
- 1利用逻辑回归进行鸢尾花分类_鸢尾花逻辑回归
- 2Unity2019.4.16安卓环境及AR环境安装_com.preface.unity.lib.bridge.apibridge
- 3MySQL too many connections 之解决方法_too many connections"}
- 4具有非线性不确定干扰的多智能体系统的固定时间事件触发一致性控制(附论文链接+源码Matlab)_随机 固定时间 一致性 时滞
- 5Hello算法6:哈希表
- 6CentOS系统中使用yum快速安装python3_centos yum python3
- 720款超级好用的idea插件,开发效率翻倍!!!_idea实用插件
- 8使用TensorFlow Serving进行模型的部署和客户端推理_tensorflow server
- 9dom型xss ---(waf绕过)_dom类xss如何判断
- 10笑死!推特限流,微博赢麻了;使用ChatGPT撰写简历;SD电脑配置推荐;斯坦福67门AI课程学习路径 | ShowMeAI日报
基于朴素贝叶斯、SVM和LDA模型的的文本处理分析_svm 朴素贝叶斯 文本分类 准确度
赞
踩
朴素贝叶斯
朴素贝叶斯算法是基于 贝叶斯原理 与 特征条件 独立假设的分类算法,对于给定的训练数据集,首先基于 特征条件 独立假设学习输入/输出的 联合概率分布 ,然后基于此模型,对给定的输入x,利用 贝叶斯定理 求出 后验概率最大 的输出y,朴素贝叶斯法实现简单,学习与预测的效率都很高,是一种常见的方法。
朴素贝叶斯(naive Bayes)算法是有监督的学习算法,解决的是分类问题,如客户是否流失、是否值得投资、信用等级评定等多分类问题。该算法的优点在于简单易懂、学习效率高、在某些领域的分类问题中能够与决策树、神经网络相媲美。但由于该算法以 自变量之间的独立 (条件特征独立)性和 连续变量 的正态性假设为前提,就会导致算法精度在某种程度上受影响。
贝叶斯方法把计算 “具有某特征的条件下属于某类” 的概率转换成计算 “属于某类的条件下具有某特征” 的概率,属于有监督学习。
算法优缺点
优点:在数据较少的情况先仍然有效,可以处理多类别问题
缺点:对于输入数据的 准备方式 较为敏感
适用数据类型:标称型数据
贝叶斯决策理论
朴素贝叶斯作为贝叶斯决策理论的一部分,首先先了解一下贝叶斯理论的概念。假设一个数据集,有两类组成。我们现在用p1(x,y)表示数据点(x,y)属于类别1的概率,用p2(x,y)表示数据点(x,y)属于类别2的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
如果p1(x,y) > p2(x,y),那么类别为1
如果p1(x,y) < p2(x,y),那么类别为2
也就是说,我们会 选择高概率对应的类别 。这就是贝叶斯决策理论的核心思想,即选择具有 最高概率的决策。p1和p2 的计算需要知道两个概念:条件概率 和 全概率公式。
条件概率
条件概率(Condittional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。

上面的结果表示条件概率的计算公式
全概率公式
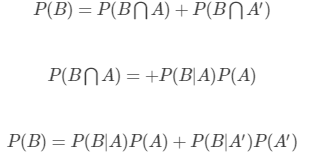
上式的含义表示:如果A和A′构成一个样本空间的一个划分,那么事件B的概率就等于A和A′的概率分别乘以B对这两个事件的条件概率之和。
贝叶斯推断
对条件概率变形,得到下式
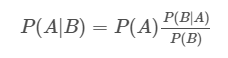
对于上式,我们对p(A)称为 “先验概率” ,即在B事件发生之前,我们对A事件概率的一个判断
p(A|B)称为 “后验概率” ,即在B事件发生之后,我们对A事件概率的重新评估
P(B|A)/P(B)称为 “可能性函数”,这是一个 调整因子,使得 预估概率更接近真实概率。
对于条件概率重新定义为:
后验概率 = 先验概率 * 调整因子
- 1
这是贝叶斯推断的 含义:
我们先预估一个”先验概率”,然后加入实验结果,看这个实验到底是增强还是削弱了”先验概率”,由此得到更接近事实的”后验概率”。
在这里,如果”可能性函数”P(B|A)/P(B)>1,意味着”先验概率”被增强,事件A的发生的可能性变大;如果”可能性函数”=1,意味着B事件无助于判断事件A的可能性;如果”可能性函数”<1,意味着”先验概率”被削弱,事件A的可能性变小。
朴素贝叶斯
“朴素” 的解释:
(
1
)
、
每
个
特
征
相
互
独
立
(1)、每个特征相互独立
(1)、每个特征相互独立
(
2
)
、
每
个
特
征
的
权
重
(
或
重
要
性
)
都
相
等
,
即
对
结
果
的
影
响
程
度
都
相
等
(2)、每个特征的权重(或重要性)都相等,即对结果的影响程度都相等
(2)、每个特征的权重(或重要性)都相等,即对结果的影响程度都相等
步骤:

举例说明:
例子1:

问题:对于第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
)
P\left ( A|B \right ) = \frac{P\left ( B|A \right )P\left ( A \right )}{P\left ( B \right )}
P(A∣B)=P(B)P(B∣A)P(A)
对样本带入计算
P(感冒|打喷嚏&建筑工人)=P(打喷嚏&建筑工人|感冒)P(感冒) / P(打喷嚏&建筑工人)
根据朴素贝叶斯条件独立假设可知,打喷嚏和建筑工人两个特征是独立的,所以:
P(感冒|打喷嚏&建筑工人)=P(打喷嚏|感冒)P(建筑工人|感冒P(感冒) / P(打喷嚏&建筑工人)
P(感冒|打喷嚏&建筑工人)=0.660.330.5/(0.5*0.33)=0.66
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
例子2:
文档分类的常用算法
以在线社区留言为例。为了不影响社区的发展,我们要屏蔽侮辱性的言论,所以要构建一个 快速过滤器,如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标志为内容不当。过滤这类内容是一个很常见的需求。对此问题建立两个类型:侮辱类和非侮辱类,使用1和0分别表示。
我们把文本看成 单词向量或者词条向量 ,也就是说将句子转换为向量。考虑出现所有文档中的单词,再决定将哪些单词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。简单起见,我们先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行 分类标注。
步骤一:创建文本及标签
def loadDataSet(): # 切分的词条 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] # 类别标签向量,1代表侮辱性词汇,0代表不是 classVec = [0, 1, 0, 1, 0, 1] return postingList, classVec if __name__=='__main__': postingList,classVec=loadDataSet() for each in postingList: print(each) print(classVec)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

其中,输出的 postingList和 classVec 分别为 切分后的样本 和 类别标签。
步骤二:创建词汇表,将切分好的词条转化为词条向量
def creatVocablist(dataset): vocabSet = set([]) for i in dataset: vocabSet = vocabSet|set(i) print("字典:\n",list(vocabSet)) return list(vocabSet) #将词条转化为词条向量 def setofWord2Vec(vocabList,inputSet): returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("该词不在词典中") return returnVec if __name__ == '__main__': postinglist,classVec = loadDataSet() myvocabList = creatVocablist(postingList) trainMat = [] for word in postingList: trainMat.append(setofWord2Vec(myvocabList,word)) print("trainMat:\n",trainMat)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

从运行结果可以看出,postingList是原始的词条列表,myVocabList是词汇表。myVocabList是所有单词出现的集合,没有重复的元素。 词汇表是用来干什么的? 没错,它是用来将 词条向量化 的,一个单词在词汇表中出现过一次,那么就在相应位置记作1,如果没有出现就在相应位置记作0。trainMat是所有的词条向量组成的列表。它里面存放的是根据myVocabList向量化的词条向量。
步骤三:创建朴素贝叶斯分类器
已知文本的词向量表示trainMat和类别标签classVec,构建贝叶斯分类器
def trainNBO(trainMtrix,trainCategory): numTrainDocs = len(trainMtrix)#文档数目 numWords = len(trainMtrix[0])#每篇文档的字数 pAbusive = sum(trainCategory)/numTrainDocs #侮辱类概率 #创建numpy.zeros数组 p0Num=np.zeros(numWords);p1Num=np.zeros(numWords) #分母初始化为0.0 p0Denom=0.0;p1Denom=0.0 #分别计算属于侮辱类和费侮辱类的概率 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMtrix[i] p1Denom += sum(trainMtrix[i]) else: p0Num += trainMtrix[i] p0Denom += sum(trainMtrix[i]) #相除 p1Vect=p1Num/p1Denom #侮辱类的条件概率数组 p0Vect=p0Num/p0Denom #非侮辱类的条件概率数组 return p1Vect,p0Vect,pAbusive if __name__ == "__main__": p1V,p0V,pAb = trainNB0(trainMat,classVec) print('侮辱类概率数组:\n',p1V) print('非侮辱类概率数组:\n',p0V) print('所有文档中侮辱类样本所占比率:\n',pAb)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

说明:
p0V存放的是每个单词属于类别0,也就是非侮辱类词汇的概率
p1V存放的就是各个单词属于侮辱类的条件概率。pAb就是先验概率。
步骤四:利用分类器进行分类
""" 函数说明:朴素贝叶斯分类器分类函数 Parameters: vec2Classifyaaa:待分类的词条数组 p0Vec:非侮辱类的条件概率数组 p1Vec:侮辱类的条件概率数组 pClass1:文档属于侮辱类的概率 Returns: 0 :属于非侮辱类 1 :属于侮辱类 """ def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1): #对应元素相乘 p1=reduce(lambda x,y:x*y,vec2Classify*p1Vec)*pClass1 p0=reduce(lambda x,y:x*y,vec2Classify*p0Vec)*(1.0-pClass1) print('p0:',p0) print('p1:',p1) if p1>p0: return 1 else: return 0 def testingNB(): #创建实验样本 listOPosts,listClasses=loadDataSet() #创建词汇表 myVocabList=createVocabList((listOPosts)) trainMat=[] for postinDoc in listOPosts: #将实验样本向量化 trainMat.append(setOfWords2Vec(myVocabList,postinDoc)) #训练朴素贝叶斯分类器 p0V,p1V,pAb=trainNB0(np.array(trainMat),np.array(listClasses)) #测试样本1 testEntry=['love','my','dalmation'] #测试样本向量化 thisDoc=np.array(setOfWords2Vec(myVocabList,testEntry)) #执行分类并打印分类结果 if classifyNB(thisDoc,p0V,p1V,pAb): print(testEntry,'属于侮辱类') # 执行分类并打印分类结果 else: print(testEntry,'属于非侮辱类') #测试样本2 testEntry=['stupid','garbage'] #测试样本向量化 thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) # 执行分类并打印分类结果 if classifyNB(thisDoc, p0V, p1V, pAb): print(testEntry, '属于侮辱类') # 执行分类并打印分类结果 else: print(testEntry, '属于非侮辱类') if __name__ == '__main__': testingNB()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60

我们发现,p0和p1的计算结果都是0,下面来探讨产生该结果的问题
总结:
朴素贝叶斯推断的一些优点:
(
1
)
、
生
成
式
模
型
,
通
过
计
算
概
率
来
进
行
分
类
,
可
以
用
来
处
理
多
分
类
问
题
。
(1)、生成式模型,通过计算概率来进行分类,可以用来处理多分类问题。
(1)、生成式模型,通过计算概率来进行分类,可以用来处理多分类问题。
(
2
)
、
对
小
规
模
的
数
据
表
现
很
好
,
适
合
多
分
类
任
务
,
适
合
增
量
式
训
练
,
算
法
也
比
较
简
单
。
(2)、对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法也比较简单。
(2)、对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法也比较简单。
朴素贝叶斯推断的一些缺点:
(
1
)
、
对
输
入
数
据
的
表
达
形
式
很
敏
感
。
(1)、对输入数据的表达形式很敏感。
(1)、对输入数据的表达形式很敏感。
(
2
)
、
由
于
朴
素
贝
叶
斯
的
“
朴
素
”
特
点
,
所
以
会
带
来
一
些
准
确
率
上
的
损
失
。
(2)、由于朴素贝叶斯的“朴素”特点,所以会带来一些准确率上的损失。
(2)、由于朴素贝叶斯的“朴素”特点,所以会带来一些准确率上的损失。
(
3
)
、
需
要
计
算
先
验
概
率
,
分
类
决
策
存
在
错
误
率
。
(3)、需要计算先验概率,分类决策存在错误率。
(3)、需要计算先验概率,分类决策存在错误率。
朴素贝叶斯改进–拉普拉斯平滑
1)零概率问题
造成原因:
利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算p(w0|A)p(w1|A)p(w2|A)p(w0|A)p(w1|A)p(w2|A),如果其中有一个为0,则最后的结果也为0。
解决方法:
为了降低这种影响,可以将所有词的出现次数初始化为1,并将分母初始化为2,这种做法称为“拉普拉斯平滑”,也称“加1平滑”,是比较常用的平滑方法,为了解决0概率问题。
2)下溢出
造成的原因:
是太多很小的数相乘,越乘越小,就造成了下溢出的问题。在相应小数位置进行四舍五入,计算结果可能就变成0了。
解决方法:
对乘积结果取自然对数,通过求对数可以避免下溢出或者浮点数舍入导致的错误,同时,采用自然对数进行处理不会有任何损失。

上图显示了f(x)和lnf(x)的曲线,可以看出上面两条曲线同增同减,且最大值处相同,取值虽然不同,但是不影响最终结果。
因此,可以对trainNB0函数进行修改:
def trainNBO(trainMtrix,trainCategory): numTrainDocs = len(trainMtrix) numWords = len(trainMtrix[0]) pAbusive = sum(trainCategory)/numTrainDocs # 创建numpy.ones数组,词条初始化为1,拉普拉斯平滑 p0Num = np.ones(numWords); p1Num = np.ones(numWords) # 分母初始化为2.0,拉普拉斯平滑 p0Denom = 2.0 p1Denom = 2.0 for i in range(numTrainDocs): # 统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)··· if trainCategory[i] == 1: p1Num += trainMtrix[i] p1Denom += sum(trainMtrix[i]) # 统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)··· else: p0Num += trainMtrix[i] p0Denom += sum(trainMtrix[i]) # 相除 p1Vect = np.log(p1Num / p1Denom) p0Vect = np.log(p0Num / p1Denom) # 返回属于侮辱类的条件概率 return p0Vect, p1Vect, pAbusive if __name__ == "__main__": p1V,p0V,pAb = trainNBO(trainMat,classVec) print('侮辱类概率数组:\n',p1V) print('非侮辱类概率数组:\n',p0V) print('所有文档中侮辱类样本所占比率:\n',pAb)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31

此时已经不存在零概率了。
对classifyNB进行修改:
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1): #对应元素相乘,logA*B=logA+logB,所以要加上np.log(pClass1) p1=sum(vec2Classify*p1Vec)+np.log(pClass1) p0 = sum(vec2Classify * p0Vec) + np.log(1.0-pClass1) if p1>p0: return 1 else: return 0 def testingNB(): #创建实验样本 listOPosts,listClasses=loadDataSet() #创建词汇表 myVocabList=creatVocablist((listOPosts)) trainMat=[] for postinDoc in listOPosts: #将实验样本向量化 trainMat.append(setofWord2Vec(myVocabList,postinDoc)) #训练朴素贝叶斯分类器 p0V,p1V,pAb=trainNBO(np.array(trainMat),np.array(listClasses)) #测试样本1 testEntry=['love','my','dalmation'] #测试样本向量化 thisDoc=np.array(setofWord2Vec(myVocabList,testEntry)) #执行分类并打印分类结果 if classifyNB(thisDoc,p0V,p1V,pAb): print(testEntry,'属于侮辱类') # 执行分类并打印分类结果 else: print(testEntry,'属于非侮辱类') #测试样本2 testEntry=['stupid','garbage'] #测试样本向量化 thisDoc = np.array(setofWord2Vec(myVocabList, testEntry)) # 执行分类并打印分类结果 if classifyNB(thisDoc, p0V, p1V, pAb): print(testEntry, '属于侮辱类') # 执行分类并打印分类结果 else: print(testEntry, '属于非侮辱类') if __name__ == '__main__': testingNB()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46

可以看出,结果变得很好
本文就先暂时这么多,其他部分可以参考博客传送门
本文参考:呆呆的猫
SVM模型
LDA(主题模型)
LDA理论原理篇本文不做过多讲解,感兴趣的可以参考传送门,本文将参考刘建平老师原理篇关于LDA模型的讲解进行梳理。
在scikit-learn中,LDA主题模型的类在sklearn.decomposition.LatentDirichletAllocation包中,其算法实现主要基于原理篇里讲的变分推断EM算法,而没有使用基于Gibbs采样的MCMC算法实现。
而具体到变分推断EM算法,scikit-learn除了我们原理篇里讲到的标准的变分推断EM算法外,还实现了另一种在线变分推断EM算法,它在原理篇里的变分推断EM算法的基础上,为了避免文档内容太多太大而超过内存大小,而提供了分步训练(partial_fit函数),即一次训练一小批样本文档,逐步更新模型,最终得到所有文档LDA模型的方法。这个改进算法我们没有讲,具体论文在这:“Online Learning for Latent Dirichlet Allocation” 。
下面我们来看看sklearn.decomposition.LatentDirichletAllocation类库的主要参数。
scikit-learn LDA主题模型主要参数和方法
我们来看看LatentDirichletAllocation类的主要输入参数:
1) n_topics: 即我们的隐含主题数K,需要调参。K的大小取决于我们对主题划分的需求,比如我们只需要类似区分是动物,植物,还是非生物这样的粗粒度需求,那么K值可以取的很小,个位数即可。如果我们的目标是类似区分不同的动物以及不同的植物,不同的非生物这样的细粒度需求,则K值需要取的很大,比如上千上万。此时要求我们的训练文档数量要非常的多。
2) doc_topic_prior: 即我们的文档主题先验Dirichlet分布θd的参数α。一般如果我们没有主题分布的先验知识,可以使用默认值1/K。
3) topic_word_prior: 即我们的主题词先验Dirichlet分布βk的参数η。一般如果我们没有主题分布的先验知识,可以使用默认值1/K。
4) learning_method: 即LDA的求解算法。有 ‘batch’ 和 ‘online’两种选择。 ‘batch’即我们在原理篇讲的变分推断EM算法,而"online"即在线变分推断EM算法,在"batch"的基础上引入了分步训练,将训练样本分批,逐步一批批的用样本更新主题词分布的算法。默认是"online"。选择了‘online’则我们可以在训练时使用partial_fit函数分布训练。不过在scikit-learn 0.20版本中默认算法会改回到"batch"。建议样本量不大只是用来学习的话用"batch"比较好,这样可以少很多参数要调。而样本太多太大的话,"online"则是首先了。
5)learning_decay: 仅仅在算法使用"online"时有意义,取值最好在(0.5, 1.0],以保证"online"算法渐进的收敛。主要控制"online"算法的学习率,默认是0.7。一般不用修改这个参数。
6)learning_offset: 仅仅在算法使用"online"时有意义,取值要大于1。用来减小前面训练样本批次对最终模型的影响。
7) max_iter : EM算法的最大迭代次数。
8)total_samples: 仅仅在算法使用"online"时有意义, 即分步训练时每一批文档样本的数量。在使用partial_fit函数时需要。
9)batch_size: 仅仅在算法使用"online"时有意义, 即每次EM算法迭代时使用的文档样本的数量。
10)mean_change_tol : 即E步更新变分参数的阈值,所有变分参数更新小于阈值则E步结束,转入M步。一般不用修改默认值。
11) max_doc_update_iter: 即E步更新变分参数的最大迭代次数,如果E步迭代次数达到阈值,则转入M步。
从上面可以看出,如果learning_method使用"batch"算法,则需要注意的参数较少,则如果使用"online",则需要注意"learning_decay", “learning_offset”,“total_samples”和“batch_size”等参数。无论是"batch"还是"online", n_topics(K), doc_topic_prior(α), topic_word_prior(η)都要注意。如果没有先验知识,则主要关注与主题数K。可以说,主题数K是LDA主题模型最重要的超参数。
scikit-learn LDA中文主题模型实例
下面我们给一个LDA中文主题模型的简单实例,从分词一直到LDA主题模型。
完整代码参见刘建平老师的github: https://github.com/ljpzzz/machinelearning/blob/master/natural-language-processing/lda.ipynb
我们的有下面三段文档语料,分别放在了nlp_test0.txt, nlp_test2.txt和 nlp_test4.txt:
沙瑞金赞叹易学习的胸怀,是金山的百姓有福,可是这件事对李达康的触动很大。易学习又回忆起他们三人分开的前一晚,大家一起喝酒话别,易学习被降职到道口县当县长,王大路下海经商,李达康连连赔礼道歉,觉得对不起大家,他最对不起的是王大路,就和易学习一起给王大路凑了5万块钱,王大路自己东挪西撮了5万块,开始下海经商。没想到后来王大路竟然做得风生水起。沙瑞金觉得他们三人,在困难时期还能以沫相助,很不容易。
沙瑞金向毛娅打听他们家在京州的别墅,毛娅笑着说,王大路事业有成之后,要给欧阳菁和她公司的股权,她们没有要,王大路就在京州帝豪园买了三套别墅,可是李达康和易学习都不要,这些房子都在王大路的名下,欧阳菁好像去住过,毛娅不想去,她觉得房子太大很浪费,自己家住得就很踏实。
347年(永和三年)三月,桓温兵至彭模(今四川彭山东南),留下参军周楚、孙盛看守辎重,自己亲率步兵直攻成都。同月,成汉将领李福袭击彭模,结果被孙盛等人击退;而桓温三战三胜,一直逼近成都。
首先我们进行分词,并把分词结果分别存在nlp_test1.txt, nlp_test3.txt和 nlp_test5.txt:
# -*- coding: utf-8 -*- import jieba jieba.suggest_freq('沙瑞金', True) jieba.suggest_freq('易学习', True) jieba.suggest_freq('王大路', True) jieba.suggest_freq('京州', True) #第一个文档分词# with open('./nlp_test0.txt') as f: document = f.read() document_decode = document.decode('GBK') document_cut = jieba.cut(document_decode) #print ' '.join(jieba_cut) result = ' '.join(document_cut) result = result.encode('utf-8') with open('./nlp_test1.txt', 'w') as f2: f2.write(result) f.close() f2.close() #第二个文档分词# with open('./nlp_test2.txt') as f: document2 = f.read() document2_decode = document2.decode('GBK') document2_cut = jieba.cut(document2_decode) #print ' '.join(jieba_cut) result = ' '.join(document2_cut) result = result.encode('utf-8') with open('./nlp_test3.txt', 'w') as f2: f2.write(result) f.close() f2.close() #第三个文档分词# jieba.suggest_freq('桓温', True) with open('./nlp_test4.txt') as f: document3 = f.read() document3_decode = document3.decode('GBK') document3_cut = jieba.cut(document3_decode) #print ' '.join(jieba_cut) result = ' '.join(document3_cut) result = result.encode('utf-8') with open('./nlp_test5.txt', 'w') as f3: f3.write(result) f.close() f3.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
现在我们读入分好词的数据到内存备用,并打印分词结果观察:
with open('./nlp_test1.txt') as f3:
res1 = f3.read()
print res1
with open('./nlp_test3.txt') as f4:
res2 = f4.read()
print res2
with open('./nlp_test5.txt') as f5:
res3 = f5.read()
print res3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
打印出的分词结果如下:
沙瑞金 赞叹 易学习 的 胸怀 , 是 金山 的 百姓 有福 , 可是 这件 事对 李达康 的 触动 很大 。 易学习 又 回忆起 他们 三人 分开 的 前一晚 , 大家 一起 喝酒 话别 , 易学习 被 降职 到 道口 县当 县长 , 王大路 下海经商 , 李达康 连连 赔礼道歉 , 觉得 对不起 大家 , 他 最 对不起 的 是 王大路 , 就 和 易学习 一起 给 王大路 凑 了 5 万块 钱 , 王大路 自己 东挪西撮 了 5 万块 , 开始 下海经商 。 没想到 后来 王大路 竟然 做 得 风生水 起 。 沙瑞金 觉得 他们 三人 , 在 困难 时期 还 能 以沫 相助 , 很 不 容易 。
沙瑞金 向 毛娅 打听 他们 家 在 京州 的 别墅 , 毛娅 笑 着 说 , 王大路 事业有成 之后 , 要 给 欧阳 菁 和 她 公司 的 股权 , 她们 没有 要 , 王大路 就 在 京州 帝豪园 买 了 三套 别墅 , 可是 李达康 和 易学习 都 不要 , 这些 房子 都 在 王大路 的 名下 , 欧阳 菁 好像 去 住 过 , 毛娅 不想 去 , 她 觉得 房子 太大 很 浪费 , 自己 家住 得 就 很 踏实 。
347 年 ( 永和 三年 ) 三月 , 桓温 兵至 彭模 ( 今 四川 彭山 东南 ) , 留下 参军 周楚 、 孙盛 看守 辎重 , 自己 亲率 步兵 直攻 成都 。 同月 , 成汉 将领 李福 袭击 彭模 , 结果 被 孙盛 等 人 击退 ; 而 桓温 三 战三胜 , 一直 逼近 成都 。
我们接着导入停用词表,这里的代码和中文文本挖掘预处理流程总结中一样,如果大家没有1208个的中文停用词表,可以到之前的这篇文章的链接里去下载传送门。
#从文件导入停用词表
stpwrdpath = "stop_words.txt"
stpwrd_dic = open(stpwrdpath, 'rb')
stpwrd_content = stpwrd_dic.read()
#将停用词表转换为list
stpwrdlst = stpwrd_content.splitlines()
stpwrd_dic.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
接着我们要把词转化为词频向量,注意由于LDA是基于词频统计的,因此一般不用TF-IDF来做文档特征。代码如下:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
corpus = [res1,res2,res3]
cntVector = CountVectorizer(stop_words=stpwrdlst)
cntTf = cntVector.fit_transform(corpus)
print cntTf
- 1
- 2
- 3
- 4
- 5
- 6
输出即为所有文档中各个词的词频向量。有了这个词频向量,我们就可以来做LDA主题模型了,由于我们只有三个文档,所以选择主题数K=2。代码如下:
lda = LatentDirichletAllocation(n_topics=2,
learning_offset=50.,
random_state=0)
docres = lda.fit_transform(cntTf)
- 1
- 2
- 3
- 4
通过fit_transform函数,我们就可以得到文档的主题模型分布在docres中。而主题词 分布则在lda.components_中。我们将其打印出来:
print docres
print lda.components_
- 1
- 2
文档主题的分布如下:
[[ 0.00950072 0.99049928]
[ 0.0168786 0.9831214 ]
[ 0.98429257 0.01570743]]
可见第一个和第二个文档较大概率属于主题2,则第三个文档属于主题1.
主题和词的分布如下:
[[ 1.32738199 1.24830645 0.90453117 0.7416939 0.78379936 0.89659305
1.26874773 1.23261029 0.82094727 0.87788498 0.94980757 1.21509469
0.64793292 0.89061203 1.00779152 0.70321998 1.04526968 1.30907884
0.81932312 0.67798129 0.93434765 1.2937011 1.170592 0.70423093
0.93400364 0.75617108 0.69258778 0.76780266 1.17923311 0.88663943
1.2244191 0.88397724 0.74734167 1.20690264 0.73649036 1.1374004
0.69576496 0.8041923 0.83229086 0.8625258 0.88495323 0.8207144
1.66806345 0.85542475 0.71686887 0.84556777 1.25124491 0.76510471
0.84978448 1.21600212 1.66496509 0.84963486 1.24645499 1.72519498
1.23308705 0.97983681 0.77222879 0.8339811 0.85949947 0.73931864
1.33412296 0.91591144 1.6722457 0.98800604 1.26042063 1.09455497
1.24696097 0.81048961 0.79308036 0.95030603 0.83259407 1.19681066
1.18562629 0.80911991 1.19239034 0.81864393 1.24837997 0.72322227
1.23471832 0.89962384 0.7307045 1.39429334 1.22255041 0.98600185
0.77407283 0.74372971 0.71807656 0.75693778 0.83817087 1.33723701
0.79249005 0.82589143 0.72502086 1.14726838 0.83487136 0.79650741
0.72292882 0.81856129]
[ 0.72740212 0.73371879 1.64230568 1.5961744 1.70396534 1.04072318
0.71245387 0.77316486 1.59584637 1.15108883 1.15939659 0.76124093
1.34750239 1.21659215 1.10029347 1.20616038 1.56146506 0.80602695
2.05479544 1.18041584 1.14597993 0.76459826 0.8218473 1.2367587
1.44906497 1.19538763 1.35241035 1.21501862 0.7460776 1.61967022
0.77892814 1.14830281 1.14293716 0.74425664 1.18887759 0.79427197
1.15820484 1.26045121 1.69001421 1.17798335 1.12624327 1.12397988
0.83866079 1.2040445 1.24788376 1.63296361 0.80850841 1.19119425
1.1318814 0.80423837 0.74137153 1.21226307 0.67200183 0.78283995
0.75366187 1.5062978 1.27081319 1.2373463 2.99243195 1.21178667
0.66714016 2.17440219 0.73626368 1.60196863 0.71547934 1.94575151
0.73691176 2.02892667 1.3528508 1.0655887 1.1460755 4.17528123
0.74939365 1.23685079 0.76431961 1.17922085 0.70112531 1.14761871
0.80877956 1.12307426 1.21107782 1.64947394 0.74983027 2.03800612
1.21378076 1.21213961 1.23397206 1.16994431 1.07224768 0.75292945
1.10391419 1.26932908 1.26207274 0.70943937 1.1236972 1.24175001
1.27929042 1.19130408]]
在实际的应用中,我们需要对K,α,η进行调参。如果是"online"算法,则可能需要对"online"算法的一些参数做调整。这里只是给出了LDA主题模型从原始文档到实际LDA处理的过程。希望可以帮到大家。
本部分参考刘建平

