
- 1android_brightness_resolving_android brightnesssliderview
- 2计算机鹅点云,CVPR 2020 | 用于点云中3D对象检测的图神经网络
- 3基于Springboot的疫情物资管理系统(有报告)。Javaee项目,springboot项目。
- 4华为鸿蒙学习笔记_华为 鸿蒙 如何学习
- 5解决wget无法下载GLDAS数据的问题_wget username/password authentication failed.
- 6【后台部署】Windows服务器部署RuoYi-Vue前后端分离项目_win本地怎么运行若依项目
- 7机器学习导论:概念、分类与应用场景
- 8常见异常
- 9鸿蒙开发实例 | ArkUI JS飞机大战游戏开发_鸿蒙版飞机大战
- 10【鸿蒙 HarmonyOS 4.0】开发工具安装_鸿蒙ide工具
python爬虫(上)--请求——关于旅游网站的酒店评论爬取(传参方法)_去哪网 酒店评论 爬虫
赞
踩
前言
最近考试一直都没有时间写这篇总结,现在考试暂告一段落,现在抽空出来写一篇总结,总结一下python爬虫的学习进度。
承接上一篇基于scrapy框架爬虫学习小结,上一篇主要是第二次作业后,“老师说会给我们时间继续完善这个作业,直到可以真的爬到微信朋友圈内容….”,其实之后前面半句是有,但是后面半句真的爬到朋友圈却没有了,老师改变了需求,我们变成了去爬一些旅游网站了。
我们被分派到的任务是:研究分析携程,艺龙,去哪儿,途牛和驴友的爬去规则分析以及爬取他们的酒店评论,我分配到的是携程和艺龙的酒店评论的爬取。
刚开始是我想用之前用过的scrapy来做这个爬取,但是不知道是不是我用的不太熟练,了解不深入,导致一些问题我自己没有办法处理,而且上网搜索的一些答案我都看不懂,之后我才直到,scrapy如果自己没有一定实力,排错很困难。
所以还是回到底层python爬虫实现,凡是要一步步来,因为如果我发现网上许多python爬虫都是用urllib,urllib2,bs4,Request等库来实现的,所以先抛开scrapy框架来,回归一些更加基础的爬虫相关库的学习。
(在进行下面之前请执行pip list查看自己是否已经安装了beautiful soup,lxml,Request和scrapy等第三方库,urllib,urllib2,re和json都是内置库不用考虑,如果没有上面四个第三方库,请用pip install之)
分析要爬取的网站
①携程
http://hotels.ctrip.com/hotel/- 1
上面这个是携程酒店页,广度优先的话就是这一层先完成爬去每个酒店评论页的URL,携程酒店页长这样:
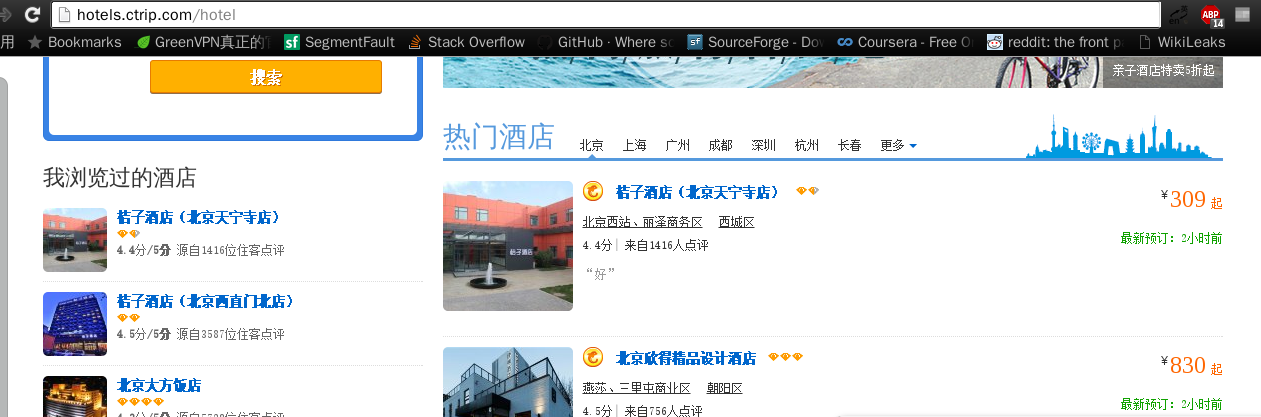
然后再在每个url里面找到评论数据来源再抓下来,这里我们选择上图第一个酒店桔子酒店(北京天宁寺店)为例子,点进去长这样:
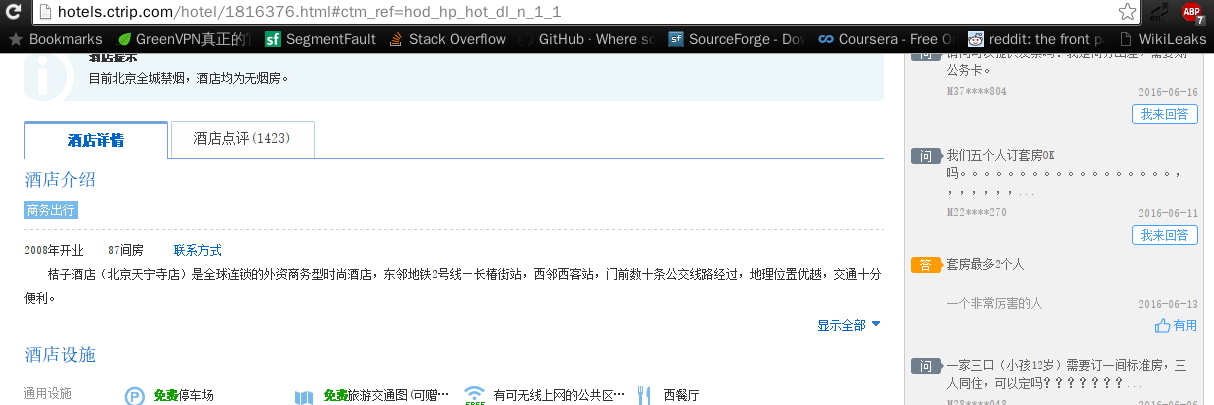
看到图中酒店评论(1423)没有,点开看看:
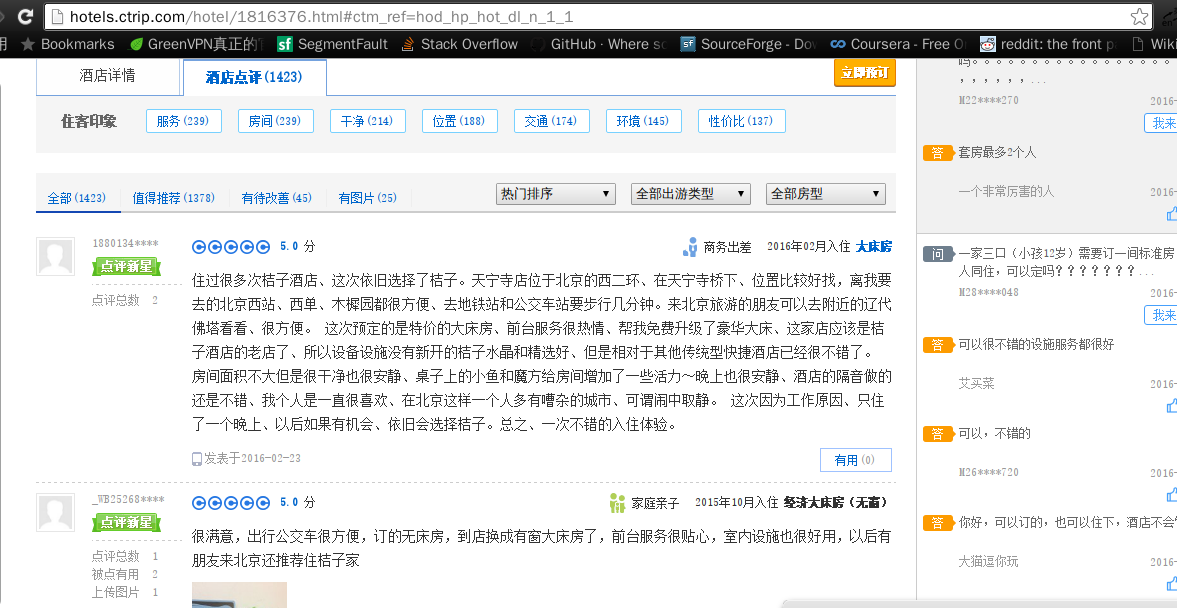
貌似我们的要的评论就近在咫尺,但是当我们打开网页源码我们发现它的评论只有第一页的5条,后面的没有了,那么剩下的评论(第2,第3页…)又是怎么获得的呢?
AJAX:这里就得说说AJAX了,本身什么意思我就不详细说了,我们只要知道AJAX技术是一种异步加载数据的方式,在原来静态网页的天下,每次点击都要重新从服务器再次请求整个网页下来,而其实中间我们需要更新的数据只有一小部分(如果原来请求整个网页是100%的话,那么这一小部分只有5%),这样就造成了大量的带宽浪费,AJAX就是当需要更新部分数据时候,只从服务器加载这一小部分数据,而不用把整个页面又重新下载一遍,AJAX属于前后端数据交互技术,那么我们又要怎么观察AJAX的交互呢?又得如何获得这些动态加载的酒店评论数据呢?我自己用的是chrome所以推荐chrome浏览器自带的开发者工具【Ctrl】+【Shift】+【I】,就可以调出来了,长这样:
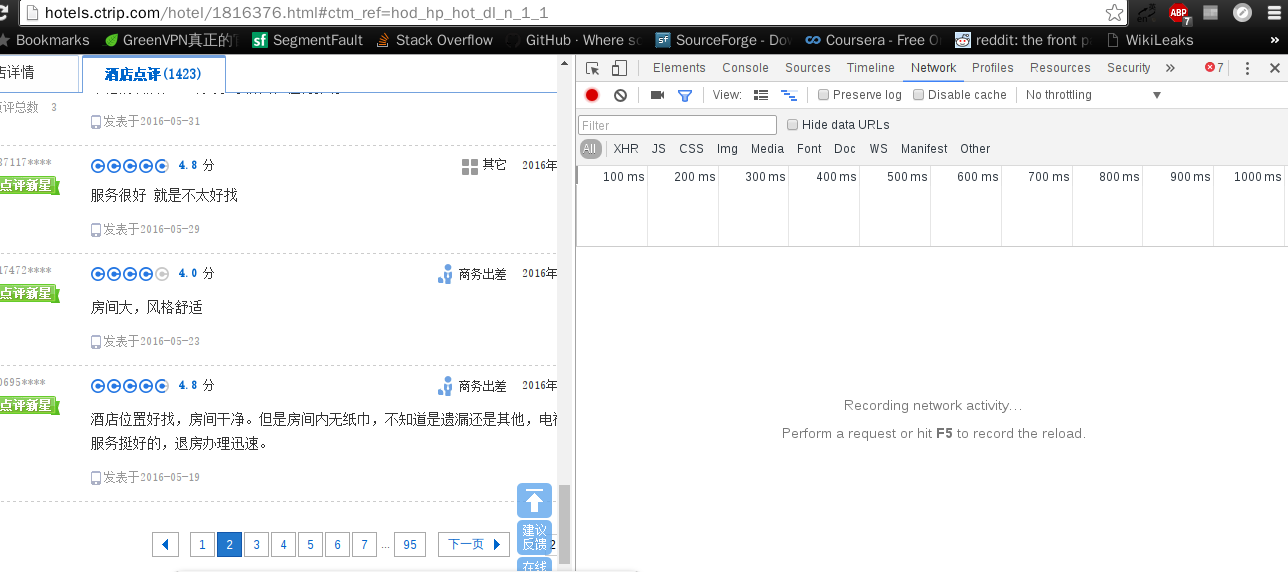
图中我们可以看到现在是评论的第二页,右边啥都没有,先点到Network,再选择筛选器,原来是【All】,现在换成【XHR】(大部分重新加载的AJAX在浏览器中都属于XHR类,当然有部分还可能在JS 类中),这样更加方便找出通过AJAX加载的更新数据,接下就刷新一下页面,让它重新加载第二页评论,结果如图:
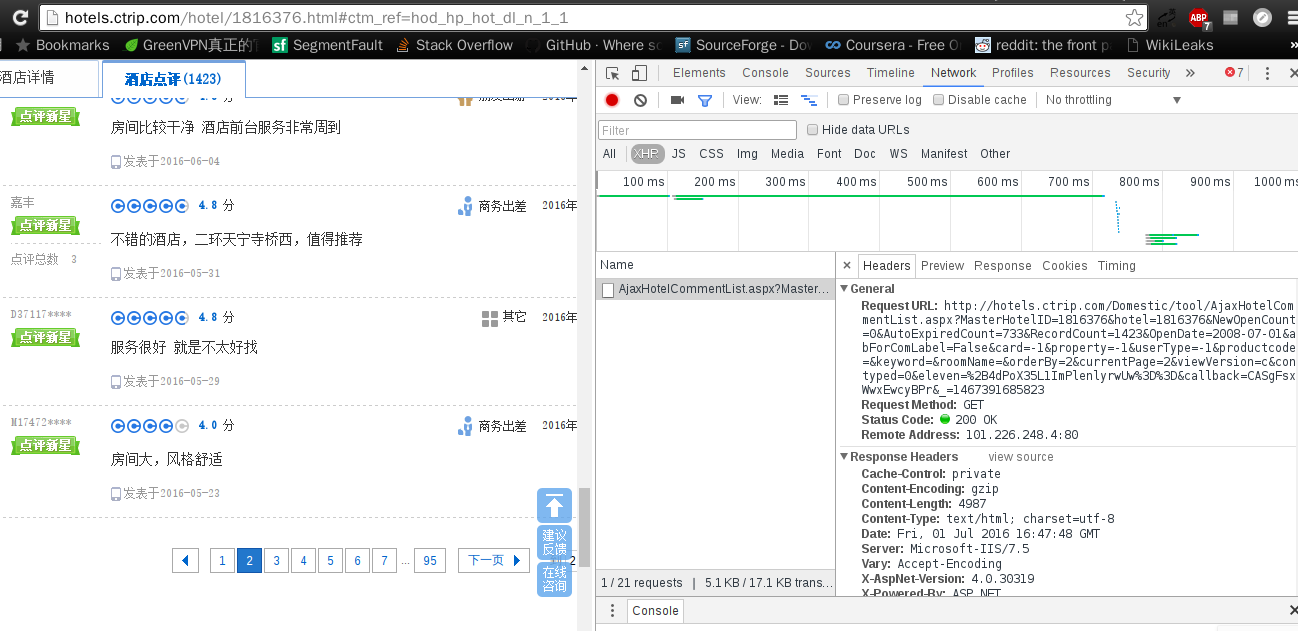
P.s.我这里试了一下,直接刷新会回到最开始的这个页面。最好的办法就是,先点进酒店评论(1420),此时为第一页,打开chrome的开发者工具,选择XHR筛选器,然后点击下一页,就会得到一模一样的上图
我们可以看到,在右侧的这个URL的内容里面有很多有价值的信息,有Request URL,往下翻,可以看到Reques Headers(Cookie,Referer,User-Agent等伪装头部必备元素~)内容,这里上张图更清晰:
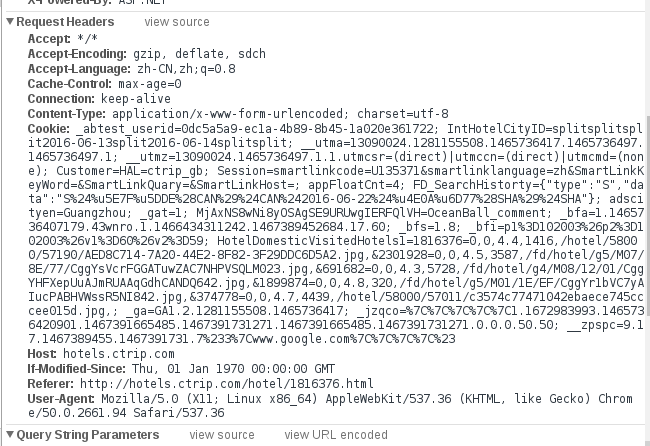
一般来说,通过Request URL,我们就可以抓到更新加载的评论数据了,但是这个URL打开

