
大模型外挂知识库rag综述
赞
踩
参考:知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具 (zsxq.com)
一、LLMs 不足点
在 LLM 已经具备了较强能力的基础上,仍然存在以下问题:
幻觉问题:LLM 文本生成的底层原理是基于概率的 token by token 的形式,因此会不可避免地产生“一本正经的胡说八道”的情况;
时效性问题:LLM 的规模越大,大模型训练的成本越高,周期也就越长。那么具有时效性的数据也就无法参与训练,所以也就无法直接回答时效性相关的问题,例如“帮我推荐几部热映的电影?”;
数据安全问题:通用的 LLM 没有企业内部数据和用户数据,那么企业想要在保证安全的前提下使用 LLM,最好的方式就是把数据全部放在本地,企业数据的业务计算全部在本地完成。而在线的大模型仅仅完成一个归纳的功能;
二、什么是 RAG
RAG(Retrieval Augmented Generation, 检索增强生成),即 LLM 在回答问题或生成文本时,先会从大量文档中检索出相关的信息,然后基于这些信息生成回答或文本,从而提高预测质量。
2.1 R:检索器模块
在 RAG技术中,“R”代表检索,其作用是从大量知识库中检索出最相关的前 k 个文档。然而,构建一个高质量的检索器是一项挑战。研究探讨了三个关键问题:
2.1.1 如何获得准确的语义表示?
在 RAG 中,语义空间指的是查询和文档被映射的多维空间。以下是两种构建准确语义空间的方法。
-
块优化
处理外部文档的第一步是分块,以获得更细致的特征。接着,这些文档块被嵌入。
选择分块策略时,需要考虑被索引内容的特点、使用的嵌入模型及其最适块大小、用户查询的预期长度和复杂度、以及检索结果在特定应用中的使用方式。实际上,准确的查询结果是通过灵活应用多种分块策略来实现的,并没有最佳策略,只有最适合的策略。
-
微调嵌入模型
在确定了 Chunk 的适当大小之后,我们需要通过一个嵌入模型将 Chunk 和查询嵌入到语义空间中。如今,一些出色的嵌入模型已经问世,例如 UAE、Voyage、BGE等,它们在大规模语料库上预训练过
2.1.2 如何协调查询和文档的语义空间?
在 RAG 应用中,有些检索器用同一个嵌入模型来处理查询和文档,而有些则使用两个不同的模型。此外,用户的原始查询可能表达不清晰或缺少必要的语义信息。因此,协调用户的查询与文档的语义空间显得尤为重要。研究介绍了两种关键技术:
-
查询重写
一种直接的方式是对查询进行重写。
可以利用大语言模型的能力生成一个指导性的伪文档,然后将原始查询与这个伪文档结合,形成一个新的查询。
也可以通过文本标识符来建立查询向量,利用这些标识符生成一个相关但可能并不存在的“假想”文档,它的目的是捕捉到相关的模式。
此外,多查询检索方法让大语言模型能够同时产生多个搜索查询。这些查询可以同时运行,它们的结果一起被处理,特别适用于那些需要多个小问题共同解决的复杂问题。
-
嵌入变换
在 Liu 于 2023 年提出的 LlamaIndex 中,研究者们通过在查询编码器后加入一个特殊的适配器,并对其进行微调,从而优化查询的嵌入表示,使之更适合特定的任务。
Li 团队在 2023 年提出的 SANTA 方法,就是为了让检索系统能够理解并处理结构化的信息。他们提出了两种预训练方法:一是利用结构化与非结构化数据之间的自然对应关系进行对比学习;二是采用了一种围绕实体设计的掩码策略,让语言模型来预测和填补这些被掩盖的实体信息。
2.1.3 如何对齐检索模型的输出和大语言模型的偏好?
在 RAG流水线中,即使采用了上述技术来提高检索模型的命中率,仍可能无法改善 RAG 的最终效果,因为检索到的文档可能不符合大语言模型的需求。
因此,研究介绍了如下方法:
大语言模型的监督训练:REPLUG使用检索模型和大语言模型计算检索到的文档的概率分布,然后通过计算 KL 散度进行监督训练。
这种简单而有效的训练方法利用大语言模型作为监督信号,提高了检索模型的性能,消除了特定的交叉注意力机制的需求。
此外,也有一些方法选择在检索模型上外部附加适配器来实现对齐,这是因为微调嵌入模型可能面临一些挑战,比如使用 API 实现嵌入功能或计算资源不足等。因此,一些方法选择在检索模型上外部附加适配器来实现对齐。
除此之外,PKG通过指令微调将知识注入到白盒模型中,并直接替换检索模块,用于根据查询直接输出相关文档。
2.2 G:生成器模块
2.2.1 生成器介绍
介绍:在 RAG 系统中,生成组件是核心部分之一
作用:将检索到的信息转化为自然流畅的文本。在 RAG 中,生成组件的输入不仅包括传统的上下文信息,还有通过检索器得到的相关文本片段。这使得生成组件能够更深入地理解问题背后的上下文,并产生更加信息丰富的回答。此外,生成组件还会根据检索到的文本来指导内容的生成,确保生成的内容与检索到的信息保持一致。
正是因为输入数据的多样性,我们针对生成阶段进行了一系列的有针对性工作,以便更好地适应来自查询和文档的输入数据。
2.2.2 如何通过后检索处理提升检索结果?
介绍:后检索处理指的是,在通过检索器从大型文档数据库中检索到相关信息后,对这些信息进行进一步的处理、过滤或优化。
主要目的:提高检索结果的质量,更好地满足用户需求或为后续任务做准备。
后检索处理策略:包括信息压缩和结果的重新排序。
2.2.3 如何优化生成器应对输入数据?
生成器工作:负责将检索到的信息转化为相关文本,形成模型的最终输出。
其优化目的:在于确保生成文本既流畅又能有效利用检索文档,更好地回应用户的查询。
RAG 的输入不仅包括查询,还涵盖了检索器找到的多种文档(无论是结构化还是非结构化)。一般在将输入提供给微调过的模型之前,需要对检索器找到的文档进行后续处理。
值得注意的是,RAG 中对生成器的微调方式与大语言模型的普通微调方法大体相同,包括有通用优化过程以及运用对比学习等。
三、使用 RAG 的好处?
RAG 方法使得开发者不必为每一个特定的任务重新训练整个大模型,只需要外挂上知识库,即可为模型提供额外的信息输入,提高其回答的准确性。RAG模型尤其适合知识密集型的任务。
可扩展性 (Scalability):减少模型大小和训练成本,并允许轻松扩展知识
准确性 (Accuracy):通过引用信息来源,用户可以核实答案的准确性,这增强了人们对模型输出结果的信任。
可控性 (Controllability):允许更新或定制知识
可解释性 (Interpretability):检索到的项目作为模型预测中来源的参考
多功能性 (Versatility):RAG 可以针对多种任务进行微调和定制,包括QA、文本摘要、对话系统等;
及时性:使用检索技术能识别到最新的信息,这使 RAG 在保持回答的及时性和准确性方面,相较于只依赖训练数据的传统语言模型有明显优势。
定制性:通过索引与特定领域相关的文本语料库,RAG 能够为不同领域提供专业的知识支持。
安全性:RAG 通过数据库中设置的角色和安全控制,实现了对数据使用的更好控制。相比之下,经过微调的模型在管理数据访问权限方面可能不够明确。
四、RAG V.S. SFT

实际上,对于 LLM 存在的上述问题,SFT 是一个最常见最基本的解决办法,也是 LLM 实现应用的基础步骤。那么有必要在多个维度上比较一下两种方法:
当然这两种方法并非非此即彼的,合理且必要的方式是结合业务需要与两种方法的优点,合理使用两种方法。
五、RAG 典型实现方法
RAG 的实现主要包括三个主要步骤:数据索引、检索和生成。
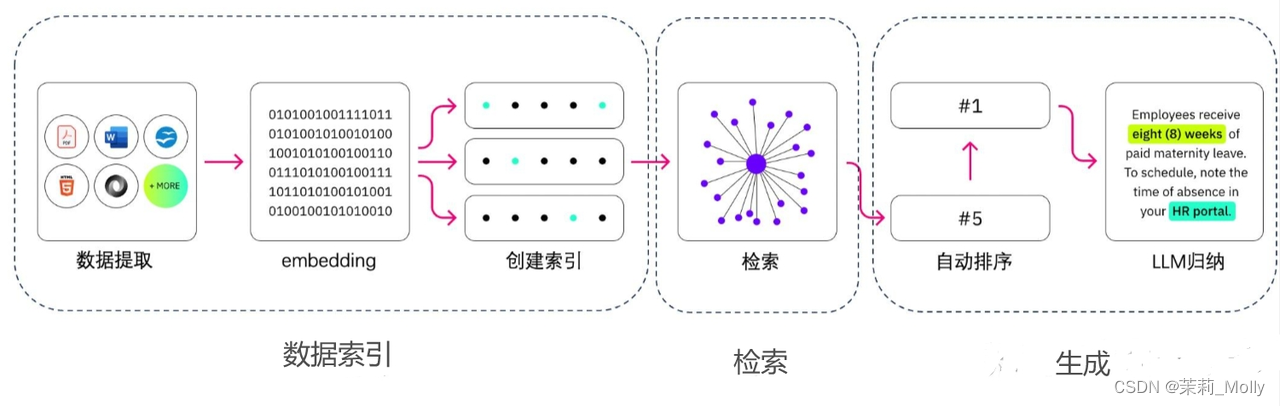
5.1 如何 构建 数据索引?
数据索引一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化(embedding)及创建索引等环节。
step 1:数据提取
即从原始数据到便于处理的格式化数据的过程,具体工程包括:
-
数据获取:包括多格式数据(eg:PDF、word、markdown以及数据库和API等)加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式;
-
Doc类文档:直接解析其实就能得到文本到底是什么元素,比如标题、表格、段落等等。这部分直接将文本段及其对应的属性存储下来,用于后续切分的依据;
-
PDF类文档:
-
难点:如何完整恢复图片、表格、标题、段落等内容,形成一个文字版的文档。
-
解决方法:使用了多个开源模型进行协同分析,例如版面分析使用了百度的PP-StructureV2,能够对Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation10类区域进行检测,统一了OCR和文本属性分类两个任务;
-
-
PPT类文档:
-
难点:如何对PPT中大量的流程图,架构图进行提取,因为这些图多以形状元素在PPT中呈现,如果光提取文字,大量潜藏的信息就完全丢失了。
-
解决方法:将PPT转换成PDF形式,然后用上述处理PDF的方式来进行解析。
-
-
-
数据清洗:对源数据进行去重、过滤、压缩和格式化等处理;
-
信息提取:提提取数据中关键信息,包括文件名、时间、章节title、图片等信息。
Step 2: 文本分割(Chunking)
-
动机:
由于文本可能较长,或者仅有部分内容相关的情况下,需要对文本进行分块切分
-
主要考虑两个因素:
-
embedding模型的Tokens限制情况;
-
语义完整性对整体的检索效果的影响;
-
-
分块的方式有:
-
句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等;
-
固定大小的分块方式:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
-
基于意图的分块方式:
-
句分割:最简单的是通过句号和换行来做切分,常用的意图包有基于NLP的NLTK和spaCy;
-
递归分割:通过分而治之的思想,用递归切分到最小单元的一种方式;
-
特殊分割:用于特殊场景。
-
-
-
常用的工具:
langchain.text_splitter 库中的类CharacterTextSplitter:可以指定分隔符、块大小、重叠和长度函数来拆分文本。
Step 3: 向量化(embedding)及创建索引
向量化(embedding)
-
思路:将文本、图像、音频和视频等转化为向量矩阵的过程,也就是变成计算机可以理解的格式。
-
常见的embedding模型:
创建索引:
-
思路:数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程。
-
常用的工具:
-
FAISS
-
Chromadb
-
ES
-
milvus等;
-
-
注:一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
5.2 如何 对数据进行 检索(Retrieval)?
动机:检索环节是获取有效信息的关键环节
思路:
元数据过滤:当我们把索引分成许多chunks的时候,检索效率会成为问题。这时候,如果可以通过元数据先进行过滤,就会大大提升效率和相关度。
图关系检索:即引入知识图谱,将实体变成node,把它们之间的关系变成relation,就可以利用知识之间的关系做更准确的回答。特别是针对一些多跳问题,利用图数据索引会让检索的相关度变得更高;
检索技术:检索的主要方式还是这几种:
-
向量化(embedding)相似度检索:相似度计算方式包括欧氏距离、曼哈顿距离、余弦等;
-
关键词检索:这是很传统的检索方式,元数据过滤也是一种,还有一种就是先把chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率;
-
全文检索:
-
SQL检索:更加传统的检索算法。
-
-
重排序(Rerank):相关度、匹配度等因素做一些重新调整,得到更符合业务场景的排序。
-
查询轮换:这是查询检索的一种方式,一般会有几种方式:
-
子查询:可以在不同的场景中使用各种查询策略,比如可以使用LlamaIndex等框架提供的查询器,采用树查询(从叶子结点,一步步查询,合并),采用向量查询,或者最原始的顺序查询chunks等;
-
HyDE:这是一种抄作业的方式,生成相似的或者更标准的 prompt 模板。
-
5.3 对于 检索到的文本,如果生成正确回复?
文本生成就是将原始 query 和检索得到的文本组合起来输入模型得到结果的过程,本质上就是个 prompt engineer ing 过程。
此外还有全流程的框架,如 Langchain 和 LlamaIndex ,都非常简单易用,如:
from langchain.chat_models import ChatOpenAI from langchain.schema.runnable import RunnablePassthrough llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) rag_chain = {"context": retriever, "question": RunnablePassthrough()} | rag_prompt | llm rag_chain.invoke("What is Task Decomposition?")
六、RAG 典型案例
6.1 ChatPDF 及其 复刻版
参考:https://www.chatpdf.com/
ChatPDF的实现流程如下:
ChatPDF首先读取PDF文件,将其转换为可处理的文本格式,例如txt格式;
ChatPDF会对提取出来的文本进行清理和标准化,例如去除特殊字符、分段、分句等,以便于后续处理。这一步可以使用自然语言处理技术,如正则表达式等;
ChatPDF使用OpenAI的Embeddings API将每个分段转换为向量,这个向量将对文本中的语义进行编码,以便于与问题的向量进行比较;
当用户提出问题时,ChatPDF使用OpenAI的Embeddings API将问题转换为一个向量,并与每个分段的向量进行比较,以找到最相似的分段。这个相似度计算可以使用余弦相似度等常见的方法进行;
ChatPDF将找到的最相似的分段与问题作为prompt,调用OpenAI的Completion API,让ChatGPT学习分段内容后,再回答对应的问题;
ChatPDF会将ChatGPT生成的答案返回给用户,完成一次查询

6.2 Baichuan
参考:https://www.baichuan-ai.com/home
 百川大模型的搜索增强系统融合了多个模块,包括:
百川大模型的搜索增强系统融合了多个模块,包括:
指令意图理解:深入理解用户指令
智能搜索:精确驱动查询词的搜索
结果增强:结合大语言模型技术来优化模型结果生成的可靠性。
通过这一系列协同作用,大模型实现了更精确、智能的模型结果回答,通过这种方式减少了模型的幻觉。
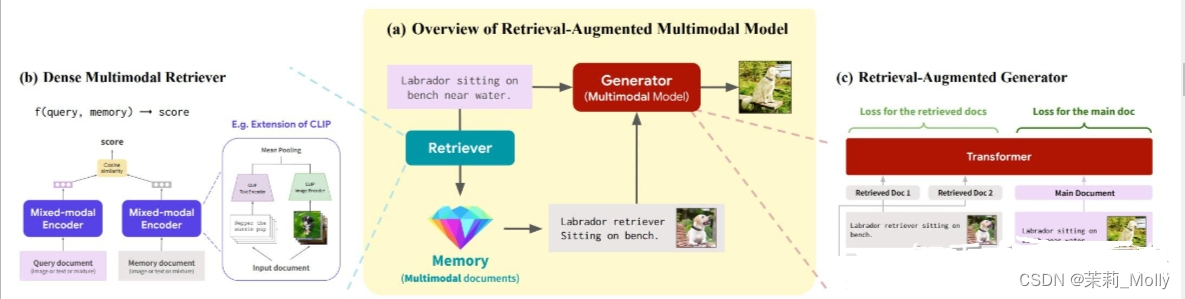
6.3 Multi-modal retrieval-based LMs
参考:https://cs.stanford.edu/~myasu/blog/racm3/
RA-CM3 是一个检索增强的多模态模型,其包含了一个信息检索框架来从外部存储库中获取知识,具体来说,作者首先使用预训练的 CLIP 模型来实现一个检索器(retriever),然后使用 CM3 Transformer 架构来构成一个生成器(generator),其中检索器用来辅助模型从外部存储库中搜索有关于当前提示文本中的精确信息,然后将该信息连同文本送入到生成器中进行图像合成,这样设计的模型的准确性就会大大提高。
七、RAG 存在的问题
检索效果依赖 embedding 和检索算法。目前可能检索到无关信息,反而对输出有负面影响;
大模型如何利用检索到的信息仍是黑盒的。可能仍存在不准确(甚至生成的文本与检索信息相冲突);
对所有任务都无差别检索 k 个文本片段,效率不高,同时会大大增加模型输入的长度;
无法引用来源,也因此无法精准地查证事实,检索的真实性取决于数据源及检索算法。
八、RAG 评估方法
主要有两种方法来评估 RAG 的有效性:独立评估和端到端评估。
8.1 独立评估
8.1.1 独立评估
介绍:独立评估涉及对检索模块和生成模块(即阅读和合成信息)的评估。
8.1.2 独立评估 模块
介绍:生成模块指的是将检索到的文档与查询相结合,形成增强或合成的输入。这与最终答案或响应的生成不同,后者通常采用端到端的评估方式。
评估指标:
1、 答案相关性(Answer Relevancy)
此指标的目标是评估生成的答案与提供的问题提示之间的相关性。答案如果缺乏完整性或者包含冗余信息,那么其得分将相对较低。这一指标通过问题和答案的结合来进行计算,评分的范围通常在0到1之间,其中高分代表更好的相关性。
示例
问题:健康饮食的主要特点是什么? 低相关性答案:健康饮食对整体健康非常重要。 高相关性答案:健康饮食应包括各种水果、蔬菜、全麦食品、瘦肉和乳制品,为优化健康提供必要的营养素。2、 忠实度(Faithfulness)
这个评价标准旨在检查生成的答案在给定上下文中的事实准确性。评估的过程涉及到答案内容与其检索到的上下文之间的比对。这一指标也使用一个介于0到1之间的数值来表示,其中更高的数值意味着答案与上下文的一致性更高。
示例
问题:居里夫人的主要成就是什么? 背景:玛丽·居里(1867-1934年)是一位开创性的物理学家和化学家,她是第一位获得诺贝尔奖的女性,也是唯一一位在两个不同领域获得诺贝尔奖的女性。 高忠实度答案:玛丽·居里在物理和化学两个领域都获得了诺贝尔奖,使她成为第一位实现这一成就的女性。 低忠实度答案:玛丽·居里只在物理学领域获得了诺贝尔奖。3、上下文精确度(Context Precision)
在这个指标中,我们评估所有在给定上下文中与基准信息相关的条目是否被正确地排序。理想情况下,所有相关的内容应该出现在排序的前部。这一评价标准同样使用0到1之间的得分值来表示,其中较高的得分反映了更高的精确度。
指标:命中率 (Hit Rate)、平均排名倒数 (MRR)、归一化折扣累积增益 (NDCG)、**精确度 (Precision)**等。
4、答案正确性(Answer Correctness)
该指标主要用于测量生成的答案与实际基准答案之间的匹配程度。这一评估考虑了基准答案和生成答案的对比,其得分也通常在0到1之间,较高的得分表明生成答案与实际答案的一致性更高。
示例: 基本事实:埃菲尔铁塔于 1889 年在法国巴黎竣工。 答案正确率高:埃菲尔铁塔于 1889 年在法国巴黎竣工。 答案正确率低:埃菲尔铁塔于 1889 年竣工,矗立在英国伦敦。8.2 端到端评估
8.2.1 端到端评估
介绍:对 RAG 模型对特定输入生成的最终响应进行评估,涉及模型生成的答案与输入查询的相关性和一致性。
8.2.2 端到端评估 模块
无标签的内容评估:
评价指标:答案的准确性、相关性和无害性
有标签的内容评估:
评价指标:准确率 (Accuracy) 和精确匹配 (EM)
九、RAG 关键指标和能力
评估 RAG 在不同下游任务和不同检索器中的应用可能会得到不同的结果。然而,一些学术和工程实践已经开始关注 RAG 的通用评估指标和有效运用所需的能力。
关键指标:集中于三个关键指标:答案的准确性、答案的相关性和上下文的相关性。
关键能力:
RGB的研究分析了不同大语言模型在处理 RAG 所需的四项基本能力方面的表现,包括抗噪声能力、拒绝无效回答能力、信息综合能力和反事实稳健性,从而为检索增强型生成设立了标准。
十、RAG 评估框架
在 RAG 评估框架领域,RAGAS 和 ARES 是较新的方法。
10.1 RAGAS
介绍:
RAGAS 是一个基于简单手写提示的评估框架,通过这些提示全自动地衡量答案的准确性、相关性和上下文相关性。
算法原理:
答案忠实度评估:利用大语言模型 (LLM) 分解答案为多个陈述,检验每个陈述与上下文的一致性。最终,根据支持的陈述数量与总陈述数量的比例,计算出一个“忠实度得分”。
答案相关性评估:使用大语言模型 (LLM) 创造可能的问题,并分析这些问题与原始问题的相似度。答案相关性得分是通过计算所有生成问题与原始问题相似度的平均值来得出的。
上下文相关性评估:运用大语言模型 (LLM) 筛选出直接与问题相关的句子,以这些句子占上下文总句子数量的比例来确定上下文相关性得分。
10.2 ARES
介绍:
ARES 的目标是自动化评价 RAG 系统在上下文相关性、答案忠实度和答案相关性三个方面的性能。ARES 减少了评估成本,通过使用少量的手动标注数据和合成数据,并应用预测驱动推理 (PDR) 提供统计置信区间,提高了评估的准确性。
算法原理:
生成合成数据集:ARES 首先使用语言模型从目标语料库中的文档生成合成问题和答案,创建正负两种样本。
训练大语言模型 (LLM) 裁判:然后,ARES 对轻量级语言模型进行微调,利用合成数据集训练它们以评估上下文相关性、答案忠实度和答案相关性。
基于置信区间对 RAG 系统排名:最后,ARES 使用这些裁判模型为 RAG 系统打分,并结合手动标注的验证集,采用 PPI 方法生成置信区间,从而可靠地评估 RAG 系统的性能。
十一、RAG 各模块优化策略
11.1 RAG 工作流程

图1 RAG工作流程(with memory)
从RAG的工作流程看,RAG 模块有:文档块切分、文本嵌入模型、提示工程、大模型生成。
11.2 RAG 各模块优化策略
文档块切分:设置适当的块间重叠、多粒度文档块切分、基于语义的文档切分、文档块摘要。
文本嵌入模型:基于新语料微调嵌入模型、动态表征。
提示工程优化:优化模板增加提示词约束、提示词改写。
大模型迭代:基于正反馈微调模型、量化感知训练、提供大context window的推理模型。
此外,还可对query召回的文档块集合进行处理,比如:元数据过滤、重排序减少文档块数量。
十二、RAG 架构优化策略
12.1 如何利用 知识图谱(KG)进行上下文增强?
12.1.1 典型RAG架构中,向量数据库进行上下文增强 存在哪些问题?
向量数据库进行上下文增强 存在问题:
-
无法获取长程关联知识
-
信息密度低(尤其当LLM context window较小时不友好)
12.1.2 如何利用 知识图谱(KG)进行上下文增强?
策略:增加一路与向量库平行的KG(知识图谱)上下文增强策略。
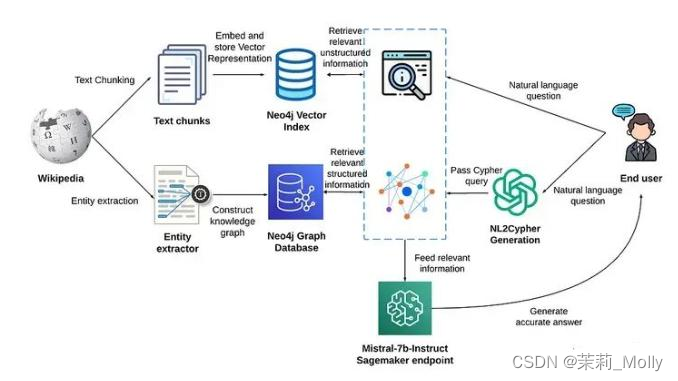
图2 基于KG+VS进行上下文增强
具体方式:对于 用户 query,通过 利用 NL2Cypher 进行 KG 增强;
优化策略:常用 图采样技术来进行KG上下文增强
处理方式:根据query抽取实体,然后把实体作为种子节点对图进行采样(必要时,可把KG中节点和query中实体先向量化,通过向量相似度设置种子节点),然后把获取的子图转换成文本片段,从而达到上下文增强的效果。
12.2 Self-RAG:如何让 大模型 对 召回结果 进行筛选?
12.2.1 典型RAG架构中,向量数据库 存在哪些问题?
经典的RAG架构中(包括KG进行上下文增强),对召回的上下文无差别地与query进行合并,然后访问大模型输出应答。但有时召回的上下文可能与query无关或者矛盾,此时就应舍弃这个上下文,尤其当大模型上下文窗口较小时非常必要(目前4k的窗口比较常见)。
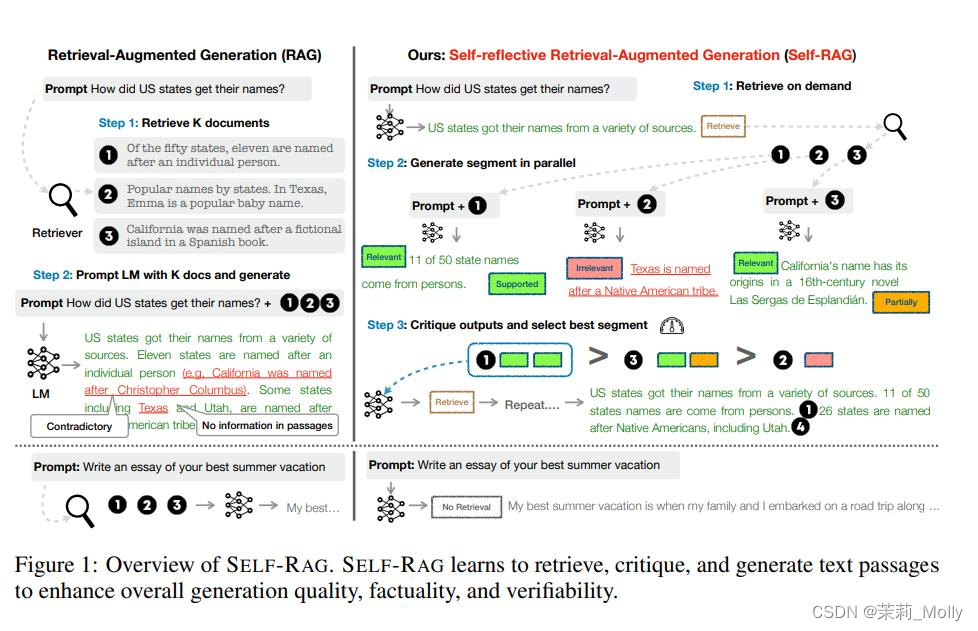
12.2.2 Self-RAG:如何让 大模型 对 召回结果 进行筛选?

图3 RAG vs Self-RAG
Self-RAG 则是更加主动和智能的实现方式,主要步骤概括如下:
-
判断是否需要额外检索事实性信息(retrieve on demand),仅当有需要时才召回;
-
平行处理每个片段:生产prompt + 一个片段的生成结果;
-
使用反思字段,检查输出是否相关,选择最符合需要的片段;
-
再重复检索;
-
生成结果会引用相关片段,以及输出结果是否符合该片段,便于查证事实。
12.2.3 Self-RAG 的 创新点是什么?
Self-RAG 的重要创新:Reflection tokens (反思字符)。通过生成反思字符这一特殊标记来检查输出。这些字符会分为 Retrieve 和 Critique 两种类型,会标示:检查是否有检索的必要,完成检索后检查输出的相关性、完整性、检索片段是否支持输出的观点。模型会基于原有词库和反思字段来生成下一个 token。

12.2.4 Self-RAG 的 训练过程?
对于训练,模型通过将反思字符集成到其词汇表中来学习生成带有反思字符的文本。 它是在一个语料库上进行训练的,其中包含由 Critic 模型预测的检索到的段落和反思字符。 该 Critic 模型评估检索到的段落和任务输出的质量。 使用反思字符更新训练语料库,并训练最终模型以在推理过程中独立生成这些字符。

为了训练 Critic 模型,手动标记反思字符的成本很高,于是作者使用 GPT-4 生成反思字符,然后将这些知识提炼到内部 Critic 模型中。 不同的反思字符会通过少量演示来提示具体说明。 例如,检索令牌会被提示判断外部文档是否会改善结果。
为了训练生成模型,使用检索和 Critic 模型来增强原始输出以模拟推理过程。 对于每个片段,Critic 模型都会确定额外的段落是否会改善生成。 如果是,则添加 Retrieve=Yes 标记,并检索前 K 个段落。 然后 Critic 评估每段文章的相关性和支持性,并相应地附加标记。 最终通过输出反思字符进行增强。
然后使用标准的 next token 目标在此增强语料库上训练生成模型,预测目标输出和反思字符。 在训练期间,检索到的文本块被屏蔽,并通过反思字符 Critique 和 Retrieve 扩展词汇量。 这种方法比 PPO 等依赖单独奖励模型的其他方法更具成本效益。 Self-RAG 模型还包含特殊令牌来控制和评估其自身的预测,从而实现更精细的输出生成。
12.2.5 Self-RAG 的 推理过程?
Self-RAG 使用反思字符来自我评估输出,使其在推理过程中具有适应性。 根据任务的不同,可以定制模型,通过检索更多段落来优先考虑事实准确性,或强调开放式任务的创造力。 该模型可以决定何时检索段落或使用设定的阈值来触发检索。
当需要检索时,生成器同时处理多个段落,产生不同的候选。 进行片段级 beam search 以获得最佳序列。 每个细分的分数使用 Critic 分数进行更新,该分数是每个批评标记类型的归一化概率的加权和。 可以在推理过程中调整这些权重以定制模型的行为。 与其他需要额外训练才能改变行为的方法不同,Self-RAG 无需额外训练即可适应。
12.2.6 Self-RAG 的 代码实战?
下面对开源的 Self-RAG 进行推理测试,可在这里下载模型 selfrag_llama2_13b ,按照官方指导使用 vllm 进行推理服务
from vllm import LLM, SamplingParams model = LLM("selfrag/selfrag_llama2_7b", download_dir="/gscratch/h2lab/akari/model_cache", dtype="half") sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False) def format_prompt(input, paragraph=None): prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input) if paragraph is not None: prompt += "[Retrieval]<paragraph>{0}</paragraph>".format(paragraph) return prompt query_1 = "Leave odd one out: twitter, instagram, whatsapp." query_2 = "What is China?" queries = [query_1, query_2] #for a query that doesn't require retrieval preds = model.generate([format_prompt(query) for query in queries], sampling_params) for pred in preds: print("Model prediction: {0}".format(pred.outputs[0].text)) #输出结果如下,其中第一段结果不需要检索,第二段结果出现[Retrieval] 字段,因为这个问题需要更细粒度的事#实依据。 ''' Model prediction: Twitter:[Utility:5]</s> Model prediction: China is a country located in East Asia.[Retrieval]<paragraph>It is the most populous country in the world, with a population of over 1.4 billion people.[Retrieval]<paragraph>China is a diverse country with a rich history and culture.[Retrieval]<paragraph>It is home to many different ethnic groups and languages, and its cuisine, art, and architecture reflect this diversity.[Retrieval]<paragraph>China is also a major economic power, with a rapidly growing economy and a large manufacturing sector.[Utility:5]</s> ''' #我们还可以在输入中增加补充信息: for a query that needs factual grounding prompt = format_prompt("Can you tell me the difference between llamas and alpacas?", "The alpaca (Lama pacos) is a species of South American camelid mammal. It is similar to, and often confused with, the llama. Alpacas are considerably smaller than llamas, and unlike llamas, they were not bred to be working animals, but were bred specifically for their fiber.") preds = model.generate([prompt], sampling_params) print([pred.outputs[0].text for pred in preds]) ''' 输出结果如下,Self-RAG 找到相关的插入文档并生成有证据支持的答案。 ['<paragraph>The main difference between llamas and alpacas is their size and fiber.[Continue to Use Evidence]Llamas are much larger than alpacas, and they have a much coarser fiber.[Utility:5]</s>'] '''12.3 多向量检索器多模态RAG篇
多向量检索器(Multi-Vector Retriever)核心想法:将文档(用于答案合成)和引用(用于检索)分离,这样可以针对不同的数据类型生成适合自然语言检索的摘要,同时保留原始的数据内容。它可以与多模态 LLM 结合,实现跨模态的 RAG。

12.3.1 如何让 RAG 支持 多模态数据格式?
12.3.1.1 如何让 RAG 支持 半结构化RAG(文本+表格)
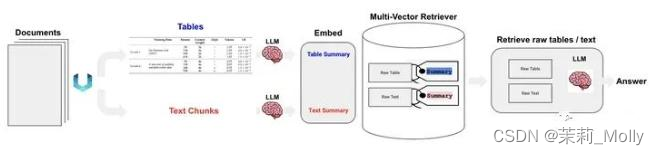
图5 半结构化RAG
此模式要同时处理文本与表格数据。其核心流程梳理如下[8]:
-
将原始文档进行版面分析(基于Unstructured工具[9]),生成原始文本 和 原始表格。
-
原始文本和原始表格经summary LLM处理,生成文本summary和表格summary。
-
用同一个embedding模型把文本summary和表格summary向量化,并存入多向量检索器。
-
多向量检索器存入文本/表格embedding的同时,也会存入相应的summary和raw data。
-
用户query向量化后,用ANN检索召回raw text和raw table。
-
根据query+raw text+raw table构造完整prompt,访问LLM生成最终结果。
12.3.1.2 如何让 RAG 支持 多模态RAG(文本+表格+图片)?

图6 多模态RAG
如图6所示,对多模态RAG而言有三种技术路线,如下我们做个简要说明:
-
选项1:对文本和表格生成summary,然后应用多模态embedding模型把文本/表格summary、原始图片转化成embedding存入多向量检索器。对话时,根据query召回原始文本/表格/图像。然后将其喂给多模态LLM生成应答结果。
-
选项2:首先应用多模态大模型(GPT4-V、LLaVA、FUYU-8b)生成图片summary。然后对文本/表格/图片summary进行向量化存入多向量检索器中。当生成应答的多模态大模型不具备时,可根据query召回原始文本/表格+图片summary。
-
选项3:前置阶段同选项2相同。对话时,根据query召回原始文本/表格/图片。构造完整Prompt,访问多模态大模型生成应答结果。
12.3.1.3 如何让 RAG 支持 私有化多模态RAG(文本+表格+图片)?
如果数据安全是重要考量,那就需要把RAG流水线进行本地部署。比如可用LLaVA-7b生成图片摘要,Chroma作为向量数据库,Nomic's GPT4All作为开源嵌入模型,多向量检索器,Ollama.ai中的LLaMA2-13b-chat用于生成应答。
12.4 RAG Fusion 优化策略
思路:检索增强这一块主要借鉴了RAG Fusion技术,这个技术原理比较简单,概括起来就是,当接收用户query时,让大模型生成5-10个相似的query,然后每个query去匹配5-10个文本块,接着对所有返回的文本块再做个倒序融合排序,如果有需求就再加个精排,最后取Top K个文本块拼接至prompt。
优点:
-
增加了相关文本块的召回率;
-
对用户的query自动进行了文本纠错、分解长句等功能
缺点:
无法从根本上解决理解用户意图的问题
12.5 模块化 RAG 优化策略
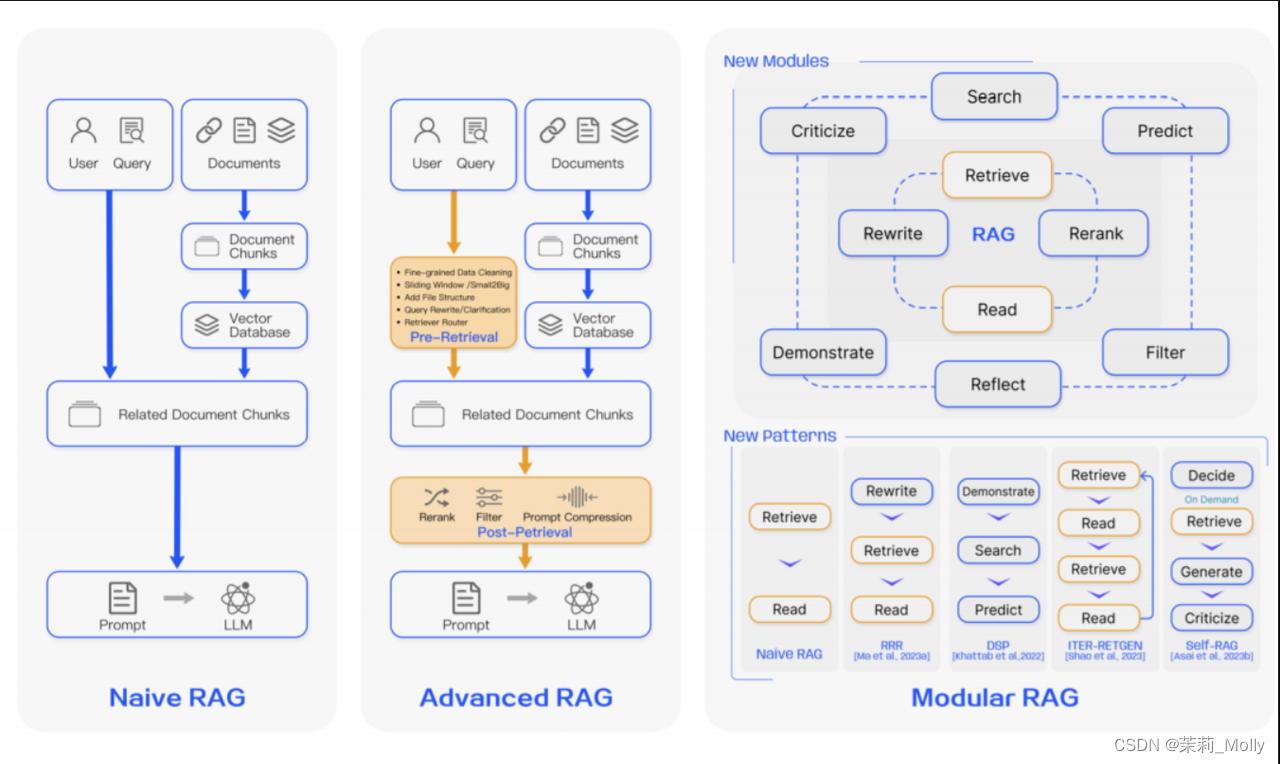
动机:打破了传统的“原始 RAG”框架,这个框架原本涉及索引、检索和生成,现在提供了更广泛的多样性和更高的灵活性。
模块介绍:
搜索模块: 融合了直接在(附加的)语料库中进行搜索的方法。这些方法包括利用大语言模型(LLM)生成的代码、SQL、Cypher 等查询语言,或是其他定制工具。其搜索数据源多样,涵盖搜索引擎、文本数据、表格数据或知识图等。
记忆模块: 本模块充分利用大语言模型本身的记忆功能来引导信息检索。其核心原则是寻找与当前输入最为匹配的记忆。这种增强检索的生成模型能够利用其自身的输出来自我提升,在推理过程中使文本更加贴近数据分布,而非仅依赖训练数据。
额外生成模块: 面对检索内容中的冗余和噪声问题,这个模块通过大语言模型生成必要的上下文,而非直接从数据源进行检索。通过这种方式,由大语言模型生成的内容更可能包含与检索任务相关的信息。
任务适应模块: 该模块致力于将 RAG 调整以适应各种下游任务。
对齐模块: 在 RAG 的应用中,查询与文本之间的对齐一直是影响效果的关键因素。在模块化 RAG 的发展中,研究者们发现,在检索器中添加一个可训练的 Adapter 模块能有效解决对齐问题。
验证模块: 在现实世界中,我们无法总是保证检索到的信息的可靠性。检索到不相关的数据可能会导致大语言模型产生错误信息。因此,可以在检索文档后加入一个额外的验证模块,以评估检索到的文档与查询之间的相关性,这样做可以提升 RAG的鲁棒性。
12.6 RAG 新模式 优化策略
RAG 的组织方法具有高度灵活性,能够根据特定问题的上下文,对 RAG 流程中的模块进行替换或重新配置。在基础的 Naive RAG 中,包含了检索和生成这两个核心模块,这个框架因而具备了高度的适应性和多样性。目前的研究主要围绕两种组织模式:
-
增加或替换模块在增加或替换模块的策略中,我们保留了原有的检索 - 阅读结构,同时加入新模块以增强特定功能。RRR 提出了一种重写 - 检索 - 阅读的流程,其中利用大语言模型(LLM)的性能作为强化学习中重写模块的奖励机制。这样,重写模块可以调整检索查询,从而提高阅读器在后续任务中的表现。
-
调整模块间的工作流程在调整模块间流程的领域,重点在于加强语言模型与检索模型之间的互动。
12.7 RAG 结合 SFT
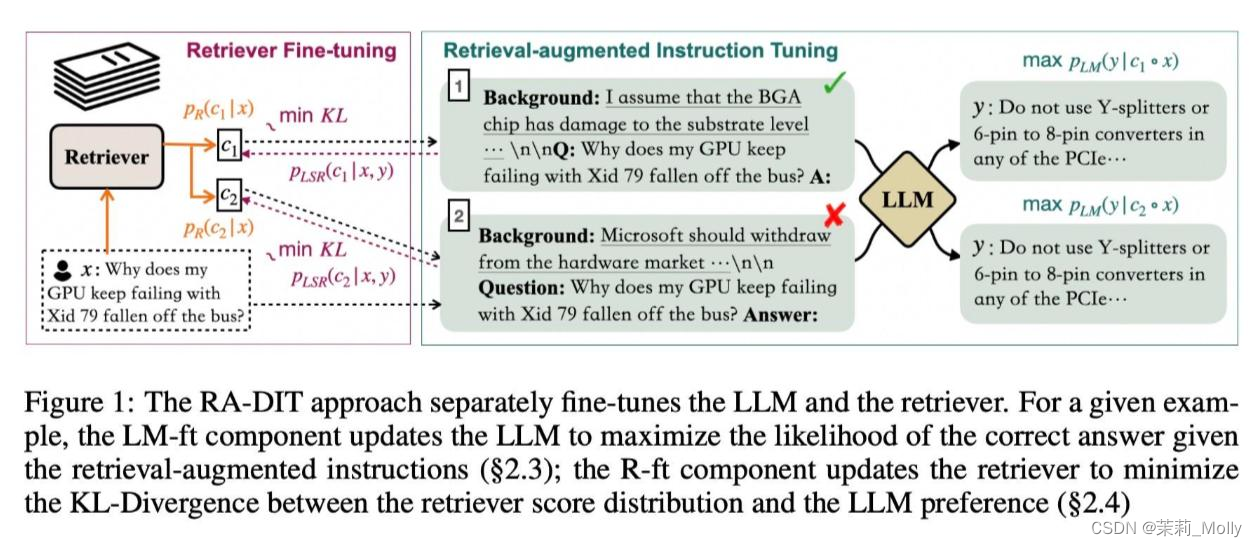
参考:https://arxiv.org/pdf/2310.01352.pdf
RA-DIT 方法 策略:
更新 LLM。以最大限度地提高在给定检索增强指令的情况下正确答案的概率;
更新检索器。以最大限度地减少文档与查询在语义上相似(相关)的程度。
优点:通过这种方式,使 LLM 更好地利用相关背景知识,并训练 LLM 即使在检索错误块的情况下也能产生准确的预测,从而使模型能够依赖自己的知识。
12.8 查询转换(Query Transformations)
动机:在某些情况下,用户的 query 可能出现表述不清、需求复杂、内容无关等问题;
查询转换(Query Transformations):利用了大型语言模型(LLM)的强大能力,通过某种提示或方法将原始的用户问题转换或重写为更合适的、能够更准确地返回所需结果的查询。LLM的能力确保了转换后的查询更有可能从文档或数据中获取相关和准确的答案。
查询转换的核心思想:用户的原始查询可能不总是最适合检索的,所以我们需要某种方式来改进或扩展它。

12.9 bert在RAG中具体是起到了一个什么作用
RAG 中,对于一些 传统任务(eg:分类、抽取等)用 bert 效率会快很多,虽然会牺牲一点点效果,但是 比起 推理时间,前者更被容忍;而对于一些生成式任务(改写、摘要等),必须得用 LLMs,原因:
1. Bert 窗口有限,只支持 512个字符,对于 这些生成任务是远远不够的;
2. LLMs 生成能力 比 Bert 系列要强很多,这个时候,时间换性能 就变得很有意义
十三、RAG 索引优化
13.1 嵌入优化策略
微调嵌入
-
影响因素:影响到 RAG 的有效性;
-
目的:让检索到的内容与查询之间的相关性更加紧密;
-
作用:可以比作在语音生成前对“听觉”进行调整,优化检索内容对最终输出的影响。特别是在处理不断变化或罕见术语的专业领域,这些定制化的嵌入方法能够显著提高检索的相关性。
动态嵌入(Dynamic Embedding)
介绍:不同于静态嵌入(static embedding),动态嵌入根据单词出现的上下文进行调整,为每个单词提供不同的向量表示。例如,在 Transformer 模型(如 BERT)中,同一单词根据周围词汇的不同,其嵌入也会有所变化。
检索后处理流程
-
动机:
-
一次性向大语言模型展示所有相关文档可能会超出其处理的上下文窗口限制。
-
将多个文档拼接成一个冗长的检索提示不仅效率低,还会引入噪声,影响大语言模型聚焦关键信息。
-
-
优化方法:
-
ReRank(重新排序)
-
Prompt 压缩
-
RAG 管道优化
-
混合搜索的探索
-
递归检索与查询引擎
-
StepBack-prompt 方法
-
子查询
-
HyDE 方法
-
13.2 RAG检索召回率低,一般都有哪些解决方案呀。尝试过不同大小的chunk,和混合检索。效果都不太好,然后优化?
个人排查方式:
知识库里面是否有对应答案?如果没有那就是知识库覆盖不全问题
知识库有,但是没召回:
q1:知识库知识是否被分割掉,导致召回出错,解决方法 修改分割方式 or 利用bert 进行上下句预测 保证知识点完整性
q2:知识没有被召回,分析 query 和 doc 的特点: 字相关还是语义相关,一般建议是先用 es做召回,然后才用模型做精排
13.3 RAG 如何 优化索引结构?
构建 RAG 时,块大小是一个关键参数。它决定了我们从向量存储中检索的文档的长度。小块可能导致文档缺失一些关键信息,而大块可能引入无关的噪音。
找到最佳块大小是要找到正确的平衡。如何高效地做到这一点?试错法(反复验证)。
然而,这并不是让你对每一次尝试进行一些随机猜测,并对每一次经验进行定性评估。
你可以通过在测试集上运行评估并计算指标来找到最佳块大小。LlamaIndex 有一些功能可以做到这一点。可以在他们的博客中了解更多。
13.4 如何通过 混合检索 提升 RAG 效果?
虽然向量搜索有助于检索与给定查询相关的语义相关块,但有时在匹配特定关键词方面缺乏精度。根据用例,有时可能需要精确匹配。
想象一下,搜索包含数百万电子商务产品的矢量数据库,对于查询“阿迪达斯参考 XYZ 运动鞋白色”,最上面的结果包括白色阿迪达斯运动鞋,但没有一个与确切的 XYZ 参考相匹配。
相信大家都不能接受这个结果。为了解决这个问题,混合检索是一种解决方案。该策略利用了矢量搜索和关键词搜索等不同检索技术的优势,并将它们智能地结合起来。
通过这种混合方法,您仍然可以匹配相关关键字,同时保持对查询意图的控制。
查看 Pinecone的入门指南,了解更多关于混合搜索的信息。
13.5 如何通过 重新排名 提升 RAG 效果?
当查询向量存储时,前K个结果不一定按最相关的方式排序。当然,它们都是相关的,但在这些相关块中,最相关的块可能是第5或第7个,而不是第1或第2个。
这就是重新排名的用武之地。
重新排名的简单概念是将最相关的信息重新定位到提示的边缘,这一概念已在各种框架中成功实现,包括 LlamaIndex、LangChain 和 HayStack。
例如,Diversity Ranker 专注于根据文档的多样性进行重新排序,而LostInTheMiddleRanker在上下文窗口的开始和结束之间交替放置最佳文档。
十四、RAG 索引数据优化
14.1 RAG 如何 提升索引数据的质量?
索引的数据决定了 RAG 答案的质量,因此首要任务是在摄取数据之前尽可能对其进行整理。(垃圾输入,垃圾输出仍然适用于此)
通过删除重复/冗余信息,识别不相关的文档,检查事实的准确性(如果可能的话)来实现这一点。
使用过程中,对 RAG 的维护也很重要,还需要添加机制来更新过时的文档。
在构建 RAG 时,清理数据是一个经常被忽视的步骤,因为我们通常倾向于倒入所有文档而不验证它们的质量。以下我建议可以快速解决一些问题:
-
通过清理特殊字符、奇怪的编码、不必要的 HTML 标签来消除文本噪音……还记得使用正则表达式的老的 NLP 技术吗?可以把他们重复使用起来;
-
通过实施一些主题提取、降维技术和数据可视化,发现与主题无关的文档,删除它们;
-
通过使用相似性度量删除冗余文档
14.2 如何通过添加元数据 提升 RAG 效果?
将元数据与索引向量结合使用有助于更好地构建它们,同时提高搜索相关性。
以下是一些元数据有用的情景:
-
如果你搜索的项目中,时间是一个维度,你可以根据日期元数据进行排序
-
如果你搜索科学论文,并且你事先知道你要找的信息总是位于特定部分,比如实验部分,你可以将文章部分添加为每个块的元数据并对其进行过滤仅匹配实验
-
元数据很有用,因为它在向量搜索之上增加了一层结构化搜索。
14.3 如何通过 输入查询与文档对齐 提升 RAG 效果?
LLMs 和 RAGs 之所以强大,因为它们可以灵活地用自然语言表达查询,从而降低数据探索和更复杂任务的进入门槛。
然而,有时,用户用几个词或短句的形式作为输入查询,查询结果会出现与文档之间存在不一致的情况。
通过一个例子来理解这一点。这是关于马达引擎的段落(来源:ChatGPT)
发动机堪称工程奇迹,以其复杂的设计和机械性能驱动着无数的车辆和机械。其核心是,发动机通过一系列精确协调的燃烧事件将燃料转化为机械能。这个过程涉及活塞、曲轴和复杂的阀门网络的同步运动,所有这些都经过仔细校准,以优化效率和功率输出。现代发动机有多种类型,例如内燃机和电动机,每种都有其独特的优点和应用。对创新的不懈追求不断增强汽车发动机技术,突破性能、燃油效率和环境可持续性的界限。无论是在开阔的道路上为汽车提供动力还是驱动工业机械,电机仍然是现代世界动态运动的驱动力。
在这个例子中,我们制定一个简单的查询,“你能简要介绍一下马达引擎的工作原理吗?”,与段落的余弦相似性为 0.72。
其实已经不错了,但还能做得更好吗?
为了做到这一点,我们将不再通过段落的嵌入来索引该段落,而是通过其回答的问题的嵌入来索引该段落。
考虑这三个问题,段落分别回答了这些问题:
发动机的基本功能是什么?
发动机如何将燃料转化为机械能?
发动机运行涉及哪些关键部件,它们如何提高发动机的效率?
通过计算得出,它们与输入查询的相似性分别为:
0.864
0.841
0.845
这些值更高,表明输入查询与问题匹配得更精确。
将块与它们回答的问题一起索引,略微改变了问题,但有助于解决对齐问题并提高搜索相关性:我们不是优化与文档的相似性,而是优化与底层问题的相似性。
14.4 如何通过 提示压缩 提升 RAG 效果?
研究表明,在检索上下文中的噪声会对RAG性能产生不利影响,更精确地说,对由 LLM 生成的答案产生不利影响。
一些方案建议在检索后再应用一个后处理步骤,以压缩无关上下文,突出重要段落,并减少总体上下文长度。
选择性上下文等方法和 LLMLingua 使用小型LLM来计算即时互信息或困惑度,从而估计元素重要性。
14.5 如何通过 查询重写和扩展 提升 RAG 效果?
当用户与 RAG 交互时,查询结果不一定能获得最佳的回答,并且不能充分表达与向量存储中的文档匹配的结果。
为了解决这个问题,在送到 RAG 之前,我们先发生给 LLM 重写此查询。
这可以通过添加中间 LLM 调用轻松实现,但需要继续了解其他的技术实现(参考论文《Query Expansion by Prompting Large Language Models》)。
十五、RAG 未来发展方向
RAG 的三大未来发展方向:垂直优化、横向扩展以及 RAG 生态系统的构建。
15.1 Rag 的垂直优化
尽管 RAG 技术在过去一年里取得了显著进展,但其垂直领域仍有几个重点问题有待深入探究:
-
RAG 中长上下文的处理问题
-
RAG 的鲁棒性研究
-
RAG 与微调(Fine-tuning)的协同作用
-
RAG 的工程应用
在工程实践中,诸如如何在大规模知识库场景中提高检索效率和文档召回率,以及如何保障企业数据安全——例如防止 LLM 被诱导泄露文档的来源、元数据或其他敏感信息——都是亟待解决的关键问题。
15.2 RAG 的水平扩展
在水平领域,RAG 的研究也在迅速扩展。从最初的文本问答领域出发,RAG 的应用逐渐拓展到更多模态数据,包括图像、代码、结构化知识、音视频等。
15.3 RAG 生态系统
下游任务和评估
通过整合来自广泛知识库的相关信息,RAG 展示了在处理复杂查询和生成信息丰富回应方面的巨大潜力。
众多研究表明,RAG 在开放式问题回答、事实验证等多种下游任务中表现优异。RAG 模型不仅提升了下游应用中信息的准确性和相关性,还增加了回应的多样性和深度。
RAG 的成功为其在多领域应用的适用性和普适性的探索铺平了道路,未来的工作将围绕此进行。特别是在医学、法律和教育等专业领域的知识问答中,RAG 的应用可能会相比微调 (fine-tuning) 提供更低的训练成本和更优的性能表现。
同时,完善 RAG 的评估体系,以更好地评估和优化它在不同下游任务中的应用,对提高模型在特定任务中的效率和效益至关重要。这涉及为各种下游任务开发更精准的评估指标和框架,如上下文相关性、内容创新性和无害性等。
此外,增强 RAG 模型的可解释性,让用户更清楚地理解模型如何以及为何作出特定反应,也是一项重要任务。
技术栈
在 RAG 的技术生态系统中,相关技术栈的发展起着推动作用。例如,随着 ChatGPT 的流行,LangChain 和 LLamaIndex 迅速成为知名技术,它们提供丰富的 RAG 相关 API,成为大模型时代的关键技术之一。
与此同时,新型技术栈也在不断涌现。尽管这些新技术并不像 LangChain 和 LLamaIndex 那样功能众多,但它们更注重自身的独特特性。例如,Flowise AI6 着重于低代码操作,使用户能够通过简单的拖拽实现 RAG 代表的各类 AI 应用。其他新兴技术如 HayStack、Meltno 和 Cohere Coral 也在不断发展。
技术栈的发展与 RAG 的进步相互促进。新技术对现有技术栈提出了更高的要求,而技术栈功能的优化又进一步推动了 RAG 技术的发展。综合来看,RAG 工具链的技术栈已经初步建立,许多企业级应用逐步出现。然而,一个全面的一体化平台仍在完善中。

