
- 1【AIGC调研系列】OpenInterpreter/01的项目如何赋能软件测试领域
- 2Python生日蛋糕_pycharm生日快乐蛋糕代码
- 3MSTP的原理以及实验_mstp中instance 10 vlan 10 100是什么意思
- 4Yolov5通俗易懂网络结构详解_yolov5网络结构详解
- 5科大讯飞AIUI评估板开发笔记
- 6零基础HTML入门教程(21)——无序列表_web无序列表代码
- 7天工大模型登顶多模态榜单!解决幻觉、跨语言两大难题
- 8【Hadoop】MapReduce详解_mapreduce运行机制
- 9Modelsim仿真图中添加内部信号到wave_modelsim怎么添加内部信号
- 10c语言编译bss和data,深入理解BSS段与data段的区别
分库分表之后,自增主键如何处理?_分库分表主键自增
赞
踩
面试题
分库分表之后,自增主键如何处理?
面试官心理分析
其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全局唯一的 id 来支持。所以这都是你实际生产环境中必须考虑的问题。
面试题剖析
基于数据库的实现方案
数据库自增 id
这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个 id。拿到这个 id 之后再往对应的分库分表里去写入。
这个方案的好处就是方便简单,谁都会用;缺点就是单库生成自增 id,要是高并发的话,就会有瓶颈的;如果你硬是要改进一下,那么就专门开一个服务出来,这个服务每次就拿到当前 id 最大值,然后自己递增几个 id,一次性返回一批 id,然后再把当前最大 id 值修改成递增几个 id 之后的一个值;但是无论如何都是基于单个数据库。
适合的场景:你分库分表就俩原因,要不就是单库并发太高,要不就是单库数据量太大;除非是你并发不高,但是数据量太大导致的分库分表扩容,你可以用这个方案,因为可能每秒最高并发最多就几百,那么就走单独的一个库和表生成自增主键即可。
设置数据库 sequence 或者表自增字段步长
可以通过设置数据库 sequence 或者表的自增字段步长来进行水平伸缩。
比如说,现在有 8 个服务节点,每个服务节点使用一个 sequence 功能来产生 ID,每个 sequence 的起始 ID 不同,并且依次递增,步长都是 8。
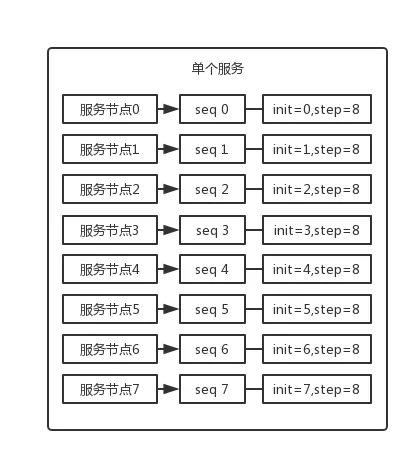
适合的场景:在用户防止产生的 ID 重复时,这种方案实现起来比较简单,也能达到性能目标。但是服务节点固定,步长也固定,将来如果还要增加服务节点,就不好搞了。
UUID
好处就是本地生成,不要基于数据库来了;不好之处就是,UUID 太长了、占用空间大,作为主键性能太差了;更重要的是,UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作(连续的 ID 可以产生部分顺序写),还有,由于在写的时候不

