
- 1人工智能基础知识:计算机视觉、自然语言处理、机器学习、强化学习等技术简介_计算机视觉、自然语言处理、其他
- 2MTCNN RetinaFace YoloFace_loss_kps
- 32022 年 前40道 ReactJS 面试问题和答案_jsx的面试题
- 4基于ZooKeeper的Kafka分布式集群搭建与集群启动停止Shell脚本
- 5读锁和写锁(共享锁和排他锁)介绍 以及相关类 ReentrantReadWriteLock 学习总结,使用场景
- 6uniapp安卓手机无线真机调试教程_uniapp无线真机调试
- 7【AI大模型应用开发】【LangChain系列】7. LangServe:轻松将你的LangChain程序部署成服务
- 8大数据毕业设计hadoop+spark+hive+nlp知识图谱课程推荐系统 慕课在线教育课程数据分析可视化大屏 课程爬虫 文本分类 LSTM情感分析 计算机毕业设计 机器学习 深度学习 人工智能_spark、hadoop课程
- 9基于ISO13209(OTX)实现EOL下线序列_dts odx
- 10BP神经网络算法学习_bp神经网络神经元层数影响
Transformer、Bert、Gpt对比系列,超详细介绍transformer的原理,bert和gpt的区别_bert transformer
赞
踩
一、Transformer架构图
Transformer 是一种用于序列到序列学习的神经网络模型,主要用于自然语言处理任务,如机器翻译、文本摘要等。它在2017年由 Google 提出,采用了注意力机制来对输入序列进行编码和解码。
Transformer 模型由编码器和解码器两部分组成,每个部分都有多个相同的层,每个层都有两个子层。编码器用于将输入序列转换为一组向量表示,解码器则将这些向量解码为输出序列。Transformer 模型的主要特点是使用了自注意力机制,即每个位置的编码器输出向量都可以关注到输入序列的所有位置,而不仅仅是局部区域。
下面是 Transformer 模型的基本结构:

1.Transformer 中的编码器是由多个编码器层(Encoder Layer)组成的,每个编码器层包含两个子层:
(1)多头自注意力子层(Multi-Head Self-Attention Layer):用于将输入序列中每个位置的向量关联起来,产生一组新的向量表示。多头自注意力子层使用了多个注意力机制,每个注意力机制关注输入序列不同的位置。
(2)前馈神经网络子层(Feed-Forward Layer):用于对多头自注意力子层的输出进行非线性变换。
在每个编码器层中,也引入了残差连接和层归一化等技术。残差连接是将输入序列直接添加到子层的输出中,以便信息能够更快地传递。层归一化是对每个子层的输出进行标准化,以使不同层之间的输入更加一致,从而加快模型的收敛速度。
2.Transformer 中的解码器也由多个解码器层(Decoder Layer)组成,每个解码器层包含三个子层:
(1)多头自注意力子层(Multi-Head Self-Attention Layer):与编码器中的自注意力子类似,用于将解码器中已经生成的序列位置进行关联,产生一组新的向量表示。
(2)编码器-解码器注意力子层(Encoder-Decoder Attention Layer):用于将编码器中产生的一组向量表示与解码器中已经生成的序列位置进行关联,产生一组新的向量表示。这一子层的注意力机制与多头注意力类似,但是其关注的是编码器的输出,而不是解码器的输出。
(3)前馈神经网络子层(Feed-Forward Layer):用于对多头自注意力子层和编码器-解码器注意力子层的输出进行非线性变换。
在每个解码器层中,同样也引入了残差连接和层归一化等技术,用于加速模型的收敛。总体而言,Transformer 解码器的主要作用是根据编码器的输出和之前已经生成的部分序列,生成下一个序列位置的预测,并输出到输出序列中。

3.Self-Attention注意力机制

下图很详细,主要依靠生成三个向量:Q(查询)K(被查询)V(向量值)

Attention整体计算流程:每个词的Q会跟每一个K计算得分,Softmax后就得到整个加权结果,此时每个词看的不只是它前面的序列,而是整个输入序列,同一时间计算出所有词的表示结果
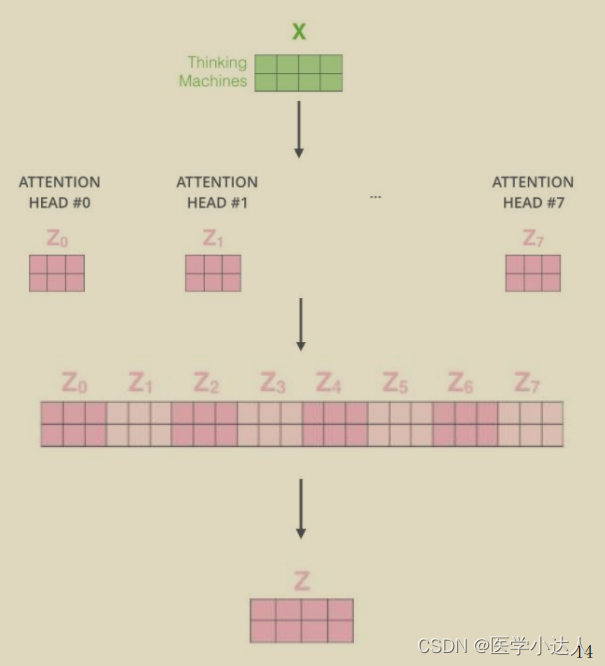

4、残差连接和归一化:
Transformer中的残差连接和归一化机制是为了解决深度神经网络训练过程中的梯度消失和梯度爆炸问题。
残差连接是将输入数据与输出数据相加,从而保留输入数据的信息,并将其传递到下一层。这样做的好处是可以避免梯度消失,因为输入数据中有一部分信息可以直接传递到输出数据中。同时,残差连接可以加速模型的训练过程,因为可以直接在残差连接中更新参数。
归一化机制是通过对每个特征的值进行归一化,使得神经网络在训练过程中更加稳定。在Transformer中,使用的是Layer Normalization,即对每个样本中的每个特征进行归一化。这样做可以使得模型对于不同的输入更加健壮,提高模型的泛化能力。此外,归一化机制还可以加速模型的收敛速度。

5、mask机制:在 Transformer 模型中,为了避免模型在预测当前元素时使用未来的元素,需要引入掩码(mask)机制,掩码通常表示为一个二维矩阵,其中对角线上方的元素都被设置为0,表示这些元素不能被使用。这个矩阵可以通过在模型训练期间进行动态生成来实现。
在 Transformer 模型中,掩码机制主要用于两个方面。
(1)解码器自身掩码
在解码器中,模型需要在每个时间步骤生成一个新的输出元素,但是这个元素只能由已经生成的输出元素来影响,而不能受到未来输出元素的影响。为了达到这个目的,我们需要在解码器输入序列中加入一个掩码,以便在生成当前输出元素时,只考虑已经生成的元素。
(2)编码器-解码器掩码
在解码器中,模型需要根据编码器生成的输入序列来生成输出序列,但是模型不能使用编码器输入序列中未来的元素来影响当前输出元素的预测。为了达到这个目的,需要在编码器输入序列中加入一个掩码,以便在生成当前输出元素时,只考虑输入序列中已经出现的元素。
通过引入掩码机制,Transformer模型可以避免在生成序列时使用未来的元素,确保生成输出序列的正确性。
区别:解码器自身掩码是为了限制解码器在生成每个输出元素时,只能使用之前已经生成的元素,而不能使用后面还未生成的元素。在每个解码器的时间步骤中,模型会生成一个掩码矩阵,该矩阵的维度为 (target_seq_len, target_seq_len),其中对角线上方的元素都被设置为0,表示这些元素不能被使用。这个掩码矩阵会与解码器的注意力机制中的查询矩阵相乘,以便在计算注意力得分时,只考虑已经生成输出元素。
编码器-解码器掩码是为了限制模型在计算解码器的注意力得分时,只考虑输入序列中已经出现的元素,而不考虑未来的元素。具体来说,模型会使用编码器的输出值作为键值对,以便在生成当前输出元素时,只考虑输入序列中已经出现的元素。为了达到这个目的,需要在计算注意力得分前,将编码器-解码器掩码与编码器的输出值相乘,以便将未来的元素掩码掉,只考虑已经出现的元素。

二、BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示学习模型,由Google公司的研究人员在2018年提出,它是基于Transformer Encoder的深度双向模型,可以在各种自然语言处理任务上达到先进的效果。
BERT模型的预训练任务是通过掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)两种方式进行的。其中,MLM任务在输入文本中随机掩盖一些标记(通常是15%左右),并要求模型预测这些标记的正确词汇;NSP任务通过给定两个句子,让模型判断它们是否是连续的语言序列,以此来学习语言的连贯性。
1.BERT的训练包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练,fine-tune阶段,BERT模型首先是被pre-train模型参数初始化,然后所有的参数会用下游的有标注的数据进行训练。

BERT是一个多任务模型,它的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP,如图所示。
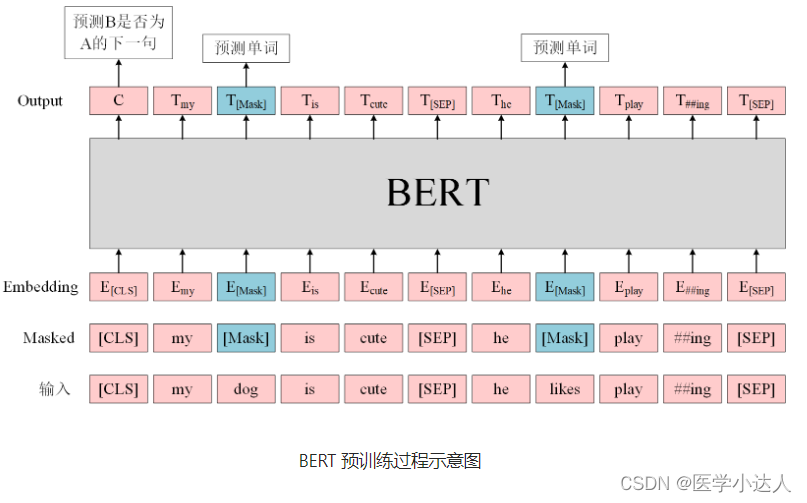
(1)MLM是指在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
80%的时候会直接替换为[Mask],将句子 "my dog is cute" 转换为句子 "my dog is [Mask]"。
10%的时候将其替换为其它任意单词,将单词 "cute" 替换成另一个随机词,例如 "apple"。将句子 "my dog is cute" 转换为句子 "my dog is apple"。
10%的时候会保留原始Token,例如保持句子为 "my dog is cute" 不变。
这么做的原因是如果句子中的某个Token 100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token ’cute‘。至于单词带来的负面影响,因为一个单词被随机替换掉的概率只有15%*10% =1.5%,这个负面影响其实是可以忽略不计的。 另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。
(2)Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中。
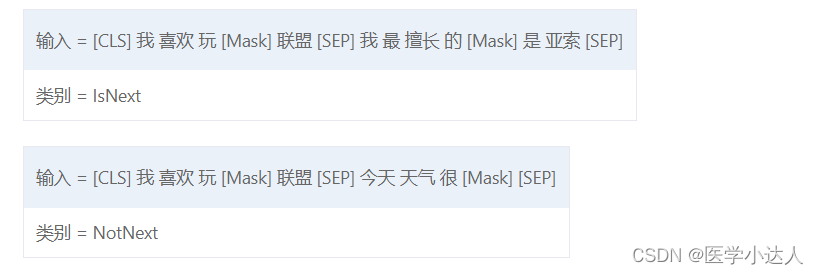
注意:
在此后的研究(论文《Crosslingual language model pretraining》等)中发现,NSP任务可能并不是必要的,消除NSP损失在下游任务的性能上能够与原始BERT持平或略有提高。这可能是由于BERT以单句子为单位输入,模型无法学习到词之间的远程依赖关系。针对这一点,后续的RoBERTa、ALBERT、spanBERT都移去了NSP任务。
BERT预训练模型最多只能输入512个词,这是因为在BERT中,Token,Position,Segment Embeddings 都是通过学习来得到的。在直接使用Google 的BERT预训练模型时,输入最多512个词(还要除掉[CLS]和[SEP]),最多两个句子合成一句。这之外的词和句子会没有对应的embedding。
如果有足够的硬件资源自己重新训练BERT,可以更改 BERT config,设置更大max_position_embeddings 和 type_vocab_size值去满足自己的需求。
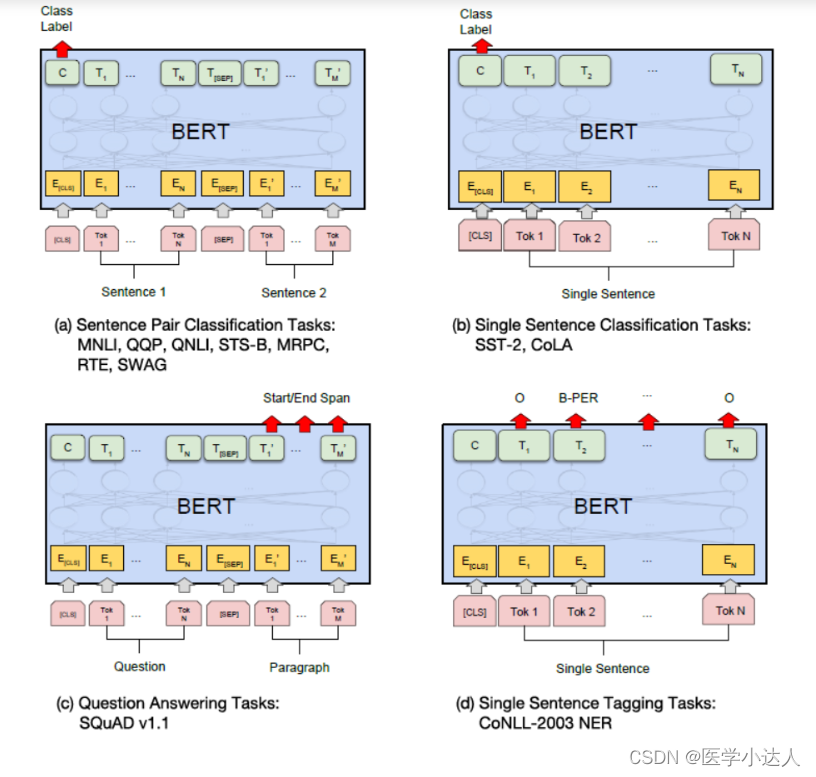
在预训练完成后,BERT模型可以通过微调的方式应用于各种NLP任务,如文本分类、命名实体识别、句法分析等。相比于传统方法,BERT模型能够更好地捕捉上下文信息,从而提高模型的预测准确率。
2.BERT模型的优点在于:
- 可以更好地理解输入文本的上下文信息;
- 可以直接利用预训练模型的参数进行微调,从而减少对领域数据的依赖;
- 引入双向性,使得整个模型可以同时考虑文本的左右两侧信息。
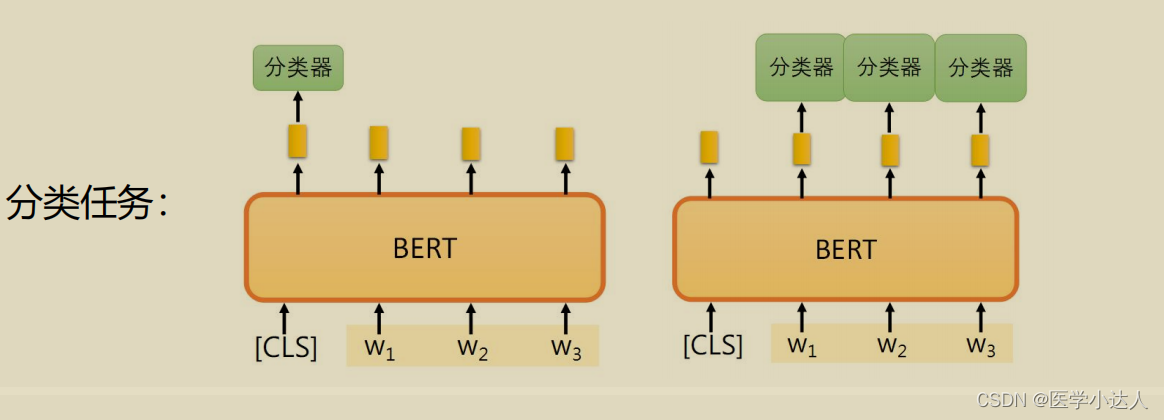
3.BERT 在进行分类任务时,使用 [CLS] 标记来表示整个句子的语义信息。其主要缺点有以下几点:
(1)[CLS] 标记只能表示整个句子的语义信息,而不能区分句子中不同部分的重要性。如果句子中有一些重要的词或短语,它们的信息可能会被 [CLS] 标记所掩盖,从而降低分类的准确性。
(2) BERT 模型是基于注意力机制的,当输入序列非常长时,它需要很多计算资源来对整个序列进行注意力计算。因此,当处理非常长的文本时,BERT 可能会出现内存不足等问题。
(3) BERT 的训练需要大量的数据和计算资源,因此在一些计算能力较弱的设备上可能无法很好地发挥其性能。
3.BERT模型在序列标注任务上的缺点主要包括以下几个方面:
(1) 模型复杂度高:BERT模型是一个十分大的模型,它的训练和推理需要巨大的计算资源,这会导致训练时间和模型大小都非常大。
(2) 需要预处理数据:BERT模型的输入需要预处理,这意味着在使用BERT模型进行序列标注任务时需要对数据进行处理,这会增加额外的工作量。
(3)对长文本处理不够稳定:BERT的输入长度是有限制的,如果输入序列过长,会导致计算资源的消耗过大,同时也会影响模型的性能。
(4)对少见词的处理不够好:BERT模型在处理罕见词汇(如专业术语、生僻词等)时存在一定的困难,这可能会影响模型的性能。
(5)需要大量数据进行训练:BERT模型需要大量的数据才能够训练出良好的效果,这对于某些特定领域的任务可能比较困难。
三、GPT:GPT(Generative Pre-trained Transformer)是由OpenAI团队提出的预训练语言模型,采用了基于Transformer的架构,旨在通过大规模无监督学习来学习文本的表示,从而为各种自然语言处理任务提供预训练模型。
1.GPT 使用 Transformer 的 Decoder 结构,并且每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个 Feed Forward,共叠加使用了 12 层的 Decoder。并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。

GPT 使用句子序列预测下一个单词,因此要采用 Mask Multi-Head Attention 对单词的下文遮挡,防止信息泄露。例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。如果利用A 预测B的时候,需要将 [B, C, D] Mask 起来。
Mask 操作是在 Self-Attention 进行 Softmax 之前进行的,具体做法是将要 Mask 的位置用一个无穷小的数替换 -inf,然后再 Softmax,如下图所示。

GPT在预训练阶段使用了两种任务:语言模型(LM)和下一句预测(NSP)。其中,LM任务要求模型预测给定上下文中缺失的单词,NSP任务要求模型判断给定两个句子是否是连续的。
2.无监督的预训练


3.有监督的Fine-Tuning

与BERT模型不同,GPT模型采用了单向Transformer结构,因此只能利用上文信息,而不能直接利用下文信息。此外,GPT模型还采用了基于位置编码的方法来处理文本的顺序关系。
GPT模型的优点在于:
- 训练过程简单,不需要额外的监督信号;
- 学习到的表示能够应用于各种自然语言处理任务;
- 可以生成流畅、连贯的文本,适用于自然语言生成任务。
4.下游任务
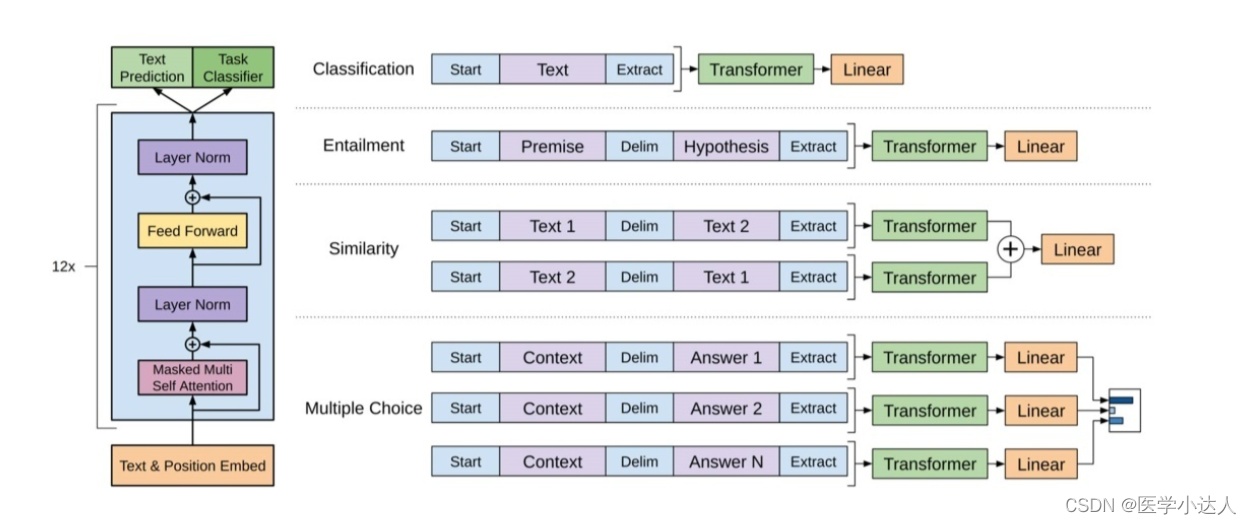
分类任务Classification:对于分类问题,不需要做什么修改
文本蕴涵(Entailment):对于文本蕴涵任务,作者用一个“$”符号将文本和假设进行拼接,并在拼接后的文本前后加入开始符“start”和结束符“end”,然后将拼接后的文本直接传入预训练的语言模型,在模型再接一层线性变换和softmax即可。
文本相似度(Similarity):对于文本相似度任务,由于相似度不需要考虑两个句子的顺序关系,因此,为了反映这一点,作者将两个句子分别与另一个句子进行拼接,中间用$进行隔开,并且前后还是加上起始和结束符,然后分别将拼接后的两个长句子传入Transformer,最后分别得到两个句子的向量![]() ,将这两个向量进行元素相加,然后再接如线性层和softmax层。
,将这两个向量进行元素相加,然后再接如线性层和softmax层。
Multiple-Choice:对于问答和常识推理任务,首先将背景信息与问题进行拼接,然后再将拼接后的文本依次与每个答案进行拼接,最后依次传入Transformer模型,最后接一层线性层得多每个输入的预测值。
5.GPT和BERT的区别:
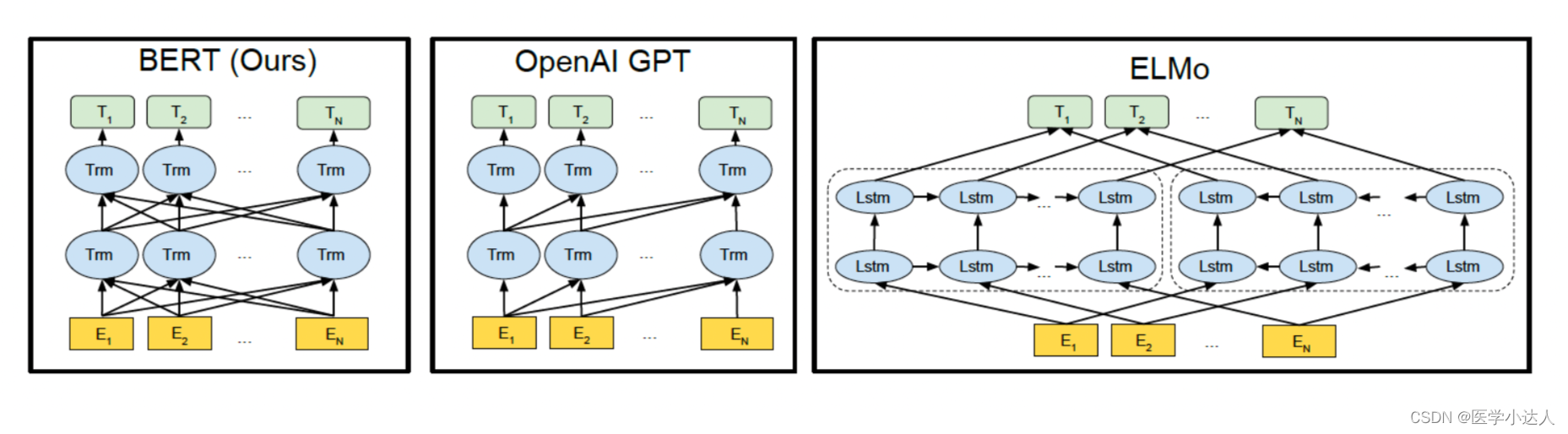
与ELMo相比:
(1)模型架构不同:ELMo 是浅层的双向 RNN;GPT 是多层的 Transformer encoder
(2)针对下游任务的处理不同:ELMo 将词嵌入添加到特定任务中,作为附加功能;GPT 则针对所有任务微调相同的基本模型
与BERT相比:
(1)架构:GPT:采用单向Transformer Decoder结构,只能利用上文信息,不能直接利用下文信息。在预训练阶段使用了两种任务:语言模型(LM)和下一句预测(NSP)。BERT:采用双向Transformer Encoder结构,在预训练阶段使用了两种任务:遮盖语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。
(2)训练任务:GPT:使用的是语言模型和下一句预测任务。在语言模型任务中,模型根据前面的文本预测下一个单词;在下一句预测任务中,模型需要判断两个句子是否相邻。BERT:使用的是遮盖语言模型和下一句预测任务。在遮盖语言模型中,模型需要根据上下文预测被遮盖的单词;在下一句预测任务中,模型需要判断两个句子是否相邻,并给出是或否的预测结果。
(3)数据集:GPT:使用了WebText等大型文本语料库。BERT:使用了Wikipedia等大型文本语料库,以及BookCorpus等小型语料库。
(4)应用场景:GPT:适用于语言生成、文本补全、问答等任务。BERT:适用于文本分类、命名实体识别、情感分析等任务。
参考文章:

