
- 1苍穹外卖项目(黑马)学习笔记DAY5_黑马外卖项目
- 2unity支持鸿蒙,#Unity# #ARKit3# Unity宣布支持ARKit3
- 3Github 上有趣的项目,用机器学习训练 AI 下五子棋_五子棋ai训练
- 4鸿蒙APP开发实战:【Api9】拍照、拍视频;选择图片、视频、文件工具类_华为鸿蒙api
- 5Transformer架构中基于窗口的的自注意力机制W-MSA和滑动窗口自注意力机制SW-MSA的实现_滑动窗口注意力机制
- 6HBase安装_hbase-2.5.5-hadoop3-client-bin.tar.gz
- 7failed to update store for object type *libnetwork.endpointCnt: Key not found in store
- 8转载:智能驾驶域控制器的软件架构及实现(下)-支持L3+的软件架构及产品架构_智能驾驶集中式架构
- 9蓝桥杯,进决赛了
- 10解决方案:2024年Pytorch(GPU版本)+ torchvision手动安装教程[万能安装方法] win64、linux、macos、arm、aarch64均适用_pytorch gpu版本
离散数学复习笔记(已完结)_离散数学笔记
赞
踩
前言
本篇为《离散数学》学科的个人复习笔记,知识点有所偏重。
课本是上海科学技术文献出版社左孝凌版的《离散数学》。
课本中定义和定理过多,文章中只记录课本中和课堂上重要常用的的定义和定理,不会做深入的解释,会有一些疏漏。
因为部分符号打不出来,所以中间插入的图片会比较多。
已完结。如有错误烦请提出。
以下是正文
离散数学主要分为四部分:
- 数理逻辑
- 集合论
- 代数系统
- 图论
数理逻辑
古典逻辑
亚里士多德的三段论:
大前提 --> 小前提 --> 结论
莱布尼兹把推理归纳为符号计算,提出思维运算的思想。
布尔发明布尔代数,(亦可解释为集合代数)
摩根几乎同时独立地作出重要贡献
弗雷格第一个提出公理化谓语逻辑系统“概念文字”,是亚里士多德以来逻辑的重大进展,基本实现莱布尼兹的梦想。
数理逻辑的内容:
命题逻辑
谓词逻辑
公理化集合论
递归论
证明论
命题逻辑
基本概念
定义:
命题是一个能判断真假的陈述句
命题不能是疑问句、命令句、感叹句等
真值的几点说明:
时间性
区域性
标准性
定义:
对于一个任意给定的命题,如果不能分解为更简单的命题,就称为原子命题,反之,成为复合命题。
命题联结词
否定,合取,析取,蕴含(条件)、等值


需要注意的有:
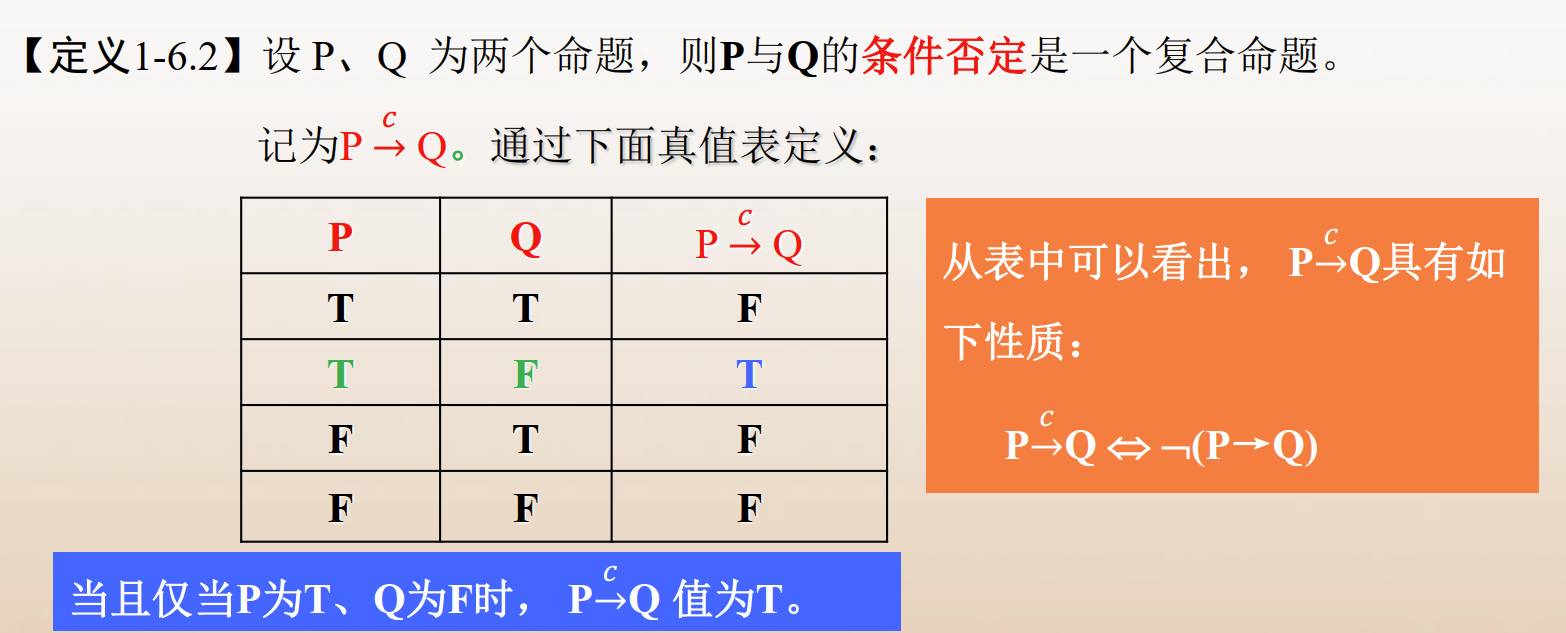
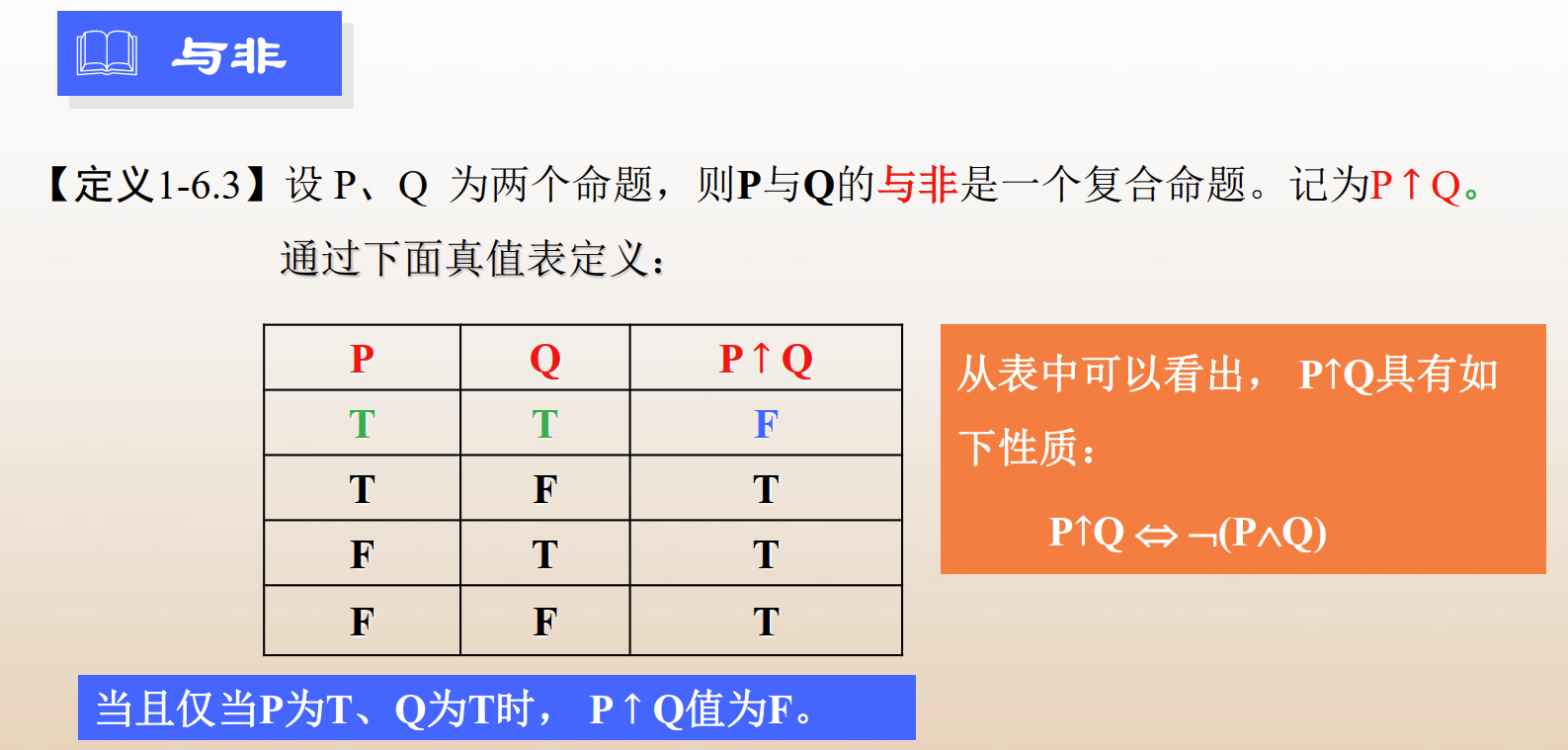
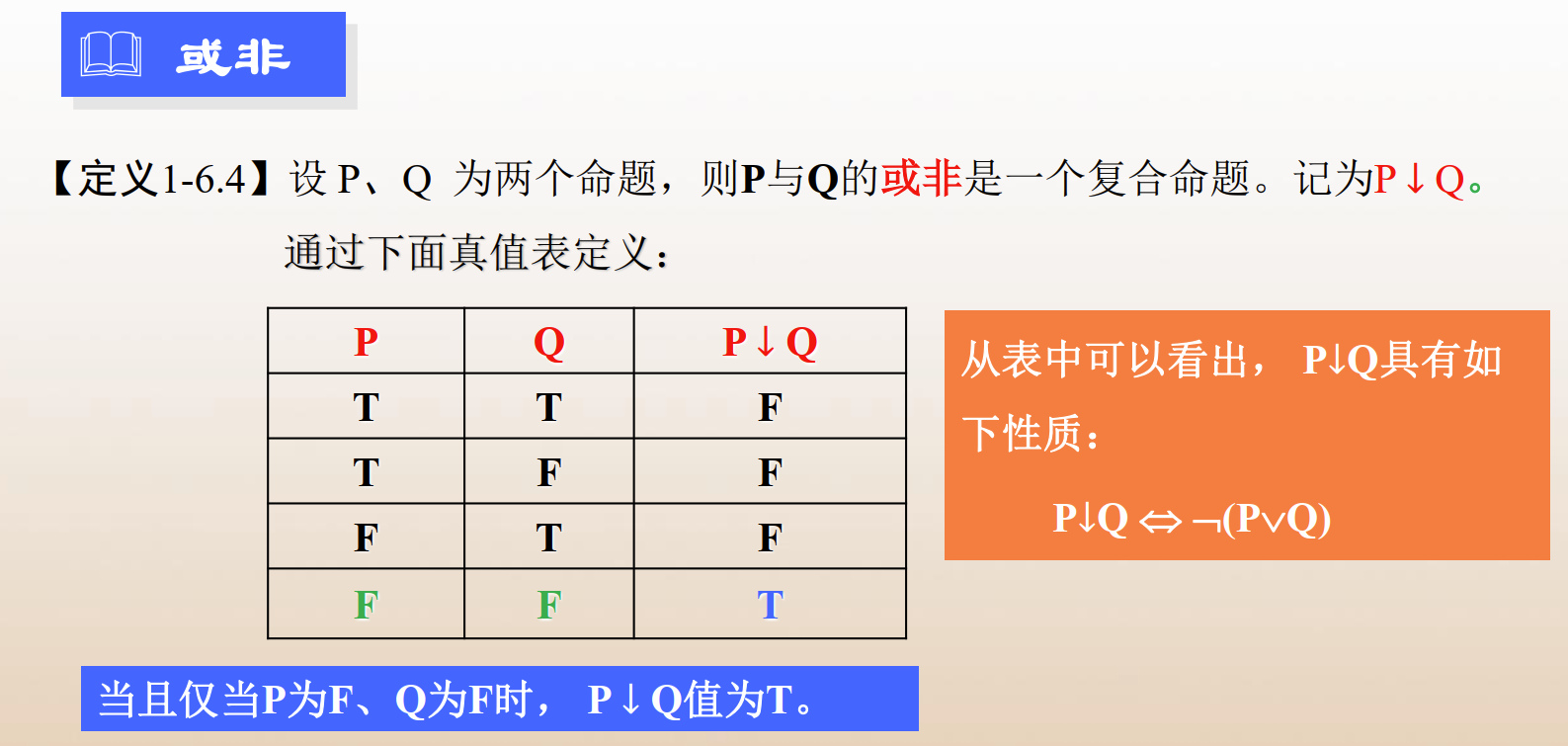
- 条件(蕴含):当且仅当 P 为真,Q 为假时,P→Q 为假;否则, P→Q 均为真。
条件 → 决定了哪个作为前件,哪个作为后件。 - 双条件(等值):当且仅当P、Q相同的时候,P↔Q为真,否则为假。
- 优先级:
否定 > 合取 > 析取 > 条件 > 双条件
- 不可兼或 (不可兼析取):▽
(与异或相似)

 例题:
例题:

公式分类
赋值永远是“真”值的式子称为永真公式,又称重言式。
赋值永远是“假”值的式子称为永假公式,又称矛盾式。
既有真值又有假值的式子称为可满足式

命题等价
定义
如果对两个公式A,B不论作何种指派,它们的真值均相同,则称A,B是逻辑等价的,亦说A等价于B,记A⇔B.
定理
命题公式A⇔B的充要条件是A↔B为永真式。
常用等价式:

除了利用真值表的方法证明两个命题公式的等价,还可以采用等价代换(等价置换)的方法进行证明。
利用公式的等值演算,可以实现以下三个基本目的
判定命题公式的基本类型,即判定或证明一个命题公式为永真或永假
证明两个命题公式之间具有等值关系
对复杂的命题公式进行化简。
命题蕴含
定义
命题公式A称为永真蕴含命题公式B,当且仅当A→B是一个永真式,记作:A=>B
注意 A=>B 与 A→B 的区别

其他联结词的补充:
对偶与范式
对偶


范式


简单合取式又称小项,真值表中小项为“真”,全体小项的析取式(即为主析取范式)为永真式。
简单析取式又称大项,真值表中大项为“假”,全体大项的合取式(即为主合取范式)为永假式。
对于任意命题公式,都存在与其等值的析取范式和合取范式。
真值表中小项为真,大项为假。
例:离散数学程序实验(C语言)——程序求主析取范式和主合取范式
输入一个逻辑表达式,根据真值表法求取该表达式的主合取范式和主析取范式。
算法思路:
把命题公式改为后缀表达式,并把后缀处理的结果保存在结构体里,对各个逻辑运算符号进行优先级的定义,按照后缀表达式的方法进行赋值计算并将结果输出存储为真值表。按照真值表选择输出主合取范式和主析取范式。
(此处附上实验代码仅供参考)
#include<stdio.h> #include<string.h> #define T 1 #define F 0 struct Stack{ int top; char zf[80]; }number={-1},symbol={-1}; //number储存后缀表达式结果 //symbol 操作符栈,用来保存操作符 int book[26];//记录变元元素和个数 int num=0;//记录变元的个数 int alphabet_true_false[26]; int enum_result[80]; char str_copy[80]; void numbers(char str[]); void strings(char str[]); void reverse_polish(char s[]); int check(int num); void function(int num); int main() { int i=0; char str[80]; printf("**************************************\n"); printf("使用小写字母表示变元,\n使用‘&’表示合取,\n使用‘|’表示析取,\n使用‘>’表示条件,\n使用‘<’表示双条件\n"); printf("**************************************\n"); strings(str); reverse_polish(str); function(num); return 0; } void numbers(char str[]){ int i,len=strlen(str); for(i=0;i<len;i++){ if(str[i]>='a'&&str[i]<='z'){ if(book[str[i]-'a']==0){ book[str[i]-'a']=1; ++num; } } } } void strings(char str[]){ int i; gets(str); strcpy(str_copy,str); numbers(str);//记录变元的个数,用全局变量num储存 int len=strlen(str); for(i=0;i<len;i++){ switch(str[i]){ case '!':str[i]=')'+5;break; case '&':str[i]=')'+4;break; case '|':str[i]=')'+3;break; case '>':str[i]=')'+2;break; case '<':str[i]=')'+1;break; } } } void reverse_polish(char s[]){ int i,len=strlen(s); for(i=0;i<len;i++){ if(s[i]>='a'&&s[i]<='z'){//如果是命题变元就直接入number栈 number.zf[++number.top]=s[i]; }else if(s[i]>')'&&s[i]<=5+')'){ //符号为逻辑运算符 if(symbol.top==-1||symbol.zf[symbol.top]==')'){ ++symbol.top; symbol.zf[symbol.top]=s[i]; }else if(s[i]>=symbol.zf[symbol.top]){ ++symbol.top; symbol.zf[symbol.top]=s[i]; }else{ while(symbol.top!=-1&&s[i]<symbol.zf[symbol.top]){ ++number.top; number.zf[number.top]=symbol.zf[symbol.top]; --symbol.top; } --i; } } else if(s[i]=='('||s[i]==')'){ if(s[i]=='('){ ++symbol.top; symbol.zf[symbol.top]=s[i]; }else{ while(symbol.zf[symbol.top]!='('){ ++number.top; number.zf[number.top]=symbol.zf[symbol.top]; --symbol.top; } if(symbol.top!=-1)--symbol.top; } } } while(symbol.top!=-1){ ++number.top; number.zf[number.top]=symbol.zf[symbol.top]; --symbol.top; } } int check(int num){ struct Stack ans={-1}; int i,k=0,len=0,temp; for(i=0;i<26;i++){ if(book[i]){ ++len; alphabet_true_false[i]=enum_result[k++]; } } for(i=0;i<=number.top;i++){ if(number.zf[i]>='a'&&number.zf[i]<='z'){ ++ans.top; ans.zf[ans.top]=alphabet_true_false[number.zf[i]-'a']; }else{ switch(number.zf[i]){ case '.': ans.zf[ans.top]=!ans.zf[ans.top]; break; case '-': ans.zf[ans.top-1]=ans.zf[ans.top-1]&ans.zf[ans.top]; --ans.top; break; case ',': ans.zf[ans.top-1]=ans.zf[ans.top-1] | ans.zf[ans.top]; --ans.top; break; case '+': ans.zf[ans.top-1]=!ans.zf[ans.top-1]|ans.zf[ans.top]; --ans.top; break; case '*':ans.zf[ans.top-1]= (!ans.zf[ans.top-1]|ans.zf[ans.top]) &(!ans.zf[ans.top]|ans.zf[ans.top-1]); --ans.top; } } } printf("%4d\n",ans.zf[0]); return ans.zf[0]; } void function(int num){ int i,j; int conjunction_top=-1,disjunction_top=-1; int result_conjunction[80]={0}; int result_disjunction[80]={0}; for(i=0;i<26;i++) if(book[i])printf("%4c|",i+'a'); putchar(' '),puts(str_copy); for(i=0;i<(1<<num);i++){// memset(enum_result,0,num); for(j=0;j<num;j++){ if(i&(1<<(num-j-1))){ enum_result[j]=T; }else{ enum_result[j]=F; } printf("%4d|",enum_result[j]); } if(check(num)){ result_disjunction[++disjunction_top]=i; }else{ result_conjunction[++conjunction_top]=i; } } puts("\n主析取范式为:"); for(i=0;i<=disjunction_top;i++){ printf("m%d%s",result_disjunction[i],i^disjunction_top?"&":""); } puts("\n主合取范式为:"); for(i=0;i<=conjunction_top;i++){ printf("M%d%s",result_conjunction[i],i^conjunction_top?"|":""); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
推理理论
验证推理有效性的方法:
真值表
命题演算
命题演算三要素:
推理依据
推理规则
推理方法
推理规则:
P 规则(引入前提规则):在推导的任何步骤上,都可以引入前提。
T 规则(引入结论规则):在推导过程中,如果前面有一个或多个命题公式永真蕴含命题公式 S,那么就可以把公式 S 也引入到推导过程之中。
CP规则:如果H1∧H2∧…∧Hn∧R => S,则H1∧H2∧…∧Hn => R→S
推理依据:
主要指已知的逻辑等价式和逻辑蕴含式
推理方法:
直接证法
间接证法(反证法 和 附加前提条件证法)
直接推理
由一组前提,利用P规则,T规则直接推演得到有效结论的方法。
条件论证(附加前提条件证法)
如果要证明的结论是R→S形式,则可以把结论中R→S的前件R作为附加前提,与给定的前提一起推出后件S即可。
反证法:
要证明H1,H2,…,Hn=>C,只要证明 {H1,H2,…,Hn , ﹁C} 是不相容的即可
解释:要证明H1,H2,…,Hn=>C,只要证明 H1∧H2∧…∧H3=>F 即可
谓词逻辑
基本概念
在研究命题逻辑中,原子命题是命题演算中最基本的单位,不再对原子命题进行分解,这样会产生两大缺点:
(1)不能研究命题内部的结构,成分和内部逻辑的特征;
(2)也不可能表达两个原子命题所具有的共同特征,甚至在命题逻辑中无法处理一些简单又常见的推理过程。
因此:
我们可将原子命题分解成两部分:个体(名词,代词)+ 谓词(动词)。
在命题的研究中,基于谓词分析的逻辑,称为谓词逻辑。谓词逻辑是命题逻辑的扩充和发展。
客观世界中可以独立存在的具体或抽象对象称为个体(客体),表示个体的词称为个体词。若个体词以常量的方式表示特定个体,则称之为个体常量;若个体词以变量的方式泛指不确定的个体,则称之为个体变量。
表示个体(客体)特征、性质或关系的词,称为谓词。
谓词与个体常量一起可以表示一个命题
由一个谓词和一些个体变元组成的表达式,称为简单谓词函数。如果一个函数包含n个个体变元,则称为n元简单谓词函数。
谓词函数不是命题,只有当所有的个体变元都用确定的个体代入时,才表示一个命题
由简单谓词函数和命题连结词组成的表达式,称为复合谓词函数。
对于一个谓词函数,每个个体变元都有其取值范围,该取值范围,称为是该个体变元的个体域(论域)
全称量词
“∀”几种表达式的读法:
∀ x P(x): “对所有的x,x 是…”;
∀ x ¬ P(x) : “对所有x,x 不是…”;
¬∀ x P(x) : “并不是对所有的x,x 是…”;
¬∀ x ¬ P(x) : “并不是所有的x,x 不是…”。
存在量词
“∃”几种表达式的读法:
∃ x P(x): “存在一个 x,使 x 是…”;
∃ x ¬ P(x) : “存在一个 x,使 x 不是…”;
¬ ∃ x P(x) : “不存在一个 x,使 x 是…”;
¬ ∃ x ¬ P(x) : “不存在一个 x,使 x 不是…”。

例题:

约束变元
辖域:紧接在量词后面括号内的谓词公式。
例如 ∀x P(x) ,∃ x (P(x) ∧ Q(x)) 。
若量词后括号内为原子谓词公式,则括号可以省去。
约束变元:在量词的辖域内,且与量词下标相同的变元。
自由变元:当且仅当不受量词的约束。
对于一个公式,如果量词均在全式的开头,它们的作用域延伸到整个公式的末尾,则该公式叫做前束范式

谓词演算的等价式与蕴含式


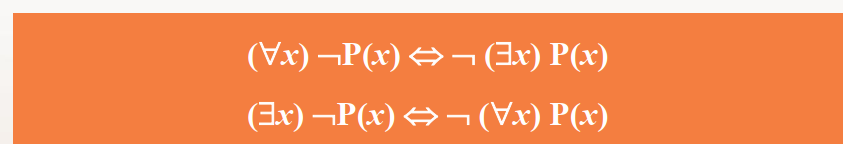
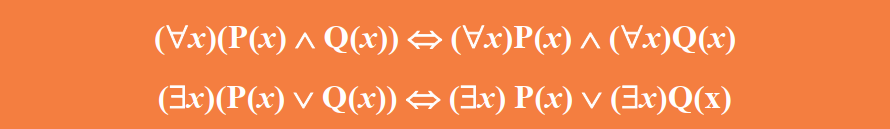


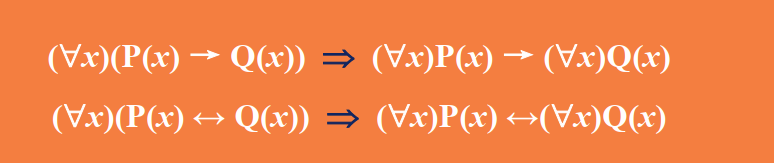

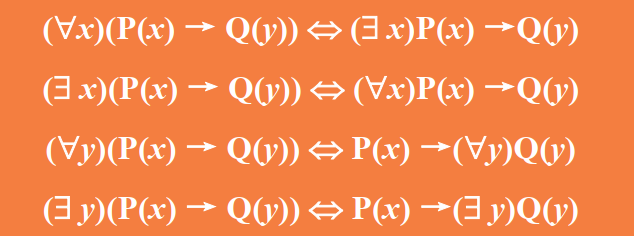
谓词演算的推理推论
命题推理的基本元素 推理规则:P规则、T规则、CP规则
推理方法:真值表法、直接证法、间接证法
推理依据:等价式、蕴含式
在谓词演算中,由于在前提和结论中的谓词公式常带有量词,因而要使用命题演算的等价式和蕴含式需要消去和添加量词。
谓词演算的推理规则:
全称指定(US)、存在指定(ES)、全称推广(UG)、存在推广(EG)。




例题:


集合论
基本概念
集合定义:集合是包含不同对象的一个无序的聚集。集合元素在集合里面叫做A包含a,记作a ∈ A。
集合的描述有:列举法:一一列举几个里面的元素,还有采用集合构造器,叙述法。
集合相等:两个集合当且仅当它们拥有相同的元素。就是说:A与B是集合,则A与B相等的条件是当且仅当(任意X)(X∈A & X∈B),若A与B相等,则A=B

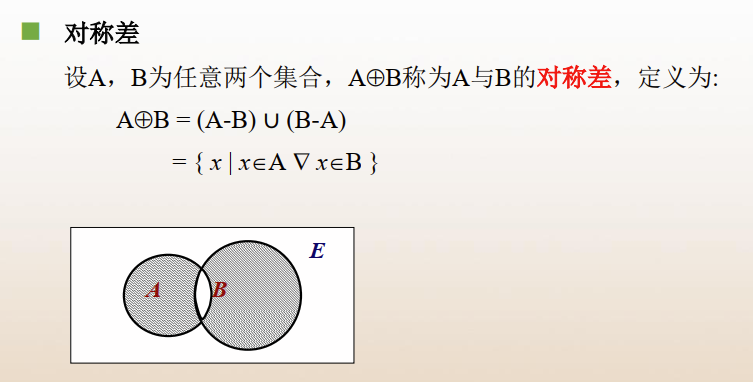
特殊运算


运算性质

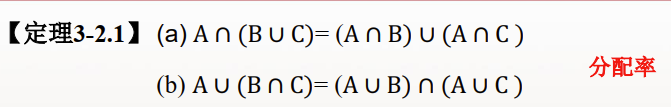
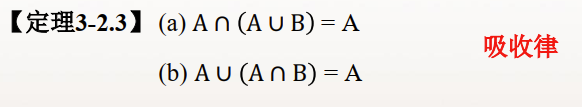

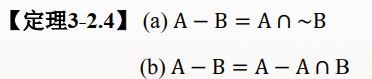
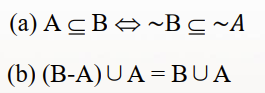


包容排斥原理(容斥原理)



序偶与笛卡尔积
序偶:有序二元组的称呼,可以看作一个有顺序的集合,记作<A,B>
序偶不同于集合的是序偶是有顺序的,<A,B> != <B,A>,相当于键值对。
笛卡尔积:A与B是集合,那么A与B的笛卡尔积相当于A*B,表示<a,b>,其中:a∈A ,b∈B
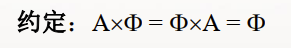
满足分配律:
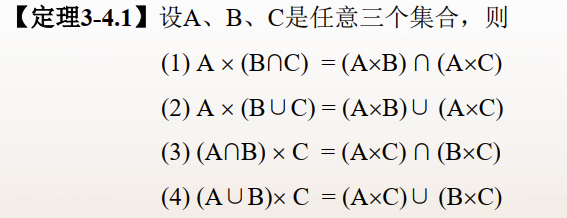
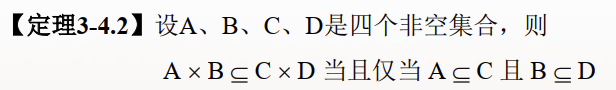
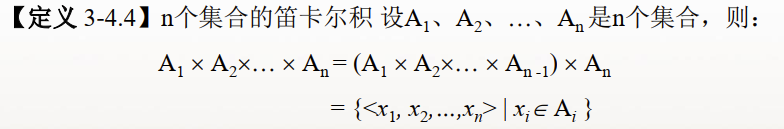
关系
关系的基础概念
集合A与B的关系可以记作 A * B里面的子集属于一个关系,也就是说,一个从A到B的二元关系就是A * B的子集。
我们可以这么记:对于一个二元关系R,R里面的任意一个序偶<x,y>可以记作<x,y>∈R 或者<x,y> !∈ R
要么是xRy 或者 x !R y

前域:在二元关系<x,y> E R里面,由所有x组成的集合叫做前域。
值域:在二元关系<x,y> E R里面,由所有y组成的集合叫做值域。
域:由前域与值域最初 相当于前域与值域的并集。
关系矩阵:我们有两个有限集合:X = {x1,x2,x3,……,xm},Y={y1,y2,y3,……,yn},R是X到Y上的一个二元关系,那么就有相应的关系矩阵:M = [rij]m*n
关系的性质
自反的关系:R是集合X上面的二元关系,如果对于每一个x ∈X,有xRx,就称R是自反的。
反自反关系:我们在自反的基础上面不能出现xRx的情况。
对称关系:对于关系里面x,y ∈ X,每当xRy,就有yRx,就X上面关系R是对称的。
反对称关系:大概地说,集合 X 上的二元关系 R 是反对称的,当且仅当不存在X里的一对相异元素a, b,它们相互 R-关系于彼此
传递关系:对于x, y, z ∈ X,每当xRy, yRz时就有xRz,就称R在X上是传递的。
关系的性质
该有的序偶不能没有
自反性:应该含有所有<x, x>
对称性:如果有<x, y>就应该有<y, x>
传递性:如果有<x, y>和<y, z>就应该有<x, z>
该有的序偶没有就不满足
不该有的序偶不能有
反自反性:不应该含有任何<x, x>
反对称性:如果有<x, y>就不应该有<y, x>
不该有的序偶有了就不满足
从关系矩阵、关系图来判断五个性质:
1、自反的:
关系矩阵的对角线上元素全为1,关系图中每个结点均有自回路。
2、对称的:
关系矩阵是对称矩阵,关系图中若两个结点之间有有向弧,则必成对出现
3、反自反的:
关系矩阵中对角线元素全为0,关系图中每个结点都没有自回路。
4、反对称的:
关系矩阵以对角线对称的元素不能同时为1,(但可为对称阵,同时为0)
关系图中如果两个结点之间有有向弧,则不能成对出现。
5、传递性:
不能明确判断,只能用定义。
特殊关系的性质:
空关系: 反自反性,对称性,反对称性,传递性
全域关系:自反性,对称性,传递性
恒等关系:自反性,对称性,传递性
复合关系和逆关系
复合关系:
定义:
R是X到Y的关系,S是Y到Z的关系,则R和S的复合关系R°S称为R和S的复合关系,表示为: RoS=
{<x,z>|x∈X且z∈Z(y∈Y ,<x, y>∈R且<y,z> ∈S)}
复合关系相当于一个个元素进行传递,看是否满足传递关系。
逆关系:
R是X到Y的二元关系,把R中每一序偶的元素次序颠倒,得到的关系称为R的逆关系,记作R^c:
闭包运算



来自:https://blog.csdn.net/weixin_46503355/article/details/108060144
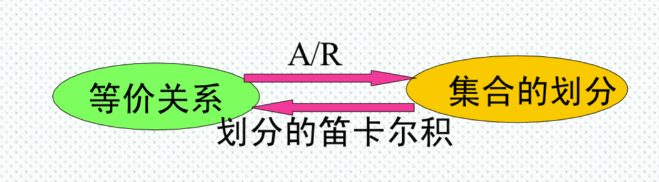
集合的划分
把一个集合A分成若干,叫做划分。

等价关系与等价类
若集合A上的关系R,满足自反性,对称性,传递性,则称R为A上的等价关系。
等价类:

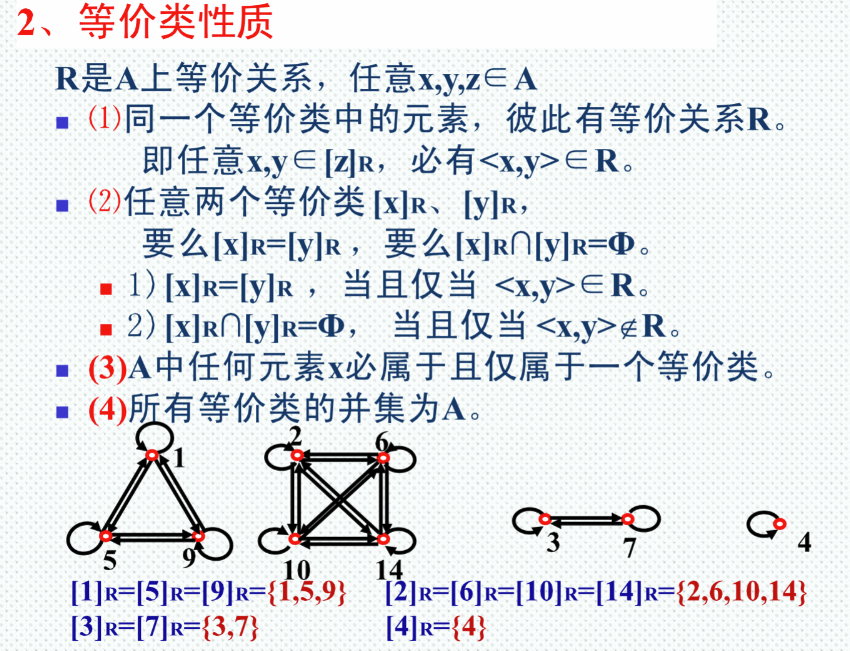 商集:
商集:
R是A上等价关系,由R的所有等价类构成的集合,称为A关于R的商集。记作A/R。
即

等价关系与划分
相容关系
对于A上的关系R,若R是自反的,对称的,则称R是相容关系。

序关系
偏序关系
A上一个关系R,若R满足自反性,反对称性和传递性,则R是A上的一个偏序关系。记作≼
设≼为偏序关系, 如果<x, y>∈≼, 则记作 x≼y, 读作 x小于或等于y
序偶<A,≼ >称偏序集
在偏序集合<A,≼ > 中,设R为非空集合A上的偏序关系, x, y∈A, 如果 x ≺ y且不存在 z ∈ \in ∈A 使得 x ≺ z ≺ y, 则称 y 盖住(覆盖)x.
链与反链
在偏序集合<A,≼ > 中,在A的一个子集中,如果每两个元素都是有关系的,则称该子集为链。
如果子集中每两个元素是无关系的,则称这个子集为反链。
全序关系
在偏序集 <A,≼ >, 若A是一个链,则称<A,≼ >为全序集合(或线序集合)。在这种情况下,二元关系≼称为全序关系或线序关系。
哈斯图
对序关系关系图的一种简化画法
① 由于序关系自反,各结点都有环,省去;
② 由于序关系反对称且传递,所以关系图中任何两个不同的结点直接不会有双向的边或通路,所以省去边的箭头,把向上的方向定为箭头方向
③ 由于序关系传递,所以省去所有推定的边。
设<A,≼>为偏序集, B⊆A, y∈B.
若 ∀x(x∈B→y≼x) 成立, 则称 y 为 B 的最小元.(唯一)
若 ∀x(x∈B→x≼y) 成立, 则称 y 为 B 的最大元.(唯一)
若 ¬∃x (x∈B∧x ≺ y) 成立, 则称 y 为B的极小元.(局部最大)
若 ¬∃x (x∈B∧y ≺ x) 成立, 则称 y 为B的极大元.(局部最大)
设<A, ≼>为偏序集, B⊆A, y∈A.
若 ∀x(x∈B→x≼y) 成立, 则称 y 为B的上界.
若 ∀x(x∈B→y≼x) 成立, 则称 y 为B的下界.
令C={y | y为B的上界}, 则称C的最小元为B的最小上界 或 上确界.
令D={y | y为B的下界}, 则称D的最大元为B的最大下界 或 下确界.
函数
基本概念
函数
设 F 为二元关系, 若任意x∈domF 都存在唯一的y∈ranF 使 xFy 成立, 则称 F 为函数
对于函数F, 如果有 xFy, 则记作 y=F(x), 并称 y 为F 在 x 的值.
f的前域就是函数f(x)的定义域,记作domf = X;
f 的值域 ranf ⊆ Y
集合Y称作 f 的共域.
满射:
若 ranf = Y,则称映射为满射(上映射)
单射(入射):
不同x对应不同的y
双射:
若映射 f 既是满射,又是入射,则称这个映射是双射。
复合函数、特征函数与基数
设F, G是函数, 则F○G也是函数, 且满足
(1) dom(F○G)={x|x∈domF∧F(x)∈domG}
(2) 任意x∈dom(F○G)有F○G(x)=F(G(x))
反函数
设 f:A→B,且f为双射,则
f-1 :B→A,且f-1也为双射.
若 f: A→B 为双射,则 f-1: B→A 称为 f 的反函数 两个函数的复合是一个函数
特征函数
特征函数:
χA:E→{0,1}, χA(x)=1⟺x∈A
当 Φ⊂A⊂E时, χA是满射
基数
设A, B是集合, 如果存在着从A到B的双射函数(A到B是单射和满射), 就称A和B是等势的, 记作A≈B. 如果A不与B 等势,
则记作A≉B.
也可定义为:
给出两个集合,两个集合的元素间一一对应,则A,B等势,记作A~B(双射)
N ≈ Z ≈ Q ≈ N×N
任何实数区间都与实数集合R等势
所有与集合A等势的集合所组成的集合,叫做集合A的基数,记作K[A]。
与自然数集合等势的任意集合称为可数的。
我们把有限集和可数集称为至多可数集。
可数集的任何无限子集是可数的
任一无限集,必含可数子集。
任一无限集,必与某一真子集等势。
若集合A到集合B存在一个入射,则A基数不大于B基数即A≤B。
代数系统
代数结构
基本概念
一个集合加上若干个运算就表示一个代数系统,记<A,f1,f2,······>。
对集合A,一个An 到B的映射,成为A上的n元运算。
可以用运算表来分析代数系统。

性质:
封闭性:
x∈A,b∈A,a*b∈A;
满足性质时,运算表中:
运算表中每个元素都属于A。
交换律:
x * y = y * x;
满足性质时,运算表中:
运算表关于主对角线对称。
分配律:
x * (y ^ z) = (x ^ y ) * (x ^ z);
无法从运算表中看出。
吸收律:
x * (y ^ z) = x
x ^ (y * z) = x
无法从运算表中看出。
等幂性:
x * x = x ;
满足性质时,运算表中:
主对角线上每一元素都与它所在行(列)表头元素相同。
零元:
x * ⊙ = ⊙;(右零元)
⊙ * x = ⊙;(左零元)
满足性质时,运算表中:
零元元素所对应的行和列中的元素都与该元素相同。
幺元(单位元):
x * e = x;(右幺元)
e * x = x;(左幺元)
满足性质时,运算表中:
幺元所对应的行或列都与运算表中的行和列一致。
逆元:
x * y =e;(y是x的右逆元)
y * x = e;(y是x的左逆元)
其他定理:
零元不存在逆元
在满足结合律时,一个数的逆元是唯一的。
若a * a = a ,则a为等幂元。
半群、群、子群
广群: 满足封闭性的代数系统
封闭性
半群: 可结合的广群
封闭性、可结合
独异点: 存在幺元的半群
封闭性、可结合、存在幺元、
群: 任意元素存在逆元的独异点。
封闭性、可结合、存在幺元、两个元素间存在逆元
定理及推论
- 独异点在运算表中没有相同的行与列。
- (a-1)-1 = a ;
- (a*b)-1 = b-1 * a-1 ;
- 有限群G中元素个数为有限群的阶数。
整数集合<I,+>是个群。- 设<S,*>是半群、独异点或群,如果S是一个有限群,则必有a∈S,使得a * a = a。(存在等幂元)
- 在群<G,>中,对于任意a,b,c属于G,如果ab = ac 或者ba = c*a ,则有b = c。(消去律)
- 设S是一个非空集合,从集合S到S的一个双射称为S的一个置换。 群的运算表<G,*>中的每一行或是每一列都是G的元素的一个置换。
- 在群<G,*>中,除了幺元e,不可能有其他的等幂元。
- 对于群<G,*>,设存在子集<S, >,那么<G,>中的幺元一定是<S, *>的幺元。
- 对于群<G,*>,设存在子集<S, *>,若S={e},或者S = G,则称<S, *>是<G, *>的平凡子集。
- 对于群<G,>,B是G的非空子集,若B是一个有限集,那么,只要运算 * 在B上封闭,则<B,>必然是 <G, *>的子群。
阿贝尔群、循环群
交换群,又称阿贝尔群,指运算满足交换律的群。
循环群:
设<G, *>为群,若在G中有一个元素a,是的G中的任意元素都由a的幂组成,则称该群为循环群,元素a成为循环群的生成元。
生成元可不唯一。
任一个循环群必是交换群。
若G阶数为n,即 |G| = n,则 an = e ;
其中e为幺元,n是使 an = e 的最小正整数,称n为元素a的阶数。
置换群
暂略。
陪集和拉格朗日定理
设<G, *>是一个群,<H, *>为一子群,a是G中元素:
aH={a * h|h∈H} H关于a的左陪集
Ha={h * a|h∈H} H关于a的右陪集
a称为陪集的代表元素
划分
每个元素非空。不存在空块
所有元素并集为G
任两个元素交集为空
等价关系
关系R满足自反、对称、传递
若<x,y>∈ R,称x等价于y,记作x~y
等价类
有等价关系的元素组成的一个集合,记为[a]R
a称为[a]R的代表元素
商集 A/R
以R的所有等价类作为元素的集合称为A关于R的商集
子群的指数
G对H的陪集的集合的基数,即陪集的数目,记为[G:H ]
若A,B表示集合:
A和B的积:
AB = {a * b | a∈A , b∈B }
A和B的逆:
A-1 = {a-1 | a∈A }
拉格朗日定理:
H为G的子群,则:
R={<a,b>|a∈G,b∈G且a-1 *b∈H}
R是G上的一个等价关系。
对于a∈G,若记[a]R={x|x∈G且<a,x>∈R},则[a]R=aH
如果G是有限群,|G|=n,|H|=m,则m|n。( | :表示整除)
推论:
素数阶群的子群一定是平凡群。(质数阶的群不存在非平凡子群)
设<G,*>是n阶群,则对任意a∈G,有an=e
有限群中,元素的阶能整除群的阶
素数阶群一定是循环群,且每个非幺元均为生成元
设<G, *>是n阶有限群,那么对于任意的a∈G,a的阶必是n的因子且必有an = e,这里e是<G, *>的幺元,如果n为质数,则<G, *>必为循环群。
同态和同构
设<A, *>和<B, ^ >是两个代数系统。
f是A到B的一个映射。
对任意x,y∈A,有:
f(x * y ) = f(x) ∧ f(y)
则称f为由<A, *>到<B, ^ >的一个同态映射。
记为 A ~ B
<f(A), *>为<A,⋆>的一个同态象
若f同时是双射,则称f为同构映射。
同构关系是等价关系
记作A ≌ B
性质:
若<G, *>是半群,则<f(G), *>也是半群。
若<G, *>是独异点,则<f(G), *>也是独异点。
若<G, *>是群,则<f(G), *>也是群。
同态核:
设f为群<G, *>到群<G‘, *>的同态映射,e’为G’的幺元,记
Ker(f) = {x | x∈ G 且 f(x) = e’ }
称Ker(f) 为同态映射f的核,简称同态核。
环与域
设<A, + , *>是一个代数系统, 若满足:
- <A,+>是阿贝尔群(交换群)
- <A, *>是半群
- 运算* 对运算+满足分配律。 则称<A, + ,* >为环。
为了区别环中的两个运算,通常称+运算为环中的加法,·运算为环中的乘法。
零元
加法单位元,记为0(θ)
单位元
乘法单位元,记为1
负元
加法逆元,记为-x
逆元
乘法逆元,记为x-1
例子
<R,+,·> 实数环
<Q,+,·> 有理数环
<I,+,·> 整数环
<Mn(I),+, ·> n阶整数矩阵环
<Nk , +k, ×k> 模k整数环
<Z[i], +, ·>(Z[i]=a+bi,a,b∈Z,i2=-1) 高斯整数环 (复数)
<R[x] ,+, ·> R[x]为实数多项式
设<A, + , *>是一个代数系统, 若满足:
- <A,+>是阿贝尔群(交换群)
- <A, *>是可交换独异点,且无零因子。
- 运算* 对运算+满足分配律。
则称<A, + ,* >为整环。
整环中的无零因子条件等价于乘法消去律。
设<A, + , *>是一个代数系统, 若满足:
- <A,+>是阿贝尔群(交换群)
- <A-{⊙}, *>是阿贝尔群
- 运算* 对运算+满足分配律。
则称<A, + ,* >为域。
性质:
1.域一定是整环。
2.有限整环必是域。
3.任一个环的同态象是一个环
设V1=<A,,∘>和V2=<B,⊛,◎>是两环,其中、∘、⊛和◎都是二元运算。
f 是从A到B的一个映射,使得
对∀a, b∈A有:
f(a*b)=f(a)⊛f(b)
f(a∘b)=f(a)◎f(b)
则称f是环V1到环V2的同态映射
分类
如果f是单射、满射和双射,分别称f是单同态、满同态和同构
同态像及其特性
<f(A),⊛,◎>是<A,*,∘>的同态像。
任何环的同态像是环
格和布尔代数
格的基本概念
设<A, ≤ >是一个偏序集,如果A中任意两个元素都有最小上界和最大下界,则称<A, ≤ >为格。
在格<A, ≤ >中,定义∨和∧两个运算,a∨b表示求a和b的最小上界,a∧b表示求a和b的最大下届,分别称其为并运算和交运算。
全序集是一个格,不是所有偏序集都是格.
性质:
设<A, ≤ >为格是一个格,由<A, ≤ >为格诱导的代数系统为<A,∨,∧>,则<A,∨,∧>具有的性质有:
交换律:
a∨b=b∨a,a∧b=b∧a。
结合律:
a ∨(b∨c)=(a∨b)∨ c,
a ∧(b∧c)=(a∧b)∧ c。
吸收律:
a ∨(a∧b)= a,
a ∧(a∨b)= a。
幂定律:
a∨a = a
a∧a = a
定理:
设<A,∨,∧>为一个代数系统,其中∨和∧都是二元运算且满足交换性、结合性、吸收性,则A上存在偏序关系≤,使得<A,≤>是一个格。
(满足吸收律可推出它们一定满足幂等律。)
∨和∧不一定满足分配律,但是一定有分配不等式:
a∨(b∧c)≤(a∨b)∧(a∨c)
(a∧b)∨(a∧c)≤a∧(b∨c)
格的对偶原则:
可以参考之前对对偶规则的定义,对偶后用≥代替≤。
特殊的格
设<A, ≤ >为格是一个格,由<A, ≤ >为格诱导的代数系统为<A,∨,∧>
分配格
若代数系统满足分配律,则为分配格,
链一定是分配格
有界格
格有全上界和全下界。
有补格
每个元素都有补元
补元:
在有界格<A, ≤ >中,对于一个元素a,如果有b∈A,使得a∨b = 1,a∧b = 0,(1是格的上确界,0是格的下确界)
则b是a的补元
一个元素可以存在多个补元,也可以没有补元。
布尔格
有补分配格
布尔代数
一个有补分配格称为布尔格,由布尔格诱导的代数系统<A,∨,∧>称为布尔代数。
具有有限个元素的布尔代数叫做有限布尔代数
设<A, ≤ >是一个具有全下界0的有限格,则对于任何一个非零元素b,至少存在一个原子a,使得a小于等于b。
若a1,a2 ······an是A中满足ai≤b的所有原子,则:
b = (a1)∨(a2)∨ ······ ∨(a n)
图论
基本概念和性质
定义:
一个图是一个三元组<V(G) , E(G) , ∮ >
其中V(G)是一个非空的结点集合,
E(G)是边集合
∮是E到结点序偶的函数
一个结点的度数,用dut(V)表示
仅由孤立结点组成的图称为零点,仅由一个孤立结点构成的图称为平凡图。
定理:
- 每个图中,结点度数的总和等于边数的两倍
∑v∈Vdeg(V) = 2 | E | - 在任何图中,度数为奇数的结点必定是偶数个,
- 含有平行边的图称为多重图
- 不含由平行边和自环的图称为简单图。
由n个结点的无向完全图记作Kn
n个结点的无向完全图Kn的边数为 n/2 * (n-1)
在有向图中,从顶点v0到顶点vn的一条路径是图中的边的序列,其中每一条边的终点是下一条边的起点。
路径与回路
—条路径中,如果同一条边不出现两次,则称此路径是简单路径。
—条路径中,如果同一顶点不出现两次,则称此路径是基本路径(或叫链)。
如果路径的始点vo和终点vn相重合,即vo=vn ,则此路径称为回路。
没有相同边的回路称为简单回路,通过各顶点不超过一次的回路称为基本回路。
路径P中所含边的条数称为路径P的长度。
在无向图G中,若结点u和结点v之间存在一条路,则称u和v是连通的。
结点之间的连通性是结点集上的等价关系,因此对应这个等价关系,我们可以对这个图G做出一个划分,把V分成非空子集V1,V2,V3,······Vm,使得两个结点vk和vj是连通的当且仅当它们同属一个Vi。我们把子图G(V1),G(V2),······G(Vm)称作G的连通分支,把G的连通分支数目记作W(G)
若图G只有一个连通分支,则G是连通图
(如果图中任意一对顶点都是连通的,则称此图是连通图,否则称G是非连通图。)
子图
如果V(H)⊆V(G)且E(H)⊆E(G),则称H是G的子图,记作H⊆G。
生成子图
若H是G的子图且V(H)=V(G),则称H是G的生成子图
最大度和最小度
Δ(G)为G的最大度
δ(G)为G的最小度
割点
设无向图G=<V,E>为连通图,若有点集V1 是V的子集,使得G中删除了V1的所有结点以后,所得的图不是连通图,二删除除了V1的任何真子集后,所得到的图仍是连通图,则称V1为点割集,
若一个点构成点割集,则称这个点为割点。
连通度
k(G) = min{| V1 | | V1 是G的点割集}
作为图G的点连通度(连通度)。
连通度数值上等于点割集元素个数,
表示为了产生一个不连通图需要删去的点的最少数目。
完全图中 Kp 中,
k(Kp) = p-1
且删去p-1个结点后会产生一个平凡图。
与点割集定义类似,我们定义边割集和割边(也称桥)
设无向图G=<V,E>为连通图,若边集E1 是E的子集,使得G中删除了E1的所有边以后,所得的图不是连通图,二删除除了E1的任何真子集后,所得到的图仍是连通图,则称V1为边割集,
若一条边构成边割集,则称这个边为割边(或桥)。
同样与点连通度相似,我们定义边连通度:
λ(G) = min{| E1 | | E1 是G的边割集}
边连通度数值上等于边割集元素个数,
表示为了产生一个不连通图需要删去的边的最少数目。
对平凡图可以定义λ(G) = 0,此外一个不连通图也有λ(G) = 0。
对于任何一个图,都有:
k(G) < λ(G) < δ(G)
一个连通无向图G中,结点v是割点的充要条件是:
存在两个结点u和w,使得u和w的每一条路都通过v。
弱连通性和强连通性:
一个有向图D=(V,E),将有向图的所有的有向边替换为无向边,所得到的图称为原图的基图.
如果一个有向图的基图是连通图,则有向图D是弱连通的,否则称D为非连通的.
若D中任意两点u,v都有从u可达v,或从v可达u,则称D是单向连通的;
若D中每点u均可达其他任一点v,则称D是强连通的。
一个有向图是强连通的,当且仅当G中有一个回路,它至少包含每个结点一次。
在简单有向图中,具有强连通性的最大图,称为强分图。
具有单侧连通性的最大子图,称为单侧分图。
具有弱连通性的最大子图,称为弱分图。
图的矩阵表示
邻接矩阵
当vi ,adj vj 时,a i*j = 1
当vi nadj vj 时或 i==j 时,a i*j = 0
adj表示联结,nadj表示不联结
对于无向图,邻接矩阵是对称的。
定理:
设A(G)是图G的邻接矩阵,则(A(G))l中的i行,j列元素ali*j 等于G中联结vi和vj的长度为l的路的数目
可达性矩阵
当vi 至少存在一条路到达 vj 时,a i*j = 1
当vi 不存在一条路到达 vj 时或 i==j 时,a i*j = 0
完全关联矩阵和关联矩阵
关联矩阵M(G)是由 G的结点 和G的边集构成的
当vi 关联 ej 时,a i*j = 1
当vi 不关联 ej 时,a i*j = 0
从关联矩阵中可以得到:
- 图中每一边关联两个结点,故M(G)的每一列只有两个1.
- 每一行元素的和数是对应结点的度数。
- 一行中元素全为0,其对应的结点为孤立节点。
- 两个平行边其对应的两列相同。
- 同一个图当结点或边的编序不同时,其对应的M(G)仅有行序和列序的不同。
完全关联矩阵
关联矩阵M(G)是由 G的结点 和G的边集构成的
当vi 是 ej起点 时,a i*j = 1
当vi 是 ej终点 时,a i*j = -1
当vi 不关联 ej 时,a i*j = 0
如果一个连通图G有 r 个结点,则其完全关联矩阵M(G)的秩为r-1 ,即 rank M(G) = r-1。
特殊的图
欧拉图
可见 哥尼斯堡七桥问题
给定无孤立节点图G,若存在一条路,经过图中每边一次且仅一次,该条路称为欧拉路。
若存在一条回路,经过图中每条边一次且仅一次,则称为回路为欧拉回路。
具有欧拉回路的图称作欧拉路。
无向图G具有一条欧拉路,当且仅当G是连通的,且由零个或两个奇数度结点。
对于有向图:
给定有向图G,通过图中每边一次且仅一次的一条单向路(回路),称作单向欧拉路(回路)。
有向图G具有一条单向欧拉回路,当且仅当是连通的,且每个结点入度等于出度。
一个有向图G具有单向欧拉路,当且仅当它是连通的,而且除两个结点外,每个结点的入度等于出度,但这两个结点中,一个结点的入度比出度大1,另一个结点的入度比出度小1。
汉密尔顿图
给定图G,若存在一条路经过图中的每个结点恰好一次,这条路称作汉密尔顿路。
若存在一条回路,经过图中的每个结点恰好一次,这条回路称作汉密尔顿回路。
具有汉密尔顿回路的图称作汉密尔顿图。
若图G=<V,E>具有汉密尔顿回路,则对于结点集v的每个非空子集S均有 W(G-S)≤|S| 成立。
其中W(G-S)是G-S中连通分支数。
汉密尔顿图的判定
虽然汉密尔顿回路问题与欧拉回路问题在形式上极为相似,但对图G是否存在汉密尔顿回路还无充要的判别准则。下面我们给出一个无向图具有汉密尔顿路的充分条件。
- 若G中每一对结点度数之和大于等于n-1,则G中存在一条汉密尔顿路。
- 若G中每一对结点度数之和大于等于n,则G中催在一条汉密尔顿回路。
闭包
给定G={V,E},有n个结点,若将G中度数之和至少为n的非邻接结点点连接起来得到G‘,重复这一步骤,则得到了G的闭包,记作C(G)
平面图
平面图的定义
在一个平面画出一个图,如果图的每条边都互不相交,则称这个图为平面图。
边
连通平面图G,由图中的边所包围的区域,在区域内既无节点,也无边,这样的区域叫做面。
一个平面图,面的次数之和等于其边数的2倍
欧拉公式
设一个连通的平面图,v个结点,e个边和r个面,则满足:
v-e+r = 2
性质及定理
-
设G是连通简单平面图: 则满足:
e ≤ 3v - 6 -
给定两个图G1,G2,如果它们是同构的,或者通过反复插入或出去度数为2的结点后,使得G1和G2同构,则称两图在2度结点内同构。
-
库拉图斯基定理:
一个图是平面图,当且仅当它不包含与K3.3或K5 同构的子图
(也就是说,如果 K3,3 或 K5 可以通过不断细分变成这副图,则这幅图是非平面图。)
对偶图与着色
本处图片及叙述摘自:
https://blog.csdn.net/qq_37868325/article/details/83867178
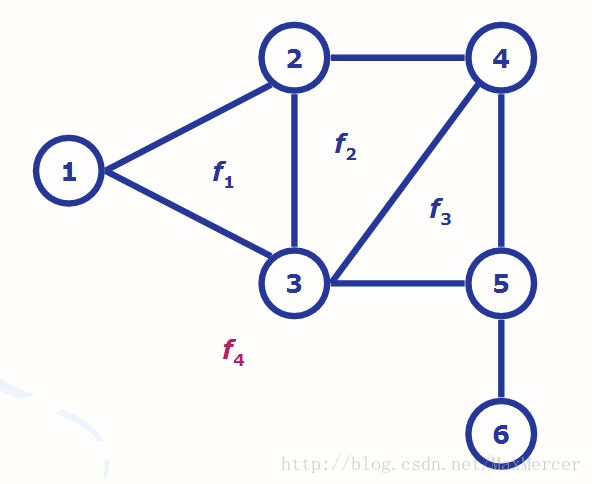
对于每一个平面图, 都有与其相对应的对偶图. 我们假设上面的例图是图G, 与其对应的对偶图G*, 那么对于G来说, G上面的每一个点, 对应的是G里面的每一个面. 比如说下面就是G*.
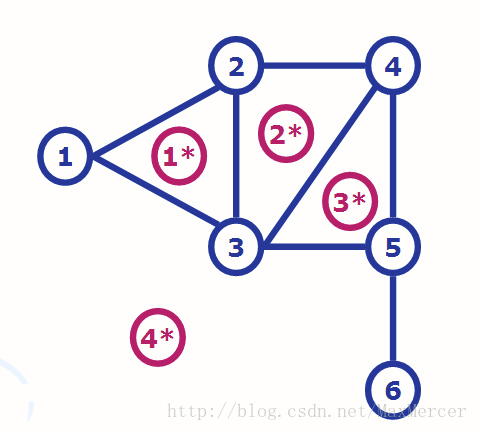
上面的点就是对偶图G里的点.
那么关于对偶图G里的边呢 ? 对于G中本来的每条边e, 他是两个面(比如说面f1和f2)的交边, 那么在对偶图里, 我们对这两个面(f1, f2)所映射在G里的点连线(f1* 连向f2*). 如果f1 == f2(比如说G中5, 6这条边, 边的两侧都是同一个面, 那我们就建一条回边.
图就长这样(回边在5, 6那里).

自对偶图
如果图G的对偶图G‘同构于G,则称图G是自对偶图。
性质及定理:
- 对于n个结点的完全图Kn ,有x(Kn) = n;
- 设G为一个至少具有三个结点的连通平面图,则G中必定有一个节点u,使得
deg(u) ≤ 5 - 任意平面图G最多是5-色的
- 若G是自对偶的,则e = 2v-2 (教材P321课后题)
树与生成树
定义
一个连通且无回路的无向图称为树。
书中度数为1的结点称为树叶。
度数大于1 的结点称为分结点或者内点。
一个无回路的无向图称为森林,它的每个连通分支是树。
定理及性质
- 给定图T,以下关于树的定义是等价的:
- 无回路的连通图
- 无回路且e = v-1,其中e为边数,v为结点数。
- 连通且e = v-1
- 无回路,但增加一条新边,得到一个且仅有一个回路
- 连通,但山区任一条边后不连通
- 每一对结点之间有一条且仅有一条路
- 任一棵树中至少有两片树叶
- 若图G的生成子图是一棵树,则称该树为G的生成树。
设G有一条生成树T,则T的边称作树枝
图G的不在生成树中的边称作弦
所有弦的集合称作生成树T的补
- 连通图至少有一棵生成树
- 一条回路和任何一棵生成树的补至少有一条公共边
- 一个边割集和任何生成树的补至少有一条公共边。
- 在图G的所有生成树中,树权最小的那棵生成树,称作最小生成树。
(求最小生成树的两种算法可见 数据结构笔记中的算法:数据结构笔记)
根树
定义
-
如果一个有向图在不考虑边的方向是是一棵树,那么,这个有向图称为有向树。
-
一棵有向树,如果恰有一个结点的入度为0 ,其余所有结点的入度都为1,则称为根树。
入度为0的结点称为根,出度为0的结点称为叶,出度不为0的结点叫做分枝点或者内点。 -
根树包含一个或多个结点,这些节点中摸一个称为根,其他所有结点都被分成有限个子根树。
-
在根树中,若每一个结点的出度小于或等于m,则称这个树为m叉树。
-
如果每一个结点的出度恰好等于m或0,则称这棵树为完全m叉树,若其所有树叶层次相同,成为正则m叉树。当m=2时,称为二叉树。
-
在根树中,一个结点的通路长度就是从树根到此结点的通路中的边数。我们把分枝点的通路长度称为内部通路长度。树叶的通路长度叫做外部通路长度。
性质及定理
- 设有完全m叉树,其树叶数为t,分枝点数为i,则:
(m-1) i = t-1
- 若完全二叉树中有n个分枝点,且内部通路长度的总和为 I ,外部通路长度的总和为 E ,则:
E = I +2n
- 在带权二叉树中,若带权为wi的树叶,其通路长度为L(wi),,我们把w(T) = ∑i=1t wiL(wi) 称为该带权二叉树的权。
在所有带权的w1,w2,······wi的二叉树中,w(T)最小的那棵树称为最优树 - 设T为带权w1≤ w2,≤···≤wi的最优树,则
- 带权w1,w2的树叶vw1,vw2是兄弟。
- 以树叶vw1,vw2为儿子的分枝点,其通路长度最长。
- 设T为带权w1≤ w2,≤···≤wi的最优树,若将以带权w1和w2的树叶为儿子的分枝点改为带权w1+w2的树叶,得到一棵新树T‘,则T’也是最优树。
前缀码问题
(哈夫曼编码,可见数据结构笔记哈夫曼编码部分数据结构笔记)

