
- 1Unity_打包Android提示找不到jdk解决方案_untiy2017找不到jdk,显示jdk小于1.7
- 2html2canvas将页面dom元素内容渲染成图片保存至本地_canvas渲染html
- 3C语言–函数的递归调用-三种经典例题_使用递归函数调用的方式计算n!。即 n=5,5!=5*4*3*2*1
- 4封装一个适合自己的AutoLayout(基于鸿洋AutoLayout)_基于autolayout封装
- 5Java使用RXTX包进行串口通信_rxtx要什么版本jdk1.8.161
- 6AI技术实践|用腾讯云录音文件识别让无字幕视频自动生成字幕_视频文件ai解析字幕 api
- 7retinex算法_光照问题之常见算法比较(附Python代码)
- 8substance painter anchor point快速教程
- 9深度解读RNN:基于经典论文的原理、关键点与优缺点分析_rnn论文
- 10ubuntu下使用SVN_ubuntu 使用svn
YYDS一道(模型)面试官爱问的考题,这样体系化作答666|(含动手实操资料)_大模型面试题
赞
踩
当我们每次成功训练出一个模型后,如何对模型的性能效果进行评估,这个面试题也是我们在面试候选人的过程中经常出的考题。今天跟大家体系化的说说这个内容,另外还有实操资料帮助大家理解。
当模型相关重要指标满足了实际业务需求,才算模型可以达到落地标准,否则需要对模型进行参数调优,或者重新构建模型,这是模型开发确定与部署应用前的必要工作。模型效果评估的具体工作内容体现在模型训练的性能评估(训练集的模型表现)、模型的样本内测试(验证集的模型表现)、模型的样本外测试(测试集的模型表现)、模型的线上监测等方面。
对于模型性能的评估,根据模型类型的不同(分类、回归、聚类、降维),模型评估指标的维度存在很大差别。因此,我们在具体评估模型的效果时,需要结合模型的类别属性、业务的场景需求、样本的数据体量等情况,来综合评价模型的整体效果。本文将围绕分类模型,来详细介绍下模型的评估指标以及业务理解,具体内容则会通过实际业务场景的样例数据展开分析。
首先,我们描述下业务场景,某金融机构根据存量数据拟开发一个模型,来预测客户是否具有比较高的营销价值,目标为是否高价值客户,属于二分类模型,案例建模样本数据如图1所示。其中,ID为样本主键,Y为目标变量(0和1),X01~X10为特征变量池,且各字段已经过标准化处理。
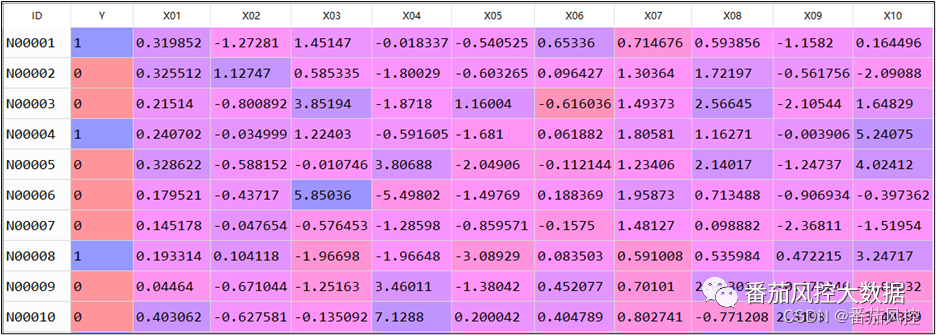
图1 建模样本数据
对建模样本数据做个简单描述性统计分析,结果如图2所示,可见各特征变量均不存在缺失值或异常值,整体数据分布情况较好。
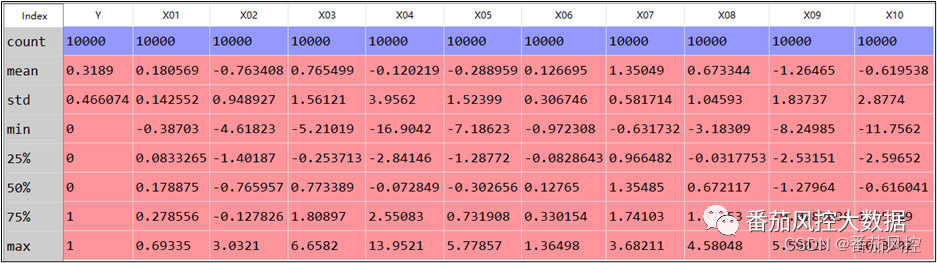
图2 样本描述分析
当初步熟悉了业务场景的建模需求,以及样本数据的分布情况,接下来我们将围绕这份数据进行建模,并重点介绍模型的评估指标与分析方法。对于模型的训练拟合,我们采用XGBoost分类算法来实现,具体如图3所示。
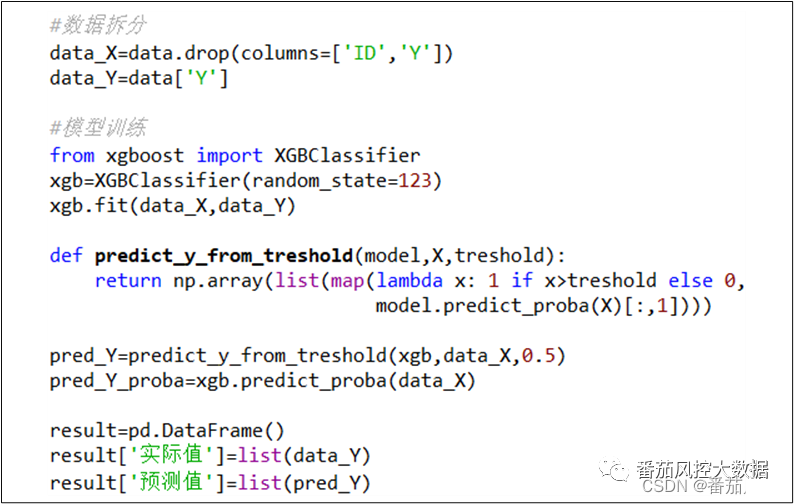
图3 模型训练拟合
在以上的模型训练过程中,模型算法选择默认参数,当模型拟合完成后,输出模型的预测标签pred_Y和预测概率pred_Y_proba,根据这些结果我们便可以算出模型性能的相关评价指标。接下来我们通过原理逻辑与业务理解,分别对分类模型的常用指标进行介绍。
1、混淆矩阵
混淆矩阵也称为误差矩阵,是表示分类模型精度评价的一种标准格式,通过n行n列的矩阵形式来展示。混淆矩阵是分类模型的最底层指标,当模型完成拟合训练后,会输出每个样本的预测结果标签(pred_Y),并与真实标签(data_Y)进行对比汇总,便可以得到混淆矩阵的4个指标,具体如图4所示。
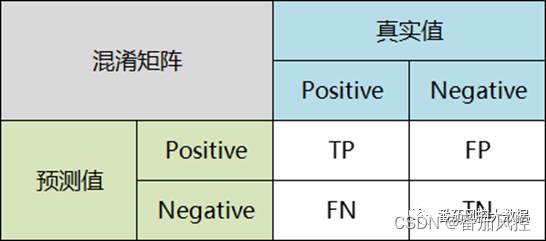
图4 混淆矩阵
(1)TP-真正例(True Positive):实际为正,且预测为正
(2)TN-真负例(True Negative):实际为负,且预测为负
(3)FP-假正例(False Positive):实际为负,但预测为正
(4)FN-假负例(False Negative):实际为正,但预测为负
模型很多评估指标都是根据以上混淆矩阵得到的,例如Accuracy(准确率)、Precision(精确率)、Recall(召回率)等。通过图5代码可以实现混淆矩阵指标,同时将结果打印输出。

图5 混淆矩阵实现
2、准确率与精确率
准确率(Accuracy):又称为ACC,是指分类模型中预测正确的样本数量占所有样本数量的比例。
精确率(Precision):又称为PPV,是指分类模型在预测结果为正样本(Positive)的所有结果中,真正预测正确的比例。
通过图6代码可实现模型Accuracy与Precision的输出:

图6 准确率与精确率
Accuracy是对分类模型整体上正确率的评价,而Precision是分类模型预测为某一类别正确率的评价,从上图结果来看,模型的准确率和精确率都是比较高的。
3、灵敏度与特异度
灵敏度(Sensitivity):又称为TPR,是指真实值为正样本(Positive)的所有结果中,分类模型预测正确的比例;灵敏度又可以称为召回率(Recall)。
特异度(Specificity):又称为TNR,是指真实值为负样本(Negative)的所有结果中,分类模型预测正确的比例。
通过图7代码实现模型TPR与TNR的输出:

图7 灵敏度与特异度
4、召回率与F1分数
召回率(Recall):与灵敏度(TPR)是一致的,仅仅是名称的区别。
F1分数(F1-Score):理想情况下,模型的精确率(Precision)与召回率(Recall)都是越高越好,但实际情况是二者变化往往是相反的,即其中一个升高时而另一个降低,我们很难兼顾两个指标的合适值,此时F1-Score指标便可以综合考虑精确率与召回率,得到更为合理的值。F分数值的原始逻辑源于以下公式,其中w其为权重因子。
当权重w=1时,代表精确率(Precision)与召回率(Recall)的权重是一样的,也就是F1分数(F1-Score)。
通过图8代码实现模型Recall与F1-Score的输出:

图8 召回率与F1分数
5、ROC曲线与AUC
ROC曲线:横纵坐标分别为FPR(False Positive Rate)、TPR(True Positive Rate),其中FPR代表在所有负类中有多少预测为正类,TPR代表在所有正类中有多少预测为正类。模型的ROC曲线样例如图9所示,曲线上的每个点可对应模型不同的分类阈值threshold,当FPR逐渐增大时,说明实际为负类但预测为正类的比例越高;当TPR逐渐增大时,说明实际为正类但预测为正类的比例越高。模型最为理想的情况是TPR=1且FPR=0,对应图中的(0,1)坐标点,也就是曲线越靠近(0,1)点且偏离45度对角线,说明模型的区分度效果越好。
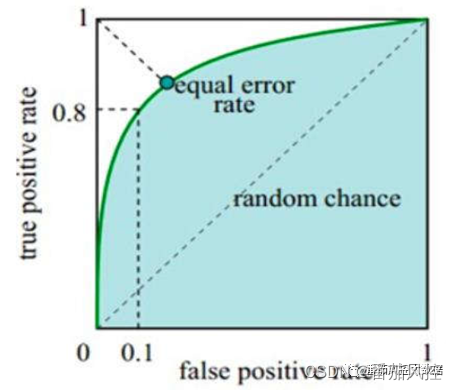
图9 ROC曲线示意图
AUC(Area Under Curve):ROC 曲线下的面积,通常情况下取值范围为0.5~1,可以评价分类模型的区分能力,数值越大说明模型的效果越好。当AUC=1时,模型预测完全正确,在实际业务场景中,一般不存在完美分类器;当AUC=0.5时,模型等同于随机猜测,没有任何预测价值;当0.5<AUC<1时,模型效果优于随机猜测,若合理设定分类阈值,模型有一定预测价值。
通过图10、11代码分别实现模型ROC 曲线与AUC的输出:
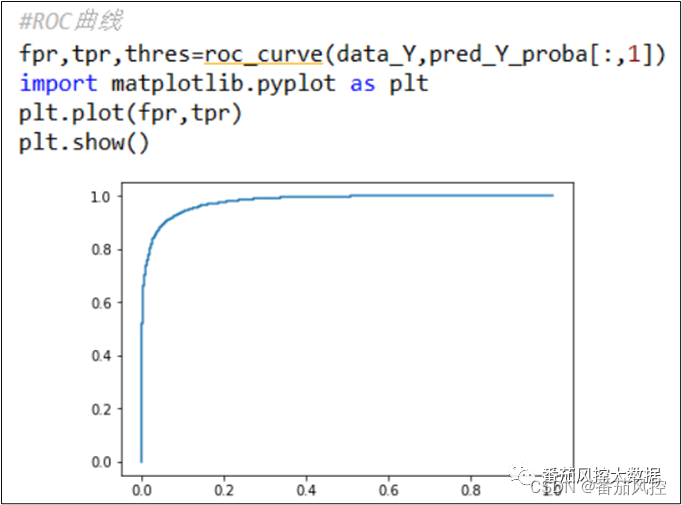
图10 模型ROC曲线

图11模型AUC
由以上结果可知,模型AUC值为0.8149,模型效果表现比较好,对应的ROC曲线也得到直观体现。一般情况下,当模型的AUC值大于0.7时,说明模型具有较好的区分度。
6、KS值
KS(Kolmogorov-Smirnov):衡量的是正负样本累计分部之间的差值,正负样本累计差异越大,KS值就越大,模型的区分能力越强。在实际场景中,根据KS值评价模型好坏的标准不是绝对的,需要结合业务类型、模型算法、样本数据等情况进行综合评估,但整体逻辑思路是一致的。举个例子,同样采用逻辑回归算法建立一个A卡模型,对于银行信用卡中心来讲,模型KS值达到0.4以上是很常见的;对于互联网现金贷,模型KS达到0.3也算很不错;对于海外现金贷,模型KS达到0.2也可以有较好的应用。因此,模型KS结果的效果评估,要结合实际业务场景进行考虑。一般情况下,KS值可以参考以下评估逻辑,如图12所示。
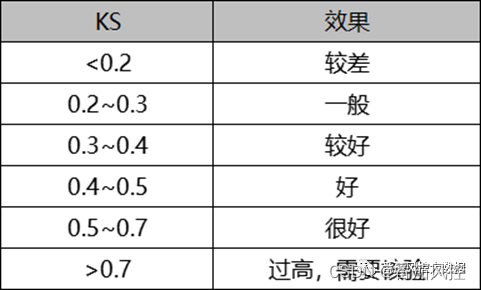
图12 模型KS评估
通过图12代码可实现模型KS的输出:
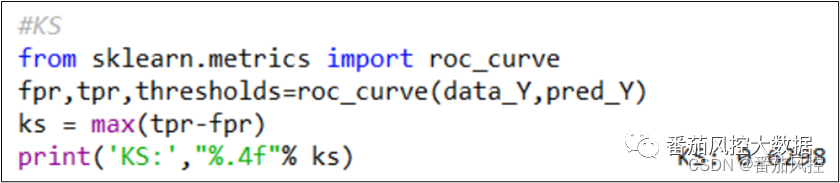
图13 模型KS
由以上结果可知,模型KS值为0.6298,说明模型的区分效果表现较好,也就是区分正负样本的能力较强,可以较好满足实际业务的场景需求。
这里我们回归至本文的案例场景,汇总以上模型整体的评估指标如图14所示。
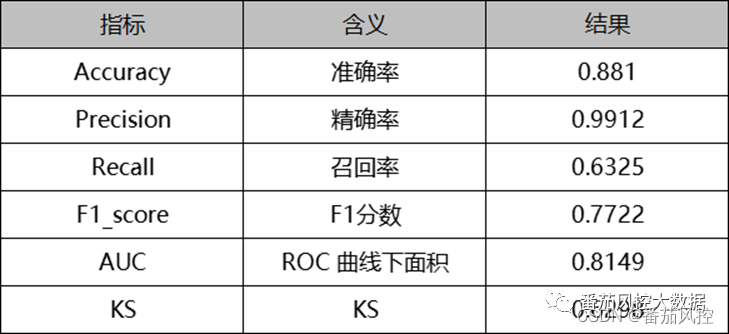
图14 模型综合指标
通过以上常见评价指标结果可知,说明此分类模型的准确度与区分度等性能表现较好,对应到本文案例关于高价值客户预测的目标,体现出模型针对存量数据的高价值客户群体,具有较好的识别区分能力,可以满足业务场景的应用需求。
当然,评估分类模型的指标还有其他维度,例如Gini系数、Lift曲线、Gain曲线等,但是在具体实践过程中,优先评估图14相关区分度指标。此外,从模型稳定度考虑,还需要测试模型与变量的PSI指标,通常看是否满足小于0.1阈值情况。总之,模型性能的评估过程,是一个需要从多个维度综合考虑的工作内容,结合实际业务场景给出一个客观合理的模型评价结果是最重要的。
为了便于各位童鞋对本文关于分类模型效果评估的进一步熟悉,我们准备了与以上内容同步的样本数据与python代码,供大家参考学习,详情请移至知识星球查看。
…
~原创文章

