
- 1css的布局
- 2Ubuntu 服务器初步设置指南_ubuntu设备服务器
- 3Hadoop HDFS HA启动出现两个StandBy NameNode
- 44x4矩阵键盘设计Verilog矩阵式键盘控制,视频/代码_4×4键盘verilog
- 5基于stm32云平台a43智能药箱嵌入式开发物联网嵌入式软硬件开发单片机毕业源码案例设计
- 6System.out.println(“我的创作纪念日 - 三周年“);_csdn 一天只能发10篇
- 7el-drawer宽度课拉伸_el-drawer__wrapper
- 8在线客服系统源码软件代码+自动回复+可生成接入+手机版管理后台
- 9kafka多线程并发消费,批量消费_kafka spring pull多线程消费
- 10LLMNR和NetBIOS欺骗攻击分析及防范_禁用netbios后会怎样
浅析数据工程
赞
踩
目前数字化转型对于市场来说并不是一个新鲜事物,从技术视角来看,尽管大模型的涌现带来人们的更多关注,但人工智能与大数据相关技术仍处于创新阶段,各行业正在寻找和探索价值场景与新兴技术融合的平衡点,希望在新兴技术的加持下能够在激烈的竞争中占据有利位置。
数据,数据
数据是新一代技术革命下的生产要素,掌握了生产要素与生产要素的加工方式就是掌握了数字经济下的价值密码,这已经是业界的基本共识。
企业想要更好地管理数据并利用数据,就必须了解数据在现代企业中的产生源头、组织形态等。企业数字化转型一般分为三个阶段:
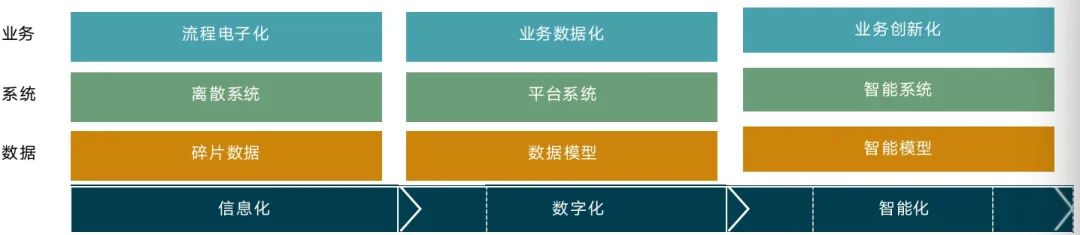
从数据产生到数据价值落地的过程中,数据的信息密度越来越高,其中蕴含的知识也越来越丰富。通过分析企业数据全流程,企业可以抓住重点环节,因地制宜地制定落地规划,数据 全流程分析是每个企业在进行数据工程落地的前提。
数据工程
从软件开发出现到软件开发逐步规模化的过程中, IT 从业者 们一点点积累下关于需求、设计、实现、测试、运维等方面的工作最佳实践。数据在企业内部流转会经历多个阶段,而每个阶段之间还存在着各种各样的问题。
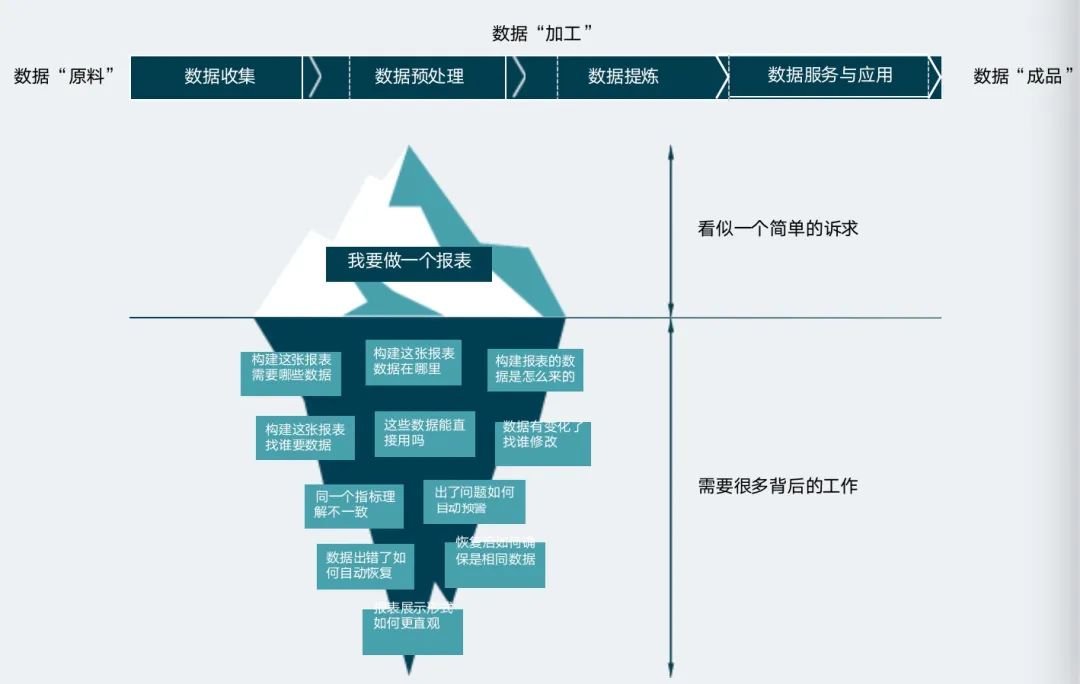
数据工程则是帮助企业高效地挖掘数据价值,持续地赋能业务增长, 加速数据到资产的升华过程的最佳实践。
数据工程包含了需求、设计、构建、测试、维护演进等阶段,涵盖了项目管理、开发过程管理、工程工具与方 法、构建管理、质量管理, 是一套为了应对规模化生产和使用数据、为业务提供数据支撑, 最终产生价值的体系。
数据工程是一套体系
数据工程是用来加速数据到价值过程的规模化最佳实践
数据工程是软件工程的一部分
数据工程不是传统软件工程在数据领域的简单重现
对于企业来说,数据工程包括三个战略环节:数据愿景对齐、数据工程落地实施、数据持续运营。

愿景对齐的第一步是通过定义、统一业务价值度量框架来识别业务价值场景。探索出的业务价值场景需要包含场景的背景、价值点、 所涉及的用户、需要什么样的能力、用户旅程、所涉及的实体、风险等信息。
落地过程就如同孕育新生命一般,其中数据梳理规 划蓝图,数据架构设计规划骨架,数据模型设计构成器官,数据接入则赋予信息感知能力,数据处理构成中枢 大脑, 测试、安全部分负责为新生儿提供保护, 每个步骤相互依赖, 缺一不可,通过数据梳理、数据架构设计、数据接入、数据处理、数据测试、数据安全和能力复用与保障七个步骤来实现数据工程落地。
数据运营的目的是要形成企业看数据、用数据、将数据作为沟通语言和工具的“数 据文化”,数据只有容易被发现,才有产生价值的可能性。
数据工程人员的能力模型
数据工程的落地,归根结底还是需要由人来完成。构建企业自身的人员能力培养机制、 搭建企业人员数据能力提升通道是数据工程能力持续迭代的重要保障。
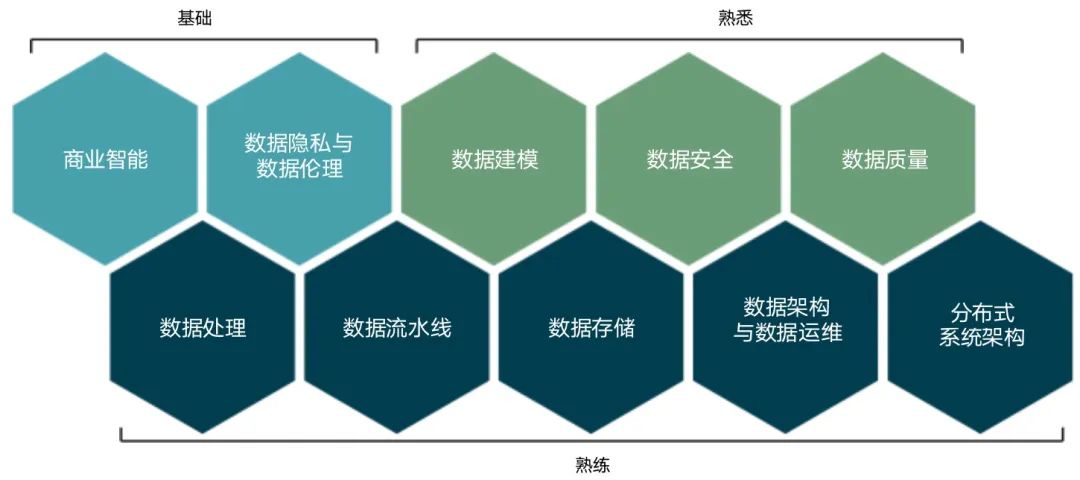
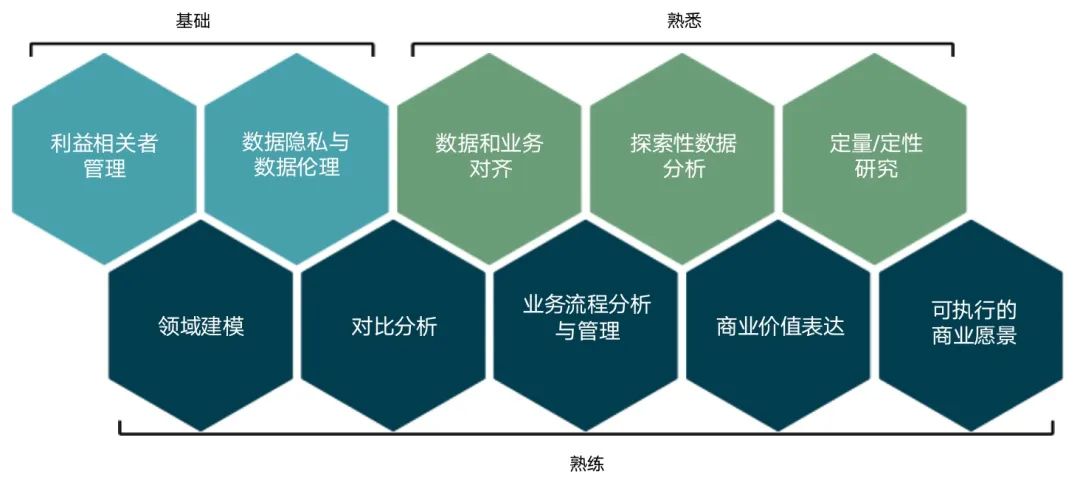
数据工程师能力模型如下:
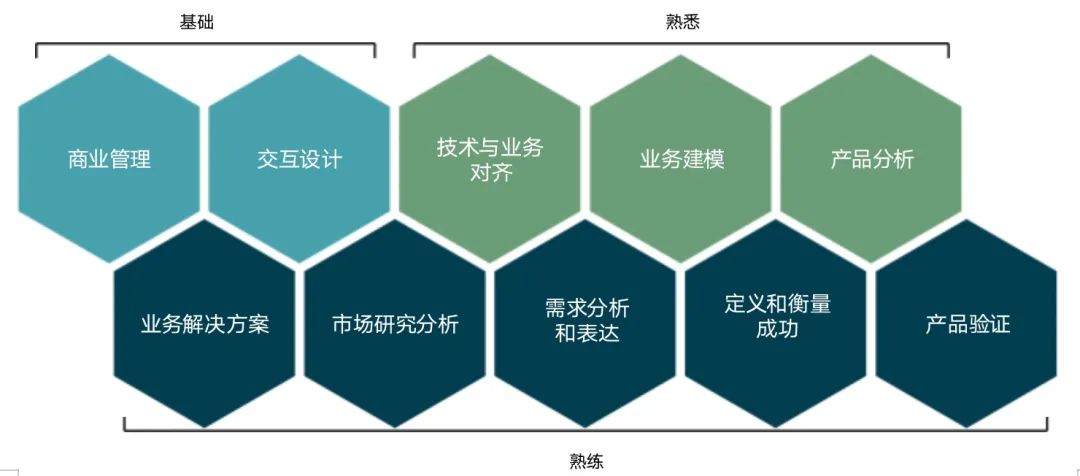
数据产品经理的能力模型如下:
数据分析师的能力模型如下:
数据工程是数字经济下确保数据价值转化的重要保障,是加速数据转化为价值的重要手段,需要应对未来数字经济的大趋势。为了处理数据领域的各种新问题, 各种新技术、新概念逐渐涌现, 现代数据仓库、数据湖、湖仓一体、分布式数据架构、机器学习、数据云原生等逐一登上舞台。
数据工程的工具图谱
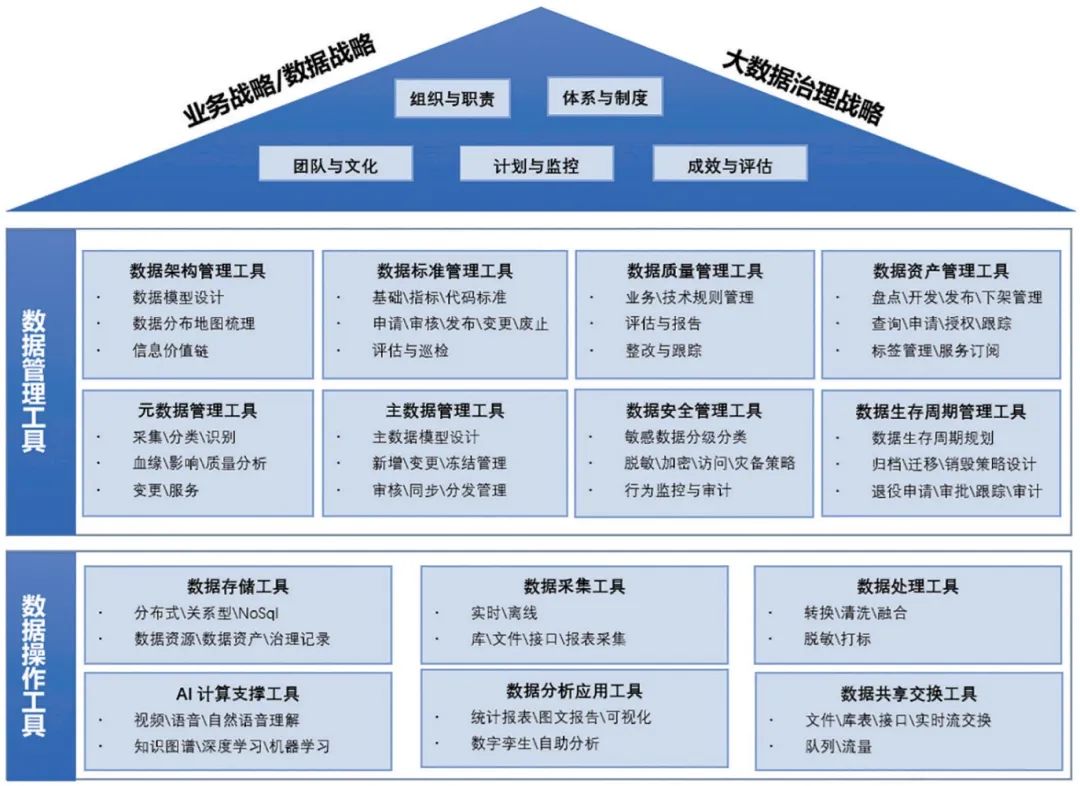
数据工程是咨询公司Thoughtworks 给出的概念, 但仍然是新瓶装旧酒, 个人可以认为,可以映射成传统意义上的数据治理。对于数据治理而言,已经有相对成熟的体系, 下面是数据治理的工具全景图:
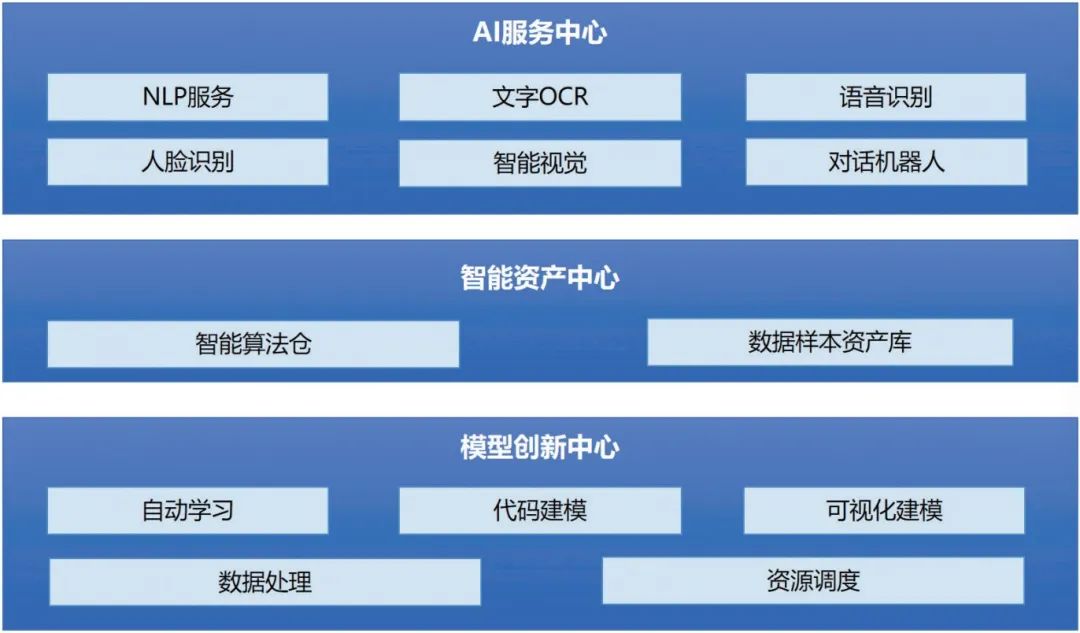
特别地, 对AI计算的能力支撑工具图谱而言,如下图所示:
大模型与数据工程
人工智能发展的突破得益于高质量数据的发展,数据是大模型竞争的关键要素之一,大模型的训练需要高质量、大规模、多样性的数据集,而优质中文数据集是稀缺的。行业数据的价值很高,具有优质数据和一定大模型能力的公司或通过行业大模型赋能业务。
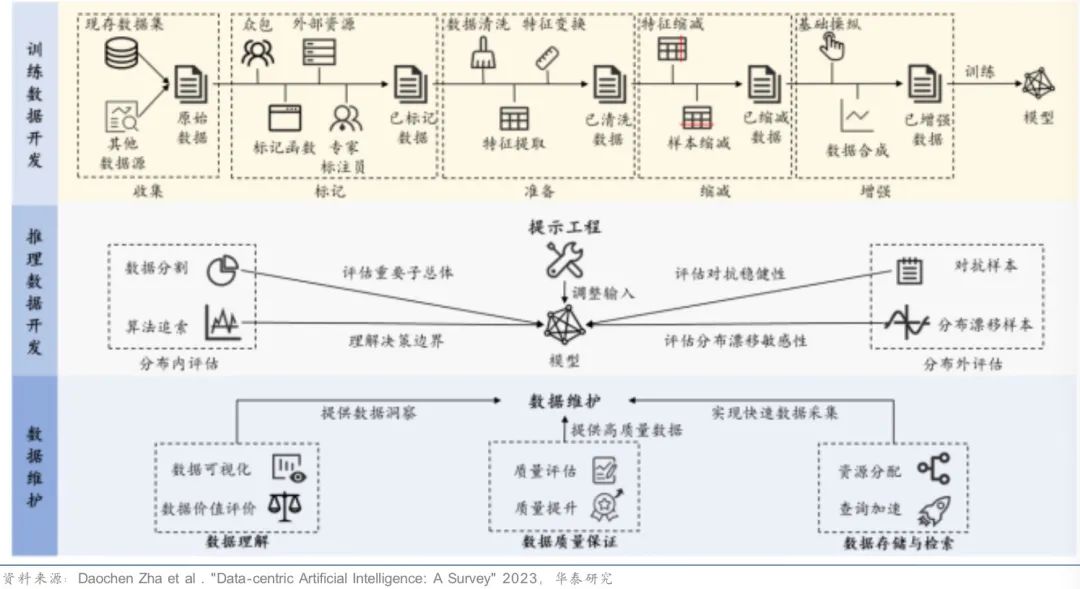
未来数据成本在大模型开发中的成本占比或将提升,主要包括数据采集, 清洗, 标注等成本。在模型相对固定的前提下,通过提升数据的质量和数量可以提升整个模型的训练效果。以数据为中心的AI工作流如下图所示:
从 GPT- 1 到 LLaMA 的大语言模型数据集主要包含六类:维基百科、书籍、期刊、Reddit 链接、 Common Crawl 和其他数据集。多模态大模型需要更深层次的网络和更大的数据集进行预训练。过 去数年中, 多模态大模性参数量及数据量持续提升。例如, 2022 年 Stability AI 发布的 Stable Diffusion 数据集包含 58.4 亿图文对/图像,是 2021 年 OpenAI 发布的 DALL-E 数据集的 23 倍。
国内各行业数据资源丰富,2021-2026 年数据量规模 CAGR 高于全球,数据主要来源于政 府/传媒/服务/零售等行业。据 IDC ,2021-2026 年中国数据量规模将由 18.51ZB 增长至 56.16ZB ,CAGR 达到 24.9%,高于全球平均 CAGR。尽管国内数据资源丰富,但由于数据挖掘不足,数据无法自由在市场上流通等现状,优质中文优质数据集仍然稀缺。
百度“文心”大模型训练特有数据主要包括万亿级的网页数据,数十亿的搜索数据 和图片数据等。阿里“通义”大模型的训练数据主要来自阿里达摩院。腾讯“混元”大模 型特有的训练数据主要来自微信公众号,微信搜索等优质数据。华为“盘古”大模型的训练数据除公开数据外, 还有 B 端行业数据加持,包括气象, 矿山, 铁路等行业数据。商汤 “日日新”模型的训练数据中包括了自行生成的 Omni Objects 3D 多模态数据集。
因此,在这个大模型的时代, 企业的数据工程中要融入面向大模型的数据架构,在数据产生时完成自行标注,同时辅之以数据服务商提供的数据,将大模型作为默认选项形成自己的领域模型。
拭目以待!
【参考资料与关联阅读】
数据工程白皮书——thoughtworks
数据治理工具图谱研究报告——中国电子技术标准研究院
大模型需要什么样的数据——华泰证券
- 引入依赖:
com.rabbitmq [详细] 赞
踩

