
- 1[深度学习]yolov8+pyqt5搭建精美界面GUI设计源码实现四_深度学习+pyqt+界面设计
- 2Python四川成都二手房源爬虫数据可视化分析大屏全屏系统 开题报告
- 3一文教你如何将Eclipse项目导入到IDEA运行_eclipse项目导入idea
- 4什么是Seq2Seq模型_seq2seq模型和chatglm
- 5solr7定时任务同步数据库_solr-dataimportscheduler.jar solr7.x
- 6人工智能:分类算法——朴素贝叶斯、决策树的简单理解与代码实现,SVM、人工神经网络的简单理解_为了完成本关任务,你需要掌握条件概率。 条件概率 朴素贝叶斯分类算法是基于贝叶
- 7华为ICT七力助推文化产业新质生产力发展
- 8ai写作论文免费网站推荐(ai论文生成器免费)
- 9Java使用opencv实现人脸识别、人脸比对_java人脸识别
- 10tritonserver学习之一:triton使用流程
Transformer预训练模型已经变革NLP领域,一文概览当前现状
赞
踩
来源:机器之心
机器之心编辑部
Transformer 为自然语言处理领域带来的变革已无需多言。近日,印度国立理工学院、生物医学人工智能创业公司 Nference.ai 的研究者全面调查了 NLP 领域中基于 Transformer 的预训练模型,并将调查结果汇集成了一篇综述论文。本文将按大致脉络翻译介绍这篇论文,并重点关注其中的讨论部分,因为研究者在其中指出了该领域新的研究机会。尤其需要说明:研究者将该论文命名为「 AMMUS 」,即 AMMU Smiles,这是为了纪念他们的朋友 K.S.Kalyan。
在如今的 NLP 领域,几乎每项任务中都能看见「基于 Transformer 的预训练语言模型(T-PTLM)」成功的身影。这些模型的起点是 GPT 和 BERT。而这些模型的技术基础包括 Transformer、自监督学习和迁移学习。T-PTLM 可使用自监督学习从大规模文本数据学习普适性的语言表征,然后将学到的知识迁移到下游任务。这些模型能为下游任务提供优质的背景知识,从而可避免从头开始训练下游任务。
这篇详尽调查 T-PTLM 的综述论文首先将简要介绍自监督学习。接下来将解释多个核心概念,包括预训练、预训练方法、预训练任务、嵌入和下游任务适应方法。接下来,文章将为 T-PTLM 给出一种新的分类方法,然后简要介绍多种不同的基准,包括内部基准和外部基准。研究者还归纳总结了一些适用于 T-PTLM 的软件库。最后讨论了一些可能有助于进一步改进这些模型的未来研究方向。

论文地址:https://arxiv.org/pdf/2108.05542.pdf
研究者相信,这篇全面详尽的综述论文能作为一份很好的参考资料,帮助读者了解 T-PTLM 的相关核心概念和近期研究进展。
引言
基于 Transformer 的预训练语言模型(T-PTLM)具备从大规模无标注文本数据学习通用语言表征并将所学知识迁移到下游任务的能力,因此已经在 NLP 领域取得了巨大的成功,这类模型包括 GPT-1、BERT、XLNet、RoBERTa、ELECTRA、T5、ALBERT、BART 和 PEGAUSUS。在更早期,NLP 系统大都采用了基于规则的方法,之后取而代之的是机器学习模型。机器学习模型需要特征工程,而特征工程又需要领域专业知识并且需要较长的时间。
随着 GPU 等更好的计算机硬件以及 Word2Vec 和 Glove 等词嵌入方法的出现,CNN 和 RNN 等深度学习模型在构建 NLP 系统方面得到了更广泛的应用。这些深度学习模型的主要缺点是除了词嵌入之外,需要从头开始训练模型。从头开始训练这类模型需要大量有标注实例,而生成这些实例的成本很高。但是,我们希望仅使用少量有标注实例来获得表现良好的模型。
迁移学习让我们可以将在源任务上学习到的知识很好地复用到目标任务上。在这其中,目标任务应该与源任务相似。基于迁移学习的思想,计算机视觉领域的研究者已在使用 ImageNet 等大规模有标注数据集来训练大型 CNN 模型。这些模型学习到的图像表征对所有任务来说都是普适的。然后,这些大型预训练 CNN 模型可以适应下游任务,具体做法是添加少数特定于任务的层,然后在目标数据集上进行微调。由于预训练 CNN 模型能为下游模型提供很好的背景知识,因此它们在许多计算机视觉任务上取得了巨大的成功。
CNN 和 RNN 等深度学习模型难以建模长期上下文以及学习具有局部性偏差(locality bias)的词表征。此外,由于 RNN 按顺序处理输入(逐词处理),因此只能有限度地使用并行计算硬件。为了克服现有深度学习模型的这些缺点,Vaswani et al. 提出了完全基于自注意力的深度学习模型:Transformer。相比于 RNN,自注意力支持更高度的并行化,并且还能轻松地建模长期上下文,因为输入序列中的每个 token 都会关注其它所有 token。
Transformer 包含一些堆叠的编码器和解码器层。在堆叠编码器和解码器层的帮助下,Transformer 可以学习到复杂的语言信息。在 NLP 领域,生成大量有标注数据的成本非常高,也非常耗时。但是,大量无标注文本数据却很容易获得。在计算机视觉社区使用基于 CNN 的预训练模型所取得的成功的感召下,NLP 研究社区将 Transformer 和自监督学习的能力组合到一起,开发出了 T-PTLM。自监督学习让 Transformer 可以使用由一个或多个预训练任务提供的伪监督进行学习。
GPT 和 BERT 是最早的 T-PTLM,它们分别是基于 Transformer 解码器和编码器层开发的。之后,又诞生了 XLNet、RoBERTa、ELECTRA、ALBERT、T5、BART 和 PEGAUSUS 等模型。其中,XLNet、RoBERTa、ELECTRA 和 ALBERT 是基于 BERT 的改进模型;T5、BART 和 PEGAUSUS 是基于编码器 - 解码器的模型。
Kaplan et al. 表明只需增加 T-PTLM 模型的规模就能带来性能的提升。这一发现推动了大规模 T-PTLM 的发展并催生了 GPT-3 (175B)、PANGU (200B)、GShard (600B) 等包含上千亿参数的模型,而 Switch-Transformers (1.6T) 的参数量更是达到了万亿级。
T-PTLM 在通用英语领域取得成功之后,又开始进军其它领域,包括金融、法律、新闻、编程、对话、网络、学术和生物医学。T-PTLM 还支持迁移学习,即通过在目标数据集上进行微调和即时调整,可让这些模型适用于下游任务。本文将全面回顾与 T-PTLM 有关的近期研究成果。这篇综述论文的看点总结如下:
第 2 节将简单介绍自监督学习,这是 T-PTLM 的核心技术。
第 3 节将介绍与 T-PTLM 相关的一些核心概念,包括预训练、预训练方法、预训练任务、嵌入和下游适应方法。
第 4 节将给出一种针对 T-PTLM 的新型分类法。这种分类法考虑了四大方面,即预训练语料库、架构、自监督学习类型和扩展方法。
第 5 节将给出一种针对不同下游适应方法的新型分类法并将详细解释每个类别。
第 6 节将简要介绍多种用于评估 T-PTLM 进展的基准,包括内部基准和外部基准。
第 7 节将给出一些适用于 T-PTLM 的软件库,从 Huggingface Transformers 到 Transformer-interpret。
第 8 节将简单讨论一些可能有助于进一步改进这些模型的未来研究方向。
自监督学习(SSL)
监督学习的缺点总结如下:
严重依赖人类标注的实例,而获取这些实例耗时费力。
缺乏泛化能力,容易出现虚假相关的问题。
医疗和法律等许多领域缺乏有标注数据,这会限制 AI 模型在这些领域的应用。
难以使用大量免费可用的无标注数据进行学习。
SSL 与监督学习和无监督学习等其它流行学习范式具有一些相似性。SSL 与无监督学习的相似之处是它们都不需要人类标注的实例。但是,它与无监督学习也有不同之处:a) SSL 需要监督,而无监督学习没有监督;b) 无监督学习的目标是识别隐藏模式,而 SSL 的目标是学习有意义的表征。SSL 与监督学习的相似之处是学习范式时都需要监督。但是,它与监督学习也有不同之处:a) SSL 会自动生成标签,而无需任何人类干预;b) 监督学习的目标是提供特定于任务的知识,而 SSL 的目标是向模型提供通用知识。
SSL 的目标总结如下:
学习通用语言表征,这能为下游模型提供优良的背景。
通过学习大量免费可用的无标注文本数据来获得更好的泛化能力。
自监督学习可大致分为生成式 SSL、对比式 SSL 和对抗式 SSL 三种。
T-PTLM 核心概念
预训练
预训练能带来以下一些优势:
通过利用大量无标注文本,预训练有助于模型学习通用语言表征。
只需增加一两个特定的层,预训练模型可以适应下游任务。因此这能提供很好的初始化,从而避免从头开始训练下游模型(只需训练特定于任务的层)。
让模型只需小型数据集就能获得更好的表现,因此可以降低对大量有标注实例的需求。
深度学习模型由于参数数量大,因此在使用小型数据集训练时,容易过拟合。而预训练可以提供很好的初始化,从而可避免在小型数据集上过拟合,因此可将预训练视为某种形式的正则化。
预训练的步骤
预训练一个模型涉及以下五个步骤:
准备预训练语料库
生成词汇库
设计预训练任务
选择预训练方法
选择预训练动态
预训练语料库

图 1:预训练语料库

图 2:预训练方法,其中 PTS 是从头开始型预训练、CPT 是持续型预训练、SPT 是同时型预训练、TAPT 是任务自适应型预训练、KIPT 是知识继承型预训练
预训练任务
闲聊语言建模(CLM)
掩码语言建模(MLM)
替代 token 检测(RTD)
混洗 token 检测(STD)
随机 token 替换(RTS)
互换语言建模(SLM)
翻译语言建模(TLM)
替代语言建模(ALM)
句子边界目标(SBO)
下一句子预测(NSP)
句子顺序预测(SOP)
序列到序列语言模型(Seq2SeqLM)
去噪自动编码器(DAE)
嵌入

图 8:T-PTLM 中的嵌入
分类法
为了了解以及跟踪各种 T-PTLM 的发展,研究者从四个方面对 T-PTLM 进行了分类,即预训练语料库、模型架构、SSL 类型和扩展方法。如下图 9 所示:
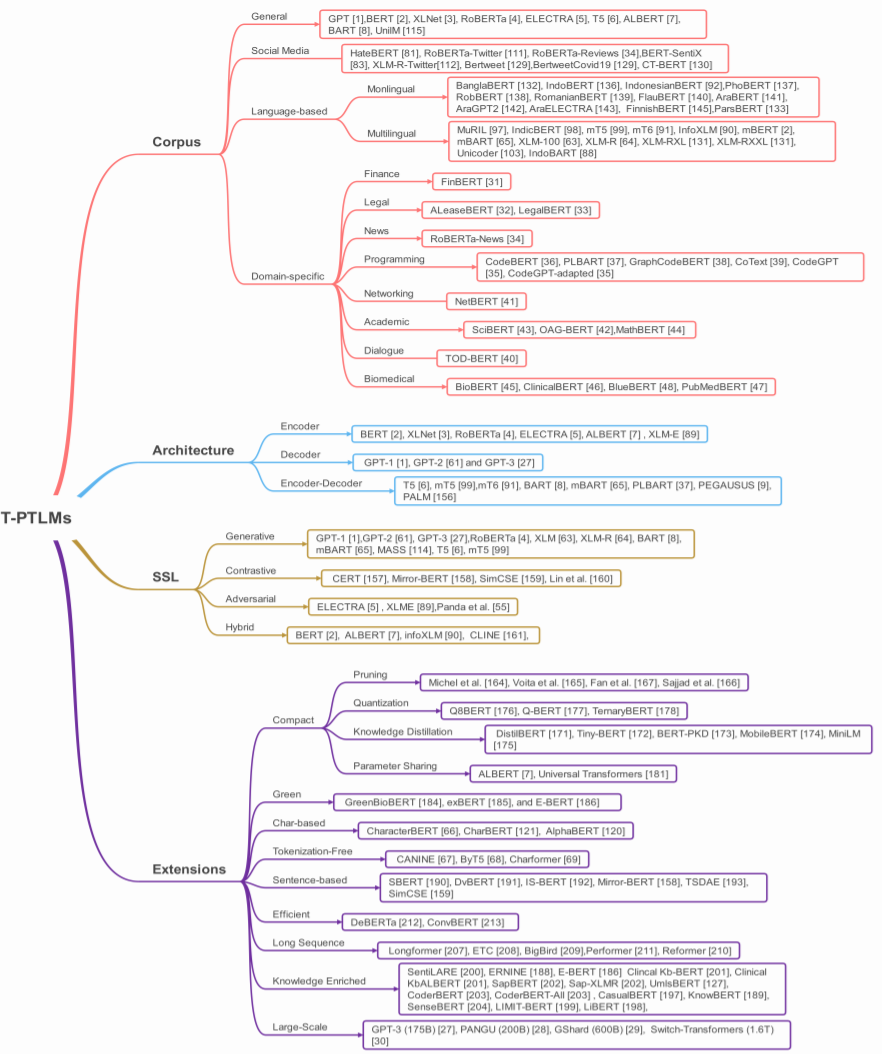
图 9:T-PTLM 的分类法。
下游适应方法
一旦完成语言模型的训练,就可将其用于下游任务了。将预训练后的语言模型用于下游任务的方式有三种:基于特征的方法、微调和基于提示的微调(prompt-based tuning)。
如下图 10 所示,基于特征的方法涉及到根据语言模型生成上下文的词嵌入,然后在针对特定下游任务的模型中将它们用作输入特征。微调涉及到根据下游任务,通过尽量降低针对特定任务的损失来调整模型权重。
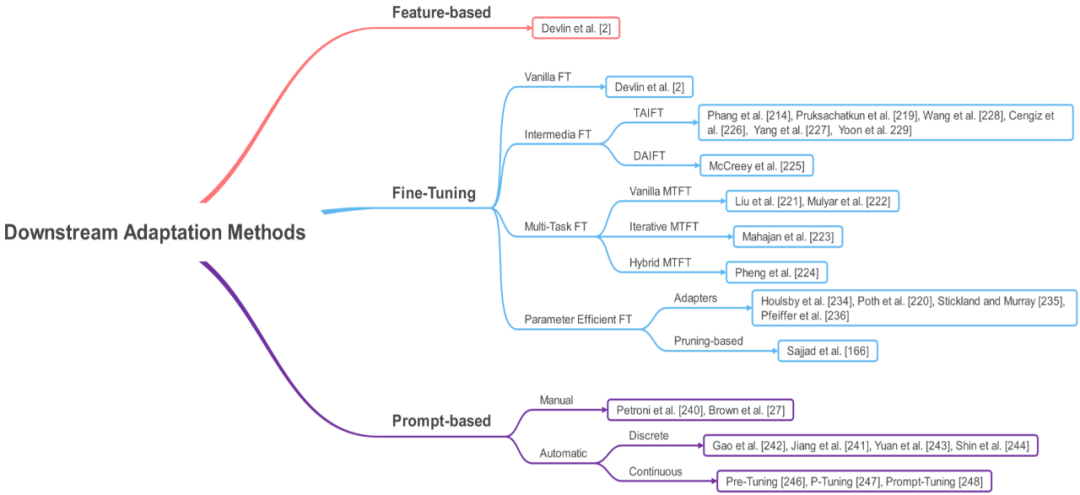
图 10:下游适应方法。
评估
在预训练阶段,T-PTLM 会获取预训练语料库中编码的知识。这里的知识包括句法、语义、事实和常识。对于 T-PTLM 的效果,评估方式有两种,即内在方式和外在方式。见下图 11。
内在评估方式是通过探测 T-PTLM 中编码的知识进行评估,而外在评估方式则是评估 T-PTLM 在真实世界下游任务中的效果如何。内在评估方式可让我们了解 T-PTLM 在预训练阶段获得的知识,这有助于我们设计更好的预训练任务,使得模型可以在预训练阶段学习到更多知识。
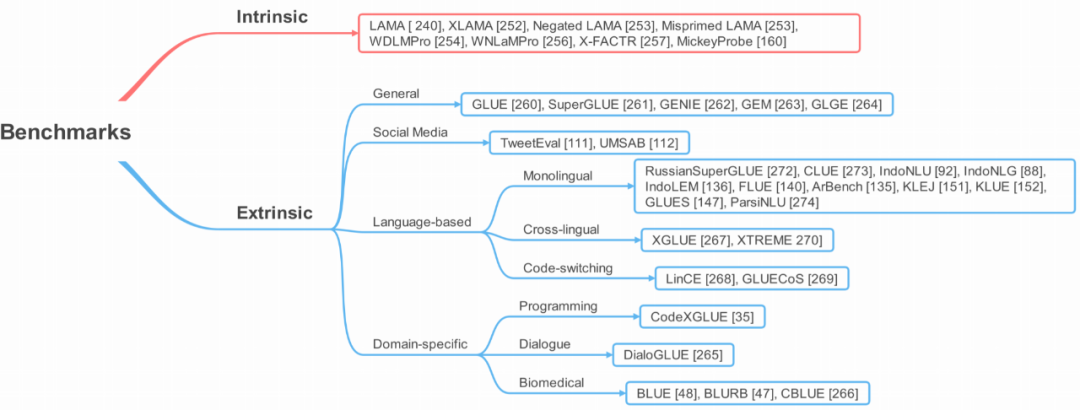
图 11:用于评估 T-PTLM 研究进展的基准。
有用的软件库
研究者还归纳总结了一些适用于 T-PTLM 的常用软件库。其中,Transformers 和 Fairseq 等软件库适用于模型训练和评估。SimpleTransformers、HappyTransformer、AdaptNLP 等则构建于 Transformer 软件库之上,可让用户仅使用少量代码就实现更轻松的训练和评估。FastSeq、DeepSpeed、FastT5、OnnxT5 和 LightSeq 等则可用于提升模型的推理速度。Ecco、BertViz 和 exBERT 都是可视化分析工具,可用于探索 Transformer 模型的层。Transformers-interpret 和 Captum 则能用于解释模型决策。
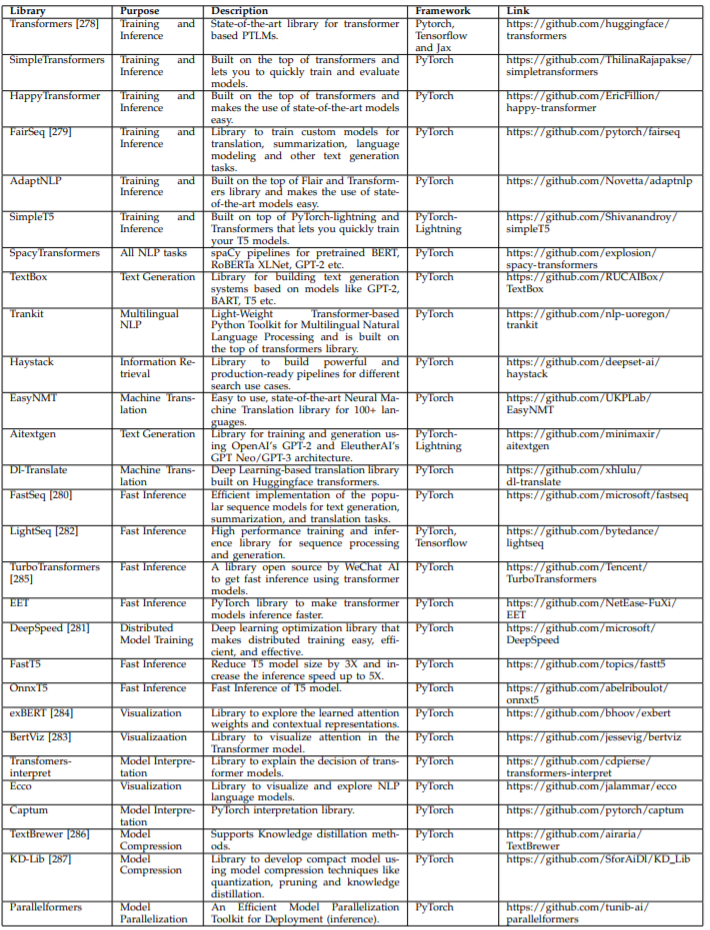
表 11:适用于 T-PTLM 的软件库。
讨论和未来方向
更好的预训练方法
仅使用 SSL 来训练模型(尤其是带有成千上万亿参数的大模型)的成本非常高。知识继承型预训练(KIPT)等全新的预训练方法涉及到 SSL 和知识蒸馏。SSL 让模型可以学习预训练语料库中可用的知识,而知识蒸馏则让模型可以学习已经编码在已有预训练模型中的知识。由于在通过知识蒸馏的预训练阶段,模型可获得额外的知识,因此 a) 模型可以更快速地收敛并由此缩短预训练时间,b) 相比于仅使用 SSL 预训练的模型,在下游任务上的表现会更好。研究社区必须重点关注开发 KIPT 等更好的预训练方法,让模型获得更多知识以及降低预训练时间。
样本高效型预训练任务
如果一个预训练任务能最大化地利用每个训练实例,那么就可以说该预训练任务是样本高效的,即它应该能在训练实例中的所有 token 上获得定义。样本高效型预训练任务能使预训练的计算效率更高。最常用的预训练任务 MLM 的样本效率就不太高,因为其仅涉及到一个 token 子集,即掩码 token,其占总 token 数的 15%。RTD、RTS 和 STD 等预训练任务可被视为是开发样本高效型预训练任务的早期尝试。这三种预训练任务都定义在每个训练实例的所有 token 之上,即它们涉及到识别每个 token 是否被替代、随机替换或混洗。未来应该还将出现使计算效率更高的样本高效型预训练任务。
高效模型
由于模型尺寸较大并且需要大量无标注的文本数据,因此预训练 T-PTLM 的成本也很高。但是,较长的预训练时间对环境并不友好,因为这个过程会释放二氧化碳;而在生物医学等许多领域,也没有大规模的无标注文本数据。近期,在 BERT 模型基础上进行全新改进的 DeBERTa 等模型实现了比 RoBERTa 模型更好的性能,尽管其仅使用了 78 GB 数据进行预训练,这只是预训练 RoBERTa 模型所用的数据量的一半。类似地,ConvBERT 凭借全新的混合注意力模块,仅使用 ELECTRA 模型四分之一的预训练成本就取得了更优的表现。为了降低预训练的数据量和训练成本,人们需要 DeBERTa 和 ConvBERT 这样的高效模型。
更好的位置编码机制
自注意力机制是置换不变型的方法,不存在位置偏差。使用绝对或相对位置嵌入,可以提供位置偏差。此外,绝对位置嵌入可以预先确定或学习到。但是,这两种方法各有优缺点。绝对位置嵌入会有泛化问题,但却很容易实现。不同于绝对位置,相对位置嵌入能稳健地应对序列长度变化,但却难以实现,性能也更差。我们还需要全新的位置编码机制,比如 CAPE,其将绝对和相对位置嵌入的优势组合到了一起。
改进现有的 T-PTLM
BERT 和 RoBERTa 等 T-PTLM 已经在许多 NLP 任务上取得了优良的结果。近期的研究表明,通过基于对抗或对比预训练任务的持续预训练注入句子层级的语义,还可以进一步改进这些模型。举个例子,Panda et al. 表明使用混洗 token 检测目标的持续预训练可提升 RoBERTa 模型在 GLUE 任务上的性能,因为其允许模型学习更连贯的句子表征。类似地,使用对比预训练目标的持续性预训练可以提升 T-PTLM 在 GLUE 任务上的性能以及多语言 T-PTLM 在 Mickey Probe 上的表现。为了将其扩展到其它单语言和特定领域的 T-PTLM,还需要进一步的研究。
超越朴素的微调
为了将预训练模型用于下游任务,微调是最常用的方法。但是,朴素的微调的主要缺点是其会改变预训练模型中的所有层,因此我们需要为每个任务维持另一个副本,这会增加部署成本。为了以一种参数高效的方式将预训练模型用于下游任务,人们提出了 Adapters 和基于剪枝的微调等方法。
举个例子,adapter 是添加到每个 Transformer 层的针对特定任务的小层。而在下游任务适应期间,仅更新 adapter 层的参数,Transformer 层的参数保持不变。此外,Poth et al. 表明 adapter 也可用于中间微调。近期,基于提示的微调(prompt-based tuning)方法在参数效率方面取得了明显更优的表现,并得到了研究社区的关注。举个例子,Prefix-tuning 等基于提示的微调方法仅需要 0.1% 的针对特定任务的参数,而基于 adapter 的微调则需要 3% 的针对特定任务的参数。
基准评测
在最后四层中,人们引入了很多基准来评估通用型和领域特定型预训练模型的进展。除了英语之外,也出现了一些用于评估其它单语言和多语言模型进展的基准。但是,现有的基准不足以覆盖所有场景。举个例子,还没有基准用于评估 a) 紧凑预训练模型的进展,b) 预训练模型的稳健性,c) 针对社交媒体以及学术等专业领域开发的 PTLM。
近日,Explainboard 等排行榜不再只是使用已有基准等单一指标评估进展,也会深挖或分析模型的长项和短板。这类排行榜应该也能扩展到其它领域。此外,FewGLUE、FLEX 和 FewCLUE 等评估少量次学习技术的基准也应当扩展到其它语言和领域。
紧凑模型
T-PTLM 几乎在每种 NLP 任务上都获得了最佳表现。但是,这些模型都很大,需要更大的存储空间。因为这些模型的层数很多,因此输入需要一定时间才能完全通过模型,从而得到预测结果,因此延迟很高。而真实世界应用的资源有限,需要更低的延迟,因此剪枝、量化、知识蒸馏、参数共享和分解等模型压缩方法已经在英语通用领域应用方面得到了探索。研究这些模型压缩方法在其它语言和领域的应用具有很大的前景。
对噪声的稳健性
T-PTLM 容易受到噪声影响,其中包括对抗噪声和自然噪声。其主要原因是使用了子词嵌入。在使用子词嵌入时,一个词会被分解为多个子词 token,因此即使很小的拼写错误也可能改变该词的整体表征,进而阻碍模型学习并影响模型预测。为了提升模型对噪声的稳健性,CharacterBERT 等模型采用了只使用字符嵌入的方法,而 CharBERT 等模型则会将字符嵌入和子词嵌入一起使用。这两种方法都能提升对噪声的稳健性。
近期,研究者们还提出了 CANINE、ByT5 和 Charformer 等无 token 化模型来提升对噪声的稳健性。为了让这些模型能在真实世界中得到应用,尤其是在医学等敏感领域,我们需要提升它们的稳健性。
全新的适应方法
为了将通用模型适应到生物医学等专业领域或将多语言模型适应到特定语言,常用的策略是使用持续性预训练。尽管这种方法通过调整模型以适应特定的领域或语言能得到良好的结果,但如果缺少领域或语言特定的词汇库,下游模型的性能会受到影响。近期有研究者提出了扩展词汇表然后持续预训练的方法。这些方法能克服 OOV 词的问题,但由于会在词汇表中增加新词,因此会增大词汇表的规模。近日,Yao et al. 提出了 Adapt and Distill 方法,即使用词汇表扩展和知识蒸馏来使通用模型适应特定领域。不同于已有的适应方法,该方法不仅能让通用模型适应特定领域,而且还能减小模型的规模。这一注意值得进一步研究并有望产出全新的适应方法。
隐私问题
T-PTLM 已经在许多 NLP 任务上取得了优良的结果。但是,这些模型也存在一些超出预期且并无益处的风险。举个例子,数据泄露是人们担心的一个主要问题,尤其是当这些模型的预训练使用了隐私数据时。由于模型是在大量文本数据上预训练的,因此有可能从中恢复敏感信息,比如可识别出个人身份的信息。因此,需要防止人们公开发布使用隐私数据预训练的模型。
近日,Carlini et al. 研究表明,GPT-2 模型可生成一个人的完整邮政地址,这些地址包含在训练数据中,可使用该人的名字通过提示得到。近期出现在生物医学领域的 KART 框架可通过执行多种攻击来评估数据泄露情况。研究社区需要开发更复杂的攻击来评估数据泄露情况并开发防止预训练模型泄露敏感数据的方法。
降低偏见
基于深度学习的方法正在现实世界中得到越来越广泛的应用,其中包括在生物医学和法律等专业领域。但是,这些模型很容易学习并放大训练数据中已有的偏见。由此造成的结果是:这些模型会产生对特定种族、性别或年龄群体的偏见。我们完全不需要这样的模型。
近期出现了一些重点关注识别和降低偏见的研究。比如,Minot et al. 提出了一种用于减少性别偏见的数据增强方法,Liang et al. 提出的 A-INLP 方法可以动态地识别偏见敏感型 token。在这一领域进行进一步研究有助于降低预训练模型中的偏见并帮助它们做出公平的决定。
降低微调不稳定性
为了让预训练模型适应下游任务,最常用的方法是微调。尽管微调的表现不错,但它并不稳定,即使用不同随机种子来执行微调会令下游表现差距巨大。有人认为,微调不稳定的原因包括灾难性遗忘和数据集规模较小。但是,Mosbach et al. 表明这两个原因都不是微调不稳定的原因,并进一步表明微调不稳定的原因包括:a) 优化困难,导致梯度消失,b) 泛化问题。为了降低微调不稳定,可能的解决方案包括:a) 中间微调,b) 混合(mix-out),c) 在早期 epoch 采用更小的学习率并且增多微调 epoch 的次数,d) 同时使用监督式对比损失和交叉熵损失。让微调更稳定的方法值得进一步研究。

推荐阅读
熬了一晚上,我从零实现了Transformer模型,把代码讲给你听
中大博士分析ICLR 2022投稿趋势:Transformer激增,ViT首进榜单前50,元学习大跌
读者,你好!为了方便大家学习交流,我们建了微信群,你可以加我的微信邀请你进群!微商和广告无关人员勿扰!谢谢合作!



