
- 1神经网络——循环神经网络(RNN)_rnn循环神经网络
- 2Transformer模型详解(图解最完整版)
- 3将YOLOv5变成接口使用_yolov5改写api
- 4如何给自己的微信机器人添加语音识别和文字识别的功能_微信hook聊天机器人语音识别
- 5红米k30pro和realmex50pro哪个好_红米k30pro与realmex50pro对比
- 6ChatGPT 商业金矿(上)
- 7使用NLTK进行自然语言处理:英文和中文示例_如何利用nltk处理中文
- 8ERROR: Could not build wheels for hdbscan, which is required to install pyproject.toml-based project
- 9数据库连接池性能优化,连接数到底应该设置多大?_druid最大连接数多少合适
- 10Flutter嵌入原生View,使用原生的WebView_flutter_inappwebview 支持安装原生接口
Actor-Critic 方法
赞
踩
前言
本篇文章我们来介绍一下Actor-Critic 方法。
一、Actor-Critic 方法
1.构造价值网络和策略网络
Actor是策略网络,用来控制agent运动;Critic是价值网络,用来给动作打分;Actor-critic方法把策略学习和价值学习结合起来;在讲策略学习的时候,我们说过我们要学习的是Vπ(s)即状态价值函数,可惜我们不知道π(a|s)和Qπ(s,a),所以我们用两个网络分别近似π(a|s)和Qπ(s,a);
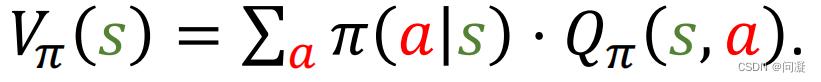
我们用π(a|s;θ)近似π(a|s),这里θ是神经网络的参数;用q(s,a;w)近似Qπ(s,a),其中w是另一个神经网络的参数;策略网络π(a|s;θ)用来控制agent运动,所以叫做actor,你可以把它当做一个运动员;价值网络q(s,a;w)用来评价动作的好坏,所以叫做critic,你可以把它当做裁判;学习这两个网络的目的是让运动员的平均分越来越高,并且让裁判的打分越来越精准;
2.训练策略网络π(a|s;θ)和价值网络q(s,a;w)
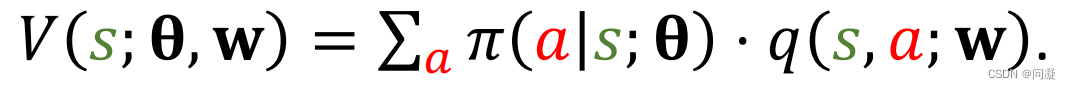
训练的时候要更新两个神经网络的参数θ和w,但是更新参数θ和w的目标是不同的,更新策略网络π(a|s;θ)的参数θ是为了让V(s;θ,w)的值增加;策略网络的监督信号是价值网络q(s,a;w)的打分,也就是通过让自己的表现越接近价值网络的打分来更新参数θ;
更新价值网络q(s,a;w)的参数w是为了让价值网络q(s,a;w)的打分更精准,价值网络的监督信号是环境给出的奖励,也就是通过让自己的打分越来越接近奖励,裁判的水平也就不断提高;
3.训练神经网络的步骤

观测到当前状态st;
把st作为输入,用策略网络π计算概率分布,然后随机随机抽样得到动作at;
agent执行动作at,环境更新状态st+1,并且给出奖励rt;
用TD算法更新价值网络的参数w;让裁判打分更精准;
最后策略梯度算法更新策略网络的参数θ;
Notes:TD算法已经在价值学习里面讲过了;策略梯度算法在策略学习里面讲了,忘记了可以回去看一下;
4.总结一下Actor-Critic Method方法:
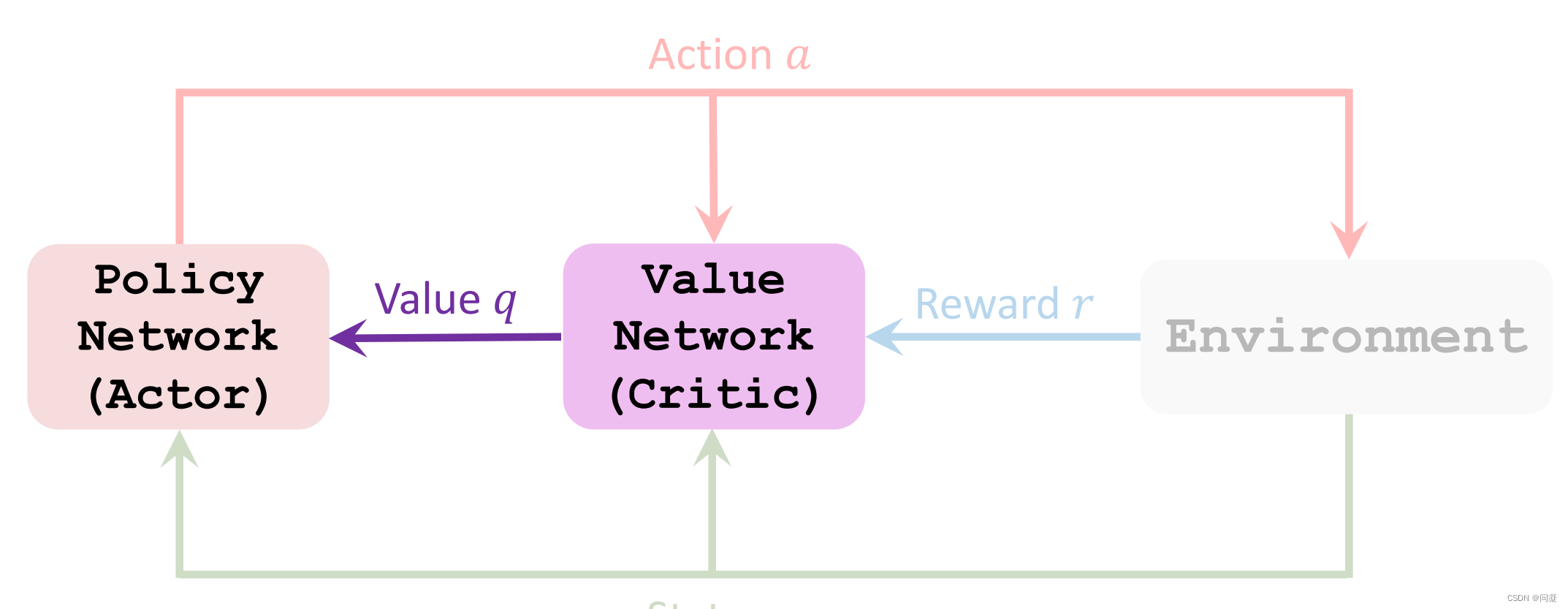
策略网络(actor)观测到当前的状态s,控制agent做出动作a;策略网络相当于一个运动员,目标是让技术越来越好;
(这里的技术指的就是神经网络的参数θ)
但是策略网络即运动员并不知道什么样的动作比较好,所以需要价值网络(critic)来对它的动作打分(也就是q);运动员这样做只是在迎合裁判的喜好,如果裁判的水平不高,那么运动员的水平也不会高,因此裁判员的水平也需要提高;价值网络的改进通过奖励r来提高;总之,Actor-Critic方法的终极目的是学习策略网络,而价值网络只是起辅助作用,策略网络学习完后就不需要这个裁判(价值网络)了;
总结
以上就是今天要讲的内容,本文简单介绍了Actor-Critic方法。

