
- 1【2017.11.28】编译可能产生的原因_strupr 用了头文件还是编译错误
- 2微信小程序自定义顶部导航栏、自定义顶部背景颜色、自定义顶部文字_微信小程序自定义顶部文字
- 3STM32CuBeMX+Keil5+STM32F103C8T6开发板环境搭建_cubmax开发stm32f1
- 4oracle获取字符位置instr截取substr_oracle判断字符出现的位置
- 5mac清理软件哪个好用?五大Mac Cleaner介绍推荐
- 6JS监听DOM位置移动_js 监听dom 移入
- 7ios基座无法安装到手机_ios真机设备无法运行未签名的标准基座
- 8element-ui全局添加loading效果_elementui导出加loading
- 9windows connect、接收发送超时 setsocketopt
- 10浏览器调试技巧-记录保存恢复_火狐浏览器导入har文件
ChatGPT :确定性AI源自于确定性数据
赞
踩

ChatGPT 幻觉
大模型实际应用落地过程中,会遇到幻觉(Hallucination)问题。对于语言模型而言,当生成的文本语法正确流畅,但不遵循原文(Faithfulness),或不符合事实(Factualness),我们认为模型出现了幻觉的问题。
在传统的自然语言处理任务中,幻觉一般指的是模型输出不遵循原文,如生成信息与原文信息存在冲突,生成原文中不存在的额外信息等。在大语言模型中,不局限于特定任务,模型幻觉往往指的是与世界知识不一致,即不符合事实。然而,对于输出内容真实性容忍度较低的情况下,大模型幻觉会严重影响落地效果。
所谓“幻觉”,通俗地将就是一本正经地胡说八道。同样是问今天的天气,在百度的文心一言和阿里的通义千问得到的回答依然是不一样。这在人们的日常常生活的对话中,我们还能够容忍,并且容易判断ChatGPT 是不是”幻觉“,但是在商业,制造业和科学教育领域是不允许的。在人类文明和科学发展过程中,我们已经积累了大量明确的知识库,每个机构内部也积累了内部信息和知识库。在商业领域,需要能够回答产品的规格,价格,图片,描述等信息,制造业生产线实时地产生数据,比如产量,设备状态,事件,产品类别,质量信息等等。这些数据是确定的,在制造业和商业环境中应用ChatGPT 需要确定性的回答,而实现确定性的数据支撑。
检索增强生成(Retrieval-Augmented Generation, RAG)
解决ChatGPT 幻觉的一种有效方法是检索增强生成技术。
检索增强生成 (RAG) 是一个 AI 框架,通过将模型建立在外部知识来源的基础上来补充 LLM 的内部信息表示,从而提高 LLM 生成的响应的质量。在基于 LLM 的问答系统中实现 RAG 有两个主要好处:它确保模型能够访问最新、最可靠的事实,并且用户可以访问模型的来源,确保可以检查其声明的准确性并最终可信。
通过将 LLM 建立在一组外部的、可验证的事实之上。这减少了 LLM 泄露敏感数据或“幻觉”不正确或误导性信息的机会。
支撑所有基础模型(包括 LLM)的是一种称为 transformer 的 AI 架构。它将大量原始数据转换为其基本结构的压缩表示形式。从这种原始表示开始,基础模型可以适应各种任务,并对标记的、特定于领域的知识进行一些额外的微调。
但是,仅靠微调很少能为模型提供在不断变化的环境中回答高度具体问题所需的全部知识。在 2020 年的一篇论文中,Meta(当时称为 Facebook)提出了一个称为检索增强生成的框架,让 LLM 能够访问训练数据之外的信息。RAG 允许 LLM 建立在专门的知识体系之上,以更准确的方式回答问题。
“这是开卷考试和闭卷考试之间的区别,”拉斯特拉斯说。“在RAG系统中,你要求模型通过浏览书中的内容来回答一个问题,而不是试图从记忆中记住事实。
检索增强生成的工作原理
如果没有 RAG,LLM 会接受用户输入,并根据它所接受训练的信息或它已经知道的信息创建响应。RAG 引入了一个信息检索组件,该组件利用用户输入首先从新数据源提取信息。用户查询和相关信息都提供给 LLM。LLM 使用新知识及其训练数据来创建更好的响应。以下各部分概述了该过程。
创建外部数据
LLM 原始训练数据集之外的新数据称为外部数据。它可以来自多个数据来源,例如 API、数据库或文档存储库。数据可能以各种格式存在,例如文件、数据库记录或长篇文本。另一种称为嵌入语言模型的 AI 技术将数据转换为数字表示形式并将其存储在向量数据库中。这个过程会创建一个生成式人工智能模型可以理解的知识库。
检索相关信息
下一步是执行相关性搜索。用户查询将转换为向量表示形式,并与向量数据库匹配。例如,考虑一个可以回答组织的人力资源问题的智能聊天机器人。如果员工搜索:“我有多少年假?”,系统将检索年假政策文件以及员工个人过去的休假记录。这些特定文件将被退回,因为它们与员工输入的内容高度相关。相关性是使用数学向量计算和表示法计算和建立的。
增强 LLM 提示
接下来,RAG 模型通过在上下文中添加检索到的相关数据来增强用户输入(或提示)。此步骤使用提示工程技术与 LLM 进行有效沟通。增强提示允许大型语言模型为用户查询生成准确的答案。
更新外部数据
下一个问题可能是——如果外部数据过时了怎么办? 要维护当前信息以供检索,请异步更新文档并更新文档的嵌入表示形式。您可以通过自动化实时流程或定期批处理来执行此操作。这是数据分析中常见的挑战——可以使用不同的数据科学方法进行变更管理。
下图显示了将 RAG 与 LLM 配合使用的概念流程。
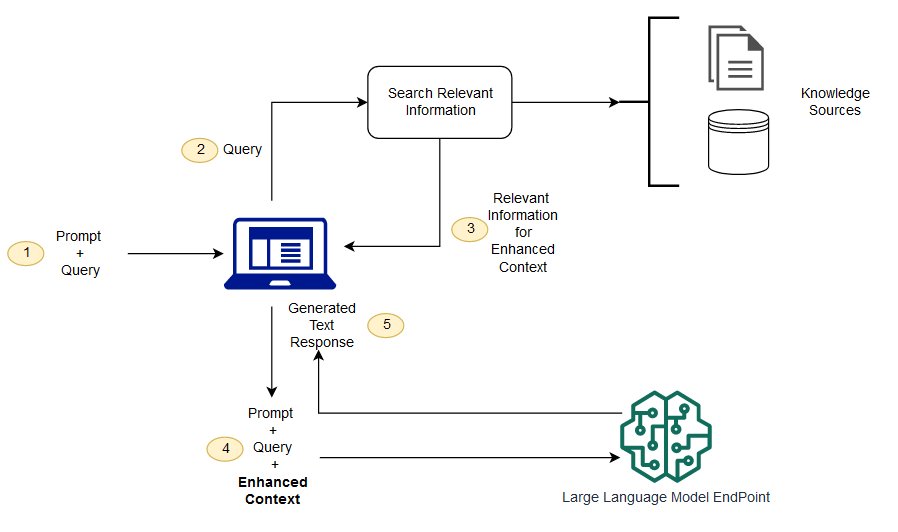
这里的知识源是知识图谱构建的数据库(例如图数据库neo4J)。其中还需要使用矢量数据库技术。
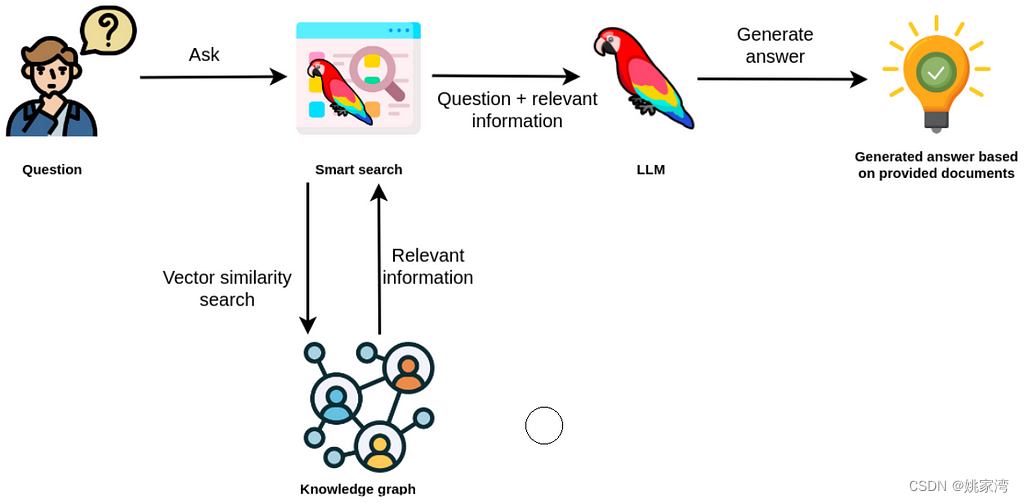
知识库异彩纷呈
ChatGPT横空出世。一些做传统知识图谱的人担心,自己的饭碗是否被chatGPT 替代?也许通用的知识图谱,比如大百科全书,字典等会部分被ChatGPT“ 剽窃”。 已经证明,RAG 要比微调技术更加有效,RAG 成功的基础就在于确定的,高质量的数据库资源。而且微调并不能实现对当前信息的查询。
除了行业知识图谱之外,在工业控制领域还包括产品分类,产品规格,各种模型(例如 OPCUA,I40 AAS),各种标准的本体库都是RAG 需要查询的对象。相信RAG 将给知识图谱更加广泛的普及,从而具有巨大的市场需求。
主数据管理尤为重要
对主数据管理的需求
德勤数字公司最近的一份报告显示,平均一家企业使用 16 个应用程序来利用客户数据,并使用大约 25 个不同的数据源来生成客户洞察。随着数据工具数量的增加,企业很难在整个组织中实现集中且高效的数据管理架构。
何为主数据
企业中发生的流程或交易总是涉及一组特定的实体或概念。根据企业的运营范围,这些实体可能会有所不同,但通常包括以下数据资产:
- 客户
- 产品
- 员工
- 位置
- 其他
- 供应商
- 供应商
- 联系
- 会计项目/发票
- 政策
这些项目通常称为主数据。在业务中执行的所有任务、流程或事务都涉及一个或多个这些主数据对象。
主数据的特点
主数据的类型因组织类型而异,但它们都具有一些相似的品质:
- 挥发性较小。与其他数据相比,主数据的变化频率往往较低,但它确实发生了变化。永不更改的数据集很少被归类为主数据。
- 更复杂。主数据通常包括具有多个变量的更复杂的大型数据集,而不是可以仅进行计数或计数的更简单的实体。主数据需要流程来保持信息的最新和准确。
- 有价值或关键任务。主数据对于组织的日常运营和分析决策至关重要。主数据被反复使用和重用。
- 非事务性。主数据通常不包括事务数据。但是,主数据可以是交易流程的一部分,例如描述客户、产品或购买点的数据。
汽车和制造业的主数据例子
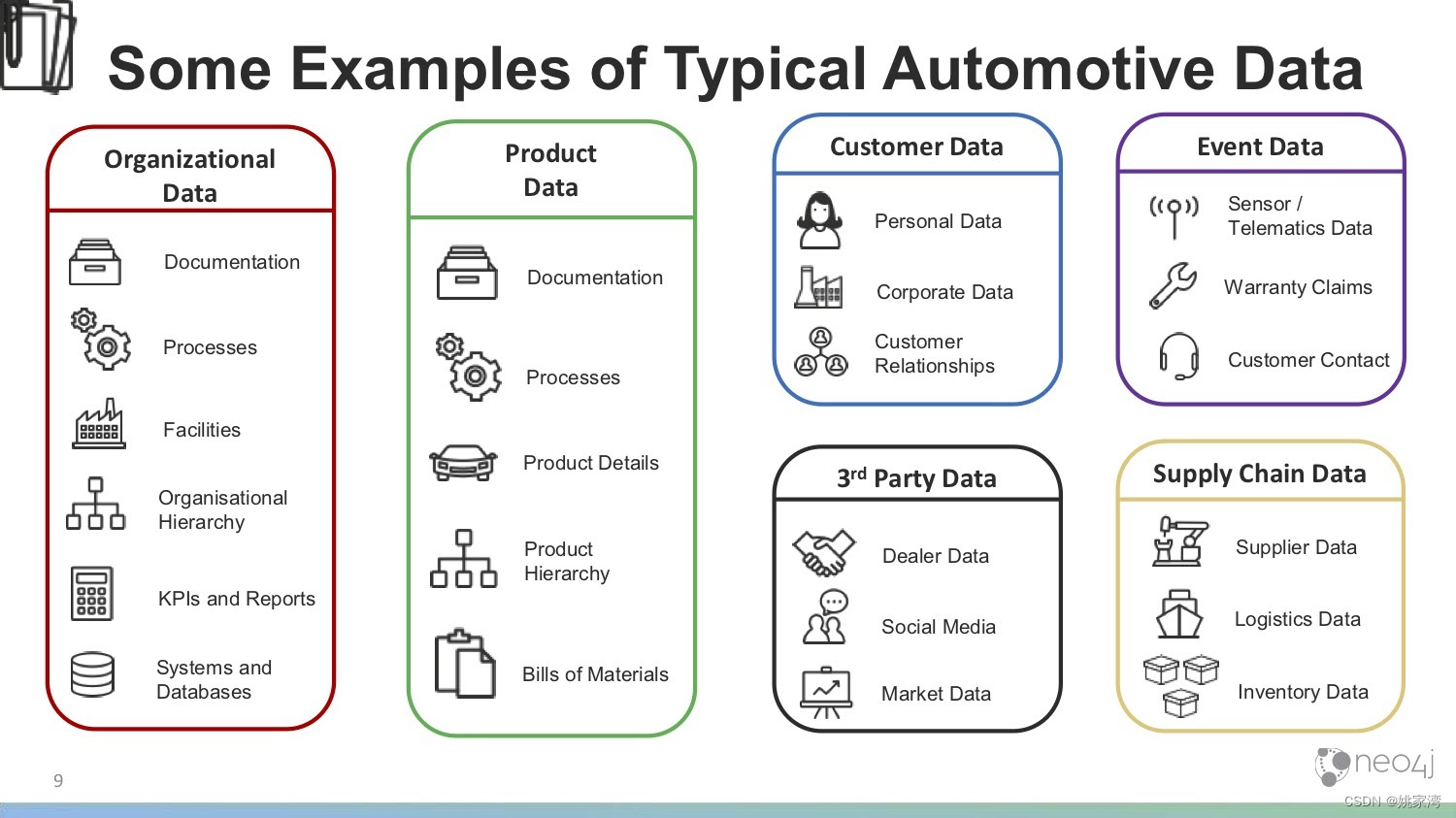
其中产品主数据(PIM)和产品信息管理是使公司能够实现数字化转型的基本要求。
主数据的管理

企业现有的信息通常分布在多个信息子系统中,将它形成主数据,便于企业的信息共享,也有助于企业之间的信息交换,比如产品信息将在供应链企业之间共享。
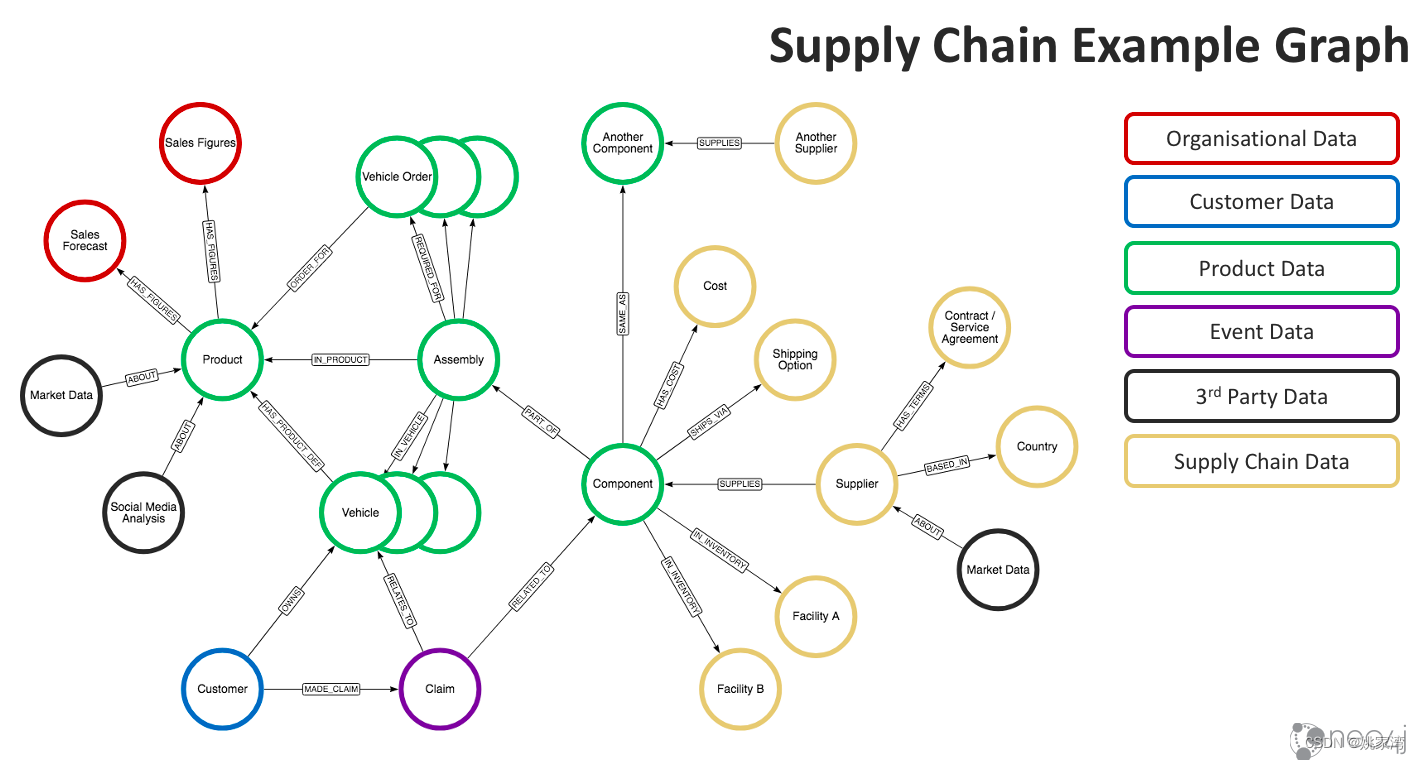
当企业构建了主数据之后,通过RAG 能够导入ChatGPT 中,提供企业全方位的信息访问。
产线数据融于ChatGPT
RAG技术为LLM 搜索外部数据提供了可能,通过OPCUA ,工业4.0 AAS等建模方式,完全可能将产线的全局状态,事件告警,设备健康检测,工艺信息加入ChatGPT中。产生令人惊讶的系统涌现。
笔者看来, 对于开放自动化领域的公司和专家,不必拘泥于工业现场的PLC ,DCS等传统设备的数字化。当下企业更需要打通电商,B2B ,供应链协作,内部数据可视化等立马见效的短平快数字化改造。
符合国际标准的数据建模十分重要
在构建制造领域的知识库,主数据和信息模型时,一个十分重要的问题,要尽可能地符合国际标准。世界贸易,全球化已经发生了重大的变化,世界经济多区域,多经济体发展已成为主流。为了实现多个经济体之间的贸易,必须遵循各种国际标准。例如供应链管理中,普遍采用了BMEcat-1,ETIM ,GS1,ECL@SS等一系列国际标准。国内电商开始采用GS1标准接入方式,欧洲大力推行ECL@SS分类。在制造业自动化领域,OPC UA ,I4.0 AAS 等方兴未艾。 这是国际合作与交流中不可或缺的。
在标准化工作中,要甚重地提独立自主,弯道超车。回顾历史,大多数自己搞一套的标准都是失败地束之高阁。况且,我国也是许多国际标准制定的参与者和贡献者。国际标准凝聚了许多公司的技术和经验,使用国际标准就是站在巨人的肩膀上,也是我们走向世界的通行证。
自作主张地搞一个标准是会觉得很爽,但是没有多少人会接受它,小公司尤其如此。
结束语
ChatGPT 出现的太快了,许多人对它表现出的种种错误嗤之以鼻,但是我们千万不要像当年嘲笑汽车不如马车,只有充分低了解它,就可能找到解决问题的机会和方法。笔者相信,确定性AI 一定会很快来到,而当它到来之时,必定是颠覆性的。

