
- 1BP,RNN 和 LSTM暨《Supervised Sequence Labelling with Recurrent Neural Networks-2012》阅读笔记
- 2关于CCS软件的Graph功能使用详解_ccs的graph导出
- 3The exception was not handled due to missing onError handler in the subscribe() method call
- 4uni-app 踩坑_小程序uni-indexed-list不生效
- 5Python数据分析的几种绘图方式——数据可视化(附源码)_plt.semilogy
- 6python turtle绘图-案例集锦(小猪佩奇、哆啦A梦、小黄人、樱花树、皮卡丘、汉诺塔、高达、星空等)_turtle绘图案例
- 7Airtest实现小程序自动化测试_airtest小程序自动化
- 8新版本Android Studio Logcat不见得解决办法_android studio 4.0.1找不到logcat
- 9video4linux简介_video4linux: frame mapping timeout (11)
- 10python iphone自动化_Appium+python自动化21-查看iOS上app元素属性
基于LDA的文本主题聚类Python实现_lda 主题分类 jieba
赞
踩
LDA简介
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
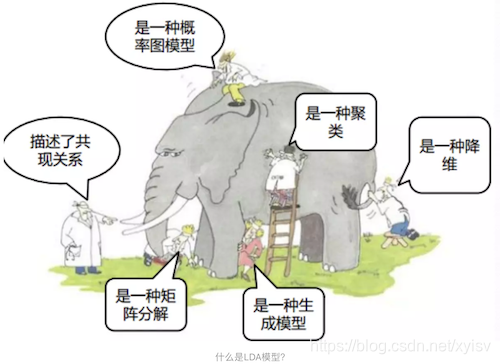
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
关键词:文档主题生成模型,无监督学习,概率模型,NLP
生成过程
对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
1.对每一篇文档,从主题分布中抽取一个主题;
2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
3.重复上述过程直至遍历文档中的每一个单词。
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
具体推导可以参考:https://zhuanlan.zhihu.com/p/31470216
Python范例
使用到的库:jieba, gensim
为了使生成结果更精确,需要构造新词,停用词和同义词词典。
import jieba import jieba.posseg as jp from gensim import corpora, models # Global Dictionary new_words = ['奥预赛', '折叠屏'] # 新词 stopwords = {' ', '再', '的', '们', '为', '时', ':'} # 停用词 synonyms = {'韩国': '南朝鲜', '传言': '流言'} # 同义词 words_nature = ('n', 'nr', 'ns', 'nt', 'eng', 'v', 'd') # 可用的词性 def add_new_words(): # 增加新词 for i in new_words: jieba.add_word(i) def remove_stopwords(ls): # 去除停用词 return [word for word in ls if word not in stopwords] def replace_synonyms(ls): # 替换同义词 return [synonyms[i] if i in synonyms else i for i in ls] documents = [ '足协申请取消女足奥预赛韩国主场比赛 公平原则保障安全', '芬森发声再回应传言:想念辽宁队友 为中国的球迷们祈福', '电商围剿涉疫商家进行时:哄抬物价,就这么罚你', '今晚视频直播华为新品发布会:全新折叠屏手机亮相'] add_new_words() words_ls = [] for text in documents: words = replace_synonyms(remove_stopwords([w.word for w in jp.cut(text)])) words_ls.append(words) # 生成语料词典 dictionary = corpora.Dictionary(words_ls) # 生成稀疏向量集 corpus = [dictionary.doc2bow(words) for words in words_ls] # LDA模型,num_topics设置聚类数,即最终主题的数量 lda = models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=2) # 展示每个主题的前5的词语 for topic in lda.print_topics(num_words=5): print(topic) # 推断每个语料库中的主题类别 print('推断:') for e, values in enumerate(lda.inference(corpus)[0]): topic_val = 0 topic_id = 0 for tid, val in enumerate(values): if val > topic_val: topic_val = val topic_id = tid print(topic_id, '->', documents[e])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54

可以看到,一共分成了两类,文本库中的标题分别分成了0,1两类,即一个是体育类,一个是科技类。
需要注意的是,LDA模型是个无监督的聚类,每次生成的结果可能不同。
参考
- https://www.jianshu.com/p/fa97454c9ffd
- https://zhuanlan.zhihu.com/p/31470216
更多内容访问 omegaxyz.com
网站所有代码采用Apache 2.0授权
网站文章采用知识共享许可协议BY-NC-SA4.0授权
© 2020-2025 • OmegaXYZ-版权所有 转载请注明出处


