最小值,如果不在该范围,就可以直接跳过该区域的扫描。
4,PRIMARYKEY不同,跳数索引可以在建表后,即使已经存储数据后,即时添加,如下:
ALTER TABLE t_order_mt
ADD INDEX skipIdxAmount total_amount TYPE minmax GRANULARITY 3
- 1
- 2
查看一个表是否为二级索引表
1,sql语句:show CREATE TABLE t_order_index2;
- 1
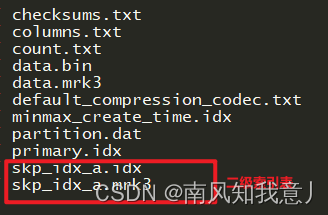
2,进入/var/lib/clickhouse/data/default/t_order_index2/20200602_2_2_0查看文件
- 1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/273179
推荐阅读
相关标签

