
- 1深度学习-TokenEmbedding-安装torch-GPU版本_token3embedding
- 2安装完Python包然后找不到模块问题解决
- 3java rabbitmq 工具类_common-project: Java后端常用工具类、缓存接口、消息队列接口、第三方支付接口封装;Restful接口参数验证,错误信息友好提示。...
- 4【selenium基础】设置浏览器Cookie及Token,记住密码免登陆_selenium 记住用户名密码
- 5大创项目推荐 深度学习 python opencv 火焰检测识别
- 6python实现词云图_python实现词云图
- 7微信工具箱小程序源码-多功能集合一体工具箱_小程序工具箱源码百度云资源下载
- 8Androidstudio ADB调试_andriod studio canary11 adb 调试
- 9利用jieba库进行词频统计
- 10Android Bluetooth架构_com.android.bluetooth
人脸检测与对齐之MTCNN网络_mtcnn 人脸对齐
赞
踩
本文将对人脸检测MTCNN算法做一个简要介绍。该MTCNN算法出自深圳先进技术研究院乔宇老师组,是今年2016的ECCV。
论文原文:https://kpzhang93.github.io/MTCNN_face_detection_alignment/paper/spl.pdf
论文译文:https://blog.csdn.net/lff1208/article/details/77328357
GitHub tensorflow源码:https://github.com/AITTSMD/MTCNN-Tensorflow
GitHub matlab版本:https://github.com/kpzhang93/MTCNN_face_detection_alignment
GitHub 基于caffe的C++ API 的源码:https://github.com/DaFuCoding/MTCNN_Caffe
这个GitHub上是原始的caffe,再加上了MTCNN的部分(一个源文件+8个训练好的caffemodel以及deploy文件),大家可以clone到本地从头编译。编译完后,生成一个可执行文件,路径为 build/examples/MTSrc/MTMain.bin ,这个可执行文件需要额外的两个参数,第一个是上面的8个文件所在目录(caffe/examples/MTmodel/),第二参数就是测试图片了。这里我们先运行下demo,将一张图片放到caffe目录下(放哪都行),然后转到caffe根目录下,运行 ./build/examples/MTSrc/MTMain.bin /examples/MTmodel/ 1.jpg 然后很快就出结果了,检测到人脸,以及五个特征点(两只眼睛,鼻子,左嘴角和右嘴角),具体demo展示可看GitHub的步骤。
MTCNN算法有三个阶段组成:第一阶段,浅层的CNN快速产生候选窗体;第二阶段,通过更复杂的CNN精炼候选窗体,丢弃大量的重叠窗体;第三阶段,使用更加强大的CNN,实现候选窗体去留,同时显示五个面部关键点定位。
一、总体架构
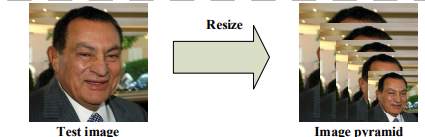
本算法的整体流程如下图所示:
①做图片的金字塔:顶端金字塔最小应该大于12 * 12
② 将每个金字塔的图片输入到P网络(在人脸的地方会有大量的框,),进而输出所有框的置信度定义一个置信度:大于此值为人脸(因为是初选,置信度定义不易过大,):得到5个通道的特征图:第一个通道代表置信度:凡是大于0.7的留下来然后。反算回去:IDX(特征图的索引)*步长=进入P网络图的尺寸,然后除以原图的比例,得到建议框(为正方形),另外四个通道为位置的偏移:(X-X') / W = offset_X,得到原框X。然后通过非大值抑制,将多余的框去掉,(不在建议框做NMS的原因是因为建议框往往是个正方形,框的位置往往会过大,会过滤的不该过滤的信息)
③将PNet的结果,输入到R网络(图片大小固定:24 * 24):由于得到的原框大小可能为长方形,所以需要在原图上接一个正方形,然后在等比例缩放,保证得到的24×24的人脸不会变形。然后重新确定位置的偏移,得到新的框,再做NMS.
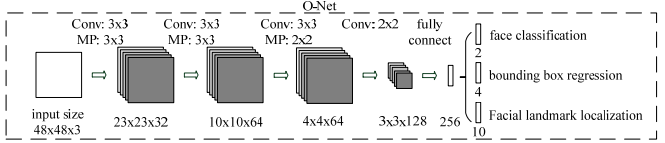
③ 将RNet输出结果,输入ONet网络(图片大小固定为48×48)

如上图所示,该MTCNN由3个网络结构组成(P-Net,R-Net,O-Net)。
- Proposal Network (P-Net):该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量。并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。
- Refine Network (R-Net):该网络结构还是通过边界框回归和NMS来去掉那些false-positive区域。只是由于该网络结构和P-Net网络结构有差异,多了一个全连接层,所以会取得更好的抑制false-positive的作用。
- Output Network (O-Net):该层比R-Net层又多了一层卷积层,所以处理的结果会更加精细。作用和R-Net层作用一样。但是该层对人脸区域进行了更多的监督,同时还会输出5个地标(landmark)。
先对图像进行多尺度变换,获取图像金字塔,获取图像多尺度信息,金字塔顶端图像尺寸大于12*12。
二、网络架构
1、P-net(Proposal Network):
主要使用一个全卷积网络, 先对图像进行多尺度变换,获取图像金字塔,获取图像多尺度信息。获取候选框和这些候选框的bounding box regression向量组。然后评估这些候选向量,并进行校准。最后使用非极大化抑制来去除大量重复的候选区域。

输入:待检测的图像;
输出:m*n(最终特征图的尺度)个box坐标回归值以及对应的是否为人脸的得分。经过进一步的计算,得到可能为人脸的box集合,如图红色框:


中间过程简述:将原图建立金字塔,得到一系列尺寸的待检测图。对于每一张待检测图(1、一种可以基于滑动框来扫描金字塔中所有的图像,滑动框尺寸为12*12,是P-Net的输入尺寸,2、另一种可以直接将整幅图像输入PNet,因为他是全卷积网络,不限输入尺寸,输出n*n*32的特征图,每个1*1*32对应一个12*12的框的检测结果),输入到PNet,会输出一系列box,去掉那些得分(score)不达标的box,并用非极大值抑制(nms)再去掉一部分box。对于所有尺寸的待检测图,都得到类似的box集合。将所有box集合合并,再用nms去除一部分box,余下的就是第一阶段最终的输出。
训练:
输入是12*12*3的图片,以及标签 = 样本类型0/1/-1 + 四个数字为一组的crop_box与真实box之间的偏差,成为回归框(bounding box regressiom)
P-Net主要用来生成一些候选框(bounding box)以及lable。在训练的时候该网络的顶部有3条支路用来分别做人脸分类、人脸框的回归和人脸关键点定位;在测试的时候这一步的输出只有N个bounding box的4个坐标信息和score,score可以看做是分类的输出(是人脸的概率),源代码中输出就是sigmoid函数值。
PNet训练数据
1、遍历数据集,在每一张照片的基础上:
一张照片可能有多张人脸,所以有boxes。由一张照片裁剪出50张不同的大小为12*12的照片,如果Iou值小于0.3,就写入nagetive样本文件中。具体方法:在一张照片的基础上随机生成crop_box,计算crop_box与boxes的Iou,然后按照crop_box的尺寸剪切原图片并缩放成12*12大小的图片,转换成12*12*3的结构,根据Iou对新生成的照片归类。
2、遍历第一步中的那一张照片的所有boxes,在每个box的基础上:
# generate negative examples that have overlap with gt
加入随机数,随机生成crop_box,根据Iou值,写入pos或part样本文件中;
计算crop_box与box之间的偏差,把这些偏差称为回归框,生成的训练数据的标注lable不仅有positive/part,还要加上回归框信息。计算crop_box与boxes的Iou进行归类。
compute bbox reg label,其中x1,x2,y1,y2为真实的人脸坐标,x_left,x_right,y_top,y_bottom,width,height为预测的人脸坐标,如果是在准备人脸和非人脸样本的时候,x_left,x_right,y_top,y_bottom,width,height就是你的滑动窗与真实人脸的IOU>0.65(根据你的定义)的滑动窗坐标。
# dface代码中box用的是正方形,即size=width=height代表box窗口的边长
- offset_x1 = (x1 - x_left) / float(width)
- offset_y1 = (y1 - y_top) / float(height)
- offset_x2 = (x2 - x_right) / float(width)
- offset_y2 = (y2 - y_bottom ) / float(height)
其中x1,x2,y1,y2为真实的人脸坐标,x_left,x_right,y_top,y_bottom,width,height为预测的人脸坐标,
3、最后的输出
negative样本:IOU < 0.3,标签为:0 0 0 0 0
positive样本:IOU > =0.65,标签为:1 0.01 0.02 0.01 0.02
part样本:0.4 <= IOU < 0.65,标签为: -1 0.03 0.04 0.03 0.04
mtcnn的label加了回归框的偏差量,标签的第一个数0,1,-1,代表了三类人脸,后面的四个值,指的是回归框的偏移量,负样本没有偏移量,所以全为0。
乱序合并标注文件,将三个样本文件合并到一个文件 PNET_TRAIN_IMGLIST_FILENAME = "imglist_anno_12.txt"
from:https://blog.csdn.net/A18730290353/article/details/88366573
二、第二阶段:RNet
R-Net,将经过P-Net确定的包含候选窗体的图片在R-Net网络中训练,网络最后选用全连接的方式进行训练,全连接层可以进行更细化的处理,排除掉大量不符合要求的候选区域,通过bounding box regression执行校准微调候选窗体,利用非极大化抑制( NMS)进行合并去除重叠窗体。

输入:R-Net和P-Net类似,输入是前面P-Net生成的边界框,每个边界框的大小都是24*24,可以通过缩放得到。网络的输出和P-Net是一样的。这一步的目的主要是为了去除大量的非人脸框。第一阶段生成的box,在原图中截取对应的区域,将所有截取得到的图像合并到一个四维矩阵中,作为RNet的输入。
输出:对于输入的每个box,输出其对应的坐标回归值以及对应的是否为人脸的得分。将得分不达标的box去掉,得到第二阶段的box集合。也就是说,第二阶段是在第一阶段的基础上对box实现进一步分筛选,同时也会以通过回归将box坐标进行更新,使得其精度更高。如图:

第三阶段:ONet
O-Net网络结构比R-Net多一层卷积,功能与R-Net作用一样,只是在去除重叠候选窗口的同时,显示五个人脸关键点定位。
输入:类似于RNet,但以第二阶段的输出得到的人脸图像。
输出:N*(2*5)个坐标值。其中N是人脸的数目,每个人脸检测5个关键点。
注意点:
- CNN输出的不是坐标,而是坐标的回归量(偏移量??),实际的坐标是要通过进一步计算得到的。可以参考bbreg.m文件
- 第一阶段生成box的时候,用到了generateBoundingBox函数,是从特征图上映射到原图得到box的。如下
- 将一张图像输入到PNet,可以输出m*n组box回归值(每组4个数)及其对应的score;而一张图像输入到RNet,仅会得到1组box回归值及其score(这个原因是卷积层和全连接层的区别)。
from:https://blog.csdn.net/wshdkf/article/details/79956976
采用PReLU激活函数:

如果ai=0,那么PReLU退化为ReLU;如果ai是一个很小的固定值(如ai=0.01),则PReLU退化为Leaky ReLU(LReLU)。 有实验证明,与ReLU相比,LReLU对最终的结果几乎没什么影响
三、网络的训练
本算法从三个方面对CNN检测器进行训练:人脸分类、边界框回归、特征点定位(关键点定位)。
3.1、人脸分类
对于每一个输入样本采用交叉熵损失函数:
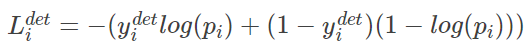
上述公式中的表示是人脸的概率,其中
,表示真实标签,在这一步中损失函数的计算,我们只用到正样本和负样本
3.2、边框回归
对于每一个候选框,需要预测它和真实坐标偏移之间的损失。对于每一个样本通过欧式距离进行回归,在这一步中损失函数的计算,我们只用到正样本和part样本:
![]()
上式为通过欧氏距离计算的回归损失。其中,带尖的y为通过网络预测得到偏移量,不带尖的y为实际的真实坐标的偏移量。y为一个(offset_x1,offset_y1,offset_x2,offset_y2)组成的四元组,每一个box是一个4维向量。
回归框偏移值计算:考虑到直接采用坐标信息进行回归框的预测,网络收敛比较慢。所以在回归框预测的时候一般采用回归框的坐标偏移进行预测,所以上面的y都是偏差量,而不是实际坐标。
训练样本生成时:生成滑动窗口样本后,对应滑动窗口样本和Guarant True Box的偏移值,即可算出来,如下所示:
- offset_x1 = (gx1 - x1) / float(x2-x1)
- offset_y1 = (gy1 - y1) / float(y2-y1)
- offset_x2 = (gx2 - x2) / float(x2-x1)
- offset_y2 = (gy2 - y2) / float(y2-y1)
这样生成滑动窗口的时候,对正样本及中间样本,同时保存相应的offset值,如下所示:
- positive/0.jpg 1 0.02 -0.01 -0.20 -0.06
- positive/1.jpg 1 0.08 0.04 -0.18 -0.06
- positive/2.jpg 1 0.16 0.10 -0.03 0.09
- positive/3.jpg 1 0.00 -0.04 0.08 0.28
- positive/4.jpg 1 0.08 0.03 -0.12 0.01
3.3、特征坐标定位
与候选框回归类似,还是计算候选特征坐标偏移量和真实坐标的偏移量的欧式距离,并最小化此距离;在这一步中损失函数的计算,我们只用到landmark样本:
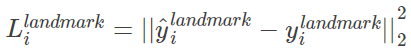
上述五点特征包括:左眼、右眼、鼻子、左边嘴角、右边嘴角。每个特征点均有两个偏移量组成,带尖的y为通过网络预测得到,不带尖的y为实际的特征点坐标与人脸框的偏移量,y是一个10维的向量。
面部轮廓关键点回归值:人脸的面部轮廓关键点不采用绝对坐标,同样使用的是回归值,不过该回归值对应的是Bounding Box的相对坐标。生成方法类似于回归框的方式,在guarand true landmark点上加上一个随机偏移量,然后再计算offset值。相应的计算公式如下所示:
- offsetX=(lx-x)/bbox_width
- offsetY=(ly-y)/bbox_height
对所有的landmark点计算offset后生成如下数据:
- train_PNet_landmark/0.jpg -2 0.288961038961 0.204545454545 0.814935064935 0.262987012987 0.535714285714 0.659090909091 0.275974025974 0.853896103896 0.724025974026 0.905844155844
- train_PNet_landmark/1.jpg -2 0.42816091954 0.215517241379 0.89367816092 0.26724137931 0.646551724138 0.617816091954 0.416666666667 0.790229885057 0.813218390805 0.836206896552
- train_PNet_landmark/2.jpg -2 0.153125 0.271875 0.659375 0.328125 0.390625 0.709375 0.140625 0.896875 0.571875 0.946875
- train_PNet_landmark/3.jpg -2 0.174327367914 0.242510936232 0.673748423293 0.342669482766 0.372792971258 0.69904560555 0.10740259497 0.864043175755 0.532653771385 0.95143882472
3.4、多源训练
训练过程中,有人脸非人脸的照片,部分人脸区域。所以上述的三个损失函数可能有的没有必要使用。所以整体的损失函数如下:
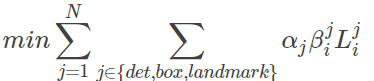
在P_Net和R_Net中设置 : ![]()
在O_net中设置: ![]()
其中N是样本集大小,其中表示任务的优先级,
∈{0,1}表示样本标签,
表示上面三步的损失函数。在训练过程中,为了取得更好的效果,作者每次只后向传播前70%样本的梯度,这样来保证传递的都是有效的数字。有点类似latent SVM,只是作者在实现上更加体现了深度学习的端到端。
四、training data的处理:
原始数据
该算法训练数据来源于wider和celeba两个公开的数据库,wider提供人脸检测数据,在图上标注了人脸框groundtruth的坐标信息,celeba提供了5个landmark点的数据。根据参与任务的不同,将训练数据分为四类:
- 负样本:滑动窗口和Ground True的IOU小于0.3;
- 正样本:滑动窗口和Ground True的IOU大于0.65;
- 中间样本:滑动窗口和Ground True的IOU大于0.4小于0.65;
- 关键点:包含5个关键点坐标的;
上面滑动窗口指的是:通过滑动窗口或者随机采样的方法获取尺寸为12*12的框:
wider数据集,数据可以从http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/地址下载。该数据集有32,203张图片,共有93,703张脸被标记,如下图所示:
人脸数据集widerface,该数据集仅提供了大量的人脸边框定位数据。如果使用wider face的 wider_face_train.mat 注解文件需要转换成txt格式的,在注解文件wider_origin_anno.txt格式如下 :
0--Parade/0_Parade_marchingband_1_849.jpg 448 329 570 478
0--Parade/0_Parade_marchingband_1_117.jpg 68 359 118 394 226 382 282 425 295 304 339 330 353 279 393 315 884 377 947 418 818 390 853 434 727 341 764 372 598 246 631 275 740 308 785 341
每四个数字代表该图片中的一个人脸边框定位数据x1, y1, x2, y2(x_left, y_top, x_right, y_bottom),第一张照片有只一个人脸,第二张照片有9个人脸。
celeba(səˈleb)人脸关键点检测的训练数据,数据可从http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm地址下载。该数据集包含5,590张 LFW数据集的图片和7,876张从网站下载的图片。
trainImageList.txt存放的是每个图片中的人脸框坐标和对应的五个特征点坐标,因此我们知道一个完整的人脸有14个参数(2个角点坐标,5个特征点坐标)。例如:![]()
训练采用四种类型的数据:
1、备选区域和目标区域的重叠率(IOU)小于0.3的,全部是非人脸。
2、IOU大于0.65的是人脸。
3、IOU在0.4到0.65之间的是part人脸区域。
4、IOU大于0.65,人脸特征坐标,人脸标注五个位置。
其中1、2数据集主要用来识别人脸与非人脸。 2、3数据集用来做box bounding regression。 4数据集主要用来确定人脸五点特征位置。训练样本的比例,负样本:正样本:part样本:坐标=3:1:1:1
from:https://blog.csdn.net/xygl2009/article/details/77917402
测试过程:
1、PNet过程:
我们输入一张图,首先简历图像金字塔,假设我们得到n张图像,我们一次将每张图像送入PNet,这里就体现了全卷积网络的优点了:对输入图像的尺寸没有要求,这里我们举个实例进行说明:
加入我们输入24*24*3的图像,经过一层3*3卷积,变成22*22*10的特征图,再经过2*2池化,变成11*11*16,再经过2层3*3的卷积层,变成7*7*32的特征图。这个特征图每个1*1*32对应原图像中一个12*12的框。
不信我们可以从滑动窗的角度来解释,加入PNet是全连接,输入尺寸是12*12,南无为了检测24*24的图像,我们就要用滑动框在图像上滑动,stride=2(之所以是2,是为了跟maxpool=2相匹配),这样我们可以计算出,遍历整幅图像需要的滑动窗口数为:((24-12)/2)+1=7,所以我们要将49个12*12的滑动框送入PNet,得到49个1*1*32的结果,这不就和上面输出的结果一模一样了嘛!!!!
这也正是全卷积的优点所在!!
接下来继续:我们得到7*7*32的特征图,对每个1*1*32的向量进行类别判断,我们得到49*2的判别结果,49对应图像上的49的滑动框,2对应每个框是人脸的概率,非人脸的概率。
对于判断是人脸的框,进行边框偏移量预测,边框回归输出4个offset,那么我们就以当前这个滑动窗口的位置为基准,求回归矫正后的人脸边框。
2、RNet
对于PNet得到的检测框,NMS处理,删除一些检测框,将剩余的检测框resize成24*24,送入RNet,之后同第一步,得到矫正回归后的检测框。
3、将检测框进行NMS,删除一些检测框,将剩余的检测框resize成48*48,送入ONet,然后得到矫正回归后的检测框。以求得的这个边框为基准,根据预测出的5个人脸特征点的offset。求取真正的五个人脸特征点坐标。
推荐:https://blog.csdn.net/dapanbest/article/details/79344558
五、OpenCV
调用caffe模型,成功完成人脸识别。
- //success
- #include <opencv2/dnn.hpp>
- #include <opencv2/imgproc.hpp>
- #include <opencv2/highgui.hpp>
- using namespace cv;
- using namespace cv::dnn;
-
- #include <iostream>
- using namespace std;
-
- int main(int argc, char **argv)
- {
- CommandLineParser parser(argc, argv,
- "{ h help | false | print this help message }"
- "{ p proto | det1.prototxt | (required) model configuration, e.g. hand/pose.prototxt }"
- "{ m model | det1.caffemodel | (required) model weights, e.g. hand/pose_iter_102000.caffemodel }"
- "{ i image | face.jpg | (required) path to image file (containing a single person, or hand) }"
- "{ width | 12 | Preprocess input image by resizing to a specific width. }"
- "{ height | 12 | Preprocess input image by resizing to a specific height. }"
- "{ t threshold | 0.1 | threshold or confidence value for the heatmap }"
- );
-
- String modelTxt = parser.get<string>("proto");
- String modelBin = parser.get<string>("model");
- String imageFile = parser.get<String>("image");
- int W_in = parser.get<int>("width");
- int H_in = parser.get<int>("height");
- float thresh = parser.get<float>("threshold");
- if (parser.get<bool>("help") || modelTxt.empty() || modelBin.empty() || imageFile.empty())
- {
- cout << "A sample app to demonstrate human or hand pose detection with a pretrained OpenPose dnn." << endl;
- parser.printMessage();
- return 0;
- }
-
- // read the network model
- Net net = readNetFromCaffe(modelTxt, modelBin);
-
- // and the image
- Mat img = imread(imageFile);
- if (img.empty())
- {
- std::cerr << "Can't read image from the file: " << imageFile << std::endl;
- exit(-1);
- }
-
- // send it through the network
- Mat inputBlob = blobFromImage(img, 1.0, Size(W_in, H_in), Scalar(0, 0, 0), false, false);
- net.setInput(inputBlob,"data");
- Mat result = net.forward("prob1");
- // the result is an array of "heatmaps", the probability of a body part being in location x,y
-
- Mat probMat = result.reshape(1, 1); //输出2个标签,第一个代表人脸,第二个代表非人脸,经验证:输入face照片,输出[1,0];输入非人脸照片,输出[0,1]
- float a = probMat.at<float>(0, 0);//是人脸的得分
- float b = probMat.at<float>(0, 1);//不是人脸的得分
- namedWindow("facedetect", 0);
- imshow("facedetect", probMat);
- waitKey();
-
- return 0;
- }

from:https://www.cnblogs.com/zyly/p/9703614.html 文中还有人脸识别的损失函数构造
prototxt的更加详细的网络结构参见:https://github.com/DaFuCoding/MTCNN_Caffe/tree/master/examples/MTmodel
分别为det1,det2,det3。
det1.prototxt结构:
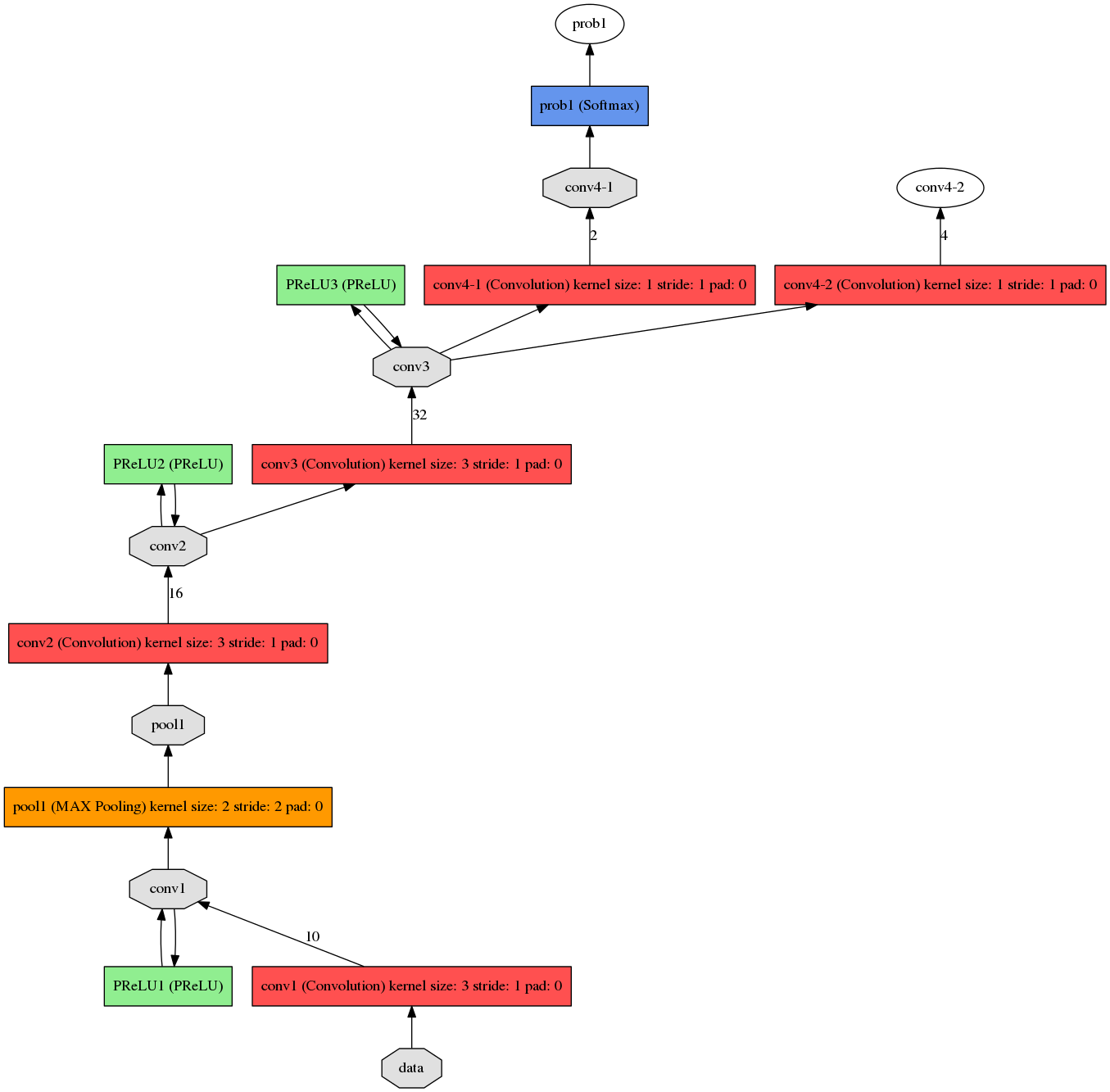
det2.prototxt结构:
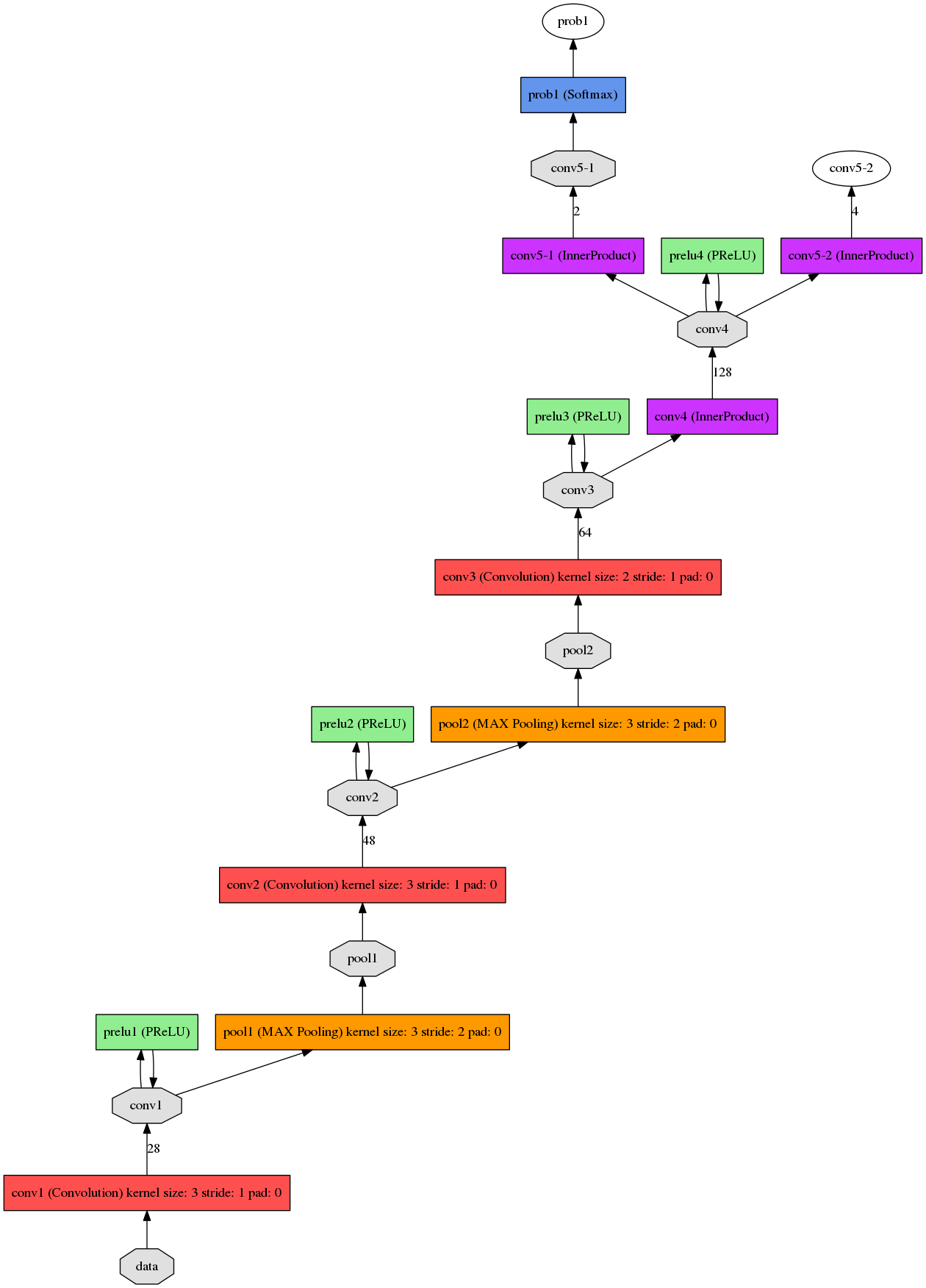
det3.prototxt结构:

from:https://blog.csdn.net/qq_14845119/article/details/52680940
以det1为例,简要介绍其结构:


