
热门标签
热门文章
- 1满足你一切需求的 MMYOLO/MMDet 可视化 (一)_mmdection可视化怎么
- 2Triton Inference Server 快速上手指南(2.40版本 预计12月写完)_trition 部署
- 3[最佳实践] conda环境内安装cuda 和 Mamba的安装_causal_conv1d_cuda
- 4视觉智能识别技术的应用瓶颈,主要面临哪些困境?_图像智能识别跟踪 技术瓶颈
- 5机器学习 - 图像识别_机器学习 图形识别
- 6基于时空注意力融合网络的城市轨道交通假期短时客流预测
- 7VMware虚拟机克隆ubuntu20.04系统IP相同_vmware克隆虚拟机后ip地址一样吗
- 8小米路由器 R4A 刷原生 OpenWrt 后的风景_miwifi_r4a_firmware_72d65_2.28.62.bin
- 9Docker | Docker+Nginx部署前端项目_docker部署nginx并部署前端项目
- 10拥抱AI大模型之美,帮你探索OpenAI大语言模型的能力(基础实战篇)_大模型 openai_key
当前位置: article > 正文
【论文精读】Emergent Abilities of Large Language Models
作者:我家自动化 | 2024-04-05 17:53:43
赞
踩
emergent abilities of large language models
1. Emergence
涌现(emergence)或称创发、突现、呈展、演生,是一种现象,为许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。

扩大(
Scaling up)语言模型已被证明可以预测性地提高各种下游任务的性能和样本效率。
- 样本效率(
Sample efficiency)是指学习算法在使用尽可能少的训练样本的情况下,在某个任务上获得良好表现的能力。换句话说,它衡量了算法在学习任务时需要多少数据才能有效地学习。 - 一个样本效率高的算法可以使用较少的样本学习与一个样本效率低的算法相同的任务。这在获取更多的训练数据可能很困难或昂贵的情况下尤为重要,例如医学诊断或机器人领域。
- 样本效率受多种因素的影响,包括任务的复杂性、训练数据的质量和相关性以及算法的设计和容量。一些学习算法由于其能够从有限的数据中很好地推广,因此比其他算法更具有样本效率;而其他算法需要更多的数据才能获得良好的性能。
- 因此,在评估和比较不同的学习算法时,样本效率是一个重要的指标。

- 涌现是指系统的量变导致行为的质变。
- 具体来说,我们将大型语言模型的涌现能力定义为在小规模模型中不存在,但在大规模模型中存在的能力;因此,涌现能力不能简单地通过外推较小模型的表现来预测。
2. Few-Shot Prompting
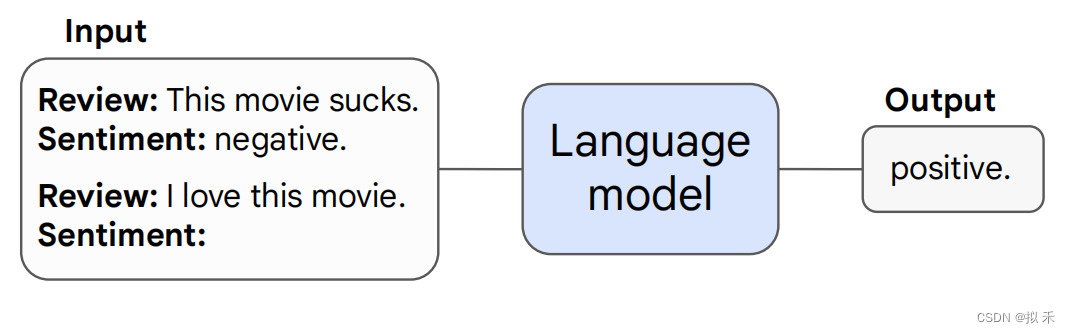
通过给
LLM(Large Language Model)几个实例,不调整模型参数,解决下游任务。本质上属于In Context Learning。
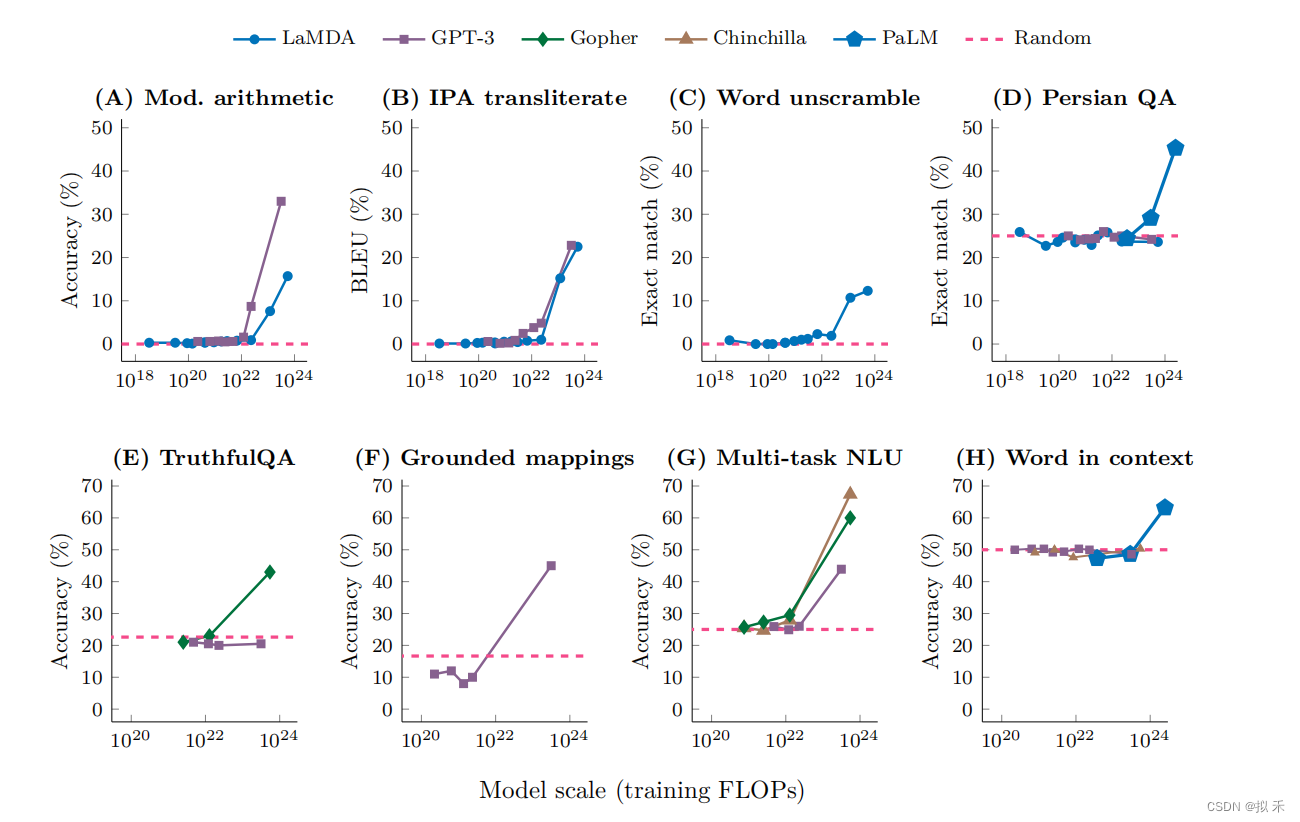
当语言模型达到一定的随机性能时,通过少量提示(
few-shot prompting)执行任务的能力就会涌现,在此之后,性能显着提高到远高于随机。
3. Augmented Prompting Strategies
例如:
Chain-of-Thought(思维链),一种增强的提示策略(Augmented Prompting Strategies)。
解决多步推理任务,引导语言模型在给出最终答案之前生成一系列中间步骤。
详情请见:【Chain-of-Thought】开创 AI 模型推理新纪元
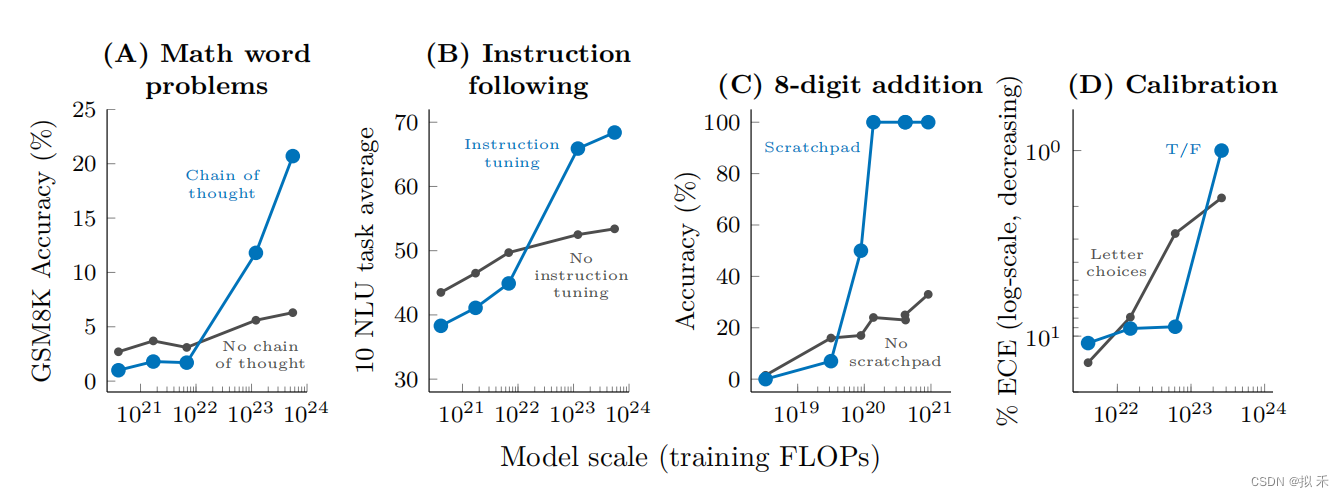
专门的提示或微调方法可能会有涌现现象,因为它们在没有达到一定的模型规模之前,是不会产生积极的效果。
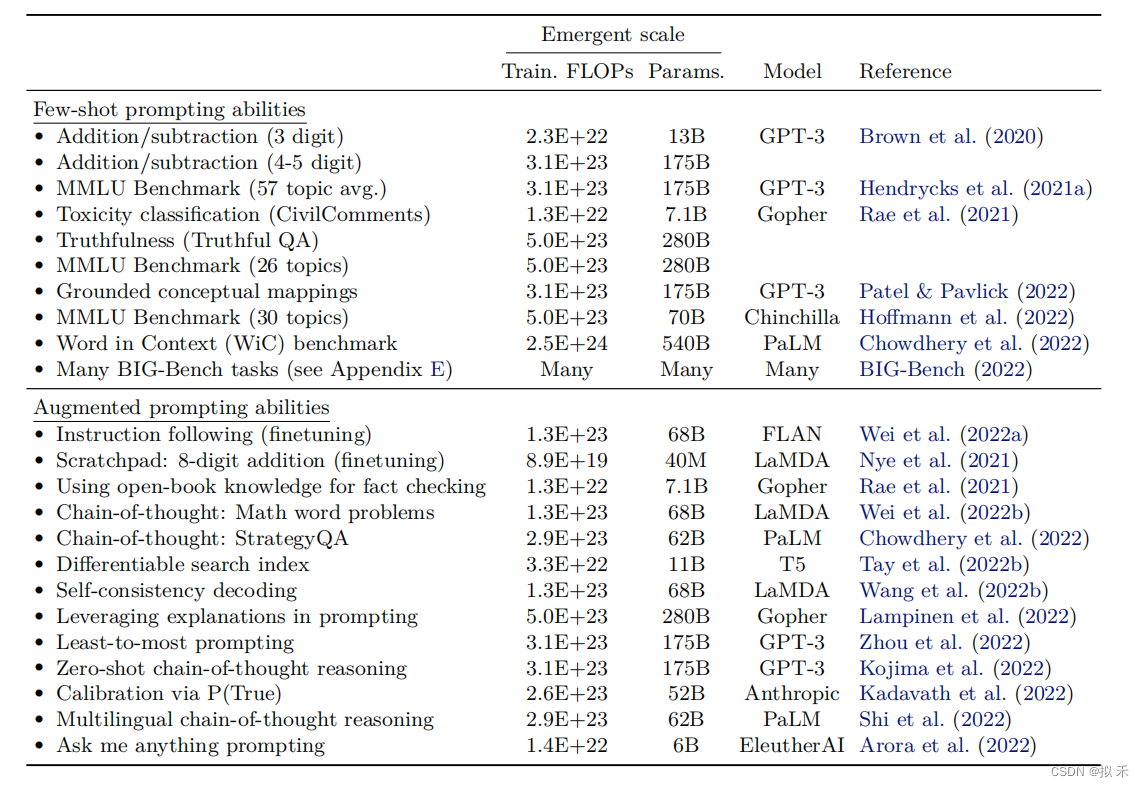
4. Discussion
- 我们已经看到,在少量样本提示设置或其他情况下,一系列能力到目前为止只在对足够大的语言模型进行评估时才被观察到。因此,它们的出现不能仅通过小型模型的表现简单外推来预测。具有涌现能力的少量样本提示任务也是不可预测的,因为这些任务并没有在预训练中显式包含,而且我们可能不知道语言模型可以执行的少量样本提示任务的全部范围。
- 这引发了一个问题,即进一步扩展是否会赋予更大的语言模型新的涌现能力。语言模型目前无法完成的任务是未来出现的主要候选对象;例如,在
BIG-Bench中有数十个任务,即使是最大的GPT-3和PaLM模型也无法实现高于随机的性能。 BIG-Bench是一个评估语言模型能力的广泛基准(benchmark),由 AI2、微软和卡内基梅隆大学等机构合作开发。它涵盖了来自多个领域的70个任务,包括自然语言理解、常识推理、知识库问答等等。这些任务旨在测试语言模型在大规模、复杂、多样化的应用场景下的表现,是目前最具挑战性的语言模型测试集之一。BIG-Bench 的任务数量和难度要远高于其他常见的语言模型基准,它的推出对于评估和推动语言模型的发展具有重要意义。- 模型大小并不是解锁涌现能力的唯一因素。随着训练大型语言模型的科学的进步,对于具有新体系结构、更高质量数据或改进的训练过程的较小模型,某些能力可能会被解锁。一个例子是,
InstructGPT、ChatGPT、GPT-4模型提出了一种基于人类反馈的微调和强化学习方法(RLHF),这使得一个参数量 1.3B 的模型在广泛的用例中,在人类评估方面的表现优于更大的模型。

- 重要的是,风险也可能会出现,例如,大型语言模型的社会风险,如真实性、偏见和毒性。无论它们是否可以准确地被描述为“涌现”,这些风险都是重要的考虑因素,并且在某些情况下,随着模型规模的增加而增加。由于关于涌现能力的工作鼓励语言模型的规模扩大,因此重要的是要意识到随着模型规模的增加而增加的风险,即使它们不是涌现的。
5. Directions for future work
- Further model scaling.
- Improved model architectures and training.
- Data scaling.
- Better techniques for and understanding of prompting.
- Frontier tasks.(解决前沿任务)
- Understanding emergence. (涌现能力的可解释性和新的理解)
6. Conclusions
我们已经讨论了语言模型的涌现能力,迄今为止,只有在一定的计算规模上才观察到有意义的表现。涌现能力可以跨越各种语言模型、任务类型和实验场景。这些能力是最近发现的大型语言模型的结果,它们是如何出现的,以及更多的扩展是否会出现进一步的涌现能力成为 NLP 领域未来重要的研究方向。
7. References
[1] Wei J, Tay Y, Bommasani R, et al. Emergent abilities of large language models[J]. arXiv preprint arXiv:2206.07682, 2022.

本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

