
- 1用Wokwi仿真ESP-IDF项目
- 2基于ssm的在线挂号小程序系统_ssm 医院挂号
- 3Dify 基于 ChatGPT 构建本地知识库问答应用
- 4mysql bigint与md5_mysql常见的优化需要注意的点
- 5基于FPGA的时间数字转换器(TDC)设计与Verilog实现_fpga tdc
- 6库卡机器人怎么用c语言写程序,KUKA机器人之了解简单的机器人程序
- 7解决 Pycharm 输出信息中文乱码_pycharm中文输出utf8乱码
- 8python编程人工智能小例子,《人工智能python课程》_编写一个小型的人工智能系统
- 9MySQL 高级SQL语句(三)——存储过程_创建存储过程的sql语句
- 10Mysql之常见可视化管理工具_mysql可视化管理工具
基于任务型对话的医疗诊断 Task-oriented Dialogue System for Automatic Diagnosis_ct图像 医疗对话
赞
踩
这项基于任务型对话的自动医疗诊断工作来自复旦大学黄萱菁团队,发表在ACL Short 2018(Task-oriented Dialogue System for Automatic Diagnosis)。初步看该工作和NIPS RL workshop 2016上的神经症状检查器的工作思路是相似的,将AI智能体跟患者多轮问诊的症状获取过程看成马尔可夫序列决策过程,然后基于强化学习算法进行训练。该工作的贡献包括:
1. 标注了第一个面向对话系统的医疗数据集,该数据由两部分组成,一部分是患者的自述,另一部分是患者和医生之间的对话数据;
2. 提出了一个基于强化学习的医学对话系统框架。在我们的数据集上的实验结果表明,我们的对话系统能够通过对话收集患者的症状,并提高自动诊断的准确性。
3. 公开了实现代码(https://github.com/LiuQL2/MedicalChatbot)和数据(http://www.sdspeople.fudan.edu.cn/zywei/data/acl2018-mds.zip)。
但是,该工作也存在较多待完善之处:
1. 疾病种类仅有4种,相比之下,NIPS RL workshop 2016上的神经症状检查器工作进行了100种疾病诊断;
2. 基于强化学习任务型对话进行症状采集的创新性不足,和 NIPS RL workshop 2016上的神经症状检查器的思路是相似的,只是增加了动作空间的多样性;
3. 诊断的准确率不高,对比方法简单。本文实现的DQN模型性能甚至没有超过SVM分类性能,这一点作者在实验结果分析中也提到。另外,基于规则的方法复杂代码实现存在一点bug,导致性能略低一些,正常结果补充在如下表5的备注。说明如何设计好的诊断系统依然任重道远。
基于任务型对话在医疗诊断方面工作应该是论文通讯作者魏忠钰在港中文大学黄锦辉团队读书期间的延续工作,毕业后与港中文团队中做任务型对话同学在医疗对话方面的探索尝试。该工作的具体实现方法我们在下文中对该工作进行详细介绍。
目录
1. 摘要
在本文中,我们着手建立一个自动诊断对话系统。我们首先从在线医学论坛收集数据集,通过患者的自述和患者与医生之间的对话数据中提取症状。然后,我们提出了一个任务型的对话系统框架来对患者进行自动医疗诊断,该框架通过与患者的对话收集患者自述之外的其他症状。在我们数据集上的实验结果表明,从对话中提取的额外症状可以极大地提高疾病诊断的准确性,我们的对话系统能够自动收集这些症状并做出更好的诊断。
2. 引言
近年来,利用电子健康记录(electronic health records,EHRs)进行自动表型识别(phenotype identification)已经成为一个新兴研究热点[15]。研究人员利用各种机器学习方法,基于患者提供的多种类型信息(包括数字数据和纯文本)进行症状和疾病识别。一些实验结果证明了在心力衰竭[4,1]、2型糖尿病[6,22]、自闭症谱系障碍[3]、感染检测[18]等疾病方面识别的有效性,大多数工作尝试侧重于某些特定类型的疾病,很难将模型从一种疾病迁移到另一种疾病。
一般来说,每个EHR包含多种类型的数据,包括个人信息、入院记录、诊断测试、生命体征和医学影像等。它是在临床诊断过程中积累起来的,包括病人和医生之间的交互以及一些复杂的医学检查。因此,收集不同疾病的EHR非常昂贵。如何自动收集患者的信息进行自动诊断是一项具有挑战的任务。
最近,任务型对话系统表现出较大潜力和诱人的商业价值,相关的研究在不同领域引起了越来越多的关注,包括订票[7,11]、在线购物[20]和餐馆搜索[19]。我们相信,在医学领域应用对话系统有很大潜力能够降低从患者收集数据的成本。
然而,将对话系统应用在疾病识别领域尚存在技术鸿沟。基本上有两大挑战:首先,缺乏带标注的医学对话数据集。第二,没有可用的疾病识别框架。通过解决这两个问题,我们第一步是建立一个对话系统,促进医学领域的自动信息收集和诊断。论文的贡献可以总结为如下两个方面:
(1)我们标注了第一个面向对话系统的医疗数据集,该数据由两部分组成,一部分是患者的自述,另一部分是患者和医生之间的对话数据;
(2)我们提出了一个基于强化学习的医学对话系统框架。在我们的数据集上的实验结果表明,我们的对话系统能够通过对话收集患者的症状,并提高自动诊断的准确性。
3. 面向医疗对话系统的数据集
我们的数据集收集自中国在线医疗社区(http://muzhi.baidu.com/)的儿科,这是一个受欢迎的网站,患者可以在线咨询医生。通常,患者会提供一份自述,介绍其基本情况。然后医生会开始一个对话问诊来收集更多信息,并根据患者自述和对话问诊进行诊断。表1给出了一个示例。正如我们所见,除了患者自述之外,医生还可以在问诊中获得其他症状。对于每个患者,我们也可以从医生那里获得最终诊断结果作为标签。为了清楚起见,我们将自述中的症状称为显性症状,而将对话数据中的症状称为隐性症状。
表1. 一个用户记录样例。每份记录包含两部分:患者自述和医患对话。下划线部分为症状表述。

我们选择了四种疾病进行标注,包括上呼吸道感染、儿童功能性消化不良、婴儿腹泻和儿童支气管炎。我们邀请三位标注者(其中一位具有医学背景)在患者自述和医患对话数据中标注所有症状短语。标注分为两个步骤,即症状提取和症状规范化。
症状提取:我们遵循BIO(begin-in-out)模式进行症状识别(图1)。每个汉字都有一个“B”、“I”或“O”的标签(如图1所示)。此外,每个提取的症状表达短语都带有一个True或False标记,指示患者是否患有该症状。为了提高标注者之间的标注一致性,我们分别为患者自述和医患对话数据建立了两个准则。每条记录至少由两个标注人员进行标注。任何不一致的标注将由第三位标注人员进一步判断。对于患者自述和医患对话,两位标注人员之间的科恩卡帕系数分别为71%和67%。

图1. 基于BIO形式进行症状标注的句子样例。
症状规范化:在症状表达识别后,医学专家手动将每个症状表达与SNOMED CT(https://www.snomed.org/snomed-ct)上最相关的概念连接起来进行规范化。表2展示了示例中描述症状的一些短语以及SNOMED CT中相关概念。数据集概述如表3所示。
表2:抽取的症状表达短语与SNOMED CT中相关概念的示例。

表3:数据集概述。 of user goal表示每种疾病的对话数量;Ave
of explicit symptoms表示患者显性症状的平均数量,Ave
of implicit symptoms表示患者隐性症状的平均数量。

症状提取和规范化后,系统共识别出144个独立的症状。为了减少对话系统的动作空间,只保留了67个频率大于或等于10的症状。然后生成样本,我们在本文中将样本称为用户目标(user goal)。正如我们所述,每个用户目标(如图2所示)都来自一个真实世界的患者记录。

图2. 一个用户目标的样例。每个用户目标由四部分组成,disease_tag是用户患有的疾病;explicit_symptoms是从用户自述中提取的症状;implicit_symptoms是从患者和医生之间的对话数据中提取的症状;request_slots是用户猜测的疾病槽。
4. 模型框架
任务型对话系统通常包含三个组件,即自然语言理解(NLU)、对话管理(DM)和自然语言生成(NLG)。NLU基于对话句子检测用户和语义槽;DM跟踪对话状态并采取系统动作;NLG根据系统动作生成自然语言。在这项工作中,我们重点研究了进行医疗诊断的对话管理,它由两个子模块组成,即对话状态跟踪器(DST)和策略学习。NLU和NLG都是用基于模板的模型实现的。这种情况,通常地,会设计一个用户模拟器与对话系统进行交互[8,12,16,14]。我们遵循与Li等人[7]相同的设置来设计我们的医疗对话系统。在医患对话开始时,用户模拟器对用户目标进行采样(见图2),同时AI智能体尝试为用户进行医疗诊断。AI智能体将学习通过最大化长期回报,在每个时间步选择最佳动作。
4.1 用户模拟器(患者)
在每个医患对话开始时,用户模拟器会从实验数据集中采样用户目标。在每轮对话时刻时,用户根据当前用户状态
和前一个AI智能体动作
执行当前用户动作
,并状态转移到下一个用户状态
。在实践中,用户状态
被分解成议程
[13]和目标
,即
确保用户以一致的、面向目标的方式行事。议程包含症状及其状态(无论是否被要求)的列表,以跟踪对话的进展。
每个对话由用户通过用户动作开始,包括自己猜测的请求疾病槽和所有显示的症状。对于AI智能体在对话过程中问诊的症状,用户将采取三种动作之一,包括True(如果症状为阳性)、False(如果症状为阴性)和not_sure(如果用户目标中未提及该症状)。如果AI智能体诊断正确的疾病,对话将被用户成功终止。否则,如果AI智能体做出错误诊断或对话轮数达到最大对话轮数
,则对话将被识别为失败。
4.2 对话策略学习(医生)
自动诊断的马尔可夫决策过程形式化:我们将对话系统描述为马尔可夫决策过程(MDP)[21],并通过强化学习训练对话策略[2]。一个MDP由状态、动作、奖励、策略和转移组成,具体描述如下。
状态:对话状态
包括在当前时间
之前由AI智能体问诊并由用户告知的症状、用户的前一动作、AI智能体的前一动作和对话轮数信息。就症状的表示向量而言,它的维度等于所有症状的数量,阳性症状的元素值为1,阴性症状的元素值为-1,不确定症状为−2,而未提及的症状为0。每个状态
是这四个向量的拼接。
动作:动作
由对话动作(如通知、请求、拒绝和确认)和语义槽(即规范化症状或疾病槽)组成。此外,表示感谢和结束对话也是两种对话动作。
转移:从
到
的转移是基于AI智能体当前动作
,用户上一时刻动作
,以及时间步
对AI智能体状态
的更新操作。
奖励:奖励
是在采取行动
后在时间步
的即时奖励,也称为强化。
政策:该策略描述AI智能体的行为,以状态
作为输入,并输出所有可能动作的概率分布
基于深度Q网络的学习:在本文中,利用深度Q网络(DQN)参数化对话策略[10],该网络以状态作为输入,并输出所有动作
的
迭代步参数
的更新迭代进行学习以减小从当前网络
的目标网络。在实践中,动作分布通常由
-贪婪策略选择,该策略以概率
采取行动
的随机动作,这可以提高探索效率。在训练策略时,我们使用了经验回放(experience reply)的技术。我们在存储AI智能体每个时间步的经验,
中。
在每一轮训练过程中,使用从缓冲区随机抽取不同批次的数据对当前DQN网络进行多次更新(取决于批次大小和当前回放缓冲区的大小),而目标DQN网络在当前DQN网络更新期间是固定的。在每轮训练结束时,将目标网络替换为当前网络,并在训练集上对当前网络进行评估。如果当前网络的性能优于所有以前的版本,则会刷新缓冲区。
医生和患者的动作空间一共有11种类型,具体包括({'request': 0, 'inform': 1, 'confirm_question': 2, 'confirm_answer': 3, 'greeting': 4, 'closing': 5, 'multiple_choice': 6, 'thanks': 7, 'welcome': 8, 'deny': 9, 'not_sure': 10}),而其中({'request': 0, 'inform': 1})可以请求或告知多种症状或疾病。
5. 实验结果
5.1 实验设置
对话的最大轮数为22。在对话成功结束时,AI智能体将获得+44的正奖励,并且对话失败时,AI智能体将获得−22的负奖励。我们对每个对话轮数给予-1的惩罚,以鼓励采用较少轮数完成对话。数据集分为两部分:80%的用户目标进行模型训练,数据量为568;20%的用户目标进行模型测试数据量为142。为了有效的动作空间探索,
贪婪策略的
设置为0.1,Bellman方程中的
设置为0.9。缓冲区
的大小为10000,批量大小为30。DQN的神经网络是一个单层神经网络。学习率为0.001。每轮训练过程由100个对话数据组成,并且当前网络在每轮训练结束时在500个对话数据上进行评估。在训练之前,缓冲区预先填满了基于规则智能体的经验(下面会介绍),以热启动我们的对话系统。
为了评估本文所提框架的性能,我们参考Li等人[7]和Peng等人[11,12]的评估方法,采用三个评估指标对我们的模型与基线进行比较,包括成功率(success rate)、平均奖励(average reward)和每次对话的平均轮次(average number of turns per dialogue session)。对于分类模型,我们使用准确率作为评估指标。
对比模型包括(1)支持向量机:该模型将自动诊断视为一个多分类问题。它将用户目标中症状的one-hot表示作为输入预测疾病。我们进行两种配置:一种是以显性和隐性症状同时作为输入(表示为SVM-ex&im),另一种是仅以显性症状预测疾病(表示为SVM-ex);(2)随机智能体:在每个对话轮数中,随机智能体从动作空间中随机执行一个动作,作为对用户动作的响应。(3) 基于规则的智能体:基于规则的智能体根据手工制定的规则执行动作。在当前对话状态的条件下,如果检测到所有已知的相关症状,智能体将告知疾病。如果无法确定疾病,智能体将随机选择左侧症状之一进行告知。疾病和症状之间的关系是从预先标注的语料库中提取出来的。在这项工作中,每种疾病只保留前
高频率的症状,以便基于规则的智能体可以在最大对话轮数
告知疾病。
5.2 结果分析
表4展示了两个基于SVM模型的准确度。结果表明,挖掘隐性症状可以大大提高四种疾病的疾病识别准确率,这表明隐性症状在患者诊断中的作用非常明显。图3展示了三种对话系统的学习曲线,表5展示了这些智能体在测试集上的性能。由于动作空间大,随机智能体的性能很差。基于规则的智能体在很大程度上优于随机智能体。这表明基于规则的智能体设计良好。我们还可以看到,基于强化学习的的深度Q网络智能体显著优于基于规则的智能体。此外,DQN智能体通过与患者问诊收集额外的隐性症状,使得我们模型的表现优于SVM-ex。但是,在准确率方面,DQN智能体和SVM ex&im的性能仍然存在差距,这表明对话系统仍有较大改进的空间。
表4. 分类模型的准确度。


图3. 策略学习的学习曲线。
表5. 在5K个模拟对话数据上的3种对话系统的性能。

注:Rule Agent实现存在bug,修复后性能为:Success: 0.32, Reward: -8.78, Turn: 18.49。这里我们思考一个问题:既然Rule Agent是基于症状-疾病映射表进行询问的,然后诊断也是基于症状-疾病映射得到的,那么为什么Success只有0.32这么低?主要原因是对话轮数的限制,如果我们在不改变动作空间大小的情况下,提升最大轮数限制至50的话,Rule Agent的性能可提升至Success: 0.56, Reward: 25.83, Turn: 20.54。
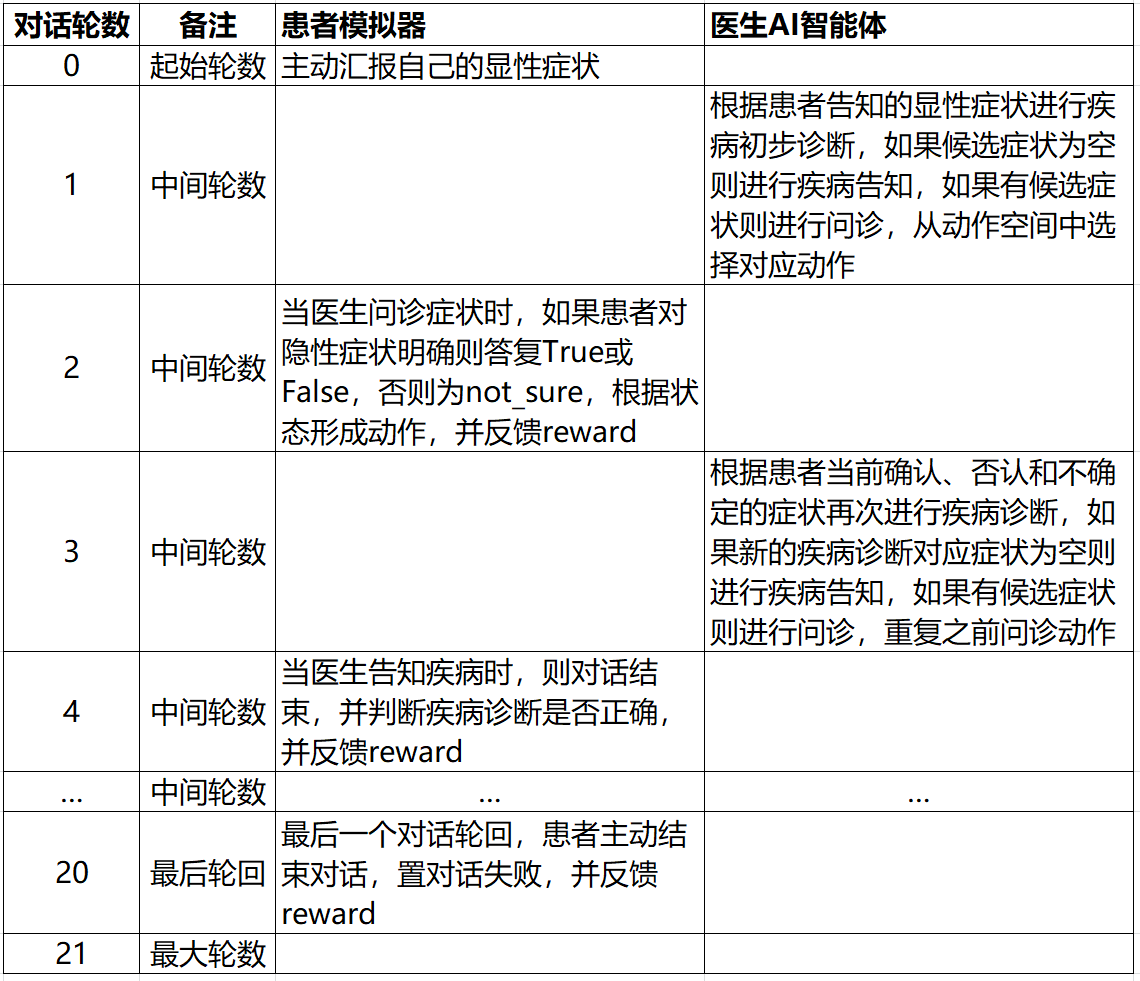
对基于规则的医患对话流程进行简单总结,如下表6所示
表6. 基于规则的医患对话流程示意
6. 相关工作
2003年,Milward和Beveridge[9]曾提出一个基于本体的对话系统,该系统支持乳腺癌的电子转诊,可以基于医学领域本体处理用户的信息响应。此外,有两项研究将深度强化学习应用于自动诊断[17,5]。然而,他们的模型需要额外的人力资源来将疾病分为不同的组,使用的数据是模拟的,不能反映真实患者的情况。
7. 总结与未来
在本文中,我们面向自动诊断问题,提出了一个基于强化学习的对话系统框架,并根据真实患者和医生之间的对话文本构建了一个用于训练对话系统的数据集。在我们构建数据集上的实验结果表明,我们的对话系统能够通过与患者的对话收集额外的隐性症状,并提高自动诊断的准确性。疾病与症状之间的关系是一种外部知识,被认为有助于自动诊断。我们未来的一个方向是探索能够结合外部知识的模式,以便进行更好地策略学习。
参考文献
[1] Edward Choi, Andy Schuetz, Walter F Stewart, and Ji[1]meng Sun. 2016. Using recurrent neural network models for early detection of heart failure onset. Journal of the American Medical Informatics Association 24(2):361–370.
[2] Heriberto Cuayahuitl, Simon Keizer, Oliver Lemon, et al. 2015. Strategic dialogue management via deep reinforcement learning. CoRR.
[3] Finale Doshi-Velez, Yaorong Ge, and Isaac Kohane. 2014. Comorbidity clusters in autism spectrum dis[1]orders: an electronic health record time-series analysis. Pediatrics 133(1):e54–e63.
[4] Siddhartha R Jonnalagadda, Abhishek K Adupa, Ravi P Garg, Jessica Corona-Cox, and Sanjiv J Shah. 2017. Text mining of the electronic health record: An information extraction approach for automated identification and subphenotyping of hfpef patients for clinical trials. Journal of cardiovascular translational research 10(3):313–321.
[5] Hao-Cheng Kao, Kai-Fu Tang, and Edward Y Chang. 2018. Context-aware symptom checking for disease diagnosis using hierarchical reinforcement learning.
[6] Li Li, Wei-Yi Cheng, Benjamin S Glicksberg, Omri Gottesman, Ronald Tamler, Rong Chen, Erwin P Bottinger, and Joel T Dudley. 2015. Identification of type 2 diabetes subgroups through topological analysis of patient similarity. Science translational medicine 7(311):311ra174–311ra174.
[7] Xiujun Li, Yun-Nung Chen, Lihong Li, Jianfeng Gao, and Asli Celikyilmaz. 2017. End-to-end task-completion neural dialogue systems. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers). volume 1, pages 733–743.
[8] Bing Liu, Gokhan Tur, Dilek Hakkani-Tur, Pararth Shah, and Larry Heck. 2017. End-to-end optimization of task-oriented dialogue model with deep reinforcement learning https://arxiv.org/abs/1711.10712.
[9] David Milward and Martin Beveridge. 2003. Ontology-based dialogue systems. In Proc. 3rd Workshop on Knowledge and reasoning in practical dialogue systems (IJCAI03). pages 9–18.
[10] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidje[1]land, Georg Ostrovski, et al. 2015. Human-level control through deep reinforcement learning. Nature 518(7540):529–533.
[11] Baolin Peng, Xiujun Li, Jianfeng Gao, Jingjing Liu, Yun-Nung Chen, and Kam-Fai Wong. 2017a. Adversarial advantage actor-critic model for task-completion dialogue policy learning.
https://arxiv.org/abs/1710.11277.
[12] Baolin Peng, Xiujun Li, Lihong Li, Jianfeng Gao, Asli Celikyilmaz, Sungjin Lee, and Kam-Fai Wong. 2017b. Composite task-completion dialogue policy learning via hierarchical deep reinforcement learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. pages 2231–2240.
[13] Jost Schatzmann, Blaise Thomson, Karl Weilhammer, Hui Ye, and Steve Young. 2007. Agenda-based user simulation for bootstrapping a pomdp dialogue system. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers. Association for Computational Linguistics, pages 149–152.
[14] Jost Schatzmann, Karl Weilhammer, Matt Stuttle, and Steve Young. 2006. A survey of statistical user simulation techniques for reinforcement-learning of dialogue management strategies. The knowledge engineering review 21(2):97–126.
[15] Chaitanya Shivade, Preethi Raghavan, Eric Fosler-Lussier, Peter J Embi, Noemie Elhadad, Stephen B Johnson, and Albert M Lai. 2013. A review of approaches to identifying patient phenotype cohorts using electronic health records. Journal of the American Medical Informatics Association 21(2):221–230.
[16] Pei-Hao Su, Milica Gasic, Nikola Mrksic, Lina Rojas-Barahona, Stefan Ultes, David Vandyke, Tsung-Hsien Wen, and Steve Young. 2016. Continuously learning neural dialogue management https://arxiv.org/abs/1606.02689.
[17] Kai-Fu Tang, Hao-Cheng Kao, Chun-Nan Chou, and Edward Y Chang. 2016. Inquire and diagnose: Neural symptom checking ensemble using deep reinforcement learning. In Proceedings of NIPS Work[1]shop on Deep Reinforcement Learning.
[18] Huaixiao Tou, Lu Yao, Zhongyu Wei, Xiahai Zhuang, and Bo Zhang. 2018. Automatic infection detection based on electronic medical records. BMC bioinformatics 19(5):117.
[19] TH Wen, D Vandyke, N Mrksıc, M Gasıc, LM Rojas-Barahona, PH Su, S Ultes, and S Young. 2017. A network-based end-to-end trainable task-oriented dialogue system. In 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017-Proceedings of Conference. volume 1, pages 438–449.
[20] Zhao Yan, Nan Duan, Peng Chen, Ming Zhou, Jian-she Zhou, and Zhoujun Li. 2017. Building task-oriented dialogue systems for online shopping. In AAAI. pages 4618–4626.
[21] Steve Young, Milica Gasiˇc, Blaise Thomson, and Jason D Williams. 2013. Pomdp-based statistical spoken dialog systems: A review. Proceedings of the IEEE 101(5):1160–1179.
[22] Tao Zheng, Wei Xie, Liling Xu, Xiaoying He, Ya Zhang, Mingrong You, Gong Yang, and You Chen. 2017. A machine learning-based framework to identify type 2 diabetes through electronic health records. International journal of medical informatics 97:120–127

