
- 1华为OD机试 - 执行任务赚积分(Java & JS & Python & C & C++)_做任务赚积分 od
- 2时间序列预测的8种常用方法简介_时间序列预测方法
- 3层次聚类算法
- 4(一)人工智能、AI批量抠图、AI视频抠像、图片换背景、视频换背景、实时抠图、实时抠像、虚拟场景直播系统、虚拟旅游、人像去背景、图像去背景、视频背景消除
- 5AttributeError: ‘Line2D‘ object has no colors‘lable‘ 解决_attributeerror: 'line2d' object has no property 'c
- 6Linux内核源代码 学习笔记_linux kernel 源
- 7系统学习Python——装饰器:基础知识-[装饰器嵌套]
- 8CCS软件的Graph功能_ccs graph
- 9左小右大
- 10springboot学习笔记(sql数据源)_springboot中的sql标签
keras:4)LSTM函数详解_keras的lstm函数
赞
踩
LSTM层
keras.layers.recurrent.LSTM(units, activation='tanh', recurrent_activation='hard_sigmoid', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', unit_forget_bias=True, kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0)
- 1
核心参数
units:输出维度
input_dim:输入维度,当使用该层为模型首层时,应指定该值(或等价的指定input_shape)
return_sequences:布尔值,默认False,控制返回类型。若为True则返回整个序列,否则仅返回输出序列的最后一个输出
input_length:当输入序列的长度固定时,该参数为输入序列的长度。当需要在该层后连接Flatten层,然后又要连接Dense层时,需要指定该参数,否则全连接的输出无法计算出来。
输入shape
形如(samples,timesteps,input_dim)的3D张量
输出shape
如果return_sequences=True:返回形如(samples,timesteps,output_dim)的3D张量否则,返回形如(samples,output_dim)的2D张量
1.输入和输出的类型
相对之前的tensor,这里多了个参数timesteps,其表示啥意思?举个栗子,假如我们输入有100个句子,每个句子都由5个单词组成,而每个单词用64维的词向量表示。那么samples=100,timesteps=5,input_dim=64,你可以简单地理解timesteps就是输入序列的长度input_length(视情而定)
2.units
假如units=128,就一个单词而言,你可以把LSTM内部简化看成
Y
=
X
1
×
64
W
64
×
128
Y=X_{1\times64}W_{64\times128}
Y=X1×64W64×128 ,X为上面提及的词向量比如64维,W中的128就是units,也就是说通过LSTM,把词的维度由64转变成了128
3.return_sequences
我们可以把很多LSTM层串在一起,但是最后一个LSTM层return_sequences通常为false,具体看下面的栗子。
栗子
Sentence01: you are really a genius
model = Sequential()
model.add(LSTM(128, input_dim=64, input_length=5, return_sequences=True))
model.add(LSTM(256, return_sequences=False))
- 1
- 2
- 3
(1)我们把输入的单词,转换为维度64的词向量,小矩形的数目即单词的个数input_length
(2)通过第一个LSTM中的Y=XW,这里输入为维度64,输出为维度128,而return_sequences=True,我们可以获得5个128维的词向量V1’…V5’
(3)通过第二个LSTM,此时输入为V1’…V5’都为128维,经转换后得到V1’’…V5’'为256维,最后因为return_sequences=False,所以只输出了最后一个红色的词向量
网友提问:
(1)activation='tanh’对应哪个门?
我们看看源码:
if self.implementation == 2: #If set to 2 (LSTM/GRU only)
z = K.dot(inputs * dp_mask[0], self.kernel)
z += K.dot(h_tm1 * rec_dp_mask[0], self.recurrent_kernel)
if self.use_bias:
z = K.bias_add(z, self.bias)
z0 = z[:, :self.units]
z1 = z[:, self.units: 2 * self.units]
z2 = z[:, 2 * self.units: 3 * self.units]
z3 = z[:, 3 * self.units:]
i = self.recurrent_activation(z0)
f = self.recurrent_activation(z1)
c = f * c_tm1 + i * self.activation(z2) #**关注点**
o = self.recurrent_activation(z3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
关注点那行代码对应下面的图(这块应该是输入门):
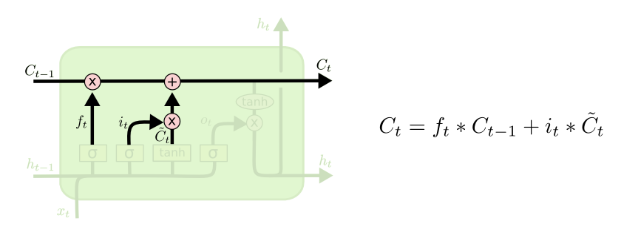
参考:
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
https://www.zhihu.com/question/41949741?sort=created
http://www.cnblogs.com/leeshum/p/6133290.html
http://spaces.ac.cn/archives/4122/ (word2vec和Ebedding的区别)

