
- 1Day27|leetcode 39. 组合总和、40.组合总和II、131.分割回文串
- 2elementui from表单提交_vue+element-ui el-form表单验证及提交验证
- 3鸿蒙开发学习-Day1_delphi 鸿蒙开发
- 4[PTA]实验7-1-1 简化的插入排序
- 5在windows 编译Gnu Global_c++ gnu global windows版本
- 6rust引用本地crate_rust 调用本地程序
- 7逆序输出 题解_一行输入n个整数,按逆序输出数值
- 8chatGPT做了这么一道数学题,我陷入了沉思_chatgpt做2023高考数学题
- 9蓝桥杯刷题-替换字符
- 10Facebook开源AI对话研究平台ParlAI ,解决人机对话最常见5类问题_人机对话国外研究
AI自动生成prompt媲美人类,网友:工程师刚被聘用,又要淘汰了
赞
踩
来源:机器之心
来自多伦多大学、滑铁卢大学等机构的研究者受 prompt engineering 的启发,提出一种使用大型语言模型自动生成和选择指令的新算法,在 24 项任务中有 19 项达到了人类水平的表现。
现阶段,得益于模型规模的扩大和基于注意力架构的出现,语言模型表现出了前所未有的通用性。这些大型语言模型(LLM,large language models)在各种不同任务中表现出非凡的能力,其中包括零样本和小样本设置。
然而,在模型通用性的基础上,继而引出一个控制问题:我们如何才能让 LLM 按照我们的要求去做?
为了回答这个问题并引导 LLM 朝着我们期望的行为方向发展,研究者们采取了一系列措施来达到这个目的,例如对模型进行微调、通过上下文进行学习、不同形式的 prompt 生成等。而基于 prompt 的方法又包括可微调的 soft prompt 以及自然语言 prompt engineering(提示工程)。众多研究者对后者表现出了极大的兴趣,因为它为人类与机器交互提供了一个自然交互的界面。
然而简单的 prompt 并不总能产生所需的结果,例如,在生成熊猫图像时,添加诸如「cute」之类的形容词或诸如「eat bamboo」之类的短语对输出有何影响,我们不了解。
因此,人类用户必须尝试各种 prompt 来引导模型完成我们期望的行为。LLM 这一执行过程可视为黑盒过程:虽然它们可以执行大范围的自然语言程序,但这些程序的处理方式对人类来说可能并不直观,非常难以理解,而且只有在执行下游任务时才能衡量指令的质量。
我们不禁会问:大型语言模型可以为自己编写 prompt 吗?答案是,不但可以,还能达到人类水平。
为了减少创建和验证有效指令的人工工作量,来自多伦多大学、滑铁卢大学等机构的研究者提出了一种使用 LLM 自动生成和选择指令的新算法:APE(Automatic Prompt Engineer)。他们将此问题描述为自然语言程序合成,并建议将其作为黑盒优化问题来处理,LLM 可以用来生成以及搜索可行的候选解决方案。

论文地址:https://arxiv.org/pdf/2211.01910.pdf
论文主页:https://sites.google.com/view/automatic-prompt-engineer
研究者从 LLM 的三个特性入手。首先,使用 LLM 作为推理模型,根据输入 - 输出对形式的一小组演示生成指令候选。接下来,通过 LLM 下的每条指令计算一个分数来指导搜索过程。最后,他们提出一种迭代蒙特卡洛搜索方法,LLM 通过提出语义相似指令变体来改进最佳候选指令。
直观地说,本文提出的算法要求 LLM 根据演示生成一组指令候选,然后要求算法评估哪些指令更有希望,并将该算法命名为 APE。
本文贡献如下:
研究者将指令生成作为自然语言程序合成,将其表述为一个由 LLM 引导的黑盒优化问题,并提出迭代蒙特卡罗搜索方法来近似求解;
APE 方法在 19/24 任务中实现了比人工注释器生成的指令更好或相当的性能。
看到这项研究,网友不禁感叹:那些刚被聘用的 prompt 工程师,几个月后可能要被 AI 淘汰。言外之意就是,这项研究要抢了人类 prompt 工程师的活。

「该研究尽最大的努力使 prompt engineering 自动化,这样从事 ML 的研究人员就可以回到真正的算法问题上了(附加两个大哭的表情)。」
还有人感叹:LLM 不愧是原始 AGI 的中流砥柱。

使用 LLM 进行自然语言程序合成
APE 在建议(proposal)和评分这两个关键组件中都使用 LLM。
如下图 2 和算法 1 所示,APE 首先提出几个候选 prompt,然后根据选定的评分函数对候选集合进行筛选 / 精炼,最终选择得分最高的指令。
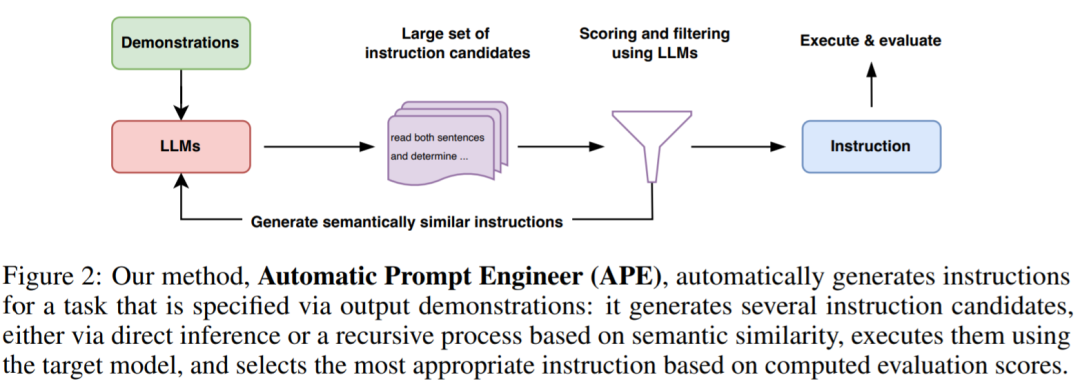
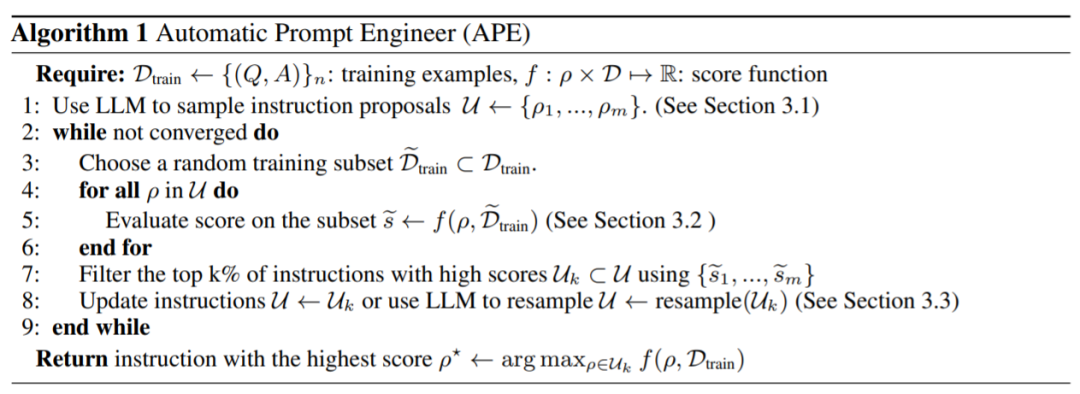
下图为 APE 的执行过程。它可以通过直接推理或基于语义相似度的递归过程生成几个候选 prompt,评估其性能,并迭代地提出新的 prompt。

初始提议分布
由于搜索空间无限大,找到正确指令是极其困难的,这使得自然语言程序合成历来难以处理。基于此,研究者考虑利用一个预先训练过的 LLM 来提出一个候选解决方案,以指导搜索过程。
他们考虑两种方法生成高质量候选。首先采用一种基于前向模式生成的方法。此外,他们还考虑了反向模式生成,使用具有填充功能的 LLM(如 T5、GLM、InsertGPT)来推断缺失的指令。

得分函数
为了将问题转换为黑盒优化问题,研究者选择了一个得分函数来准确测量数据集和模型生成的数据之间的对齐情况。
在归纳实验中,研究者考虑了两个潜在的得分函数。在 TruthfulQA 实验中,研究者主要关注 Lin 等人提出的自动化指标,类似于执行精度。
在每一种情况下,研究者使用如下公式 (1) 来评估生成指令的质量,并对持有测试数据集 Dtest 进行期望。
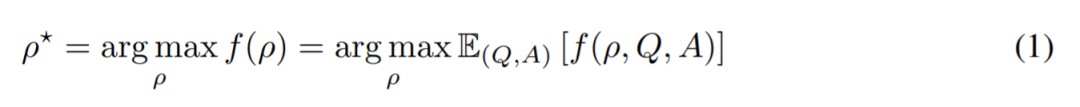
实验
研究者对 APE 如何引导 LLM 实现预期的行为进行了研究。他们从三个角度进行:零样本性能、少样本上下文学习性能和真实性(truthfulness)。
研究者评估了 Honovich 等人提出的 24 个指令归纳任务的零样本和少样本上下文学习。这些任务涵盖语言理解的许多方面,从简单的短语结构到相似性和因果关系识别。为了了解 APE 生成的指令如何引导 LLM 生成不同风格的答案,本文将 APE 应用于 TruthfulQA(一个数据集)。
对于零样本测试准确率,APE 在 24 项任务中有 19 项达到了人类水平的表现。
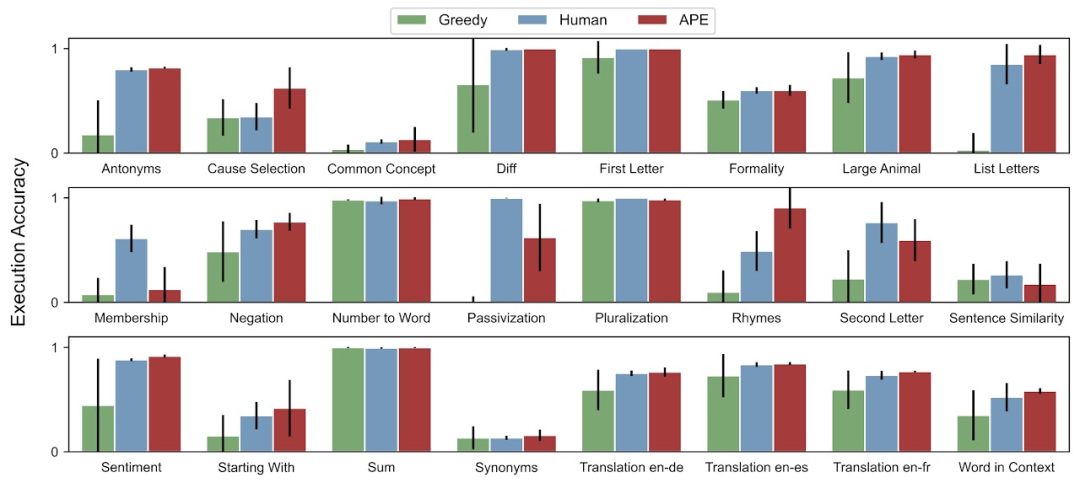
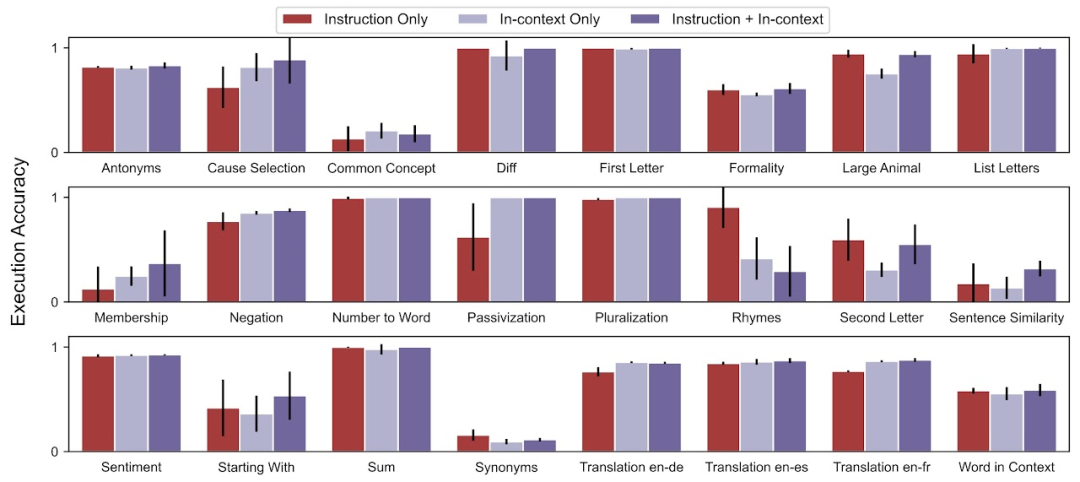
对于少样本上下文测试准确率,在 24 个任务中,APE 提高了 21 个任务的少样本上下文学习性能。
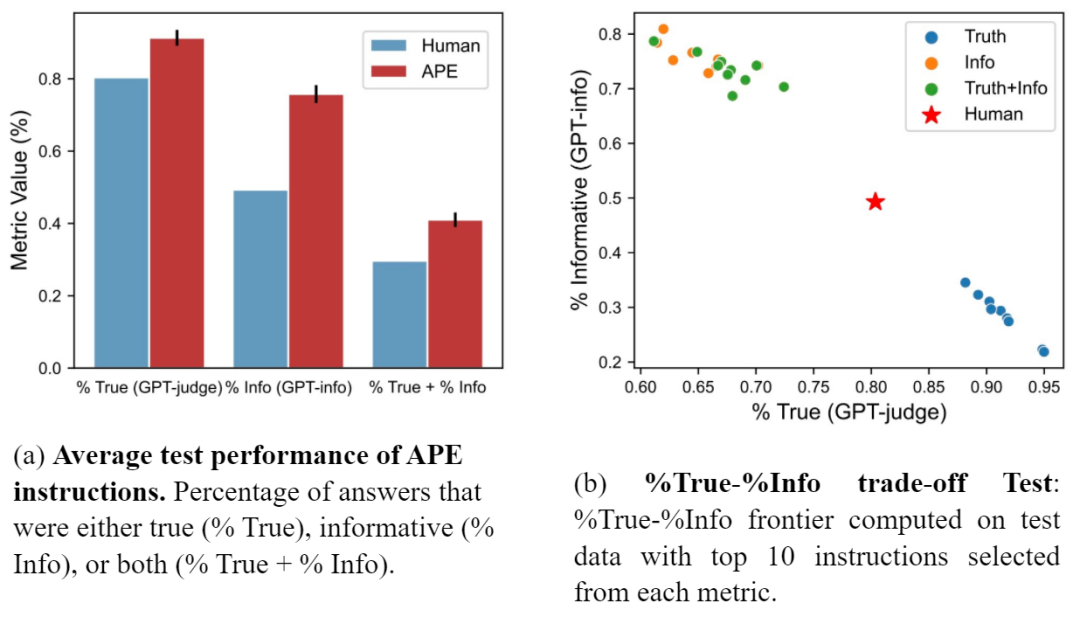
研究者还将 APE prompt 与 Lin 等人提出的人工 prompt 进行了对比。图 (a) 显示 APE 指令在所有三个指标上的表现都优于人工 prompt。图(b)显示了 truthfulness 和 informativeness 之间的权衡。
更多细节请参阅原论文。
推荐阅读
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

