- 1Linux中likely 函数的使用分析_if(lickly)
- 2linux centos7中使用 Postfix 和Dovecot搭建邮件系统
- 3Linux split分割xls或csv文件
- 4AMDET: Attention based Multiple Dimensions EEG Transformer for Emotion 论文精读_brainemotions
- 5【LLM GPT】李宏毅大型语言模型课程_李宏毅 llm
- 6GIS遥感专栏02:ENVI深度学习模块实现水质提取
- 7四种常见的Web攻击手段及其防御方式_web威胁防护四种技术
- 8前端js和react面试题及答案_react.js考试填空题
- 9kaggle比赛流程(转)
- 10shortcut icon地址栏显示个性图标_shortcut icon bookmark
【论文+综述+视觉换衣】视觉虚拟换衣调研:StableVITON、OutfitAnyone、TryOnDiffusion、HR-VITON
赞
踩

23.12.StableVITON (韩国科学技术院 KAIST):基于潜在扩散模型的虚拟试穿语义对应学习:Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
23.12.OutfitAnyone(阿里未开源): 超高质量的虚拟试穿,适合任何服装和任何人: Outfit Anyone: Ultra-high quality virtual try-on for Any Clothing and Any Person
23.06.TryOnDiffusion: (Google未开源)基于diffusion的试穿模型: 2个Unet网络的故事 (阿里着重参考)
A Tale of Two UNets:项目地址 | 论文
22.11 Paint by Example: 将换衣作为去除衣服后的填充方法 Exemplar-based Image Editing with Diffusion Models
22.06 HR-VITON:(韩国科学技术院开源) High-Resolution Virtual Try-On with Misalignment and Occlusion-Handled Conditions | code
21.03 VITON-HD: (韩国科学技术院开源) High-Resolution Virtual Try-On via Misalignment-Aware Normalization | code
VITON-HD数据集下载:https://opendatalab.com/OpenDataLab/VITON-HD
产品—沃尔玛的虚拟衣服试穿:https://www.walmart.com/cp/virtual-try-on/4879497
文章目录
从最新的论文到旧的,更能理解一些参数意义与发展
23.12stable-Viton与其他方法的对比

23.06 TryOnDiffusion与其他效果对比

23.12 StableVITON (半开源,模型需要申请,没有训练代码)
项目主页 | 论文 | 代码
Learning Semantic Correspondence with Latent Diffusion Model for Virtual Try-On
简介
换衣结果:
VITON-HD 数据集中的图片(第一行(以换衣后人物为一行))、
SHHQ-1.0(第二行的前两幅图像)和网络爬取图像(第二行的最后两个图像)。
所有结果都是使用在VITON-HD数据集上训练的StableVITON生成的。

方法
本文将虚拟试穿作为一个基于范例(exemplar)的图像修复(image inpainting)问题(用需要换的衣服来填充去掉衣服的人), 灵感来源于: 22.11 Paint by Example: Exemplar-based Image Editing with Diffusion Models
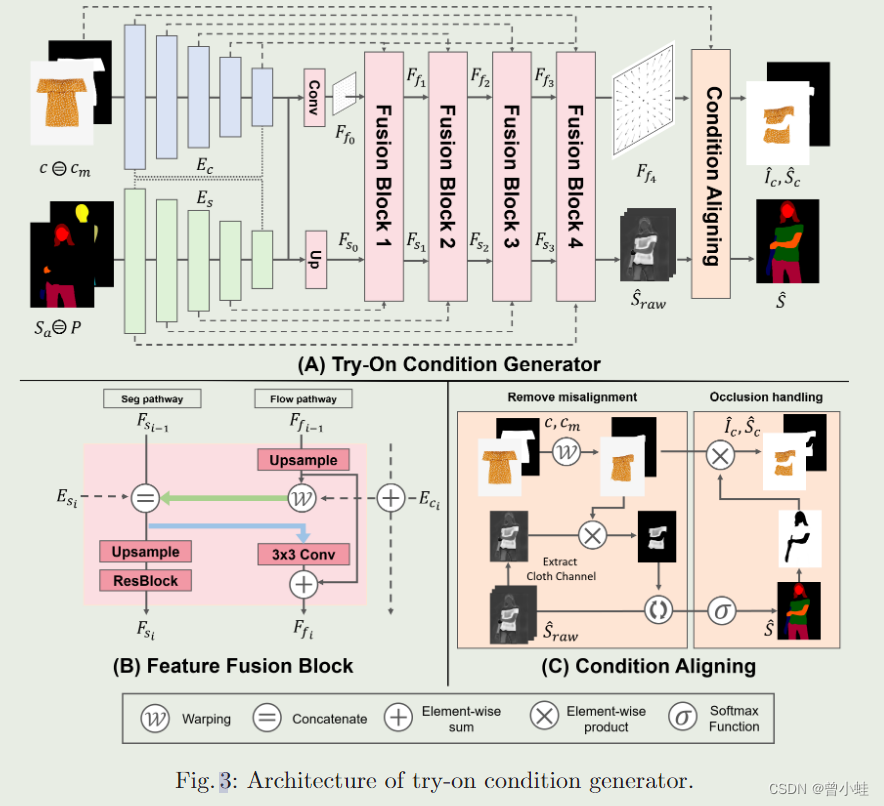
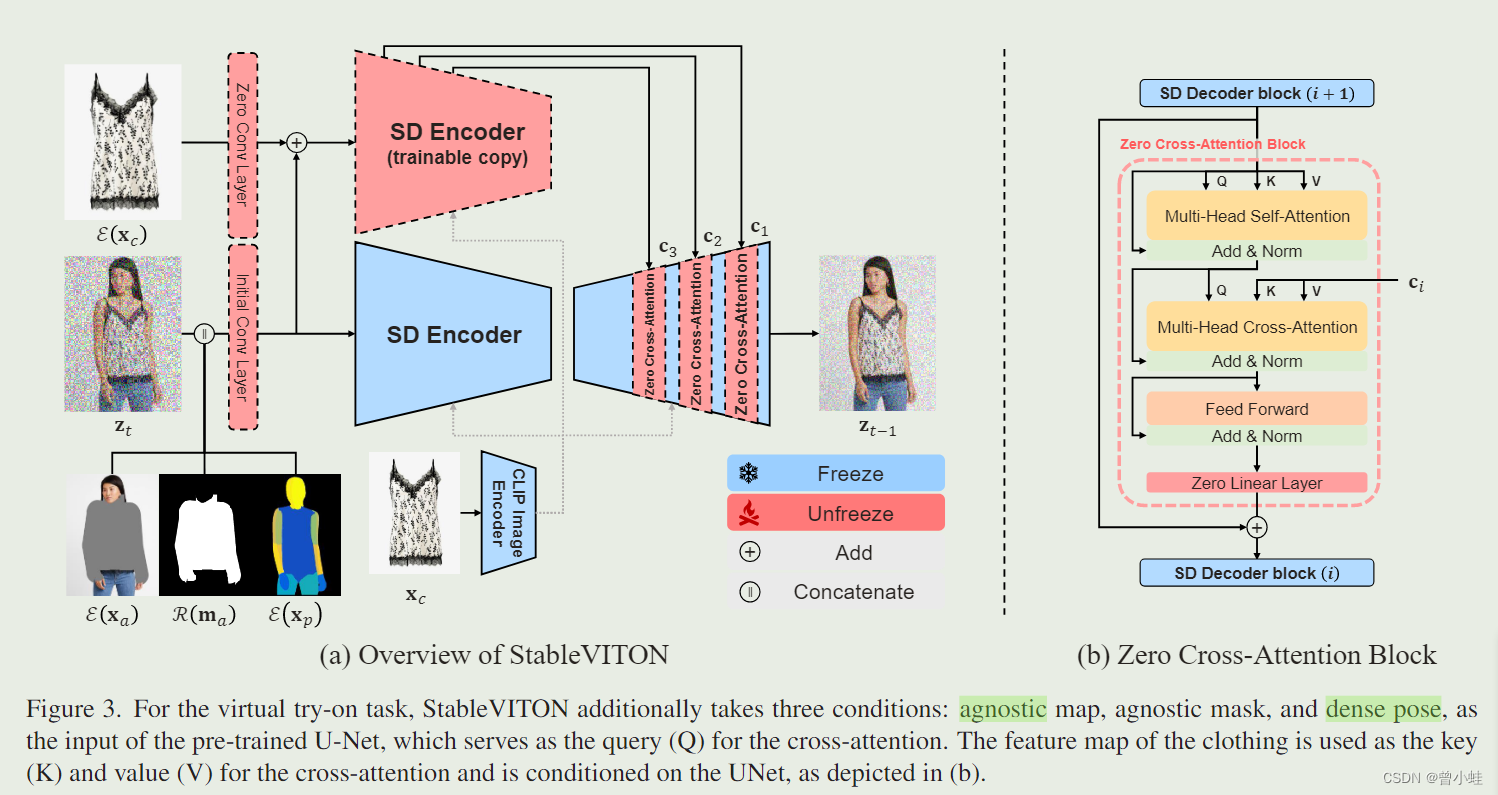
对于虚拟试穿任务,StableVITON还采用三个条件(通过预处理得到):不可知衣服的人(agnostic map(消除需要换装人的任何服装信息))、不可知掩码(mask)和密集分割图(dense pose),作为预训练U-Net的输入,U-Net用作交叉注意力的查询向量(Q)。服装的特征图被用作交叉注意力的关键点(K)和值(V),并以UNet为条件,如(b)所示。
为了保持服装的精细细节,我们引入了空间编码器(spatial encoder,图中可训练的SD encoder),对服装进行编码,并通过zero-cross-attention 作为条件与预训练preprain相连
23.12 OutfitAnyone (未开源、无论文):
在线运行:https://modelscope.cn/studios/DAMOXR/OutfitAnyone/summary

Outfit Anyone: Ultra-high quality virtual try-on for Any Clothing and Any Person
超高质量的虚拟试穿,适合任何服装和任何人
现有方法往往难以生成高保真(high-fidelity)和细节一致的(detail-consistent)结果。
扩散模型已经证明了其生成高质量逼真图像的能力,但在虚拟试穿等条件生成场景中,它们在实现控制和一致性(control and consistency)方面仍面临挑战。
Outfit Anyone 利用双流条件扩散模型(two-stream conditional diffusion model)解决了这些局限性,使其能够巧妙地处理服装变形(garment deformation),从而获得更逼真的效果。
它的与众不同之处在于可扩展性–可调节姿势和体形等因素(modulating factors such as pose and body shape)–以及广泛的适用性,从动漫到现实场景图像
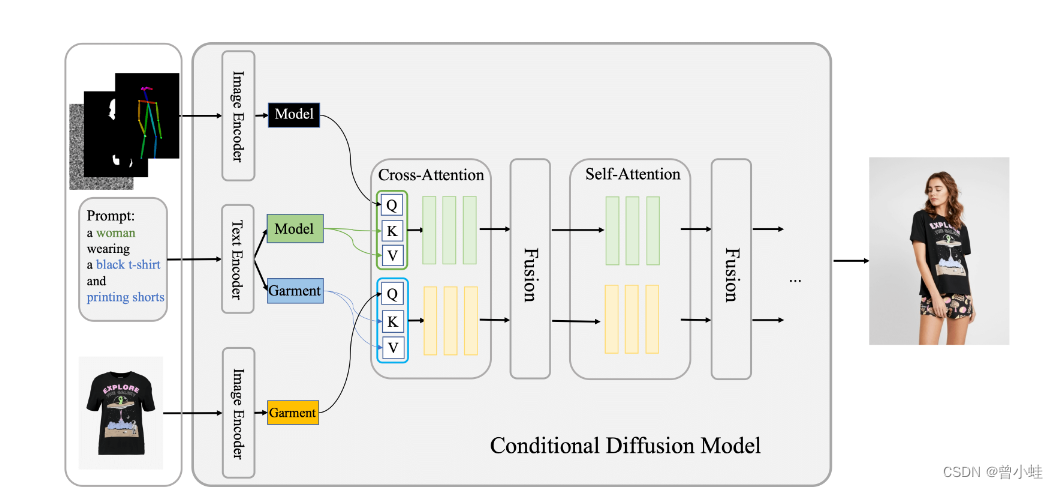
outfit-anyone 部分方法概述
条件扩散模型是本方法的核心,使用服装图像(garment image)作为控制因素,处理模特、服装和附带文本提示的图像。在内部,该网络分为两个流,用于独立处理模特(试穿者,model)和服装数据。这些流汇聚在一个融合网络中,该融合网络有助于将服装细节嵌入到模特(试穿者)的特征表示中。
训练完成后的推理
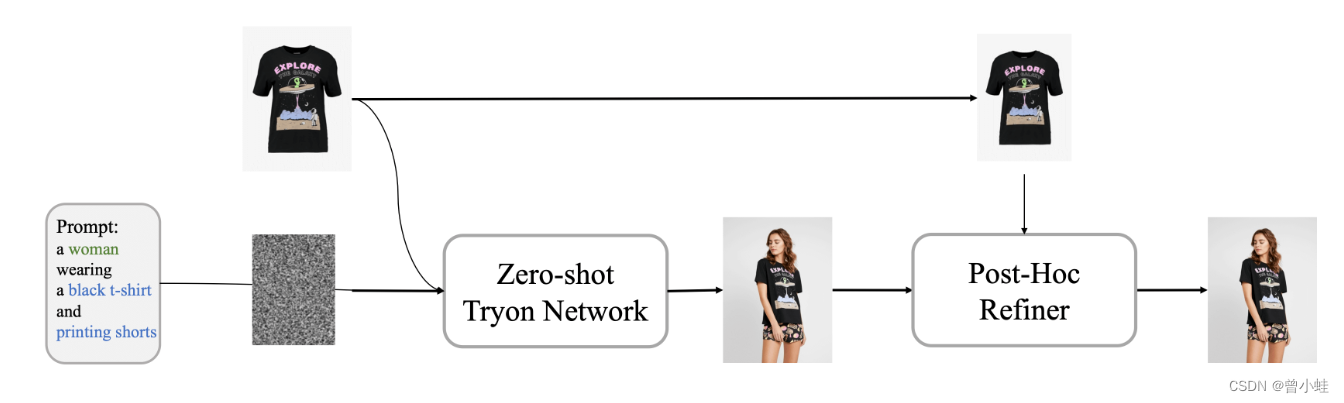
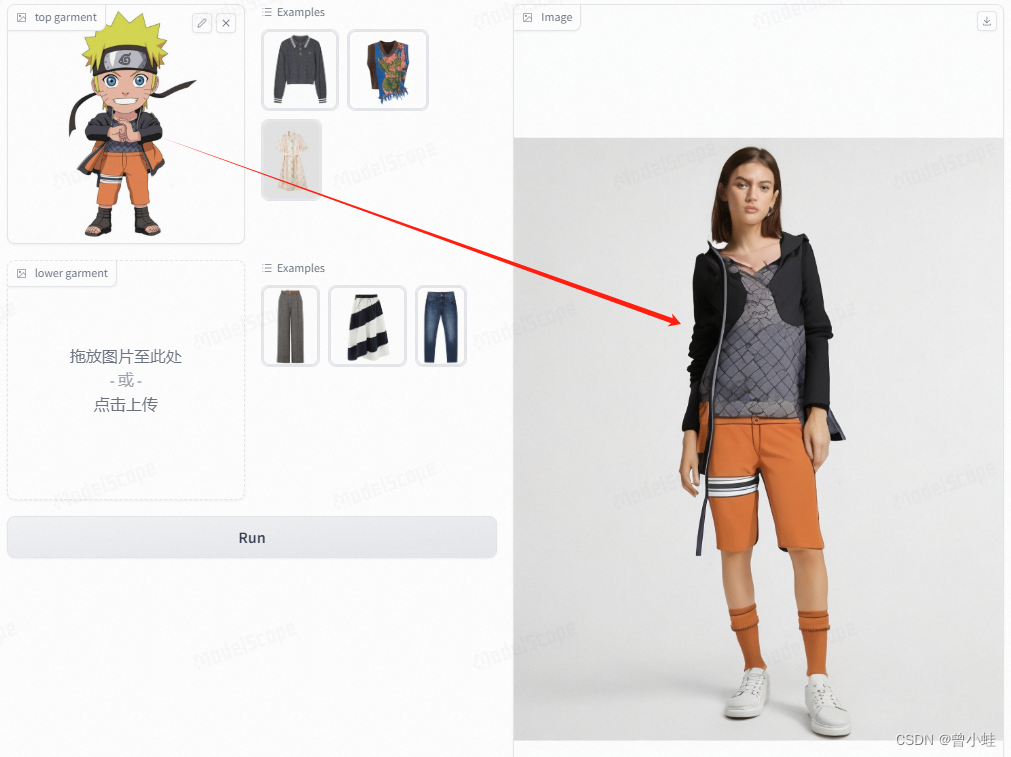
实测 (可上传图片,自动提取到衣服)
在线测试:https://modelscope.cn/studios/DAMOXR/OutfitAnyone/summary
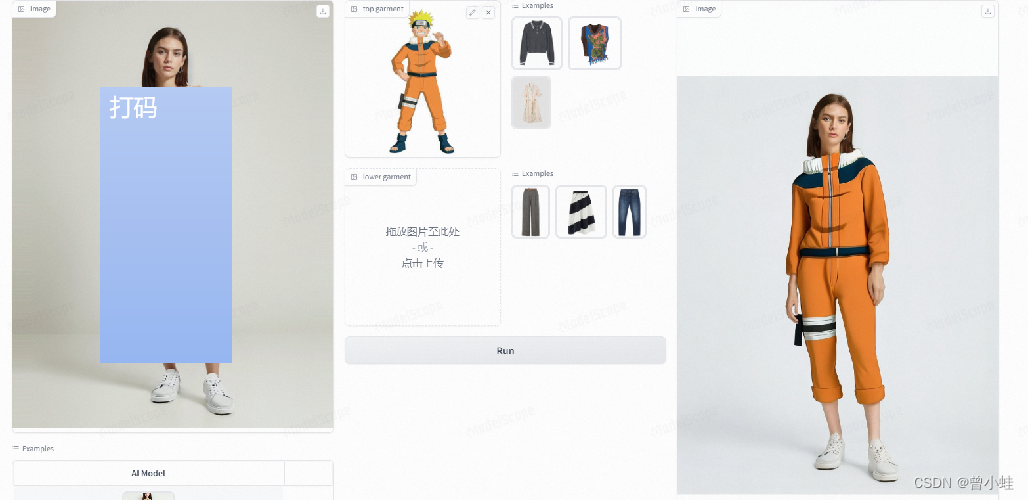
有遮挡的衣服测试(无法还原衣服)
2306. TryOnDiffusion(未开源)项目地址 | 论文
生成具有显着身体形状和姿势变化、(body shape and pose )、大遮挡(large occlusions)的服装试穿结果,同时保留 1024×1024 分辨率的服装细节。
输入显示在生成结构右上角(需要换装的人,已经穿着衣服的另一个人)
并在姿势和身材变化大时,对衣服的图片和纹理褶皱进行相应变化(当姿势或身体形状差异很大时,服装需要以根据新的形状或遮挡创建或展平皱纹的方式扭曲。)

方法
在400万的图像对进行训练。
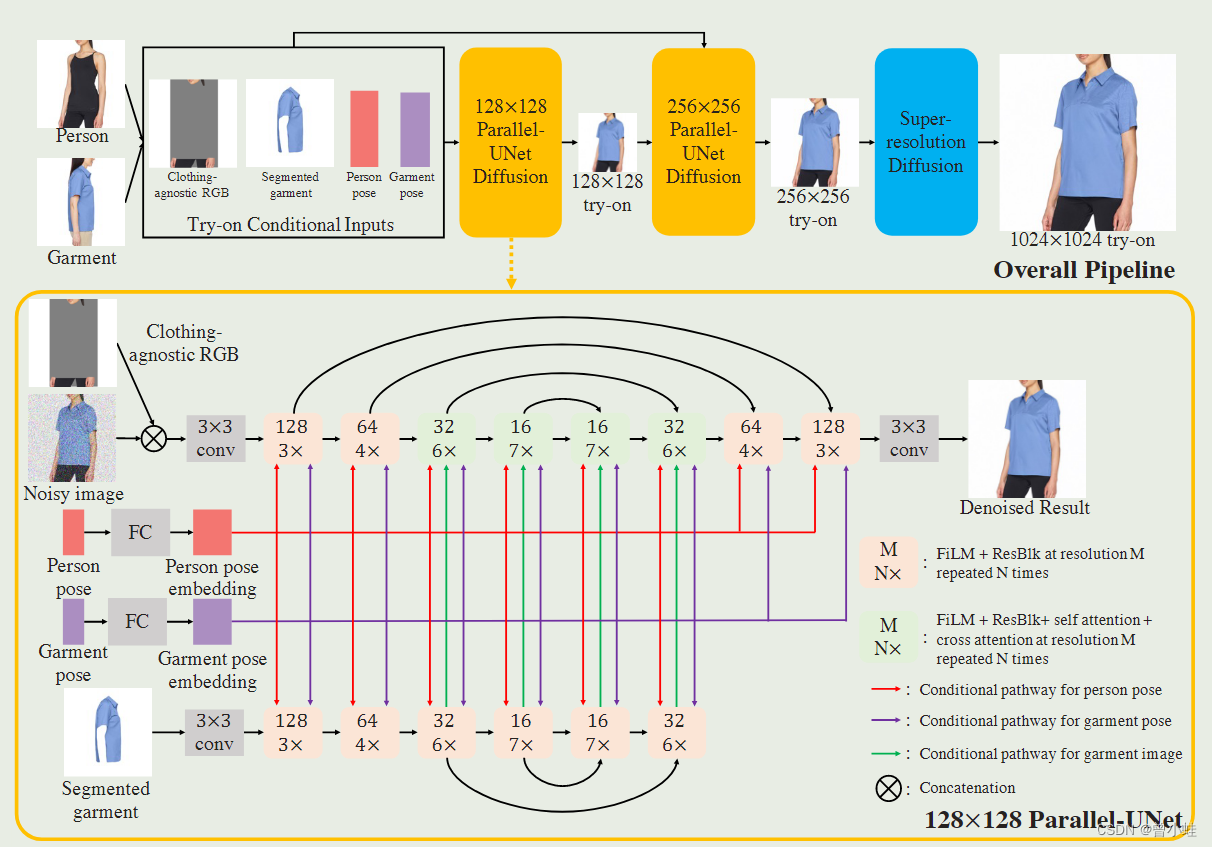
采用了2个并行Unet(Parallel-UNet)网络:通过交叉注意进行通信
服装通过交叉注意机制隐式(implicitly)变形(以适应新的身体和角度),
目标人和源服装是通过多尺度特征交叉注意它们的来实现的,这允许建立远程对应。
- 在
预处理步骤中,目标人物(去除原始衣服后)处理成 “服装不可知RGB”图像(“clothing agnostic RGB” )目标服装从服装图像中分割出来,并对原始换衣人和服装图像计算姿态。 - 这些输入被视为128×128 Parallel-UNet(注意力机制中的key),以创建128×128试穿图像,这些图像进一步作为输入发送到256×256 Parallel-UNet,以及试穿条件输入。
- 256×256 Parallel-UNet的输出被发送到
标准超分辨率扩散模型以创建1024×1024图像(为了在1024×1024分辨率下生成高质量的我们遵循Imagen:22.03.Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)
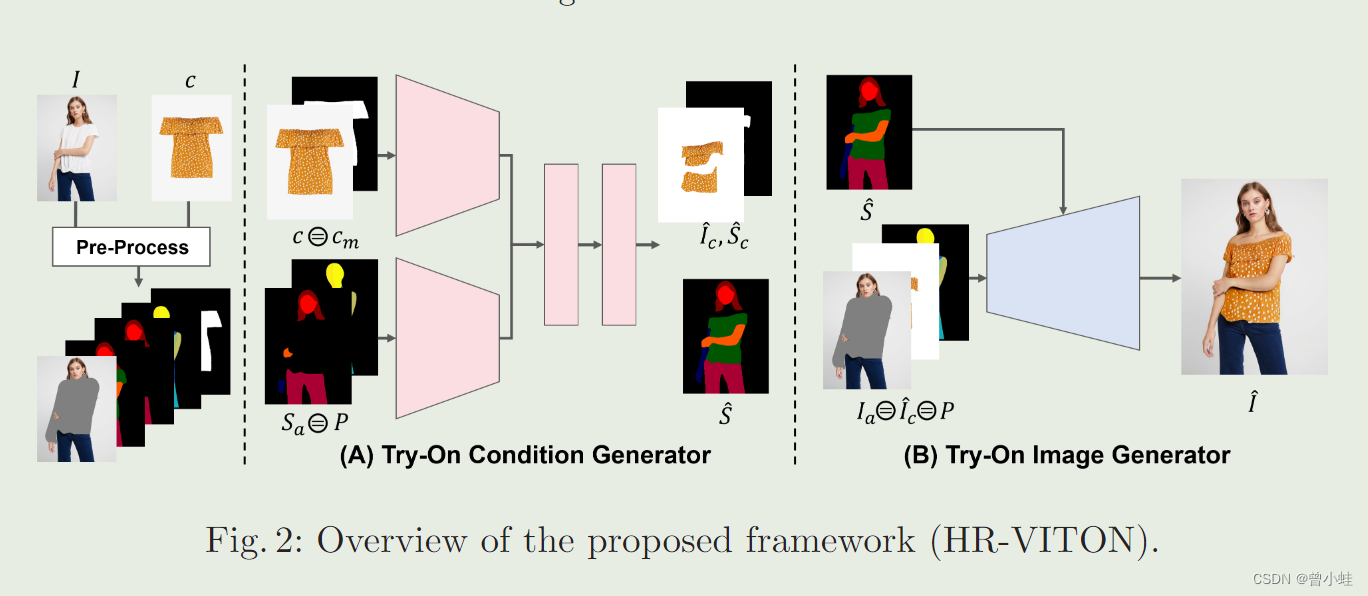
22.06 HR-VITON:错位和遮挡条件下高分辨率虚拟试穿
(韩国科学技术院开源) High-Resolution Virtual Try-On with Misalignment and Occlusion-Handled Conditions | code

方法概述
总框架
生成器详细的结构