
热门标签
热门文章
- 1竞赛保研 python的搜索引擎系统设计与实现
- 2Java基于微信小程序的校园订餐小程序的研究与实现,附源码
- 3万字长文推演智能汽车EE架构的终极形态
- 4【IOS开发】SwiftUI中的@State、@Binding、@ObservedObject、@EnvironmentObject等属性包装器的作用和用法,并附上代码案例!!!_swiftui @state
- 5《华为C语言编程规范》summary
- 6【调剂】211西藏大学2020年硕士研究生招生调剂公告
- 7android开发-百度语音识别Android SDK的简单使用,跨平台小程序开发框架_安卓百度语音识别需要哪些权限
- 8使用barrier共享键鼠_barrier安装及使用教程
- 9常见编程语言总结介绍 (包括:C/C++,Java,Go,Python,C#,Javascript,scala,PHP,R,Visual Basic .NET)_c、c++、java、python、c#、visual basic、javascript外的其他编程
- 10在服务器远程配置 jupyter lab / jupyter notebook_jupyter lab 远程
当前位置: article > 正文
大模型中的注意力机制——MHA、GQA、MQA_gqa 注意力 github
作者:我家自动化 | 2024-03-23 23:43:56
赞
踩
gqa 注意力 github
注意力机制是Transformer模型的核心组件。考虑到注意力机制的计算效率问题,研究人员也进行了许多研究。代表的就是以下三种模式:
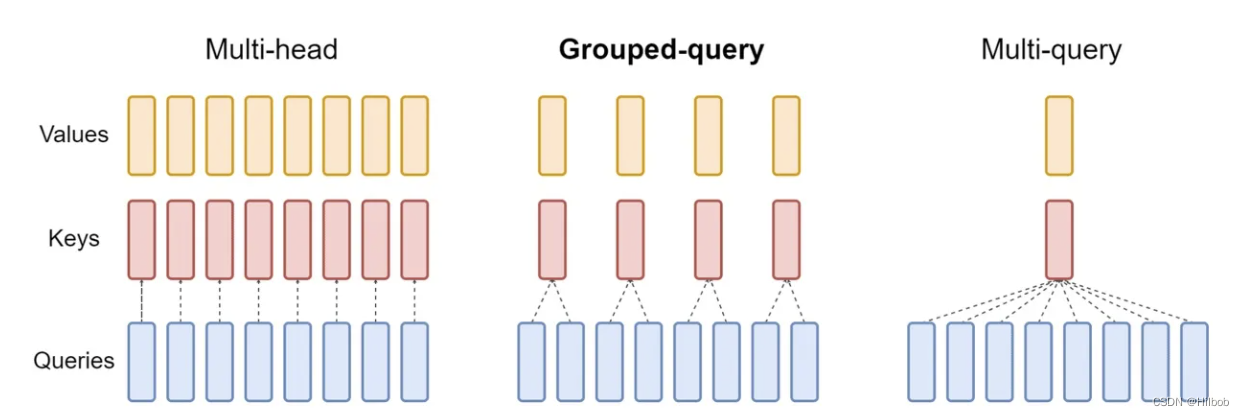
MHA(Multi-head Attention)是标准的多头注意力机制,包含h个Query、Key 和 Value 矩阵。所有注意力头的 Key 和 Value 矩阵权重不共享
MQA(Multi-Query Attention,Fast Transformer Decoding: One Write-Head is All You Need)是多查询注意力的一种变体,也是用于自回归解码的一种注意力机制。与MHA不同的,MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。
GQA(Grouped-Query Attention,GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)是分组查询注意力,GQA将查询头分成G组,每个组共享一个Key 和 Value 矩阵。GQA-G是指具有G组的grouped-query attention。GQA-1具有单个组,因此具有单个Key 和 Value,等效于MQA。若GQA-H具有与头数相等的组,则其等效于MHA。
显然,GQA介于MHA和MQA之间。下图展示了他们的具体结构:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/298454
推荐阅读
相关标签

