
- 1Pytorch版本MobileNetV3转ONNX然后转om模型使用Pyacl离线推理_mobilenet3 onnx
- 2Springboot实现邮箱发送短信_springboot 邮箱发送提醒
- 3Ubuntu介绍、与centos的区别、基于VMware安装Ubuntu Server 22.04、配置远程连接、安装jdk+Tomcat_ubuntu 22.04.3 lts 和centos
- 4【Ra-08 LoRaWAN应用】Ra-08基于LoRaWAN协议的Class B模式应用_at+cjoinmode4
- 5鸿蒙子系统解读-分布式软总线子系统初步研究(上)_鸿蒙软总线实例
- 6fastboot简介(android烧录指令)_android fastboot
- 7机器学习——分类树DecisionTreeClassifier
- 8tar命令压缩解压缩带进度条的实现_tar进度条
- 9Linux下自动安装Miniconda脚本_miniconda3 自动安装
- 10熵算法阈值_包络熵的阈值是什么
代码+通俗理解attention机制_torch attention
赞
踩
attention机制在机器学习领域人尽皆知,并且逐渐成为了从NLP扩散到各个领域的科研密码,但是一直对attention的理解不是很深入。尤其是看网上各种各样对论文的翻译和截图,看的云里雾里,因此记录一下attention到底是什么以及其计算过程。
1 attention在直观理解上的作用
attention的作用是在一段文本中注意到关键的字词,或者在图片中注意到局部信息,比如:


因此,attention是用于特征增强的技术,即突出强调单个样本中部分特征的信息。然而,实现这一点并不是像传统数据增强算法一样对单个样本进行操作得到的,而是在一个batch上对多个样本进行操作得到的。
2 attention在数据层面上的作用
将attention看做一个黑盒模型,其在数据层面上的作用就是将1个batch的样本特征,通过变换后得到另一个batch的样本特征,样本数量不会改变,但是样本的特征数量可能会变多或者变少。因此可以理解为做了和全部样本归一化、全部样本缩放一样的操作,只不过attention机制后的样本有了一些新的变化:即更容易被机器训练或者识别了。
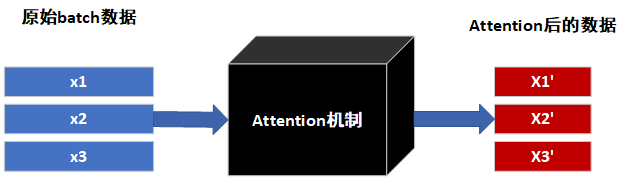
3 attention的流程
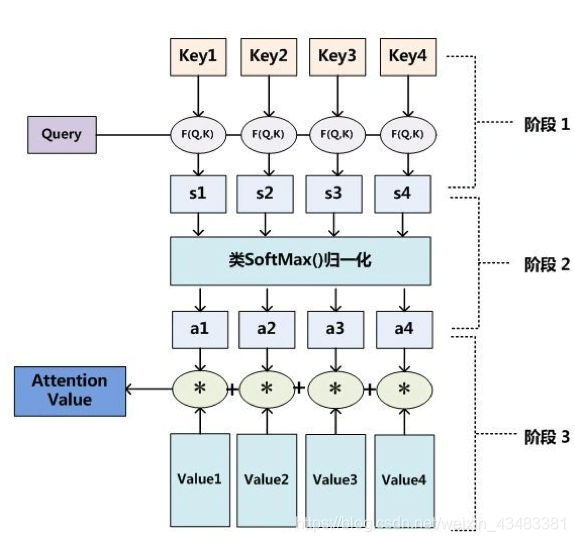
attention的种类随着各种变化有很多,在此只分析最传统的attention机制作为代表,相比于这个图:
我更喜欢下面这个图代表attention的流程:
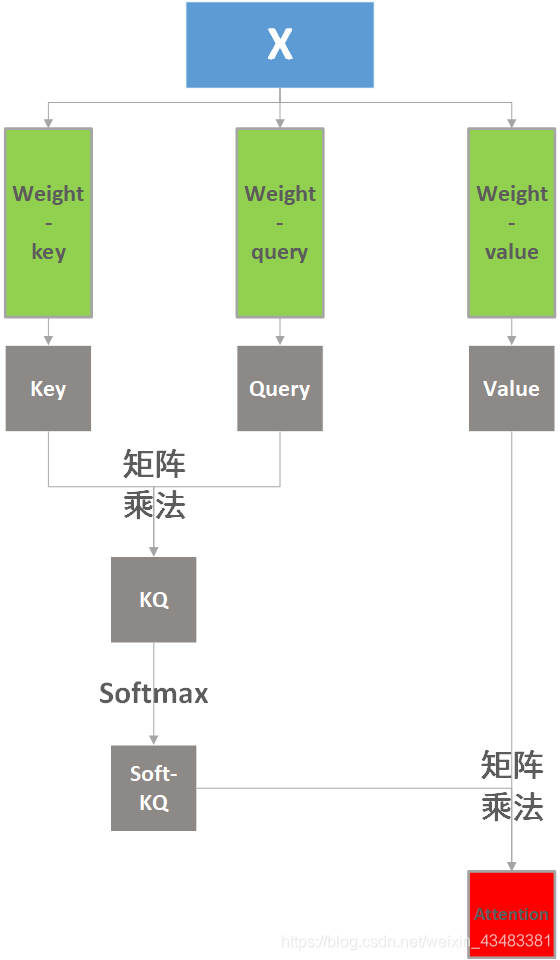
图中绿色的三个权重矩阵是生成Key、Query、Value的关键,需要训练学习出来。
整个流程用一个公式表示为:
A
t
t
e
n
t
i
o
n
(
X
)
=
s
o
f
t
m
a
x
(
Q
u
e
r
y
T
K
e
y
d
(
Q
u
e
r
y
,
K
e
y
)
)
V
a
l
u
e
Attention(X)=softmax(\frac{Query^TKey}{\sqrt{d_{(Query,Key)}}})Value
Attention(X)=softmax(d(Query,Key)
QueryTKey)Value
其中
d
(
Q
u
e
r
y
,
K
e
y
)
d_{(Query,Key)}
d(Query,Key)代表的就是Query和Key的维度,二者是一样的,
1
d
(
Q
u
e
r
y
,
K
e
y
)
\frac{1}{\sqrt{d_{(Query,Key)}}}
d(Query,Key)
1的意思类似对方针归一化,以方便softmax。
使用代码表示上述流程,可以表示为:
import torch # 本质上Attention是对一个batch样本中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数 # 三个样本x1 x2 x3 x1 = torch.tensor([1.,2.,3.,4.,5.]) x2 = torch.tensor([2.,3.,4.,5.,6.]) x3 = torch.tensor([0.,0.,0.,0.,0.]) # 堆成一个batch X = torch.stack([x1,x2,x3], dim=0) # shape 3*5 # 三个attention的矩阵Wq Wk Wv 5*3 # query: Wq = torch.tensor([ [0,1,0], [1,0,3], [3,6,0], [1,4,5], [1,3,0] ], dtype=torch.float32) # key: Wk = torch.tensor([ [1,1,0], [6,6,3], [3,0,0], [0,1,0], [1,1,1] ], dtype=torch.float32) # value: Wv = torch.tensor([ [0,1,0], [0,0,3], [0,1,0], [0,4,0], [0,3,1] ], dtype=torch.float32) # 条件都具备了,下面开始执行self-attention的计算流程 # 1-根据X计算query key value query = torch.mm(X, Wq) # shape 3*5 * 5*3 = 3*3 key = torch.mm(X, Wk) value = torch.mm(X, Wv) # 2-计算attentiond的score=key*value score = torch.mm(query, key) # shape 3*3 * 3*3 = 3*3 softmax_score = torch.softmax(score, dim=1) # shape 3*3 -> 3*3 # dim = 1 相当于矩阵的行不变,dim=1,dim指的是张量(列表)的dim # 3-乘以value,得到最后的attention attention = torch.mm(softmax_score, value) print("初始值X:",X, '\n','attention结果:', attention)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
4 attention的本质
分析一下attention机制的本质:在一个batch的样本集X中,利用样本 x 1 , x 2 , . . . x n x_1,x_2,...x_n x1,x2,...xn的关系,对各个样本中的特征向量进行重构,使得重构后的向量中特征更加明显,更方便机器进行识别。这个过程就相当于让机器戴了一层滤镜一样。
如何实现上面的过程?主要就是通过将原始样本集X先变换成三个相同尺寸的张量key,query,value,想象一个做数学题的场景:key就是会做的不同题目的完整解法,query就是要做的各个题目,value可以看做会的不同的做题技巧(也就是做题人本身),那么做题的过程就是先计算各个key与各个query的相似度,然后根据这个相似度去在大脑里搜寻应该采用哪些做题技巧的组合更好。

