
- 1Matlab对语音信号做fft及对语音信号进行分帧加窗_matlab 把音频导入做成fft
- 2NET Framework平台_.net framework平台
- 3OAuth2.0踩坑之路一(获取此资源的范围不足)_error": "insufficient_scope", "error_description":
- 4基于cnn的短文本分类_基于CNN和BiLSTM的文档二分类模型
- 5大数据开发笔试题整合
- 6Android开发之Intent.Action_android.intent.action.date_changed
- 7Docker容器跨主机通信之:直接路由方式_docker不同主机之间互通
- 8el-table 中实现表格可编辑_el-table 可编辑
- 9【云原生】k8s之HPA,命名空间资源限制_命名空间限制
- 10年薪百万难求的AI新技能:Prompt工程中文教程来了!
LoRA大模型加速微调和训练算法解读_lora增量微调
赞
踩
理论
Lora( Low-Rank Adaotation),低秩自适应模型微调的方法,它冻结预训练模型的权重,并将可训练的秩分解矩阵注入到transformer架构的每一层,从而大大减少下游任务的可训练参数的数量,
怎么微调下游任务:利用LoRA对下游任务数据训练时,只通过训练新加部分的参数来适配下游任务,当训练好新的参数后,将新的参数与老的参数合并,利用重参的方式,这样既能在新的任务上达到fine-tune整个效果,又不会在模型推理中增加耗时。
效果
以GPT3为例,Lora可以将训练参数的数量减少10000倍,GPU内存需求减少3倍,LoRA在RoBertTa,GPT2和3上的模型推理结果表现的于微调相当或者更好,并且多加网络层,所以推理没有延时
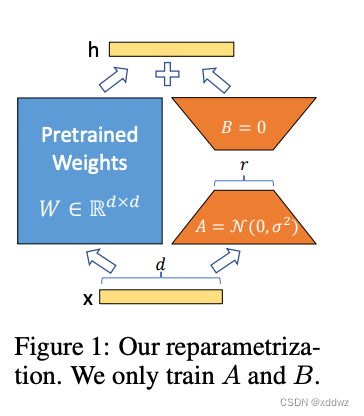
实现的方法
1 低秩参数化更新矩阵
神经 网络 包 含许 多 执行 矩阵 乘 法的 密集 层 。这 些层 中 的权 重 矩阵 通常 是 满秩 的。 在 适应 特定 任 务时, ag hajya n 等 人 (202 0)表 明 , 预 训练 的 语 言模 型 具 有较 低 的“内 在 维度 ” , 尽管 随 机 投影 到 较小的 子空 间 ,但 仍 然可 以有 效 地学 习。 受 此启 发, 我 们假 设 在适 应过 程 中对 权重 的 更新 也具 有 较低的 “内 在秩 ”。 对于 预训 练的 权重 矩阵 W0 ∈ Rd ×k, 我们 用低 秩分 解 W 0 +∆ W = W 0 + BA 来表示它的 更新 ,其 中 B∈ Rd× r, a∈ Rr× k, 秩 R ? min(d, k) .在 训练 期间 , Wis 冻结 0 并 且不 接收 梯度 更新 ,而 A 和 B 包 含可 训练 的参 数。 注意 两个 Wa nd∆ W = B A0 乘以 相同 的输 入, 它们 各自 的输 出向 量按坐标求和。对于 h = Wx,修正 后的 正 向 0 传递 收益 率为 :
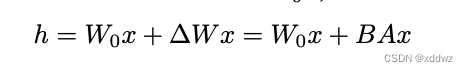
原始权重矩阵W0加上微调权重∆ W,两边参数相加就是整个模型,整个过程通俗来讲,蓝色部分为预训练的模型参数,LoRA在预训练号的模型结构旁加上一个分支,这个分支包含A,B两个结构,这两个参数分别初始化为高斯分布和0,在训练刚开始,附加的参数就是0,A的输入维度和B的输出维度分别与原始模型的输入输出维度相同,而A的输出维度和和B的输入维度是一个远小于原始模型输入输出维度的值,这样做就可以极大的减少待训练的参数,在训练时只更新A,B的参数,预训练好的模型参数固定不变,将AB与原始模型参数矩阵W合并,这样九不会在推断中引入额外的计算,对于不同的下游任务只需要在预训练模型的基础上重新训练A,B就可以。计算的过程例如,原始矩阵是512 * 512,假设r=4,现有用512 * 4的矩阵进行降维,最后的输出再用4 * 512 还原维度,r也可以取值为512,相当于对fine -tuing
作者通过实验表明,lora施加到transformer中的q,k,v,和原始矩阵w上时候,出现的效果是做好的,并且r=4时候效果是最好的。
总结:
冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量
LoRA 几个关键优势
1,预训练模型可以共享,例如Chinese-LLaMA或者stable-difficution ,为不同的任务构建许多小型的LoRA模块,我们可以通过替换矩阵A和B来共享冻结模型并有效切换任务,从而降低存储需要和任务切换开销,
2,当使用Adam这种自适应优化器时候,LoRA可以让训练更有效,并将硬件门槛减低3倍,LORA不需要计算梯度或者维护大多数参数的优化器状态,只需要优化注入,小的多的低秩矩阵
3,LoRA简单的显示设计允许在部署时将训练矩阵与冻结的权重合并,没有多加层,与完全微调模型相比,没有推理延时,
代码
https://github.com/microsoft/LoRA/tree/main
以Linear层为例:
- ```Plain Text
- class Linear(nn.Linear, LoRALayer):
- # LoRA implemented in a dense layer
- def __init__(
- self,
- in_features: int,
- out_features: int,
- r: int = 0,
- lora_alpha: int = 1,
- lora_dropout: float = 0.,
- fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
- merge_weights: bool = True,
- **kwargs
- ):
- nn.Linear.__init__(self, in_features, out_features, **kwargs)
- LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
- merge_weights=merge_weights)
-
- self.fan_in_fan_out = fan_in_fan_out
- # Actual trainable parameters
- if r > 0:
- self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features))) # 用0初始化A的权重,forward中会进行转置
- self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r))) # 用0初始化B的权重,forward中会进行转置
- self.scaling = self.lora_alpha / self.r
- # Freezing the pre-trained weight matrix
- self.weight.requires_grad = False # 冻结预训练的权重
-
- self.reset_parameters()
- if fan_in_fan_out: # False
- self.weight.data = self.weight.data.transpose(0, 1)
-
- def reset_parameters(self):
- nn.Linear.reset_parameters(self)
- if hasattr(self, 'lora_A'): # 再次初始化A的权重
- # initialize A the same way as the default for nn.Linear and B to zero
- nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
- nn.init.zeros_(self.lora_B)
-
- def train(self, mode: bool = True):
- def T(w):
- return w.transpose(0, 1) if self.fan_in_fan_out else w
- nn.Linear.train(self, mode)
- if mode:
- if self.merge_weights and self.merged:
- # Make sure that the weights are not merged
- if self.r > 0:
- self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
- self.merged = False
- else:
- if self.merge_weights and not self.merged:
- # Merge the weights and mark it
- if self.r > 0:
- self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
- self.merged = True
-
- def forward(self, x: torch.Tensor):
- print("self.merged: ", self.merged)
- def T(w):
- return w.transpose(0, 1) if self.fan_in_fan_out else w
- if self.r > 0 and not self.merged:
- result = F.linear(x, T(self.weight), bias=self.bias) # 原来的输出
-
- result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
- return result
- else:
- return F.linear(x, T(self.weight), bias=self.bias)
- ```
-
-
代码分步解读:
1、创建lora_A和lora_b
- self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features))) # 用0初始化A的权重,forward中会进行转置
- self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r))) # 用0初始化B的权重,forward中会进行转置
2、对lora_A和lora_b参数初始化
- def reset_parameters(self):
- nn.Linear.reset_parameters(self)
- if hasattr(self, 'lora_A'): # 再次初始化A的权重
- # initialize A the same way as the default for nn.Linear and B to zero
- nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
- nn.init.zeros_(self.lora_B)
3、通过合并lara_a和lora_b以及预训练模型饿参数,部署时相当于没有增加额外的层:
- if mode:
- if self.merge_weights and self.merged:
- # Make sure that the weights are not merged
- if self.r > 0:
- self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
- self.merged = False
- else:
- if self.merge_weights and not self.merged:
- # Merge the weights and mark it
- if self.r > 0:
- self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
- self.merged = True

