
- 1LayoutLM——文本与布局的预训练用于文档图像理解
- 2拉扎维模拟CMOS集成电路设计西交张鸿老师课程P2~5视频学习记录_张鸿半导体模拟集成电路 ppt
- 3 B2B跨境电子商务平台综合服务解决方案
- 4NLP经典论文:FastText 笔记_fasttext论文
- 5每天读一篇文献8--Contextualized Medication Information Extraction Using Transformer-based Deep Learning Arc_gatortron
- 6SIM7600CE-CNSE 4G模块 树莓派/Windows连网指南_at+cnmp
- 7O2OA(翱途)移动端如何查看系统日志?_o2oa 日志
- 8【xinference】(4):在autodl上,使用xinference部署sd-turbo模型,可以根据文本生成图片,在RTX3080-20G上耗时1分钟,占用显存11G_3080ti跑sd
- 9【MMDetection3D】基于单目(Monocular)的3D目标检测入门实战_mmdetection 3d
- 10模型训练损失,正确率绘制曲线图_怎么画模型训练时的损失下降图
【Transformer】Transformer 网络解析(Self-Attention 、Multi-Head Attention、位置编码、Mask等)_masked multi-head attention
赞
踩
【Transformer】Transformer 网络解析(Self-Attention 、Multi-Head Attention、位置编码、Mask等)
1. 介绍
原论文地址:Attention Is All You Need
近年来,Transformer在CV领域很火,Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的。
- 之前的RNN模型记忆长度有限;且无法并行化,只有计算完 t i t_i ti 时刻后的数据才能计算 t i + 1 t_{i+1} ti+1 时刻的数据,
- 但Transformer都可以做到。
在《Attention Is All You Need]》中作者提出了Self-Attention的概念,然后在此基础上提出Multi-Head Attention,所以本文对Self-Attention以及Multi-Head Attention 等理论进行讲解。
2. 模型
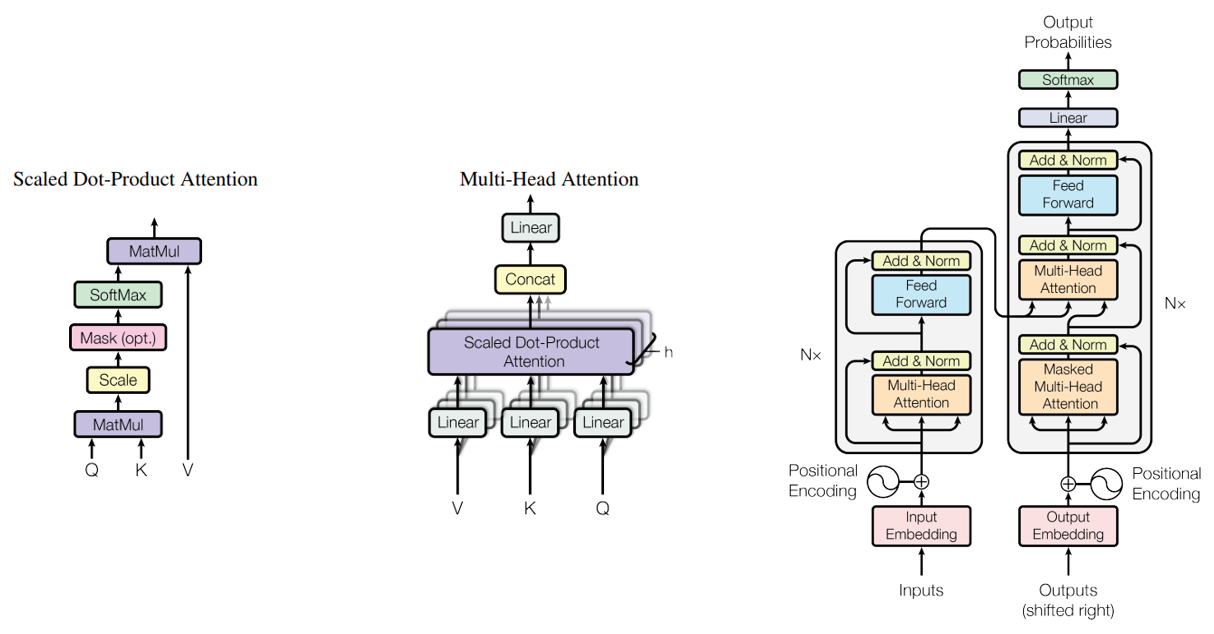
2.1 Self-Attention
为了便于理解,假设输入的序列长度为2,输入就两个节点 x 1 , x 2 x_1, x_2 x1,x2,然后通过Input Embedding也就是图中的 f ( x ) f(x) f(x) 将输入映射到 a 1 , a 2 a_1, a_2 a1,a2 。紧接着分别将 a 1 , a 2 a_1, a_2 a1,a2 分别通过三个变换矩阵 W q , W k , W v W_q, W_k, W_v Wq,Wk,Wv(这三个参数是可训练的,是共享的)得到对应的 q i , k i , v i q^i, k^i, v^i qi,ki,vi(这里在源码中是直接使用全连接层实现的,这里为了方便理解,忽略偏置参数 b)。
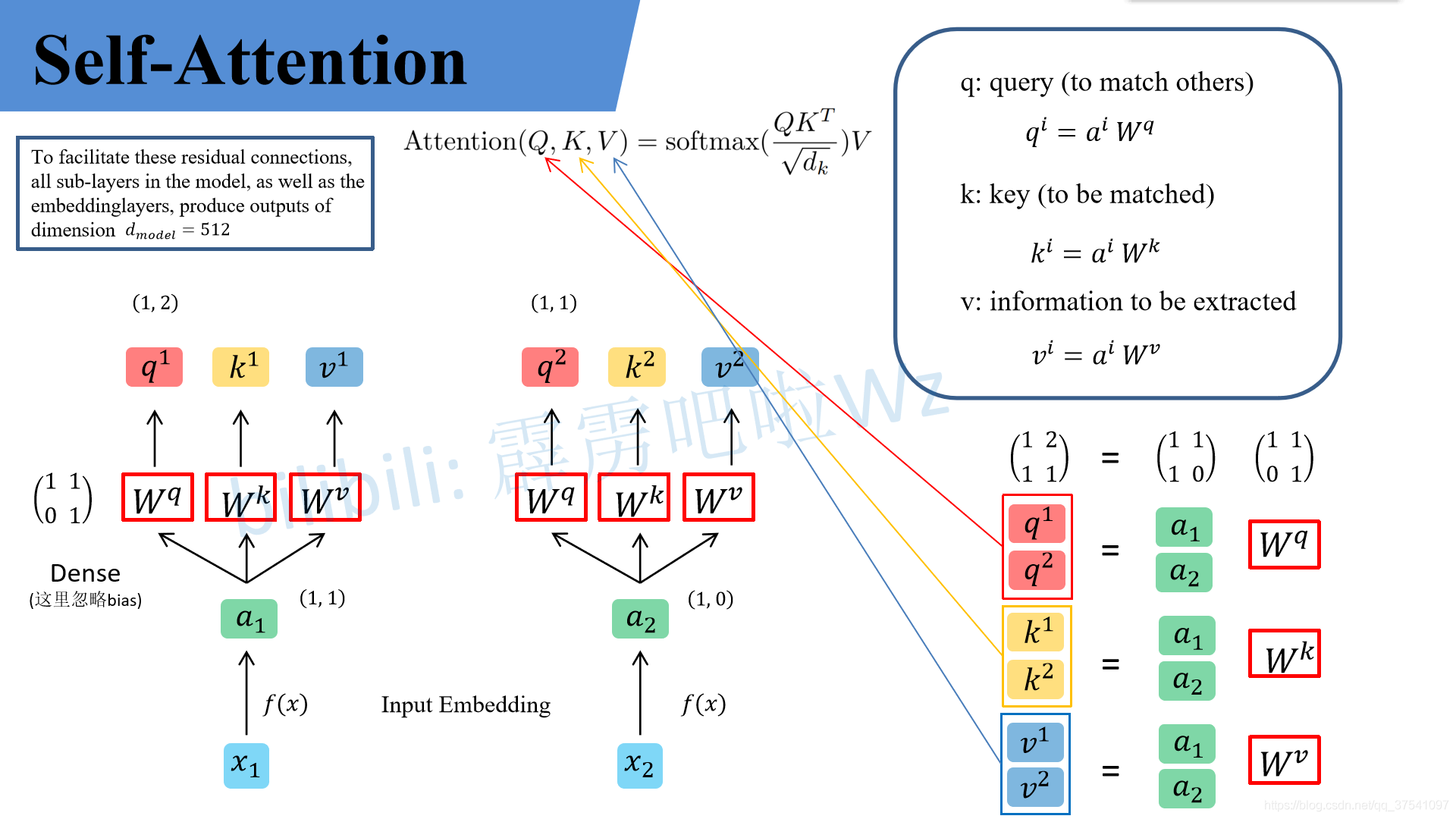
其中
- q q q 代表query,后续会去和每一个 k k k 进行匹配
- k k k 代表key,后续会被每个 q q q 匹配
- v v v 代表从 原始特征 a a a 中提取得到的信息
后续 q 和 k 匹配的过程可以理解成计算两者的相关性,相关性越大对应 v(value) 的权重也就越大。

同理我们可以得到
(
k
1
k
2
)
\binom{k^1}{k^2}
(k2k1) 和
(
v
1
v
2
)
\binom{v^1}{v^2}
(v2v1),那么求得的
(
q
1
q
2
)
\binom{q^1}{q^2}
(q2q1)就是原论文中的
Q
Q
Q ,
(
k
1
k
2
)
\binom{k^1}{k^2}
(k2k1) 就是
K
K
K,
(
v
1
v
2
)
\binom{v^1}{v^2}
(v2v1) 就是
V
V
V。
接着先拿 q 1 q^1 q1 和每个 k k k 进行match,点乘操作,接着除以 d \sqrt{d} d 得到对应的权重 α,其中 d 代表向量 k i k^i ki 的维度。在本示例中等于2。
- 注意:除以
d
\sqrt{d}
d
的原因在论文中的解释是:“进行点乘后的数值很大,导致通过softmax后梯度变的很小”,所以通过除以
d
\sqrt{d}
d
来进行缩放。比如计算
α
1
,
i
\alpha_{1, i}
α1,i:
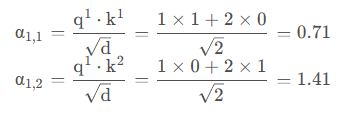

接着对每一行即
(
α
1
,
1
,
α
1
,
2
)
(\alpha_{1, 1}, \alpha_{1, 2})
(α1,1,α1,2) 和
(
α
2
,
1
,
α
2
,
2
)
(\alpha_{2, 1}, \alpha_{2, 2})
(α2,1,α2,2) 分别进行softmax处理得到
(
α
^
1
,
1
,
α
^
1
,
2
)
(\hat\alpha_{1, 1}, \hat\alpha_{1, 2})
(α^1,1,α^1,2) 和
(
α
^
2
,
1
,
α
^
2
,
2
)
(\hat\alpha_{2, 1}, \hat\alpha_{2, 2})
(α^2,1,α^2,2),这里的
α
^
\hat{\alpha}
α^ 相当于计算得到针对每个 v 的权重。
到这儿,我们就完成了 A t t e n t i o n ( Q , K , V ) {\rm Attention}(Q, K, V) Attention(Q,K,V) 公式中 s o f t m a x ( Q K T d k ) {\rm softmax}(\frac{QK^T}{\sqrt{d_k}}) softmax(dk QKT) 部分。
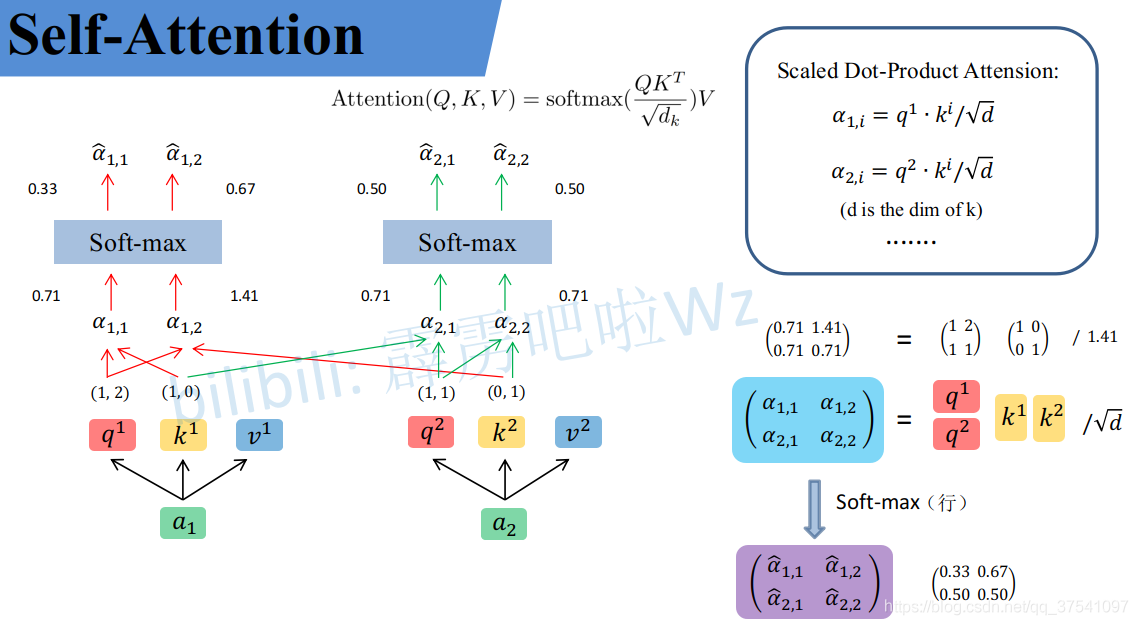
上面已经计算得到
α
^
\hat\alpha
α^,即针对每个 v 的权重,接着进行加权得到最终结果:

统一写成矩阵乘法形式:

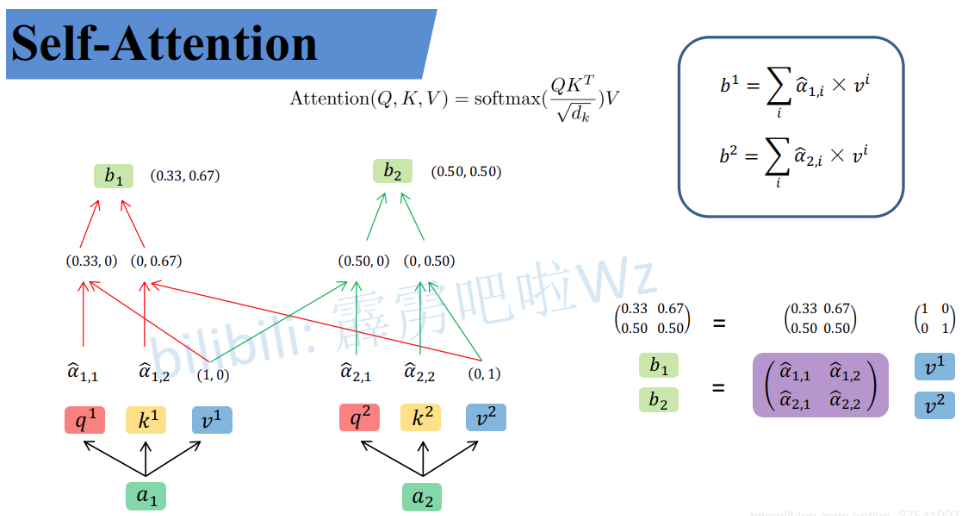
到这,Self-Attention 的内容就讲完了。总结下来就是论文中的一个公式:

2.2 Multi-Head Attention
接下来是 Multi-Head Attention(多头注意力)模块,实际使用中基本使用的还是Multi-Head Attention模块。原论文中说使用多头注意力机制能够联合来自不同head部分学习到的信息:
- Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
其实只要懂了Self-Attention模块Multi-Head Attention模块就非常简单了。
- 首先还是和Self-Attention模块一样将 a 分别通过 W q , W k , W v W^q, W^k, W^v Wq,Wk,Wv 得到对应的 q , k , v;
- 然后再根据使用的head的数目 h 进一步把得到的 q, k, v 均分成 h 份。
比如下图中假设h = 2,然后
q
1
q^1
q1 拆分成
q
1
,
1
q^{1,1}
q1,1 和
q
1
,
2
q^{1,2}
q1,2 ,那么
q
1
,
1
q^{1,1}
q1,1 就属于head1,
q
1
,
2
q^{1,2}
q1,2 属于head2。

看到这里,可能会有疑问,论文中不是写的通过
W
i
Q
,
W
i
K
,
W
i
V
W^Q_i, W^K_i, W^V_i
WiQ,WiK,WiV 映射得到每个 head 的
Q
i
,
K
i
,
V
i
Q_i, K_i, V_i
Qi,Ki,Vi 吗?

二者其实是等价的,因为都是线性运算,把
W
W
W 设置为原来的h倍大小即可。即通过将
W
i
Q
,
W
i
K
,
W
i
V
W^Q_i, W^K_i, W^V_i
WiQ,WiK,WiV 设置成对应值来实现均分,比如下图中的
Q
Q
Q 通过
W
1
Q
W^Q_1
W1Q 就能得到均分后的
Q
1
Q_1
Q1。
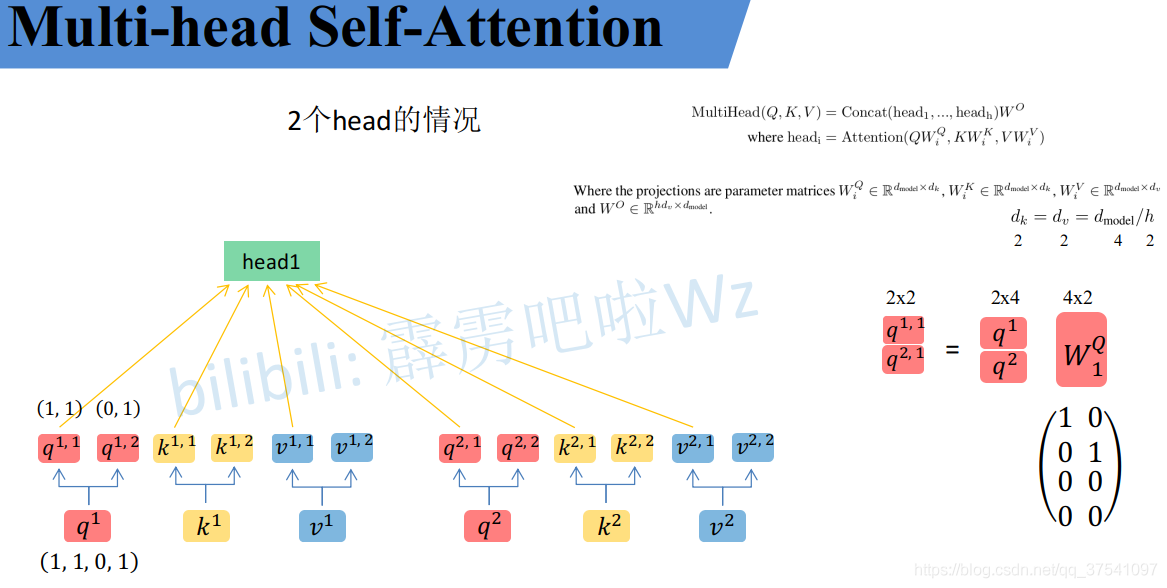
接着将每个head得到的结果进行concat拼接,比如下图中 b 1 , 1 b_{1,1} b1,1( h e a d 1 head_1 head1 得到的 b 1 b_1 b1)和 b 1 , 2 b_{1,2} b1,2( h e a d 2 head_2 head2 得到的 b 1 b_1 b1)拼接在一起, b 2 , 1 b_{2,1} b2,1 ( h e a d 1 head_1 head1 得到的 b 2 b_2 b2) 和 b 2 , 2 b_{2,2} b2,2(head_2$ 得到的 b 2 b_2 b2) 拼接在一起。
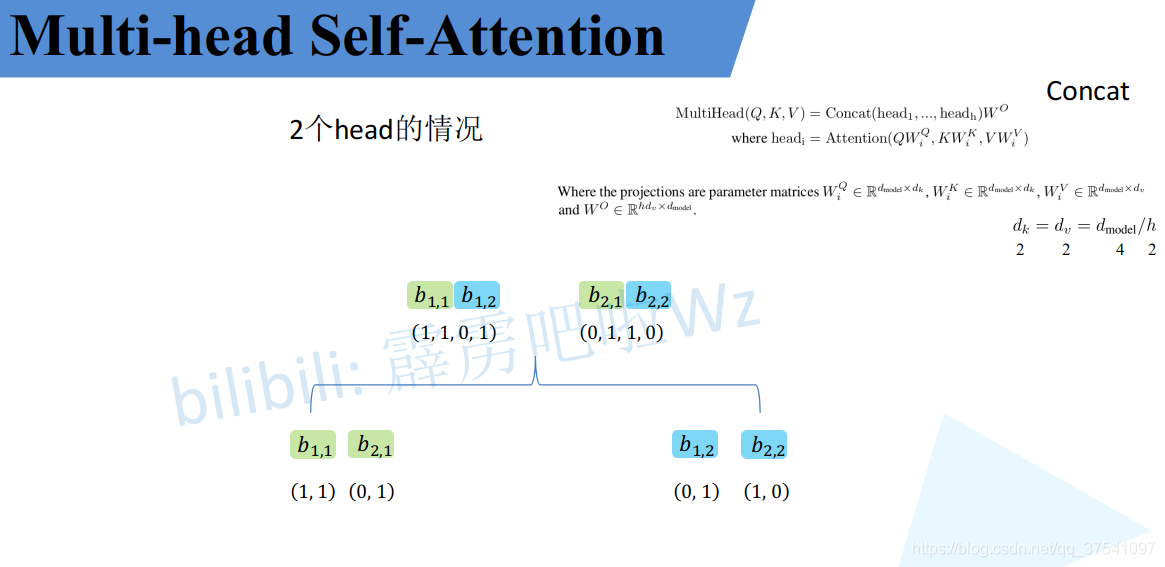
接着将拼接后的结果通过
W
O
W^O
WO(可学习的参数)进行融合,如下图所示,融合后得到最终的结果
b
1
,
b
2
b_1, b_2
b1,b2。

到这儿,Multi-Head Attention 的内容就讲完了。总结下来就是论文中的两个公式:

2.3 Self-Attention与Multi-Head Attention 对比
原论文章节 3.2.2 中有说两者的计算量其实是差不多。
- Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
可以简单的尝试一下,这个Attention就是实现Multi-head Attention的方法,其中包括上面讲的所有步骤。
- 首先创建了一个Self-Attention模块(单头)a1;
- 然后把proj变量置为Identity(Identity对应的是Multi-Head Attention中最后那个 W O W^O WO 的映射,单头中是没有的,所以置为Identity即不做任何操作);
- 再创建一个Multi-Head Attention模块(多头)a2,然后设置8个head;
- 创建一个随机变量,注意shape;
- 使用fvcore分别计算两个模块的FLOPs。
注:FLOPs 为每秒浮点运算次数,也就是所用的时间。
通过实验发现:
- 可以发现确实两者的FLOPs差不多,Multi-Head Attention比Self-Attention 略高一点。
- 其实两者FLOPs的差异只是在最后的 W O W^O WO 上,如果把Multi-Head Attentio的 W O W^O WO 也删除(即把a2的proj也设置成Identity),可以看出两者FLOPs是一样的。
- 总结:可能是由于线性的相乘关系(矩阵乘法优化),导致多头和单头是差不多,差距也就在于多头比单头多了个 W O W^O WO映射。
2.4 Positional Encoding
上述所讲的 Self-Attention 和 Multi-Head Attention 模块,在计算中是没有考虑到位置信息的。假设在Self-Attention模块中,输入
a
1
,
a
2
,
a
3
a_1, a_2, a_3
a1,a2,a3 得到
b
1
,
b
2
,
b
3
b_1, b_2, b_3
b1,b2,b3 。对于
a
1
a_1
a1而言,
a
2
a_2
a2 和
a
3
a_3
a3 离它都是一样近的而且没有先后顺序。
- 假设将输入的顺序改为 a 1 , a 3 , a 2 a_1, a_3, a_2 a1,a3,a2,对结果 b 1 b_1 b1 也是没有任何影响的。
因此,为了引入位置信息,在原论文中引入了位置编码 positional encodings。
- To this end, we add “positional encodings” to the input embeddings at the bottoms of the encoder and decoder stacks.
如下图所示,位置编码是直接加在输入的
a
=
{
a
1
,
.
.
.
,
a
n
}
a=\{a_1,...,a_n\}
a={a1,...,an} 中的,即
p
e
=
{
p
e
1
,
.
.
.
,
p
e
n
}
pe=\{pe_1,...,pe_n\}
pe={pe1,...,pen} 和
a
=
{
a
1
,
.
.
.
,
a
n
}
a=\{a_1,...,a_n\}
a={a1,...,an} 拥有相同的维度大小。
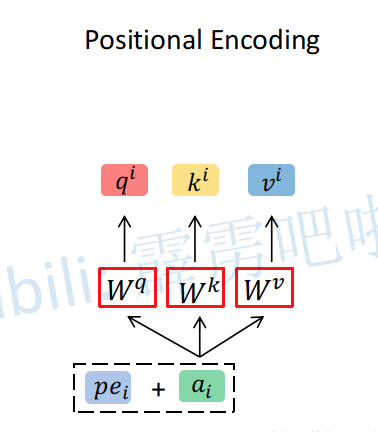
关于位置编码在原论文中有提出两种方案,
- 一种是原论文中使用的固定编码,即论文中给出的sine and cosine functions方法,按照该方法可计算出位置编码;
- 另一种是可训练的位置编码,作者说尝试了两种方法发现结果差不多(但在ViT论文中使用的是 可训练 的位置编码)。
2.5 Mask
mask是Transformer中很重要的一个概念,mask操作的目的有两个:
-
让padding (不够长的补0) 部分不参与attention操作。(每个句子的序列长度不同)
-
在生成当前词语的概率分布时,让模型不会注意到这个词后面的部分,避免利用未来信息。
在自注意力机制中,每个位置都会与所有其他位置进行交互,因此为了避免模型在预测时利用未来信息,需要将未来位置的信息掩盖掉。在编码器中,需要将输入序列中不够长的部分进行mask,而在解码器中,还需要将当前位置之后的位置进行掩盖,以避免模型利用未来信息。掩盖的方式可以是将对应位置的注意力权重设置为0,或者将对应位置的输入向量设置为一个特殊的掩码向量。
2.5.1 padding mask
这个很好理解,下面就是一个mask矩阵,这个mask矩阵表示的是这个句子只有两个单词,句子后两个词是padding的内容,所以全都是0(假设序列长度为4)。我们在进行attention时不应该将这里考虑进attention,当给mask矩阵为0的对应位置替换一个负很大的值后,相应attention的结果就会趋近为0。

2.5.2 Masked Multi-Head Attention中的Mask
这个稍微复杂一点,我们先看看对应的mask矩阵(下三角矩阵),与得到的权重矩阵
α
\alpha
α 点乘,进而可以屏蔽掉未来的位置。
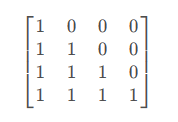
3. 参考
【1】https://blog.csdn.net/qq_37541097/article/details/117691873


