
- 1动态规划——背包问题(C语言)_背包问题[动态规划]代码
- 2Prometheus监控K8S_prometheus监控kubernetes
- 3Transformer代码实现(基于Pytorch)_transformer应用python
- 4制造业数据挖掘系统对于业务增长的作用日益增大_制造数据分析对业务
- 5鸿蒙HarmonyOS 编辑器 下载 安装_鸿蒙官方编辑器在哪
- 6代码智能化应用的通用框架_代码智能助手 产品架构
- 7【PyTorch】GPU实现cnn手写数字识别_pytorch gpu手写数字
- 8自然语言处理之新闻分类(二)_新闻自然语言处理
- 9时间序列数据挖掘_时间序列多特征怎么降维
- 10Android Studio搭建系统App开发环境_在androidstudio中开发系统app
《自然语言处理实战入门》---- 第1课:自然语言处理简介
赞
踩
本博客为《自然语言处理实战课程》---- 第一课:自然语言处理简介 讲稿
大家好,今天开始和大家分享,我在自然语言处理(Natural Language Processing,NLP)的一些学习经验和心得体会。
随着人工智能的快速发展,自然语言处理和机器学习技术的应用愈加广泛。为使大家对该领域整体概况有一个系统、明晰的认识,同时入门一些工程实践,也借CSDN为NLP的学习,开发者们搭建一个交流的平台。
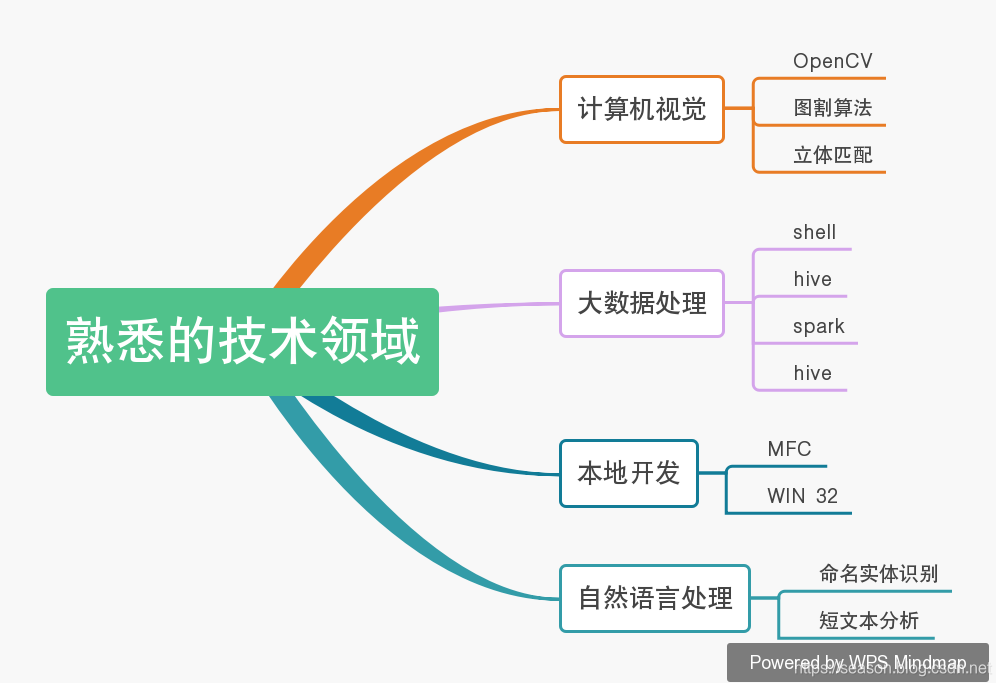
个人简介
王雅宁, 2016年毕业于陕西师范大学计算机软件与理论专业。
CSDN博客专家,主要专注于大数据,计算机视觉,自然语言处理
对大数据机器学习类软件开发技术都有比较浓厚的兴趣,熟悉数据分析,机器学习,计算机视觉等领域的研发工作。熟悉windows,Linux下的c/c++开发,OpenCV图形图像库的各类接口。熟悉大数据生态圈下的Python开发。
曾参与并负责国家级安全项目相关POC验证与探索工作,在客户业务场景下验证产品的功能与性能。
主要工作内容有:
1、在客户现场搭建大数据产品平台,与客户沟通,根据客户的需求或业务场景在大数据平台上实现大数据平台软件的项目实施与安装部署。
2、现场提供专业服务,包括系统、大数据集群故障分析与诊断,数据分析服务,业务应用对接迁移,完善提供整体解决方案。
3、实现在单机与分布式环境下发掘等短文本的兴趣倾向和命名实体识别。该项目对结构化数据进行分词,停用词处理,命名实体识别,图计算等操作。
目前在西安知盛数据科技有限公司主要负责大健康平台中医疗健康保险的部分内容构建与实施,主要负责包括数据理解,数据接入与清洗,描述性统计分析,大数据可视化等方面的工作与探索。对自然语言处理,保险数据异常检测方面有独到的探索经验。
本节课程导览
本小结主要介绍内容如下
- 自然语言处理简介
3W,发展历程、研究现状、
- 课程涵盖的主要内容总览
第一阶段
第二阶段 - 知名NLP服务系统与开源组件简介
对汉语自然处理的服务提供商及其服务内容做一个简单的梳理,让大家能够更好的了解目前的技术手段,技术现状。
本小节课程主要内容分为2大部分:
第一部分,自然语言处理简介,用认知思维的方法,结合发展历程总揽自然语言处理.
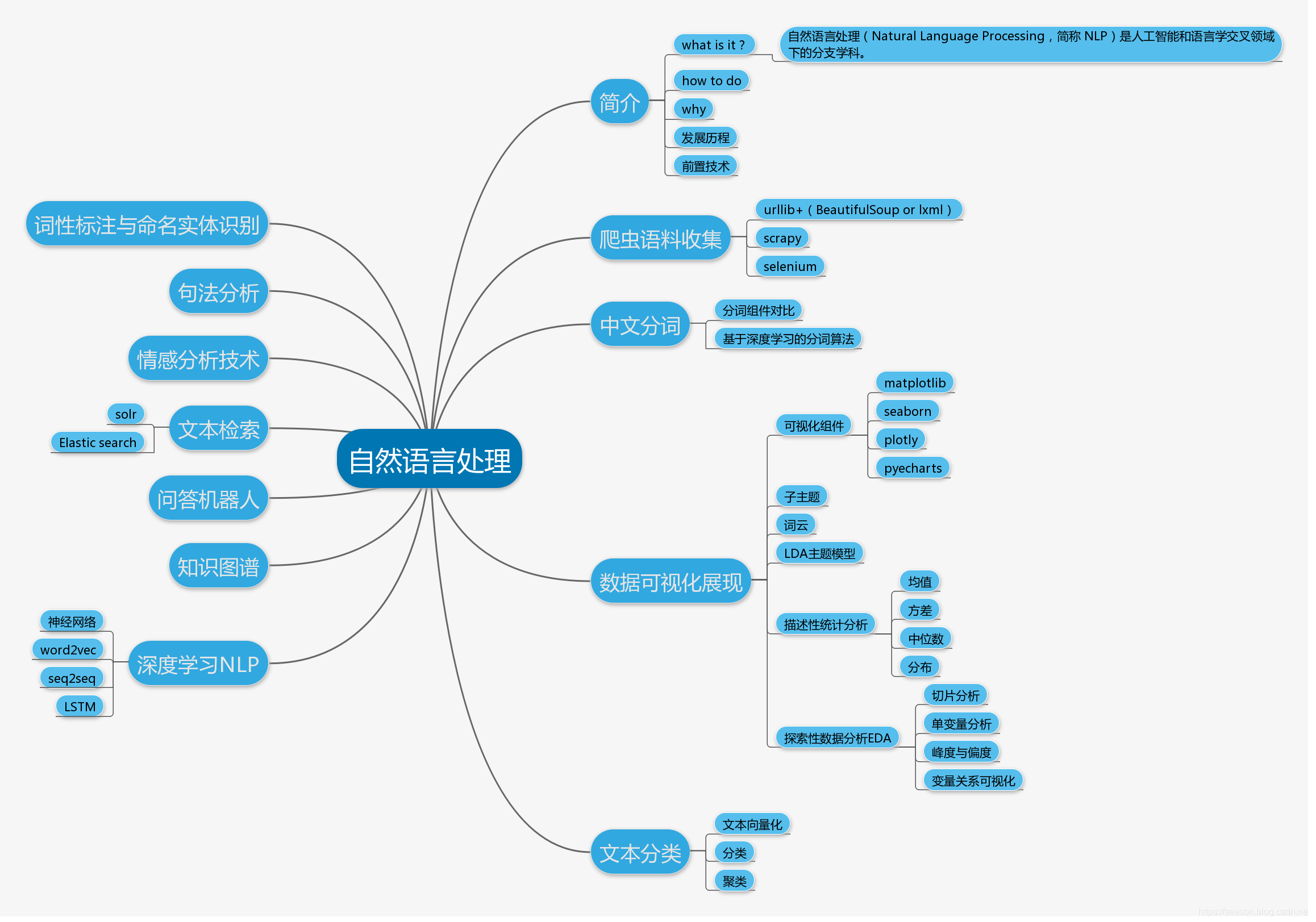
同时顺带介绍,本课程的主要内容,本课程的主要内容我们分成两个阶段 。第一个阶段如思维导图的右边,我们力求短时间内上手,完成爬虫、分词、可视化、文本分类4个自然语言处理实战中最经常碰到的问题,我首先通过爬虫爬取自己CSDN的博客积累语料,其次尝试通过一些解决方案的对比,比如不同的分词组件的对比,选择一个进行可视化词云,主题模型的生成。最后我们介绍一些文本分类的方法,文本分类的应用较广,如垃圾邮件检测,舆论分析,文本查重等场景都可以转化为文本分类问题。第二个阶段的课程,如果有时间的话,我们来共同探讨一些业界常用的NLP实战场景,如脑图左侧所示的,命名实体识别,问答机器人,知识图谱,基于深度学习的NLP 等
第二部分介绍 ,NLP技术在我国的应用现状,以及一些我们经常用到的开源包。
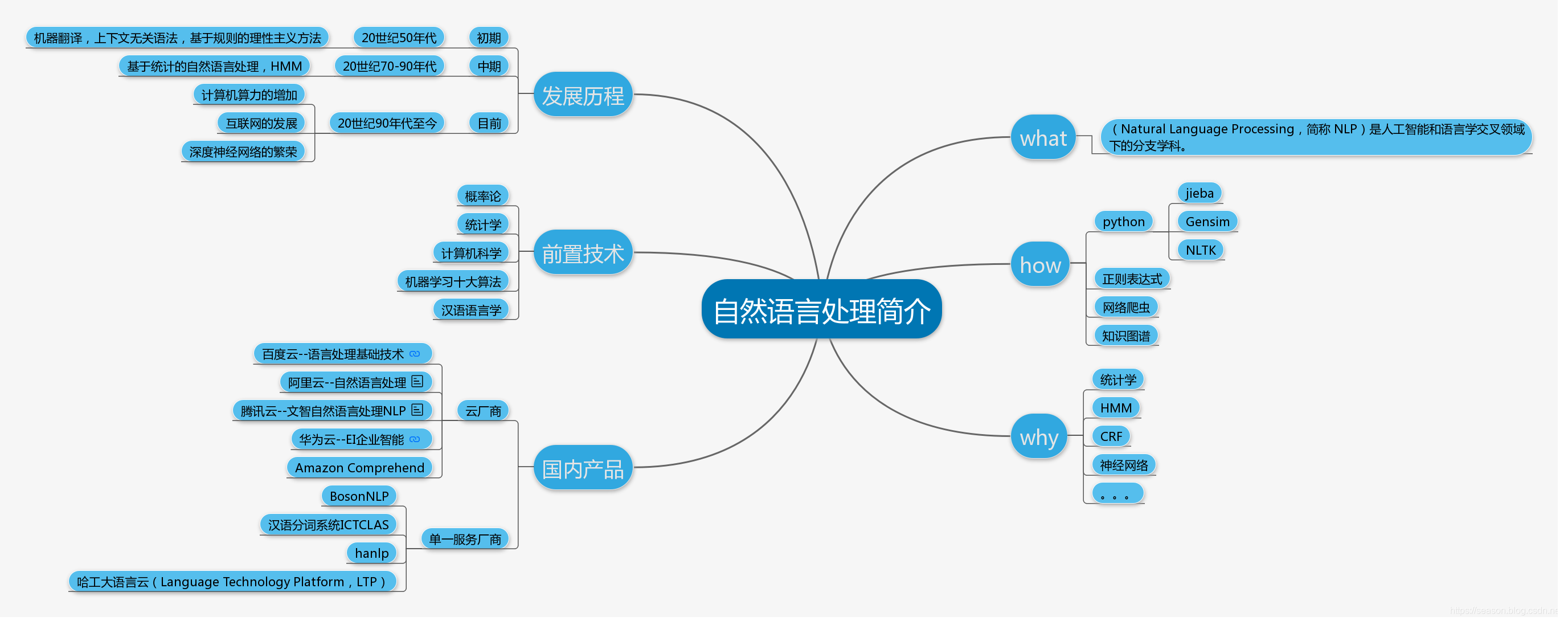
1.自然语言处理(NLP)简介
上学的时候,老师经常使用这样提问的方式加深我们对于知识的理解和认知
what is it?
自然语言处理(Natural Language Processing,简称 NLP)是人工智能和语言学交叉领域下的分支学科。
用于分析、理解和生成自然语言,以方便人和计算机设备进行交流,以及人与人之间的交流
NLP 是人工智能和语言学领域的交叉学科,
自然语言处理在广义上分为两大部分:
- 第一部分为自然语言理解,是指让计算机懂人类的语言。
- 第二部分为自然语言生成,是指把计算机数据转化为自然语言。
NLP 技术按照由浅入深可以分为三个层次,分别为:
- 基础技术
- 核心技术
- NLP+
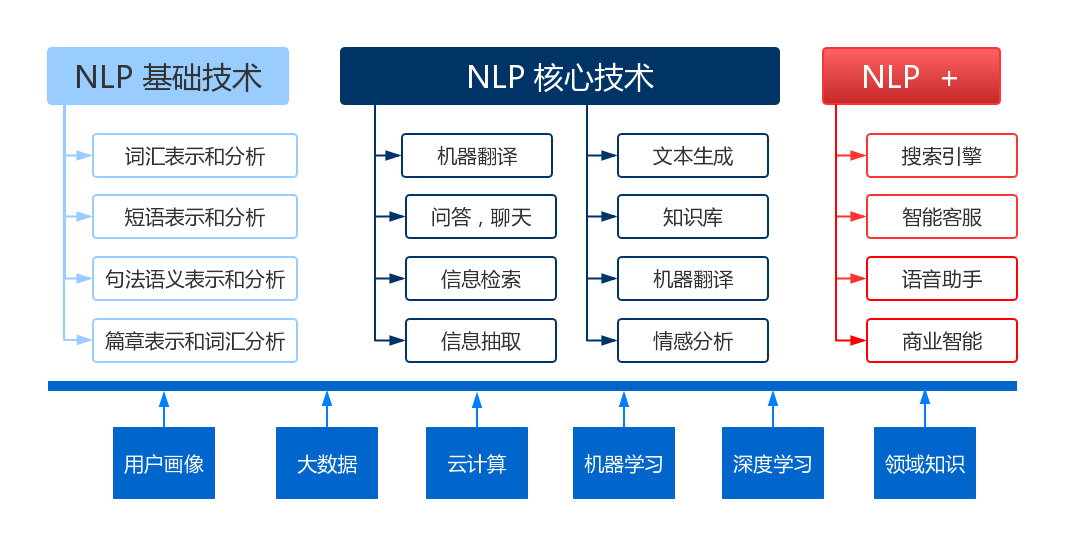
1.1 基础技术
这三个层次中,基础技术主要是对自然语言中的基本元素进行表示和分析,比如词汇,短语,句子。
词汇短语分析中,大家熟知的分词技术,就是为了解决如下问题,比如:我去北京大学玩,北京大学独立成词,而不是分成北京和大学。
句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧。
1.2 NLP 核心技术
NLP 的核心技术是建立在基础技术之上的的技术产出,基础技术中如词法,句法的分析越准确,核心技术的产出才能越准确。核心技术主要包括以下几个方面:
-
信息抽取
从给定文本中抽取重要的信息,比如,时间、地点、人物、事件、原因、结果、数字、日期、货币、专有名词等等。通俗说来,就是要了解谁在什么时候、什么原因、对谁、做了什么事、有什 么结果。涉及到实体识别、时间抽取、因果关系抽取等关键技术。 -
文本挖掘(或者文本数据挖掘)
包括文本聚类、分类、信息抽取、摘要、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面。目前主流的技术都是基于统计机器学习的。 -
机器翻译
把输入的源语言文本通过自动翻译获得另外一种语言的文本。根据输入媒介不同,可以细分为文本翻译、语音翻译、手语翻译、图形翻译等。机器翻译从最早的基于规则的方法到二十年前的基于统计的方法,再到今天的基于神经网络(编码-解码)的方法,逐渐形成了一套比较严谨的方法体系。 -
信息检索
对大规模的文档进行索引。可简单对文档中的词汇,赋之以不同的权重来建立索引,也可利用(句法分析,信息抽取,文本发掘)来建立更加深层的索引。在查询的时候,对输入的查询表达式比如一个检索词或者一个句子进行分析,然后在索引里面查找匹配的候选文档,再根据一个排序机制把候选文档排序,最后输出排序得分最高的文档。
1.3 NLP+(高端技术)
能够真正影响我们生活的黑科技,能够通过图灵测试的机器问答系统,我们可以称之为NLP+
-
问答系统
对一个自然语言表达的问题,由问答系统给出一个精准的答案。需要对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别,形成逻辑表达式,然后到知识库中查找可能的候选答案并通过一个排序机制找出最佳的答案。 -
对话系统
系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务。涉及到用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。此外,为了体现上下文相关,要具备多轮对话能力。 -
AI助手
目前自然语言处理的前沿,已经与人类真假难辨
https://v.qq.com/x/page/w0648xqraxj.html
参考:
https://www.zhihu.com/question/19895141/answer/149475410
1.4 课程涵盖的主要内容总揽
2.知名NLP服务系统与开源组件简介
以下我们通过一些知名中文NLP服务提供商,包括我们熟知的云服务提供商BAT ,aws,以及两家科研院所的系统简介,来介绍以及宏观认识NLP的各种技术手段和应用场景。
首先介绍的是两家NLP基础分析,准确率很高的科研院所 的产品,源自北理工和哈工大,之后我们介绍知名云服务提供商的产品。
2.1 单一服务提供商
2.1.1 汉语分词系统ICTCLAS
主页:http://ictclas.nlpir.org/
在线演示系统:http://ictclas.nlpir.org/
Python版本:https://github.com/tsroten/pynlpir
(需要频繁更新key)
https://blog.csdn.net/sinat_26917383/article/details/77067515

对于**** 这篇新闻稿 的实体抽取结果
http://news.163.com/18/0715/14/DMOTHJEK000189FH.html
该系统为汉语自然语言处理领域顶尖大牛,北京理工大学张华平博士20年的专业技术积累,NShort 革命性分词算法的发明者。
主要功能包括中文分词;英文分词;中英文混合分词,词性标注;命名实体识别;新词识别;关键词提取;支持用户专业词典与微博分析。NLPIR系统支持多种编码、多种操作系统、多种开发语言与平台。
该平台的特点为:功能丰富,分词,语义,实体发现准确率高,近期发布了最新的2018版。
(与熟知的jieba,ltp,清华thulac)
2.1.2 哈工大语言云(Language Technology Platform,LTP)
https://www.ltp-cloud.com/
源自哈工大知名的分词插件ltp,准确率高
Python版本:https://github.com/HIT-SCIR/pyltp

语言技术平台(Language Technology Platform,LTP)是哈工大社会计算与信息检索研究中心历时十年开发的一整套中文语言处理系统。LTP制定了基于XML的语言处理结果表示,并在此基础上提供了一整套自底向上的丰富而且高效的中文语言处理模块(包括词法、句法、语义等6项中文处理核心技术),以及基于动态链接库(Dynamic Link Library, DLL)的应用程序接口、可视化工具,并且能够以网络服务(Web Service)的形式进行使用。
“语言云”
以哈工大社会计算与信息检索研究中心研发的 “语言技术平台(LTP)” 为基础,为用户提供高效精准的中文自然语言处理云服务。 使用 “语言云” 非常简单,只需要根据 API 参数构造 HTTP 请求即可在线获得分析结果,而无需下载 SDK 、无需购买高性能的机器,同时支持跨平台、跨语言编程等。 2014年11月,哈工大联合科大讯飞公司共同推出 “哈工大-讯飞语言云”,借鉴了讯飞在全国性大规模云计算服务方面的丰富经验,显著提升 “语言云” 对外服务的稳定性和吞吐量,为广大用户提供电信级稳定性和支持全国范围网络接入的语言云服务,有效支持包括中小企业在内开发者的商业应用需要。
有关更多语言云API的使用方法,请参考:http://www.ltp-cloud.com/document/
windows 下安装pyltp的话,应该是需要安装visual studio, 由于LTP是用c++写的,pyltp也是基于它封装而成的,需要调用 cl.exe 完成源码的编译。然后下载源码,使用python setup.py install 的方式进行安装就可以了。
2.1.3 HanLP
HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
HanLP提供下列16大类功能:
- 中文分词
- 词性标注
- 命名实体识别
- 关键词提取
- 自动摘要
- 短语提取
- 拼音转换
- 简繁转换
- 文本推荐
- 依存句法分析
- 文本分类
- 情感分析
- 文本聚类
- word2vec
- 文档语义相似度计算
- 语料库工具
项目地址:https://github.com/hankcs/HanLP
python 版本:https://github.com/hankcs/pyhanlp
windows 安装指南:https://github.com/hankcs/pyhanlp/wiki/Windows
由于HanLP底层是java 版本的,所以对java 的支持比较好,python 版本中有一些功能没有实现,但可以通过调用java 实现。HanLP随v1.6.8发布了在一亿字的大型综合语料库上训练的分词模型,该语料是已知范围内全世界最大的中文分词语料库。在HanLP的在线演示中使用已久,现在无偿公开。语料规模决定实际效果
,所以不用多说HanLP确实可以直接拿来做项目。有趣的是HanLP 有着非常多的衍生项目,其中docker 版和ES 版值得大家关注,这些衍生项目无疑更加提高了HanLP的可用性、灵活性。
调用代码样例
from pyhanlp import * print(HanLP.segment('你好,欢迎在Python中调用HanLP的API')) for term in HanLP.segment('下雨天地面积水'): print('{}\t{}'.format(term.word, term.nature)) # 获取单词与词性 testCases = [ "商品和服务", "结婚的和尚未结婚的确实在干扰分词啊", "买水果然后来世博园最后去世博会", "中国的首都是北京", "欢迎新老师生前来就餐", "工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作", "随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。"] for sentence in testCases: print(HanLP.segment(sentence)) # 关键词提取 document = "水利部水资源司司长陈明忠9月29日在国务院新闻办举行的新闻发布会上透露," \ "根据刚刚完成了水资源管理制度的考核,有部分省接近了红线的指标," \ "有部分省超过红线的指标。对一些超过红线的地方,陈明忠表示,对一些取用水项目进行区域的限批," \ "严格地进行水资源论证和取水许可的批准。" print(HanLP.extractKeyword(document, 2)) # 自动摘要 print(HanLP.extractSummary(document, 3)) # 依存句法分析 print(HanLP.parseDependency("徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。"))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
2.1.4 BosonNLP
BosonNLP(界面,接口友好,准确率高)
https://bosonnlp.com/demo
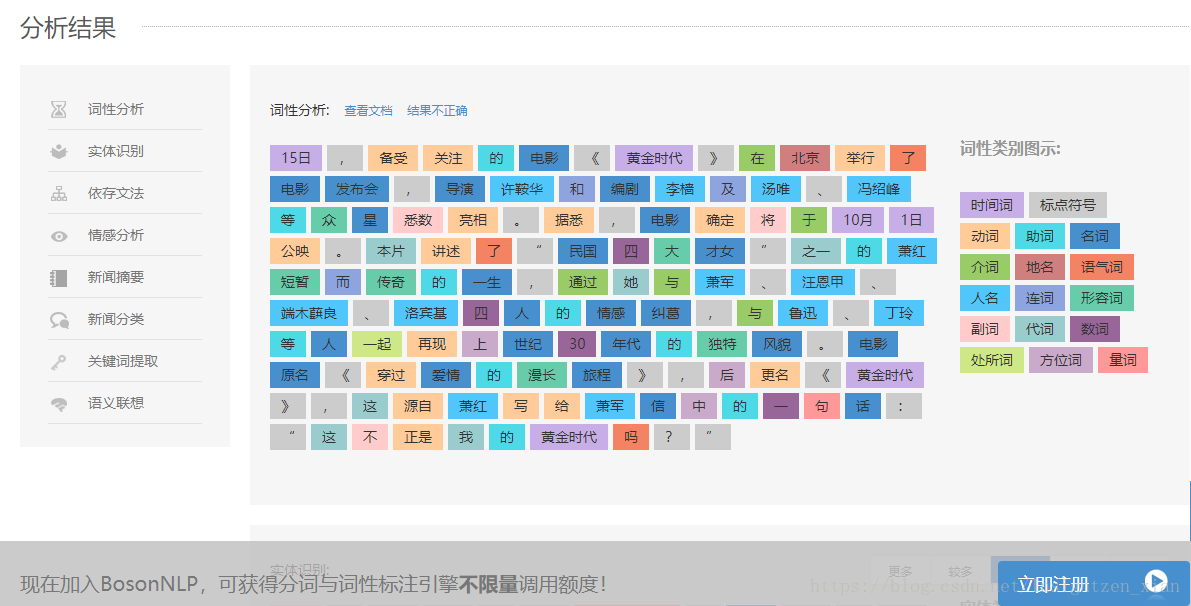
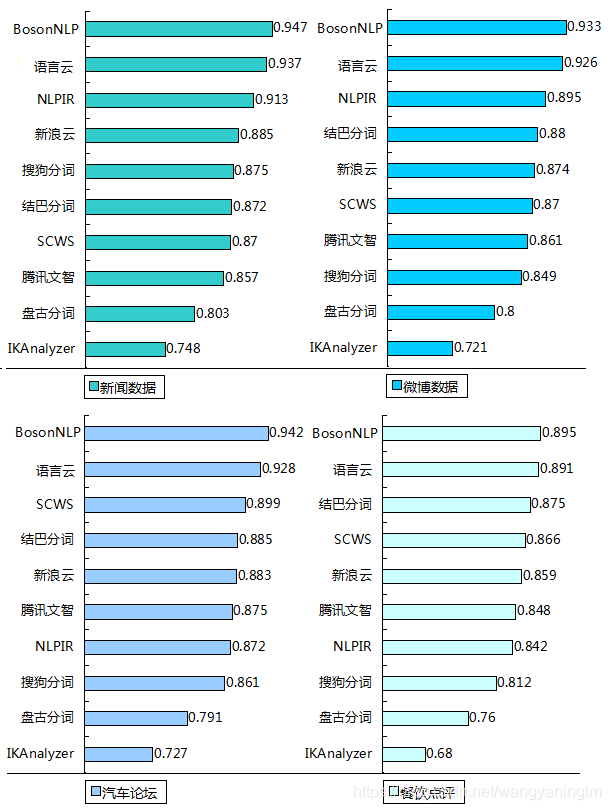
如果你在网上搜索汉语分词评测,十有八九你会搜索到专注于汉语自然语言处理技术的这家公司,以及下面这张评测结果:
2.2 云服务提供商
2.2.1 Amazon Comprehend

https://amazonaws-china.com/cn/comprehend/?nc2=h_a1
Amazon Comprehend 是一项自然语言处理 (NLP) 服务,可利用机器学习发现文本中的见解和关系。Amazon Comprehend 可以识别文本语言,提取关键的短语、地点、人物、品牌或事件,了解文本的含义是肯定还是否定,还可以自动按主题整理一系列文本文件。
您可使用 Amazon Comprehend API 分析文本,并将结果进行广泛应用,包括客户意见分析、智能文档搜索以及 Web 应用程序的内容个性化设置。
该服务不断地通过各种信息来源 (包括世界上最大的自然语言数据集之一:Amazon.com 商品描述和买家评论) 学习和提升, 以跟上语言的发展演变。
实例:利用 AWS Comprehend 打造近实时文本情感分析
https://amazonaws-china.com/cn/blogs/china/realizing-near-real-time-text-sentiment-analysis-with-aws-comprehend/
可以看到图中,aws 使用kibana 仪表盘和 Comprehend 服务组成了一个实时的电影评论实时分析系统,其实主要功能就是实现了分词和内容来源的地理位置统计,看起来很炫酷。
2.2.2 阿里云NLP

https://data.aliyun.com/product/nlp?spm=5176.8142029.388261.396.63f36d3eoZ8kNK
阿里的NLP 服务简介为:
自然语言处理是为各类企业及开发者提供的用于文本分析及挖掘的核心工具,
已经广泛应用在电商、文化娱乐、金融、物流等行业客户的多项业务中。
自然语言处理API可帮助用户搭建内容搜索、内容推荐、舆情识别及分析、文本结构化、对话机器人等智能产品,
也能够通过合作,定制个性化的解决方案。
- 1
- 2
- 3
- 4
- 5
按量付费的基准价,在没有购买资源包或资源包用尽的情况下,将按基准价进行计费。
其中,基础版对每个主帐号提供每日5万次的免费使用额度。商品评价解析没有免费额度。
值得注意的是阿里云的nlp 服务刚发布不到1年,应该算是领域内的新手,语料库应该和aws 一样,主要为商品描述和评论,所以它有一项功能叫做商品评价解析
时隔半年之后我们再来看一下这个产品名录发现,功能更加丰富了。整体来看受限于语料的积累,我认为没有什么亮点。

2.2.3 腾讯云NLP


https://cloud.tencent.com/product/nlp
界面友好,功能丰富,语料库为海量综合性语料库
腾讯云智在线演示系统
http://nlp.qq.com/semantic.cgi
2.2.4 百度语言处理基础技术

http://ai.baidu.com/tech/nlp
依托海量检索数据,并且搜索引擎本身就是NLP 最终的结果产出,所以在NLP领域,百度无论是语料库丰富程度,技术先进性,以及服务多样性等都是遥遥领先其他厂家,基本上可以算作是中文NLP服务提供商的业界最佳实践。
-
功能丰富且技术领先
- 词法分析
- 词向量表示
- 词义相似度
- 评论观点抽取
- 文章标签
- 依存句法分析
- DNN语言模型
- 短文本相似度
- 情感倾向分析
- 文章分类
- 对话情绪识别
- 文本纠错
- 新闻摘要
等13个大类的服务,对于个人开发者来说,配比了免费额度,对于词向量来说,每秒免费的额度是5个词,基本可以够用拿来做点有趣的事情了。
从图中结果也可以看出,百度对词向量相似度的分析和我用余弦相似度的结果一样,可以推断出百度的算法比较接地气。
- DNN语言模型
Deep Neural Network(DNN)模型是基本的深度学习框架,DNN语言模型是通过计算给定词组成的句子的概率,从而判断所组成的句子是否符合客观语言表达习惯
通常用于机器翻译、拼写纠错、语音识别、问答系统、词性标注、句法分析和信息检索等
百度这个模型是大厂中首个公开提供服务接口的深度学习语言模型。
- 调用方式友好简单
提供更加简单的调用方式:类似aws boto3
如果已安装pip,执行pip install baidu-aip即可
Sdk 方式,安装
from aip import AipNlp
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
word = "张飞"
""" 调用词向量表示 """
client.wordEmbedding(word);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.3 NLP开源组件简介
NLP 领域有非常多的开源组件可以用来快速构建开发的原型,我来简单介绍以下四个知名开源组件
2.3.1 NLTK
http://www.nltk.org/
- 最常用的自然语言处理库
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。基本包含了NLP 中需要用到的所有技术。
它提供了易于使用的接口,通过这些接口可以访问超过50个语料库和词汇资源(如WordNet),还有一套用于分类、标记化、词干标记、解析和语义推理的文本处理库,以及工业级NLP库的封装器和一个活跃的讨论论坛。 - 古腾堡项目(Project Gutenberg)
NLTK 包含古腾堡项目(Project Gutenberg)中电子文本档案的经过挑选的一小部分文本。该项目大约有57,000 本免费电子图书,放在http://www.gutenberg.org/上。我们先要用Python 解释器加载NLTK 包,然后尝试nltk.corpus.gutenberg.fileids(),当然其中的中文语料也很丰富(都是没有版权的免费文档),比如李白文集,三字经,百家姓等等(要是用这些训练中文模型效果可想而知)
2.3.2 Jieba分词
https://github.com/fxsjy/jieba
“结巴”中文分词:做最好的 Python 中文分词组件
“Jieba” (Chinese for “to stutter”) Chinese text segmentation: built to be the best Python Chinese word segmentation module.
实现基本功能的代码量在一千行左右,词典长度35w ,安装方式友好,简洁,高效,(但准确性已经跟不上时代!!!85%)
2.3.3 ICTCLAS
http://ictclas.nlpir.org/
主要功能包括中文分词;词性标注;中英混合分词;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码。新增微博分词、新词发现与关键词提取;张华平博士先后倾力打造20余年,内核升级10次。
全球用户突破20万,先后获得了2010年钱伟长中文信息处理科学技术奖一等奖,2003年国际SIGHAN分词大赛综合第一名,2002年国内973评测综合第一名。
2.3.4 Gensim
https://radimrehurek.com/gensim/
它的 slogan 是:Topic modelling for humans.
Gensim提供了一个发现文档语义结构的工具,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达。它将语料(Corpus)向量化表示后,主要能够实现以下三个功能:
- 建立语言模型
- 词嵌入模型的训练
- 检索和语义分析的神器
简介参考:https://www.cnblogs.com/iloveai/p/gensim_tutorial.html
参考文献
我爱自然语言处理
http://www.52nlp.cn/
深度学习与中文短文本分析总结与梳理
https://blog.csdn.net/wangyaninglm/article/details/66477222
分析了近5万首《全唐诗》,发现了这些有趣的秘密
http://www.growthhk.cn/cgo/9542.html
万字干货|10款数据分析“工具”,助你成为新媒体运营领域的“增长黑客”
http://www.woshipm.com/data-analysis/553180.html
jieba分词简介与解析
https://www.cnblogs.com/baiboy/p/jieba2.html
有哪些好的汉语分词方案
https://www.zhihu.com/question/19578687
基于分布式的短文本命题实体识别之----人名识别(python实现)
https://blog.csdn.net/wangyaninglm/article/details/75042151
NLP技术的应用及思考
https://yq.aliyun.com/articles/78031

